
















 Maison
Maison
Comment fonctionnent les réseaux neuronaux convolutifs (CNN) en 2025 ? Un guide visuel complet.
Les réseaux neuronaux convolutifs (CNN) ont transformé la vision par ordinateur, permettant aux machines d'interpréter les images avec une précision incroyable. Ce guide détaillé examine le fonctionnement des CNN, en clarifiant les noyaux, les couches convolutives et la manière dont ces systèmes parviennent à des conclusions. À l'aide d'exemples pratiques et d'outils de visualisation, nous révélons les capacités de cette technologie fondamentale, de l'analyse des images aux implémentations de codage.
Points clés
Les CNN préservent la structure bidimensionnelle des images à l'aide de noyaux.
Les noyaux fonctionnent comme des filtres qui identifient des caractéristiques spécifiques de l'image.
Les couches convolutives appliquent ces filtres aux images pour produire des cartes de caractéristiques.
Plusieurs couches convolutives se combinent pour détecter des motifs visuels complexes.
Les couches de mise en commun rationalisent les cartes de caractéristiques en réduisant leurs dimensions.
CNN Explainer fournit une démonstration visuelle du fonctionnement de ces réseaux.
Keras, intégré à TensorFlow, simplifie le processus de codage des couches CNN.
L'aplatissement prépare les données pour les couches denses qui gèrent la classification finale.
L'ajustement de la taille du noyau a un impact direct sur la qualité de la détection des caractéristiques.
Les GPU ou TPU accélèrent l'apprentissage du CNN pour de meilleures performances.
Présentation des réseaux neuronaux convolutifs
Qu'est-ce qu'un réseau neuronal convolutif (CNN) ?
Les réseaux neuronaux convolutifs (CNN) sont des réseaux neuronaux artificiels spécialisés conçus pour traiter les informations visuelles. Contrairement aux réseaux conventionnels qui traitent les images comme des tableaux de pixels plats, les réseaux neuronaux convolutifs utilisent les relations spatiales entre les pixels. Cette capacité est essentielle pour la classification des images, la détection des objets et les tâches de segmentation.

Les CNN s'inspirent du fonctionnement du cortex visuel humain. Ils utilisent des couches spécialisées pour apprendre progressivement des hiérarchies de caractéristiques spatiales, en partant d'éléments de base comme les bords et les coins jusqu'à des représentations d'objets avancées.
Principaux composants des CNN :
- Les couches convolutives : Ces composants fondamentaux utilisent des noyaux (ou filtres) pour détecter les caractéristiques des images d'entrée.
- Couches de mise en commun : Ces couches réduisent la taille des représentations, en diminuant le nombre de paramètres et les exigences de calcul, tout en assurant l'invariance de la traduction.
- Fonctions d'activation : Les fonctions non linéaires telles que ReLU permettent aux réseaux de reconnaître des modèles complexes.
- Couches entièrement connectées : Placées à l'extrémité du réseau, ces couches effectuent une classification en utilisant les caractéristiques recueillies dans les couches précédentes.
Le principal avantage des CNN réside dans l'apprentissage automatique des caractéristiques à partir des données, ce qui élimine les processus d'extraction manuelle. Cela les rend exceptionnellement efficaces pour diverses applications de vision par ordinateur. Leurs couches convolutives uniques les distinguent des autres types de réseaux neuronaux.
L'importance de conserver les informations 2D
Les réseaux neuronaux traditionnels convertissent généralement les images en tableaux de pixels unidimensionnels, sacrifiant ainsi la structure bidimensionnelle cruciale et les relations de voisinage. Imaginez que vous essayiez de comprendre une peinture en ne connaissant que les couleurs des points individuels sans voir leur disposition - vous manqueriez le contexte et la composition globale.
Les CNN tirent leur force de la préservation de cette structure bidimensionnelle. En employant des noyaux qui analysent des régions localisées de l'image, le réseau capture les dépendances spatiales entre les pixels. Cela permet d'identifier avec précision les bords, les coins et les textures, quelle que soit leur position dans l'image.
Cons
ider une tasse de café. Notre cerveau l'identifie comme une tasse à café, qu'elle soit placée à gauche ou à droite. Les CNN imitent cette capacité. En conservant les informations 2D, les CNN deviennent plus résistants aux variations de positionnement, d'échelle et d'orientation des objets. Cette connaissance de l'espace améliore considérablement la capacité du réseau à généraliser et à obtenir des résultats précis sur des données inconnues.Noyaux : Les extracteurs de caractéristiques
Le noyau constitue le cœur de chaque couche convolutive. Il s'agit d'une matrice de poids compacte qui sert de détecteur de motifs. Il s'agit d'une matrice de poids compacte qui sert de détecteur de modèle. Chaque noyau identifie des caractéristiques spécifiques telles que les bords, les coins ou les textures.
