
















 Дом
ДомРаспознавание лиц в 2025 году: Сиамские сети или бинарная классификация?
Распознавание лиц играет важную роль в самых разных приложениях - от систем безопасности до социальных сетей. В то время как триплетные потери являются широко используемым методом обучения сверточных нейронных сетей (CNN) для этих целей, альтернативная стратегия рассматривает задачу как проблему бинарной классификации. Этот подход использует сиамские сети, обеспечивая особый способ обучения параметров, необходимых для эффективной верификации лиц. Ниже мы рассмотрим, как это достигается путем использования пары нейронных сетей для генерации вкраплений.
Ключевые моменты
Сиамские сети эффективны для верификации лиц.
Распознавание лиц можно смоделировать как задачу бинарной классификации.
Обучение функций сходства включает в себя логистическую регрессию.
Предварительное вычисление вкраплений повышает эффективность развертывания.
Процессы включают сбор данных, обучение модели, оценку и развертывание.
Как верификация, так и распознавание лиц могут быть обучены с использованием бинарной классификации в качестве альтернативы триплетным потерям.
Понятие распознавания и верификации лиц
Распознавание лиц как бинарная классификация

Распознавание лиц - это не просто идентификация человека, а проверка его личности. Это известно как верификация лица. Один из практических подходов рассматривает верификацию как задачу бинарной классификации. Вместо того чтобы различать множество лиц, система отвечает на простой вопрос: "Принадлежат ли эти два лица одному и тому же человеку?". Такое двоичное представление упрощает задачу и повышает эффективность вычислений. В основе метода лежит сиамская сеть, состоящая из двух идентичных нейронных сетей с общими весами и архитектурой. Каждая сеть обрабатывает одно входное изображение, а их выходы сравниваются для получения оценки сходства. Если этот показатель превышает определенный порог, лица считаются совпадающими, в противном случае они классифицируются как разные. Сеть обучена выдавать 1 для совпадающих лиц и 0 для несовпадающих. Это отличается от более сложных систем, которые должны различать широкий спектр известных лиц.
Архитектура сиамской сети
В основе метода лежит архитектура сиамской сети.
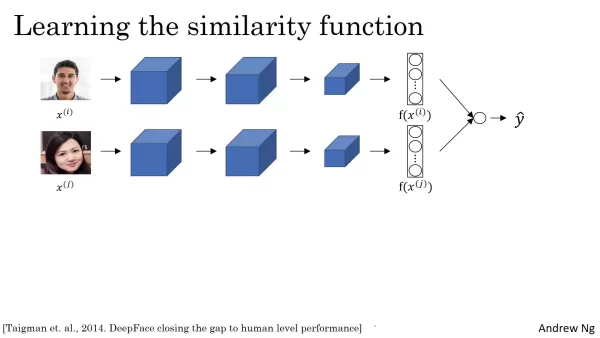
Эта архитектура объединяет две идентичные нейронные сети, каждая из которых обрабатывает одно из двух входных изображений. Эти сети вычисляют вкрапления, которые представляют собой высокоразмерные векторы, кодирующие уникальные черты лица. Сравнивая эти вкрапления, система оценивает сходство лиц. Процесс встраивания обычно включает в себя конволюционный, объединяющий и полностью связанный слои, каждый из которых извлекает из изображения все более сложные черты. В итоге получается вектор, часто 128-мерный, который отражает основные характеристики лица. Для выявления более тонких деталей могут использоваться и более крупные размеры. Очень важно, что обе сети в сиамской системе имеют одинаковые параметры, что гарантирует, что вкрапления генерируются в ходе одного и того же процесса извлечения признаков и являются непосредственно сравнимыми.
