
















 Maison
MaisonReconnaissance des visages en 2025 : Réseaux siamois ou classification binaire ?
La reconnaissance des visages joue un rôle essentiel dans des applications allant des systèmes de sécurité aux médias sociaux. Alors que la perte de triplet est une méthode largement utilisée pour entraîner les réseaux neuronaux convolutionnels (CNN) à cette fin, une stratégie alternative présente la tâche comme un problème de classification binaire. Cette approche s'appuie sur les réseaux siamois, qui offrent un moyen distinct d'apprendre les paramètres nécessaires à une vérification efficace des visages. Nous examinons ci-dessous comment cela est possible en employant une paire de réseaux neuronaux pour générer des encastrements.
Points clés
Les réseaux siamois sont efficaces pour la vérification des visages.
La reconnaissance des visages peut être modélisée comme une tâche de classification binaire.
L'apprentissage des fonctions de similarité intègre la régression logistique.
Le pré-calcul des embeddings améliore l'efficacité du déploiement.
Les processus comprennent la collecte de données, la formation de modèles, l'évaluation et le déploiement.
La vérification et la reconnaissance des visages peuvent être formées en utilisant la classification binaire comme alternative à la perte de triplet.
Comprendre la reconnaissance et la vérification des visages
Reconnaissance des visages en tant que classification binaire

La reconnaissance des visages ne se limite pas à l'identification d'un individu ; elle vérifie l'identité déclarée d'une personne. C'est ce que l'on appelle la vérification des visages. Une approche pratique traite la vérification comme un problème de classification binaire. Au lieu de faire la distinction entre plusieurs visages, le système répond à une question simple : "Ces deux visages appartiennent-ils à la même personne ?" Ce cadrage binaire simplifie le problème et améliore l'efficacité des calculs. La technique repose sur un réseau siamois, composé de deux réseaux neuronaux identiques dont les poids et l'architecture sont communs. Chaque réseau traite une image d'entrée et ses sorties sont comparées pour obtenir un score de similarité. Si le score dépasse un seuil défini, les visages sont considérés comme correspondants ; dans le cas contraire, ils sont classés comme différents. Le réseau est entraîné à produire un résultat de 1 pour les identités correspondantes et de 0 pour les identités non correspondantes. Cela contraste avec des systèmes plus complexes qui doivent faire la différence entre un grand nombre d'individus connus.
L'architecture du réseau siamois
La méthode est centrée sur l'architecture du réseau siamois.
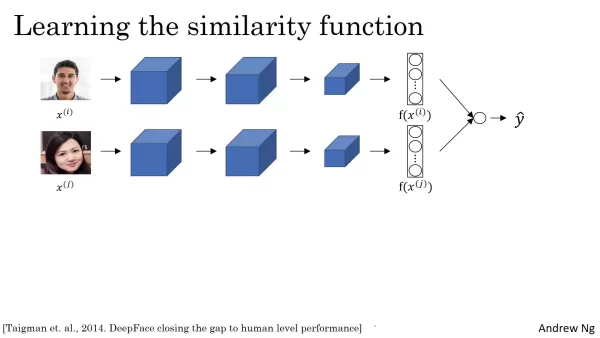
Cette architecture associe deux réseaux neuronaux identiques, chacun traitant l'une des deux images d'entrée. Ces réseaux calculent des encastrements, qui sont des vecteurs à haute dimension codant des traits faciaux uniques. En comparant ces encastrements, le système évalue la similarité des visages. Le processus d'intégration comprend généralement des couches convolutives, de mise en commun et entièrement connectées, chacune extrayant progressivement des caractéristiques complexes de l'image. Le résultat final est un vecteur - souvent à 128 dimensions - qui capture les caractéristiques faciales essentielles. Des dimensions plus grandes peuvent également être utilisées pour détecter des détails plus fins. Il est essentiel que les deux réseaux de la configuration siamoise partagent des paramètres identiques, ce qui garantit que les encastrements sont générés par le même processus d'extraction de caractéristiques et qu'ils sont directement comparables.