Un noyau est fondamentalement une matrice de poids. Chaque valeur de la matrice contient un poids qui se multiplie avec les pixels correspondants de l'image d'entrée, ce qui permet de capturer la structure photographique en 2D pour l'extraction d'informations.
Le noyau parcourt l'image d'entrée, exécutant des opérations de convolution à chaque endroit. Au cours de ce processus, chaque élément du noyau se multiplie avec les valeurs des pixels correspondants dans les régions locales de l'image. Ces produits s'additionnent pour créer des valeurs uniques qui alimentent la carte des caractéristiques de sortie.
En ajustant précisément les poids des noyaux, le réseau apprend à reconnaître les caractéristiques pertinentes pour la tâche. Par exemple, le noyau d'un détecteur de bords horizontaux contient des poids positifs le long d'une ligne horizontale et des poids négatifs au-dessus et en dessous de celle-ci.
Les noyaux fonctionnent donc comme des mécanismes de filtrage pour l'extraction d'informations.
La couche convolutive en action
La couche convolutive applique des noyaux à l'ensemble des images d'entrée. Cette approche par fenêtre coulissante, combinée à la convolution, permet de détecter des caractéristiques sur l'ensemble de l'image.
Lorsque les noyaux se déplacent sur les images, ils génèrent des cartes de caractéristiques indiquant la présence et l'intensité des caractéristiques détectées. Chaque valeur de carte de caractéristiques correspond à un emplacement de l'image d'entrée, l'ampleur reflétant le degré de correspondance entre le modèle du noyau et le contenu local de l'image.
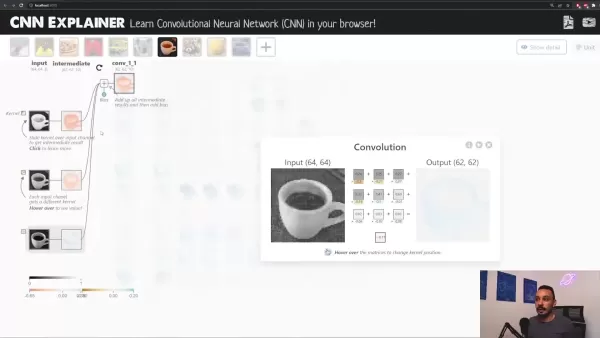
Considérons le positionnement de notre noyau au premier coin de l'image, qui comprend six pixels. Les poids du noyau se multiplient avec ces pixels et la somme devient un seul pixel dans la nouvelle image. Ce processus ressemble à l'application de filtres d'image.
Les différents noyaux d'une même couche convolutive détectent des caractéristiques distinctes. Ces caractéristiques créent collectivement des représentations complètes de l'image. L'application de plusieurs noyaux pour générer diverses cartes de caractéristiques permet aux CNN d'apprendre des modèles visuels complexes.
En résumé, chaque noyau se réplique sur plusieurs canaux au cours de la formation.
Mise en commun des couches : Simplifier la représentation
Les couches de mise en commun réduisent considérablement les dimensions spatiales des cartes de caractéristiques issues des couches convolutives. Cette réduction de la dimensionnalité sert plusieurs objectifs :
- Réduction des calculs : La réduction de la taille des cartes de caractéristiques diminue considérablement les paramètres et la complexité de calcul.
- Invariance de la traduction : Les couches de mise en commun aident les réseaux à devenir insensibles aux changements mineurs de l'entrée. Par exemple, la mise en commun maximale sélectionne les valeurs maximales des régions locales, réduisant ainsi la sensibilité au positionnement exact des caractéristiques.
- Généralisation améliorée : En résumant les informations relatives aux régions locales, le pooling favorise l'apprentissage de caractéristiques robustes et généralisables qui résistent à l'overfitting.

La mise en commun maximale extrait les valeurs maximales, moyennes ou minimales des groupes de pixels. Avec une définition de pool 2x2, quatre pixels sont réduits à deux, ce qui divise par deux le nombre de pixels tout en préservant les informations essentielles.
Les variantes de pooling les plus courantes sont le pooling max, le pooling average et le pooling min. Le pooling max prévaut particulièrement pour son efficacité à préserver les caractéristiques cruciales lors de la réduction de la dimensionnalité. Cela permet de maintenir l'efficacité tout en conservant des représentations précises.