Обучение функций сходства с помощью логистической регрессии
Использование логистической регрессии
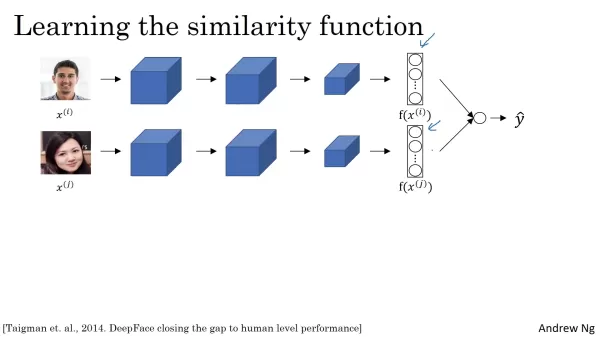
Чтобы определить, представляют ли два лица одного и того же человека, необходимо сравнить вкрапления из сиамской сети. Блок логистической регрессии применяет сигмоидальную функцию к этим вкраплениям, получая оценку вероятности, которая отражает вероятность совпадения. На вход этого блока подаются не исходные вкрапления, а полученные из них характеристики. Распространенным методом является вычисление абсолютной разницы между двумя вложениями по элементам, при этом выделяются признаки с наибольшим расхождением. Другой используемый метод - сходство по критерию хи-квадрат. Цель состоит в том, чтобы сформировать высокодискриминативные признаки, которые позволят блоку логистической регрессии делать точные прогнозы. Различия по элементам поступают в модель логистической регрессии, которая учится присваивать соответствующие веса. Если различия минимальны, блок присваивает высокую вероятность, указывая на одного и того же человека; если различия значительны, он присваивает низкую вероятность, указывая на разных людей.
Обучение сиамской сети и логистической регрессии
Пошаговый процесс обучения
- Сбор обучающих данных: Начните с составления набора данных изображений лиц с метками, указывающими, изображают ли пары изображений одного и того же человека или разных людей. На этом наборе данных обучаются сиамская сеть и блок логистической регрессии.
- Настройка сиамской сети: Настройте две идентичные CNN с одинаковой архитектурой и общими весами. Эти сети будут учиться генерировать вкрапления из входных изображений лиц.
- Вычисление различий признаков: Определите абсолютные разности между вкраплениями, сгенерированными двумя CNN для каждой пары изображений. Эти различия становятся входными признаками для блока логистической регрессии.
- Интеграция логистической регрессии: Использование модели логистической регрессии для преобразования различий признаков в оценку вероятности, указывающую на совпадение лиц.
- Тонкая настройка: Уточнение слоя логистической регрессии путем корректировки весов, присвоенных признакам (например, в 128-мерном вложении).
- Обучение с обратным распространением: Обучите всю систему - ИНС и блок логистической регрессии - методом обратного распространения. При этом минимизируется функция потерь, которая наказывает ошибки прогнозирования, постепенно повышая точность путем оптимизации весов и смещений сети.
- Настройка весов: Окончательная модель логистической регрессии может включать дополнительные параметры, такие как вес (W) и смещение (B).
- Предварительное вычисление вкраплений: Для ускорения развертывания предварительно вычисляйте вкрапления для быстрого сравнения.
Преимущества и недостатки сиамских сетей для распознавания лиц
Плюсы
Вычислительная эффективность
Непосредственно для верификации лиц
Эффективное извлечение признаков
Cons
Требования к обучающим данным
Возможность переоценки
Ограниченная генерализация
Часто задаваемые вопросы
Что такое сиамские сети и как они работают при распознавании лиц?
Сиамские сети - это нейронные сети, состоящие из двух или более одинаковых подсетей. Каждая подсеть получает отдельный входной сигнал, но имеет общие веса с остальными. При распознавании лиц эти сети обрабатывают пары изображений лиц для получения вкраплений, которые затем оцениваются на предмет сходства.
Почему распознавание лиц иногда рассматривается как проблема бинарной классификации?
Если рассматривать распознавание лиц как задачу бинарной классификации, то это упрощает задачу до определения совпадения двух лиц, что повышает эффективность по сравнению с распознаванием множества лиц. Этот метод использует сиамские сети для сравнения пар изображений лиц.
Какова роль логистической регрессии в обучении функций сходства для распознавания лиц?
Логистическая регрессия отображает различия между вкраплениями из сиамских сетей в балл вероятности. Этот показатель оценивает вероятность того, что два лица - это один и тот же человек, поддерживая бинарное решение.
Похожие вопросы
Как этот подход с использованием сиамских сетей сопоставляется с традиционными методами, такими как triplet loss?
Традиционные методы, такие как triplet loss, направлены на изучение пространства встраивания, в котором лица одного и того же человека находятся ближе, а лица разных людей - дальше друг от друга. Сиамские сети, структурированные для бинарной классификации, сосредоточены на проверке идентичности двух лиц, что дает вычислительные преимущества. Выбор оптимального варианта зависит от конкретного приложения и характеристик набора данных.