Apprentissage des fonctions de similarité avec la régression logistique
Utilisation de la régression logistique
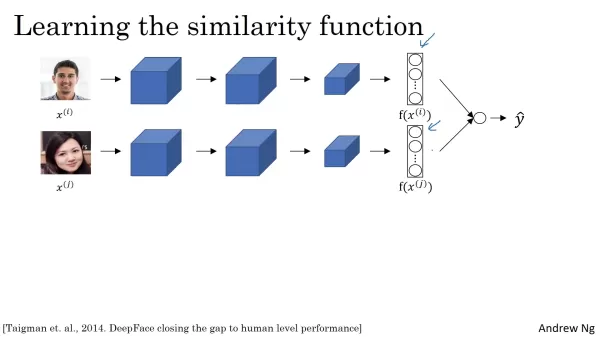
Pour déterminer si deux visages représentent la même personne, il faut comparer les enregistrements du réseau siamois. Une unité de régression logistique applique une fonction sigmoïde à ces encastrements, produisant un score de probabilité qui reflète la probabilité d'une correspondance. L'entrée de cette unité n'est pas les encastrements bruts, mais les caractéristiques qui en sont dérivées. Une méthode courante consiste à calculer la différence absolue par élément entre les deux encastrements, en mettant l'accent sur les caractéristiques présentant les plus grandes disparités. La similarité du chi carré est une autre technique utilisée. L'objectif est de former des caractéristiques hautement discriminantes qui permettent à l'unité de régression logistique de faire des prédictions précises. Les différences entre les éléments alimentent le modèle de régression logistique, qui apprend à attribuer les poids appropriés. Si les différences sont minimes, l'unité attribue une forte probabilité, ce qui indique qu'il s'agit de la même personne ; si les différences sont importantes, elle attribue une faible probabilité, ce qui indique qu'il s'agit d'individus différents.
Formation du réseau siamois et de la régression logistique
Processus de formation étape par étape
- Collecte des données de formation: Commencez par compiler un ensemble de données d'images de visages, avec des étiquettes indiquant si les paires d'images représentent la même personne ou des personnes différentes. Cet ensemble de données permet d'entraîner le réseau siamois et l'unité de régression logistique.
- Configuration du réseau siamois: Configurez deux réseaux CNN identiques avec la même architecture et des poids partagés. Ces réseaux apprendront à générer des embeddings à partir d'images de visages en entrée.
- Calcul des différences de caractéristiques: Déterminer les différences absolues par élément entre les encastrements générés par les deux CNN pour chaque paire d'images. Ces différences deviennent les caractéristiques d'entrée de l'unité de régression logistique.
- Intégration de la régression logistique: Utiliser un modèle de régression logistique pour convertir les différences de caractéristiques en un score de probabilité, indiquant si les visages correspondent.
- Mise au point: Affiner la couche de régression logistique en ajustant les poids attribués aux caractéristiques (telles que celles d'un encastrement à 128 dimensions).
- Formation par rétropropagation: Entraînez l'ensemble du système - les réseaux nationaux et l'unité de régression logistique - à l'aide de la rétropropagation. Cette méthode minimise une fonction de perte qui pénalise les erreurs de prédiction, améliorant progressivement la précision en optimisant les poids et les biais du réseau.
- Ajustement des poids: Le modèle final de régression logistique peut inclure des paramètres supplémentaires tels que le poids (W) et le biais (B).
- Pré-calcul des emboîtements: Pour un déploiement plus rapide, pré-calculer les embeddings pour permettre des comparaisons rapides.
Avantages et inconvénients des réseaux siamois pour la reconnaissance des visages
Avantages
Efficacité informatique
S'attaque directement à la vérification des visages
Extraction efficace des caractéristiques
Cons
Exigences en matière de données d'entraînement
Risque de surajustement
Généralisation limitée
Questions fréquemment posées
Que sont les réseaux siamois et comment fonctionnent-ils dans la reconnaissance des visages ?
Les réseaux siamois sont des réseaux neuronaux composés d'au moins deux sous-réseaux identiques. Chaque sous-réseau reçoit une entrée distincte mais partage des poids avec les autres. Dans la reconnaissance des visages, ces réseaux traitent des paires d'images de visages pour produire des encastrements, dont la similarité est ensuite évaluée.
Pourquoi la reconnaissance des visages est-elle parfois présentée comme un problème de classification binaire ?
Considérer la reconnaissance des visages comme un problème de classification binaire la simplifie en déterminant si deux visages correspondent, ce qui augmente l'efficacité par rapport à la distinction entre de nombreux individus. Cette méthode utilise des réseaux siamois pour comparer des paires d'images de visages.
Quel est le rôle de la régression logistique dans l'apprentissage des fonctions de similarité pour la reconnaissance des visages ?