Visualiser les CNN avec CNN Explainer
Exploiter CNN Explainer pour une meilleure compréhension
Comprendre les processus internes des CNN peut s'avérer difficile. Heureusement, des outils comme CNN Explainer offrent des interfaces visuelles qui clarifient les opérations du réseau.

CNN Explainer permet de visualiser les transformations de chaque couche, ce qui en fait un excellent outil pédagogique pour comprendre les réseaux neuronaux convolutifs.
Avantages de l'utilisation de CNN Explainer :
- Visualisation des cartes de caractéristiques : Observez les cartes de caractéristiques de chaque couche convolutive pour comprendre les modèles appris par le réseau.
- Comprendre les opérations du noyau : Survolez les matrices pour observer les effets des noyaux sur les images d'entrée et leurs contributions aux cartes de caractéristiques.
- Explorer différentes architectures : Testez différentes configurations de CNN et observez leurs effets sur les caractéristiques apprises.
Grâce à son interface visuelle interactive, CNN Explainer facilite la compréhension des fonctionnalités des CNN.
Codage des CNN avec Keras
Étapes de codage d'un modèle Conv2D
Programmer des CNN à partir de zéro peut être exigeant. Des frameworks comme Keras - étroitement intégré à TensorFlow - simplifient ce processus grâce à des API de haut niveau pour la définition et l'entraînement des réseaux.
Commencez par configurer TensorFlow. Procédez ensuite aux étapes suivantes :
- Ajoutez une couche de convolution 2D.
- Spécifiez la quantité de filtres souhaitée.
- Définissez le nombre de filtres (par exemple, 10 pour un CNN de démonstration).
- Définissez les spécifications du noyau et les dimensions d'entrée.
L'utilisation de ces API de haut niveau permet de développer rapidement des CNN puissants pour diverses applications de vision par ordinateur.
Avantages et inconvénients de l'utilisation des CNN
Avantages
Extraction automatique des caractéristiques : Les CNN apprennent de manière autonome les caractéristiques pertinentes, ce qui minimise les besoins en ingénierie manuelle.
Conscience spatiale : Les CNN conservent les relations spatiales entre les pixels, ce qui leur permet de résister aux changements de position, d'échelle et d'orientation des objets.
Précision élevée : Les CNN offrent des performances de pointe dans de nombreuses tâches de vision artificielle, notamment la classification d'images et la détection d'objets.
Généralisation : Les CNN s'adaptent efficacement aux données non familières, ce qui les rend pratiques pour les implémentations dans le monde réel.
Inconvénients
Complexité informatique : L'apprentissage des CNN nécessite des ressources informatiques considérables, en particulier pour les grands ensembles de données et les architectures complexes.
Exigences en matière de données : Les CNN ont généralement besoin d'un grand nombre de données étiquetées pour obtenir des résultats optimaux.
Interprétabilité : Il peut être difficile de comprendre les processus décisionnels des CNN.
Surajustement : Les CNN sont souvent surajoutés lorsqu'ils sont formés sur des ensembles de données limités.
Questions fréquemment posées
Quelles sont les principales différences entre les CNN et les réseaux neuronaux traditionnels ?
Les CNN sont spécialisés dans le traitement des données visuelles tout en conservant les relations spatiales 2D, alors que les réseaux traditionnels traitent les images comme des tableaux 1D. Les CNN automatisent également l'apprentissage des caractéristiques, contrairement aux réseaux traditionnels qui nécessitent souvent une ingénierie manuelle des caractéristiques.
Quel est le rôle des fonctions d'activation dans les CNN ?
Les fonctions d'activation introduisent la non-linéarité, ce qui permet une reconnaissance complexe des formes. Sans elles, les réseaux ne comprendraient que des relations linéaires, ce qui limiterait leur potentiel de résolution de problèmes.
Pourquoi Google Colab est-il recommandé pour l'entraînement des CNN ?
L'entraînement des CNN nécessite des calculs intensifs. Google Colab offre un accès gratuit aux GPU et TPU, ce qui accélère considérablement la formation par rapport aux processeurs standard.
Questions connexes
Les CNN peuvent-ils être utilisés pour des tâches autres que la reconnaissance d'images ?
Bien que les CNN excellent dans la vision par ordinateur, ils s'adaptent à d'autres domaines tels que le traitement du langage naturel et l'analyse audio. Ces applications convertissent les données d'entrée en structures de type grille pouvant être traitées par des couches convolutives. Dans le traitement du langage naturel, par exemple, le texte devient une matrice où les lignes représentent les mots et les colonnes les caractéristiques telles que les enchâssements de mots. Le principe sous-jacent persiste : Les CNN extraient de manière remarquable des modèles des régions locales des données d'entrée. Leur flexibilité architecturale les rend précieux pour diverses applications d'apprentissage automatique.