Существуют ли другие методы оценки сходства вкраплений?
Да, альтернативные методы включают косинусоидальное сходство, евклидово расстояние и сходство по критерию хи-квадрат. Формула сходства по критерию хи-квадрат предлагает другой подход к распознаванию лиц. Каждый метод имеет свои сильные стороны и подходит для разных типов данных и случаев использования. Например, косинусное сходство хорошо работает с высокоразмерными данными, а евклидово расстояние эффективно в более низких измерениях.
Что нужно сделать, чтобы развернуть обученную систему?
Развертывание подразумевает предварительный расчет вкраплений, чтобы избежать хранения необработанных изображений. Система, построенная на архитектуре сиамской сети, предназначена для эффективного сравнения этих вкраплений.
Связанная статья
 Meituan представила трехлетнюю дорожную карту по развитию искусственного интеллекта для усовершенствования бизнес-аналитики
На фоне стремительного развития интернет-технологий искусственный интеллект стал одним из приоритетных направлений деятельности крупнейших компаний. Meituan, ведущая платформа по предоставлению услуг
Canva планирует выйти на биржу в следующем году и перейти к экосистеме дизайна на базе искусственного интеллекта
Canva, «единорог» в сфере программного обеспечения для дизайна, планирует официально начать процесс IPO в следующем году. Этот шаг знаменует вступление компании в решающую фазу привлечения капитала на
Hightouch достигла годового повторяемого дохода (ARR) в 100 млн долларов благодаря маркетинговым инструментам на базе искусственного интеллекта
Раньше маркетологи полагались на дизайнеров и других креативных специалистов при создании изображений и видеороликов для персонализированных рекламных кампаний в Интернете.В конце 2024 года семилетний
Рекомендации по связанным специальным темам
Образование и обучение
Meituan представила трехлетнюю дорожную карту по развитию искусственного интеллекта для усовершенствования бизнес-аналитики
На фоне стремительного развития интернет-технологий искусственный интеллект стал одним из приоритетных направлений деятельности крупнейших компаний. Meituan, ведущая платформа по предоставлению услуг
Canva планирует выйти на биржу в следующем году и перейти к экосистеме дизайна на базе искусственного интеллекта
Canva, «единорог» в сфере программного обеспечения для дизайна, планирует официально начать процесс IPO в следующем году. Этот шаг знаменует вступление компании в решающую фазу привлечения капитала на
Hightouch достигла годового повторяемого дохода (ARR) в 100 млн долларов благодаря маркетинговым инструментам на базе искусственного интеллекта
Раньше маркетологи полагались на дизайнеров и других креативных специалистов при создании изображений и видеороликов для персонализированных рекламных кампаний в Интернете.В конце 2024 года семилетний
Рекомендации по связанным специальным темам
Образование и обучение
 Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
 10 инструментов
10 инструментов
 xix.ai
чат-бот
Лучшие тренажеры по флирту и общению на базе ИИ: повышайте свою харизму и уверенность в себе в режиме реального времени
xix.ai
чат-бот
Лучшие тренажеры по флирту и общению на базе ИИ: повышайте свою харизму и уверенность в себе в режиме реального времени
Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai
код
Лучшие инструменты ИИ для автоматизированного тестирования модулей: создание случаев тестирования Jest, PyTest и JUnit одним кликом
Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
10 инструментов
xix.ai
Анализ данных
Лучшие инструменты для визуализации данных с помощью ИИ: автоматическое создание интерактивных панелей BI на основе исходных файлов
Откройте для себя лучшие инструменты визуализации данных на базе ИИ 2026 года на сайте XIX.AI. Наша тщательно отобранная подборка лидеров рейтинга поможет вам мгновенно создавать мощные интерактивные информационные панели BI на основе необработанных файлов. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Раскройте потенциал ваших данных уже сегодня.