La régression logistique associe les différences entre les intégrations des réseaux siamois à un score de probabilité. Ce score estime la probabilité que les deux visages soient ceux d'une même personne, ce qui permet de prendre une décision binaire.
Questions connexes
Comment l'approche des réseaux siamois se compare-t-elle aux méthodes traditionnelles telles que la perte de triplet ?
Les méthodes traditionnelles telles que la perte de triplet visent à apprendre un espace d'intégration dans lequel les visages d'une même personne sont plus proches et ceux de personnes différentes sont plus éloignés. Les réseaux siamois, structurés pour la classification binaire, se concentrent sur la vérification de l'identité de deux visages, ce qui offre des avantages en termes de calcul. Le meilleur choix dépend de l'application spécifique et des caractéristiques de l'ensemble de données.
Existe-t-il d'autres méthodes pour évaluer la similarité des encastrements ?
Oui, les alternatives incluent la similarité en cosinus, la distance euclidienne et la similarité chi-carré. La formule de similarité chi-carré offre une autre façon d'aborder la reconnaissance des visages. Chaque technique a ses points forts et est adaptée à différents types de données et cas d'utilisation. Par exemple, la similarité en cosinus donne de bons résultats avec des données de haute dimension, tandis que la distance euclidienne est efficace dans des dimensions inférieures.
Qu'implique le déploiement effectif du système formé ?
Le déploiement implique le calcul préalable des encastrements afin d'éviter de stocker des images brutes. Le système, construit sur une architecture de réseau siamois, est conçu pour comparer efficacement ces encastrements.
Article connexe
 Meituan définit une feuille de route triennale en matière d'IA pour dynamiser l'intelligence d'affaires
Avec l'évolution rapide des technologies Internet, l'IA est devenue une priorité pour les grandes entreprises. Meituan, l'une des principales plateformes chinoises de services de proximité, investit d
Canva prévoit d'entrer en bourse l'année prochaine et de se transformer en un écosystème de conception basé sur l'IA
Canva, la licorne du logiciel de conception graphique, prévoit de lancer officiellement son processus d'introduction en bourse l'année prochaine, une initiative qui marque l'entrée de l'entreprise dan
Hightouch atteint les 100 millions de dollars de chiffre d'affaires annuel récurrent grâce à ses outils marketing basés sur l'IA
Autrefois, les spécialistes du marketing comptaient sur des graphistes et d’autres professionnels de la création pour produire des images et des vidéos destinées à des campagnes publicitaires en ligne
Recommandations de sujets spéciaux liés
Éducation et apprentissage
Meituan définit une feuille de route triennale en matière d'IA pour dynamiser l'intelligence d'affaires
Avec l'évolution rapide des technologies Internet, l'IA est devenue une priorité pour les grandes entreprises. Meituan, l'une des principales plateformes chinoises de services de proximité, investit d
Canva prévoit d'entrer en bourse l'année prochaine et de se transformer en un écosystème de conception basé sur l'IA
Canva, la licorne du logiciel de conception graphique, prévoit de lancer officiellement son processus d'introduction en bourse l'année prochaine, une initiative qui marque l'entrée de l'entreprise dan
Hightouch atteint les 100 millions de dollars de chiffre d'affaires annuel récurrent grâce à ses outils marketing basés sur l'IA
Autrefois, les spécialistes du marketing comptaient sur des graphistes et d’autres professionnels de la création pour produire des images et des vidéos destinées à des campagnes publicitaires en ligne
Recommandations de sujets spéciaux liés
Éducation et apprentissage
 Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
 10 outils
10 outils
 xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai
Analyse des données
Les meilleurs outils de visualisation de données basés sur l'IA : générez automatiquement des tableaux de bord BI interactifs à partir de fichiers bruts
Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai
Réseaux sociaux
Kits de marque basés sur l'IA pour les réseaux sociaux : assurez la cohérence visuelle de votre marque sur tous les canaux
Découvrez les meilleurs kits de branding IA pour les réseaux sociaux en 2026. La sélection de XIX.AI regroupe des outils de premier plan qui changent la donne et vous permettent de garantir une cohérence visuelle parfaite de votre marque sur tous les canaux. Comparez les options gratuites et payantes grâce à des tests concrets. Donnez dès aujourd'hui un coup de pouce visuel à votre marque.