Article connexe
 China Telecom investit dans Mianbi Intelligence et porte son capital à 713 000 yuans pour développer des modèles de langage de grande envergure (LLM) et une infrastructure de données
L'«équipe nationale» et la figure de proue de l'université Tsinghua dans le domaine des grands modèles renforcent leur alliance stratégique. Le 1er mars 2026, selon les dernières données d'enregistrem
Le groupe Taotian accélère sa restructuration axée sur l'IA et offre des quotas de jetons gratuits à ses stagiaires
Le groupe TaoTian a récemment lancé le « Plan de productivité IA », conçu pour accélérer l'intégration de la technologie IA dans les opérations de commerce électronique et les processus de R&D grâce à
Glean vise les infrastructures d'IA d'entreprise dans une course à l'acquisition de parts de marché
La course à la domination du marché de l'IA d'entreprise s'accélère. Microsoft intègre Copilot à Office, Google intègre Gemini à Workspace, tandis qu'OpenAI et Anthropic commercialisent leurs produits
Recommandations de sujets spéciaux liés
en écrivant
China Telecom investit dans Mianbi Intelligence et porte son capital à 713 000 yuans pour développer des modèles de langage de grande envergure (LLM) et une infrastructure de données
L'«équipe nationale» et la figure de proue de l'université Tsinghua dans le domaine des grands modèles renforcent leur alliance stratégique. Le 1er mars 2026, selon les dernières données d'enregistrem
Le groupe Taotian accélère sa restructuration axée sur l'IA et offre des quotas de jetons gratuits à ses stagiaires
Le groupe TaoTian a récemment lancé le « Plan de productivité IA », conçu pour accélérer l'intégration de la technologie IA dans les opérations de commerce électronique et les processus de R&D grâce à
Glean vise les infrastructures d'IA d'entreprise dans une course à l'acquisition de parts de marché
La course à la domination du marché de l'IA d'entreprise s'accélère. Microsoft intègre Copilot à Office, Google intègre Gemini à Workspace, tandis qu'OpenAI et Anthropic commercialisent leurs produits
Recommandations de sujets spéciaux liés
en écrivant
 Les meilleurs assistants IA pour les genres xianxia et wuxia : rédigez des récits épiques de progression spirituelle et des chorégraphies d'arts martiaux
Les meilleurs assistants IA pour les genres xianxia et wuxia : rédigez des récits épiques de progression spirituelle et des chorégraphies d'arts martiaux
Découvrez les meilleurs assistants IA de 2026 pour créer des récits épiques de xianxia et de wuxia. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants pour maîtriser la progression dans la voie de la cultivation et la chorégraphie des arts martiaux. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez à écrire dès aujourd'hui !
 10 outils
10 outils
 xix.ai
code
Outils de codage pour applications mobiles AI : générer du code Flutter et React Native multiplateforme à partir de commandes.
xix.ai
code
Outils de codage pour applications mobiles AI : générer du code Flutter et React Native multiplateforme à partir de commandes.
Découvrez les 20 meilleurs outils de codage pour applications mobiles basées sur l'IA en 2026, conçus pour Flutter et React Native. Notre liste, soigneusement sélectionnée et hautement réputée, met en avant des solutions puissantes qui permettent de générer du code multiplateforme à partir de simples instructions. Comparez les options gratuites et payantes grâce à des tests pratiques. Accélérez votre développement et créez de meilleures applications. Consultez le classement sur XIX.AI dès maintenant !
10 outils
xix.ai
code
Les meilleurs générateurs d'extensions Chrome basés sur l'IA : créez des extensions de navigateur personnalisées sans aucune connaissance en programmation
Découvrez les meilleurs générateurs d'extensions Chrome basés sur l'IA de 2026 sur XIX.AI. Notre sélection comprend les outils les mieux notés et incontournables qui vous permettent de créer des extensions de navigateur personnalisées sans aucune connaissance en programmation. Comparez les options gratuites et payantes, consultez des tests en conditions réelles et boostez votre productivité. Explorez les derniers classements et trouvez l'outil idéal dès aujourd'hui !
10 outils
xix.ai
Synthèse vocale
Meilleur système de synthèse vocale multilingue par intelligence artificielle : génération de discours authentiques avec accent natif dans plus de 50 langues
Découvrez les meilleurs outils de synthèse vocale multilingues basés sur l'IA en 2026, qui permettent d'obtenir des prononciations authentiques avec l'accent natif dans plus de 50 langues. Explorez nos classements sélectionnés, accompagnés de comparaisons entre les versions gratuites et payantes ainsi que de tests réalisés dans le monde réel. Trouvez l'outil vocal idéal sur XIX.AI et déclenchez dès aujourd'hui une communication mondiale sans limites.