10 инструментов
xix.ai
Социальные сети
Наборы материалов для продвижения бренда в социальных сетях с использованием ИИ: обеспечение единообразия визуального стиля бренда во всех каналах
Откройте для себя лучшие наборы материалов для брендинга на базе ИИ в социальных сетях 2026 года. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, которые помогут обеспечить идеальную визуальную согласованность бренда во всех каналах. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте визуальный потенциал вашего бренда уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие приложения с виртуальными подругами на базе ИИ и инструменты для ролевых игр с ИИ-компаньонами (руководство 2026 года)
Откройте для себя 2026 лучших инструментов с искусственным интеллектом для увлекательных ролевых игр и общения. В тщательно составленном руководстве XIX.AI представлены мощные приложения, которые кардинально меняют правила игры, с еженедельно обновляемым рейтингом, сравнением бесплатных и платных версий, а также результатами реальных тестов. Найдите идеальный вариант и начните наслаждаться полноценным цифровым общением уже сегодня.
10 инструментов
xix.ai

 Комментарии (2)
Комментарии (2)
![PaulMartínez]()
Interessant, dass hier Siamese Networks und binäre Klassifikation verglichen werden. Ich frage mich, ob die Wahl je nach Anwendungsfall variieren sollte – vielleicht ist der eine Ansatz für Sicherheitssysteme besser, der andere für Social Media? 🤔 Die Diskussion um Triplet Loss vs. Alternativen zeigt, wie dynamisch das Feld noch ist. Hoffentlich bleibt die Ethik dabei nicht auf der Strecke, gerade bei Gesichtserkennung.
![JohnRoberts]()
¿Redes Siamesas vs. clasificación binaria en 2025? Me pregunto si esto afectará cómo funcionan los desbloqueos faciales en nuestros móviles 🤔 ¿Será más rápido o más seguro? Alguien que sepa del tema que comente!
Распознавание лиц играет важную роль в самых разных приложениях - от систем безопасности до социальных сетей. В то время как триплетные потери являются широко используемым методом обучения сверточных нейронных сетей (CNN) для этих целей, альтернативная стратегия рассматривает задачу как проблему бинарной классификации. Этот подход использует сиамские сети, обеспечивая особый способ обучения параметров, необходимых для эффективной верификации лиц. Ниже мы рассмотрим, как это достигается путем использования пары нейронных сетей для генерации вкраплений.
Ключевые моменты
Сиамские сети эффективны для верификации лиц.
Распознавание лиц можно смоделировать как задачу бинарной классификации.
Обучение функций сходства включает в себя логистическую регрессию.
Предварительное вычисление вкраплений повышает эффективность развертывания.
Процессы включают сбор данных, обучение модели, оценку и развертывание.
Как верификация, так и распознавание лиц могут быть обучены с использованием бинарной классификации в качестве альтернативы триплетным потерям.
Понятие распознавания и верификации лиц
Распознавание лиц как бинарная классификация
Распознавание лиц - это не просто идентификация человека, а проверка его личности. Это известно как верификация лица. Один из практических подходов рассматривает верификацию как задачу бинарной классификации. Вместо того чтобы различать множество лиц, система отвечает на простой вопрос: "Принадлежат ли эти два лица одному и тому же человеку?". Такое двоичное представление упрощает задачу и повышает эффективность вычислений. В основе метода лежит сиамская сеть, состоящая из двух идентичных нейронных сетей с общими весами и архитектурой. Каждая сеть обрабатывает одно входное изображение, а их выходы сравниваются для получения оценки сходства. Если этот показатель превышает определенный порог, лица считаются совпадающими, в противном случае они классифицируются как разные. Сеть обучена выдавать 1 для совпадающих лиц и 0 для несовпадающих. Это отличается от более сложных систем, которые должны различать широкий спектр известных лиц.
Архитектура сиамской сети
В основе метода лежит архитектура сиамской сети.
Эта архитектура объединяет две идентичные нейронные сети, каждая из которых обрабатывает одно из двух входных изображений. Эти сети вычисляют вкрапления, которые представляют собой высокоразмерные векторы, кодирующие уникальные черты лица. Сравнивая эти вкрапления, система оценивает сходство лиц. Процесс встраивания обычно включает в себя конволюционный, объединяющий и полностью связанный слои, каждый из которых извлекает из изображения все более сложные черты. В итоге получается вектор, часто 128-мерный, который отражает основные характеристики лица. Для выявления более тонких деталей могут использоваться и более крупные размеры. Очень важно, что обе сети в сиамской системе имеют одинаковые параметры, что гарантирует, что вкрапления генерируются в ходе одного и того же процесса извлечения признаков и являются непосредственно сравнимыми.