10 outils
xix.ai
chatbot
Les meilleures applications de petite amie virtuelle et outils d'accompagnement IA pour les jeux de rôle (Guide 2026)
Découvrez les meilleurs outils d'IA de 2026 pour des jeux de rôle immersifs et des interactions enrichissantes. Le guide sélectionné par XIX.AI présente des applications puissantes et révolutionnaires, avec des classements mis à jour chaque semaine, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le partenaire idéal et profitez dès aujourd'hui d'une compagnie numérique enrichissante.
10 outils
xix.ai

 commentaires (2)
commentaires (2)
![PaulMartínez]()
Interessant, dass hier Siamese Networks und binäre Klassifikation verglichen werden. Ich frage mich, ob die Wahl je nach Anwendungsfall variieren sollte – vielleicht ist der eine Ansatz für Sicherheitssysteme besser, der andere für Social Media? 🤔 Die Diskussion um Triplet Loss vs. Alternativen zeigt, wie dynamisch das Feld noch ist. Hoffentlich bleibt die Ethik dabei nicht auf der Strecke, gerade bei Gesichtserkennung.
![JohnRoberts]()
¿Redes Siamesas vs. clasificación binaria en 2025? Me pregunto si esto afectará cómo funcionan los desbloqueos faciales en nuestros móviles 🤔 ¿Será más rápido o más seguro? Alguien que sepa del tema que comente!
La reconnaissance des visages joue un rôle essentiel dans des applications allant des systèmes de sécurité aux médias sociaux. Alors que la perte de triplet est une méthode largement utilisée pour entraîner les réseaux neuronaux convolutionnels (CNN) à cette fin, une stratégie alternative présente la tâche comme un problème de classification binaire. Cette approche s'appuie sur les réseaux siamois, qui offrent un moyen distinct d'apprendre les paramètres nécessaires à une vérification efficace des visages. Nous examinons ci-dessous comment cela est possible en employant une paire de réseaux neuronaux pour générer des encastrements.
Points clés
Les réseaux siamois sont efficaces pour la vérification des visages.
La reconnaissance des visages peut être modélisée comme une tâche de classification binaire.
L'apprentissage des fonctions de similarité intègre la régression logistique.
Le pré-calcul des embeddings améliore l'efficacité du déploiement.
Les processus comprennent la collecte de données, la formation de modèles, l'évaluation et le déploiement.
La vérification et la reconnaissance des visages peuvent être formées en utilisant la classification binaire comme alternative à la perte de triplet.
Comprendre la reconnaissance et la vérification des visages
Reconnaissance des visages en tant que classification binaire
La reconnaissance des visages ne se limite pas à l'identification d'un individu ; elle vérifie l'identité déclarée d'une personne. C'est ce que l'on appelle la vérification des visages. Une approche pratique traite la vérification comme un problème de classification binaire. Au lieu de faire la distinction entre plusieurs visages, le système répond à une question simple : "Ces deux visages appartiennent-ils à la même personne ?" Ce cadrage binaire simplifie le problème et améliore l'efficacité des calculs. La technique repose sur un réseau siamois, composé de deux réseaux neuronaux identiques dont les poids et l'architecture sont communs. Chaque réseau traite une image d'entrée et ses sorties sont comparées pour obtenir un score de similarité. Si le score dépasse un seuil défini, les visages sont considérés comme correspondants ; dans le cas contraire, ils sont classés comme différents. Le réseau est entraîné à produire un résultat de 1 pour les identités correspondantes et de 0 pour les identités non correspondantes. Cela contraste avec des systèmes plus complexes qui doivent faire la différence entre un grand nombre d'individus connus.
L'architecture du réseau siamois
La méthode est centrée sur l'architecture du réseau siamois.
Cette architecture associe deux réseaux neuronaux identiques, chacun traitant l'une des deux images d'entrée. Ces réseaux calculent des encastrements, qui sont des vecteurs à haute dimension codant des traits faciaux uniques. En comparant ces encastrements, le système évalue la similarité des visages. Le processus d'intégration comprend généralement des couches convolutives, de mise en commun et entièrement connectées, chacune extrayant progressivement des caractéristiques complexes de l'image. Le résultat final est un vecteur - souvent à 128 dimensions - qui capture les caractéristiques faciales essentielles. Des dimensions plus grandes peuvent également être utilisées pour détecter des détails plus fins. Il est essentiel que les deux réseaux de la configuration siamoise partagent des paramètres identiques, ce qui garantit que les encastrements sont générés par le même processus d'extraction de caractéristiques et qu'ils sont directement comparables.