Обучение функций сходства с помощью логистической регрессии
Использование логистической регрессии
Чтобы определить, представляют ли два лица одного и того же человека, необходимо сравнить вкрапления из сиамской сети. Блок логистической регрессии применяет сигмоидальную функцию к этим вкраплениям, получая оценку вероятности, которая отражает вероятность совпадения. На вход этого блока подаются не исходные вкрапления, а полученные из них характеристики. Распространенным методом является вычисление абсолютной разницы между двумя вложениями по элементам, при этом выделяются признаки с наибольшим расхождением. Другой используемый метод - сходство по критерию хи-квадрат. Цель состоит в том, чтобы сформировать высокодискриминативные признаки, которые позволят блоку логистической регрессии делать точные прогнозы. Различия по элементам поступают в модель логистической регрессии, которая учится присваивать соответствующие веса. Если различия минимальны, блок присваивает высокую вероятность, указывая на одного и того же человека; если различия значительны, он присваивает низкую вероятность, указывая на разных людей.
Обучение сиамской сети и логистической регрессии
Пошаговый процесс обучения
- Сбор обучающих данных: Начните с составления набора данных изображений лиц с метками, указывающими, изображают ли пары изображений одного и того же человека или разных людей. На этом наборе данных обучаются сиамская сеть и блок логистической регрессии.
- Настройка сиамской сети: Настройте две идентичные CNN с одинаковой архитектурой и общими весами. Эти сети будут учиться генерировать вкрапления из входных изображений лиц.
- Вычисление различий признаков: Определите абсолютные разности между вкраплениями, сгенерированными двумя CNN для каждой пары изображений. Эти различия становятся входными признаками для блока логистической регрессии.
- Интеграция логистической регрессии: Использование модели логистической регрессии для преобразования различий признаков в оценку вероятности, указывающую на совпадение лиц.
- Тонкая настройка: Уточнение слоя логистической регрессии путем корректировки весов, присвоенных признакам (например, в 128-мерном вложении).
- Обучение с обратным распространением: Обучите всю систему - ИНС и блок логистической регрессии - методом обратного распространения. При этом минимизируется функция потерь, которая наказывает ошибки прогнозирования, постепенно повышая точность путем оптимизации весов и смещений сети.
- Настройка весов: Окончательная модель логистической регрессии может включать дополнительные параметры, такие как вес (W) и смещение (B).
- Предварительное вычисление вкраплений: Для ускорения развертывания предварительно вычисляйте вкрапления для быстрого сравнения.
Преимущества и недостатки сиамских сетей для распознавания лиц
Плюсы
Вычислительная эффективность
Непосредственно для верификации лиц
Эффективное извлечение признаков
Cons
Требования к обучающим данным
Возможность переоценки
Ограниченная генерализация
Часто задаваемые вопросы
Что такое сиамские сети и как они работают при распознавании лиц?
Сиамские сети - это нейронные сети, состоящие из двух или более одинаковых подсетей. Каждая подсеть получает отдельный входной сигнал, но имеет общие веса с остальными. При распознавании лиц эти сети обрабатывают пары изображений лиц для получения вкраплений, которые затем оцениваются на предмет сходства.
Почему распознавание лиц иногда рассматривается как проблема бинарной классификации?
Если рассматривать распознавание лиц как задачу бинарной классификации, то это упрощает задачу до определения совпадения двух лиц, что повышает эффективность по сравнению с распознаванием множества лиц. Этот метод использует сиамские сети для сравнения пар изображений лиц.
Какова роль логистической регрессии в обучении функций сходства для распознавания лиц?
Логистическая регрессия отображает различия между вкраплениями из сиамских сетей в балл вероятности. Этот показатель оценивает вероятность того, что два лица - это один и тот же человек, поддерживая бинарное решение.
Похожие вопросы
Как этот подход с использованием сиамских сетей сопоставляется с традиционными методами, такими как triplet loss?
Традиционные методы, такие как triplet loss, направлены на изучение пространства встраивания, в котором лица одного и того же человека находятся ближе, а лица разных людей - дальше друг от друга. Сиамские сети, структурированные для бинарной классификации, сосредоточены на проверке идентичности двух лиц, что дает вычислительные преимущества. Выбор оптимального варианта зависит от конкретного приложения и характеристик набора данных.
Существуют ли другие методы оценки сходства вкраплений?
Да, альтернативные методы включают косинусоидальное сходство, евклидово расстояние и сходство по критерию хи-квадрат. Формула сходства по критерию хи-квадрат предлагает другой подход к распознаванию лиц. Каждый метод имеет свои сильные стороны и подходит для разных типов данных и случаев использования. Например, косинусное сходство хорошо работает с высокоразмерными данными, а евклидово расстояние эффективно в более низких измерениях.
Что нужно сделать, чтобы развернуть обученную систему?
Развертывание подразумевает предварительный расчет вкраплений, чтобы избежать хранения необработанных изображений. Система, построенная на архитектуре сиамской сети, предназначена для эффективного сравнения этих вкраплений.










 Meituan представила трехлетнюю дорожную карту по развитию искусственного интеллекта для усовершенствования бизнес-аналитики
На фоне стремительного развития интернет-технологий искусственный интеллект стал одним из приоритетных направлений деятельности крупнейших компаний. Meituan, ведущая платформа по предоставлению услуг
Meituan представила трехлетнюю дорожную карту по развитию искусственного интеллекта для усовершенствования бизнес-аналитики
На фоне стремительного развития интернет-технологий искусственный интеллект стал одним из приоритетных направлений деятельности крупнейших компаний. Meituan, ведущая платформа по предоставлению услуг
 Canva планирует выйти на биржу в следующем году и перейти к экосистеме дизайна на базе искусственного интеллекта
Canva, «единорог» в сфере программного обеспечения для дизайна, планирует официально начать процесс IPO в следующем году. Этот шаг знаменует вступление компании в решающую фазу привлечения капитала на
Canva планирует выйти на биржу в следующем году и перейти к экосистеме дизайна на базе искусственного интеллекта
Canva, «единорог» в сфере программного обеспечения для дизайна, планирует официально начать процесс IPO в следующем году. Этот шаг знаменует вступление компании в решающую фазу привлечения капитала на
 Hightouch достигла годового повторяемого дохода (ARR) в 100 млн долларов благодаря маркетинговым инструментам на базе искусственного интеллекта
Раньше маркетологи полагались на дизайнеров и других креативных специалистов при создании изображений и видеороликов для персонализированных рекламных кампаний в Интернете.В конце 2024 года семилетний
Hightouch достигла годового повторяемого дохода (ARR) в 100 млн долларов благодаря маркетинговым инструментам на базе искусственного интеллекта
Раньше маркетологи полагались на дизайнеров и других креативных специалистов при создании изображений и видеороликов для персонализированных рекламных кампаний в Интернете.В конце 2024 года семилетний

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
10 инструментов
xix.ai

Откройте для себя лучшие инструменты визуализации данных на базе ИИ 2026 года на сайте XIX.AI. Наша тщательно отобранная подборка лидеров рейтинга поможет вам мгновенно создавать мощные интерактивные информационные панели BI на основе необработанных файлов. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Раскройте потенциал ваших данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие наборы материалов для брендинга на базе ИИ в социальных сетях 2026 года. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, которые помогут обеспечить идеальную визуальную согласованность бренда во всех каналах. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте визуальный потенциал вашего бренда уже сегодня.
10 инструментов
xix.ai

Откройте для себя 2026 лучших инструментов с искусственным интеллектом для увлекательных ролевых игр и общения. В тщательно составленном руководстве XIX.AI представлены мощные приложения, которые кардинально меняют правила игры, с еженедельно обновляемым рейтингом, сравнением бесплатных и платных версий, а также результатами реальных тестов. Найдите идеальный вариант и начните наслаждаться полноценным цифровым общением уже сегодня.
10 инструментов
xix.ai

Interessant, dass hier Siamese Networks und binäre Klassifikation verglichen werden. Ich frage mich, ob die Wahl je nach Anwendungsfall variieren sollte – vielleicht ist der eine Ansatz für Sicherheitssysteme besser, der andere für Social Media? 🤔 Die Diskussion um Triplet Loss vs. Alternativen zeigt, wie dynamisch das Feld noch ist. Hoffentlich bleibt die Ethik dabei nicht auf der Strecke, gerade bei Gesichtserkennung.
¿Redes Siamesas vs. clasificación binaria en 2025? Me pregunto si esto afectará cómo funcionan los desbloqueos faciales en nuestros móviles 🤔 ¿Será más rápido o más seguro? Alguien que sepa del tema que comente!