Apprentissage des fonctions de similarité avec la régression logistique
Utilisation de la régression logistique
Pour déterminer si deux visages représentent la même personne, il faut comparer les enregistrements du réseau siamois. Une unité de régression logistique applique une fonction sigmoïde à ces encastrements, produisant un score de probabilité qui reflète la probabilité d'une correspondance. L'entrée de cette unité n'est pas les encastrements bruts, mais les caractéristiques qui en sont dérivées. Une méthode courante consiste à calculer la différence absolue par élément entre les deux encastrements, en mettant l'accent sur les caractéristiques présentant les plus grandes disparités. La similarité du chi carré est une autre technique utilisée. L'objectif est de former des caractéristiques hautement discriminantes qui permettent à l'unité de régression logistique de faire des prédictions précises. Les différences entre les éléments alimentent le modèle de régression logistique, qui apprend à attribuer les poids appropriés. Si les différences sont minimes, l'unité attribue une forte probabilité, ce qui indique qu'il s'agit de la même personne ; si les différences sont importantes, elle attribue une faible probabilité, ce qui indique qu'il s'agit d'individus différents.
Formation du réseau siamois et de la régression logistique
Processus de formation étape par étape
- Collecte des données de formation: Commencez par compiler un ensemble de données d'images de visages, avec des étiquettes indiquant si les paires d'images représentent la même personne ou des personnes différentes. Cet ensemble de données permet d'entraîner le réseau siamois et l'unité de régression logistique.
- Configuration du réseau siamois: Configurez deux réseaux CNN identiques avec la même architecture et des poids partagés. Ces réseaux apprendront à générer des embeddings à partir d'images de visages en entrée.
- Calcul des différences de caractéristiques: Déterminer les différences absolues par élément entre les encastrements générés par les deux CNN pour chaque paire d'images. Ces différences deviennent les caractéristiques d'entrée de l'unité de régression logistique.
- Intégration de la régression logistique: Utiliser un modèle de régression logistique pour convertir les différences de caractéristiques en un score de probabilité, indiquant si les visages correspondent.
- Mise au point: Affiner la couche de régression logistique en ajustant les poids attribués aux caractéristiques (telles que celles d'un encastrement à 128 dimensions).
- Formation par rétropropagation: Entraînez l'ensemble du système - les réseaux nationaux et l'unité de régression logistique - à l'aide de la rétropropagation. Cette méthode minimise une fonction de perte qui pénalise les erreurs de prédiction, améliorant progressivement la précision en optimisant les poids et les biais du réseau.
- Ajustement des poids: Le modèle final de régression logistique peut inclure des paramètres supplémentaires tels que le poids (W) et le biais (B).
- Pré-calcul des emboîtements: Pour un déploiement plus rapide, pré-calculer les embeddings pour permettre des comparaisons rapides.
Avantages et inconvénients des réseaux siamois pour la reconnaissance des visages
Avantages
Efficacité informatique
S'attaque directement à la vérification des visages
Extraction efficace des caractéristiques
Cons
Exigences en matière de données d'entraînement
Risque de surajustement
Généralisation limitée
Questions fréquemment posées
Que sont les réseaux siamois et comment fonctionnent-ils dans la reconnaissance des visages ?
Les réseaux siamois sont des réseaux neuronaux composés d'au moins deux sous-réseaux identiques. Chaque sous-réseau reçoit une entrée distincte mais partage des poids avec les autres. Dans la reconnaissance des visages, ces réseaux traitent des paires d'images de visages pour produire des encastrements, dont la similarité est ensuite évaluée.
Pourquoi la reconnaissance des visages est-elle parfois présentée comme un problème de classification binaire ?
Considérer la reconnaissance des visages comme un problème de classification binaire la simplifie en déterminant si deux visages correspondent, ce qui augmente l'efficacité par rapport à la distinction entre de nombreux individus. Cette méthode utilise des réseaux siamois pour comparer des paires d'images de visages.
Quel est le rôle de la régression logistique dans l'apprentissage des fonctions de similarité pour la reconnaissance des visages ?
La régression logistique associe les différences entre les intégrations des réseaux siamois à un score de probabilité. Ce score estime la probabilité que les deux visages soient ceux d'une même personne, ce qui permet de prendre une décision binaire.
Questions connexes
Comment l'approche des réseaux siamois se compare-t-elle aux méthodes traditionnelles telles que la perte de triplet ?
Les méthodes traditionnelles telles que la perte de triplet visent à apprendre un espace d'intégration dans lequel les visages d'une même personne sont plus proches et ceux de personnes différentes sont plus éloignés. Les réseaux siamois, structurés pour la classification binaire, se concentrent sur la vérification de l'identité de deux visages, ce qui offre des avantages en termes de calcul. Le meilleur choix dépend de l'application spécifique et des caractéristiques de l'ensemble de données.
Existe-t-il d'autres méthodes pour évaluer la similarité des encastrements ?
Oui, les alternatives incluent la similarité en cosinus, la distance euclidienne et la similarité chi-carré. La formule de similarité chi-carré offre une autre façon d'aborder la reconnaissance des visages. Chaque technique a ses points forts et est adaptée à différents types de données et cas d'utilisation. Par exemple, la similarité en cosinus donne de bons résultats avec des données de haute dimension, tandis que la distance euclidienne est efficace dans des dimensions inférieures.
Qu'implique le déploiement effectif du système formé ?
Le déploiement implique le calcul préalable des encastrements afin d'éviter de stocker des images brutes. Le système, construit sur une architecture de réseau siamois, est conçu pour comparer efficacement ces encastrements.










 Meituan définit une feuille de route triennale en matière d'IA pour dynamiser l'intelligence d'affaires
Avec l'évolution rapide des technologies Internet, l'IA est devenue une priorité pour les grandes entreprises. Meituan, l'une des principales plateformes chinoises de services de proximité, investit d
Meituan définit une feuille de route triennale en matière d'IA pour dynamiser l'intelligence d'affaires
Avec l'évolution rapide des technologies Internet, l'IA est devenue une priorité pour les grandes entreprises. Meituan, l'une des principales plateformes chinoises de services de proximité, investit d
 Canva prévoit d'entrer en bourse l'année prochaine et de se transformer en un écosystème de conception basé sur l'IA
Canva, la licorne du logiciel de conception graphique, prévoit de lancer officiellement son processus d'introduction en bourse l'année prochaine, une initiative qui marque l'entrée de l'entreprise dan
Canva prévoit d'entrer en bourse l'année prochaine et de se transformer en un écosystème de conception basé sur l'IA
Canva, la licorne du logiciel de conception graphique, prévoit de lancer officiellement son processus d'introduction en bourse l'année prochaine, une initiative qui marque l'entrée de l'entreprise dan
 Hightouch atteint les 100 millions de dollars de chiffre d'affaires annuel récurrent grâce à ses outils marketing basés sur l'IA
Autrefois, les spécialistes du marketing comptaient sur des graphistes et d’autres professionnels de la création pour produire des images et des vidéos destinées à des campagnes publicitaires en ligne
Hightouch atteint les 100 millions de dollars de chiffre d'affaires annuel récurrent grâce à ses outils marketing basés sur l'IA
Autrefois, les spécialistes du marketing comptaient sur des graphistes et d’autres professionnels de la création pour produire des images et des vidéos destinées à des campagnes publicitaires en ligne

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai

Découvrez les meilleurs kits de branding IA pour les réseaux sociaux en 2026. La sélection de XIX.AI regroupe des outils de premier plan qui changent la donne et vous permettent de garantir une cohérence visuelle parfaite de votre marque sur tous les canaux. Comparez les options gratuites et payantes grâce à des tests concrets. Donnez dès aujourd'hui un coup de pouce visuel à votre marque.
10 outils
xix.ai

Découvrez les meilleurs outils d'IA de 2026 pour des jeux de rôle immersifs et des interactions enrichissantes. Le guide sélectionné par XIX.AI présente des applications puissantes et révolutionnaires, avec des classements mis à jour chaque semaine, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le partenaire idéal et profitez dès aujourd'hui d'une compagnie numérique enrichissante.
10 outils
xix.ai

Interessant, dass hier Siamese Networks und binäre Klassifikation verglichen werden. Ich frage mich, ob die Wahl je nach Anwendungsfall variieren sollte – vielleicht ist der eine Ansatz für Sicherheitssysteme besser, der andere für Social Media? 🤔 Die Diskussion um Triplet Loss vs. Alternativen zeigt, wie dynamisch das Feld noch ist. Hoffentlich bleibt die Ethik dabei nicht auf der Strecke, gerade bei Gesichtserkennung.
¿Redes Siamesas vs. clasificación binaria en 2025? Me pregunto si esto afectará cómo funcionan los desbloqueos faciales en nuestros móviles 🤔 ¿Será más rápido o más seguro? Alguien que sepa del tema que comente!