10 outils
xix.ai
Assistante de réunion
Meilleurs outils d'automatisation des réunions par intelligence artificielle pour une collaboration plus intelligente et plus rapide
Découvrez les derniers outils d’automatisation de réunions basés sur l’intelligence artificielle, hautement recommandés en 2026, pour une collaboration plus intelligente et plus rapide. Notre sélection met en avant des solutions puissantes et révolutionnaires permettant d’automatiser la prise de notes, la rédaction de résumés et l’organisation des tâches à accomplir. Comparez les options gratuites et payantes grâce à des tests pratiques et aux classements mises à jour chaque semaine. Optimisez ainsi la productivité de votre équipe. Découvrez nos meilleurs choix dès maintenant sur XIX.AI.
10 outils
xix.ai
Rapide
Suggestions d'IA pour l'infrastructure en tant que code : déployez en toute sécurité les configurations Terraform et Docker
Découvrez les meilleures suggestions d'IA de 2026 pour l'Infrastructure-as-Code. La sélection soigneusement préparée par XIX.AI vous aide à déployer en toute sécurité des configurations Terraform et Docker, à automatiser les configurations cloud et à booster la productivité DevOps. Comparez les options gratuites et payantes grâce à des tests concrets. Explorez dès maintenant et exploitez tout le potentiel de l'IA.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Les réseaux neuronaux convolutifs (CNN) ont transformé la vision par ordinateur, permettant aux machines d'interpréter les images avec une précision incroyable. Ce guide détaillé examine le fonctionnement des CNN, en clarifiant les noyaux, les couches convolutives et la manière dont ces systèmes parviennent à des conclusions. À l'aide d'exemples pratiques et d'outils de visualisation, nous révélons les capacités de cette technologie fondamentale, de l'analyse des images aux implémentations de codage.
Points clés
Les CNN préservent la structure bidimensionnelle des images à l'aide de noyaux.
Les noyaux fonctionnent comme des filtres qui identifient des caractéristiques spécifiques de l'image.
Les couches convolutives appliquent ces filtres aux images pour produire des cartes de caractéristiques.
Plusieurs couches convolutives se combinent pour détecter des motifs visuels complexes.
Les couches de mise en commun rationalisent les cartes de caractéristiques en réduisant leurs dimensions.
CNN Explainer fournit une démonstration visuelle du fonctionnement de ces réseaux.
Keras, intégré à TensorFlow, simplifie le processus de codage des couches CNN.
L'aplatissement prépare les données pour les couches denses qui gèrent la classification finale.
L'ajustement de la taille du noyau a un impact direct sur la qualité de la détection des caractéristiques.
Les GPU ou TPU accélèrent l'apprentissage du CNN pour de meilleures performances.
Présentation des réseaux neuronaux convolutifs
Qu'est-ce qu'un réseau neuronal convolutif (CNN) ?
Les réseaux neuronaux convolutifs (CNN) sont des réseaux neuronaux artificiels spécialisés conçus pour traiter les informations visuelles. Contrairement aux réseaux conventionnels qui traitent les images comme des tableaux de pixels plats, les réseaux neuronaux convolutifs utilisent les relations spatiales entre les pixels. Cette capacité est essentielle pour la classification des images, la détection des objets et les tâches de segmentation.
Les CNN s'inspirent du fonctionnement du cortex visuel humain. Ils utilisent des couches spécialisées pour apprendre progressivement des hiérarchies de caractéristiques spatiales, en partant d'éléments de base comme les bords et les coins jusqu'à des représentations d'objets avancées.
Principaux composants des CNN :
- Les couches convolutives : Ces composants fondamentaux utilisent des noyaux (ou filtres) pour détecter les caractéristiques des images d'entrée.
- Couches de mise en commun : Ces couches réduisent la taille des représentations, en diminuant le nombre de paramètres et les exigences de calcul, tout en assurant l'invariance de la traduction.
- Fonctions d'activation : Les fonctions non linéaires telles que ReLU permettent aux réseaux de reconnaître des modèles complexes.
- Couches entièrement connectées : Placées à l'extrémité du réseau, ces couches effectuent une classification en utilisant les caractéristiques recueillies dans les couches précédentes.
Le principal avantage des CNN réside dans l'apprentissage automatique des caractéristiques à partir des données, ce qui élimine les processus d'extraction manuelle. Cela les rend exceptionnellement efficaces pour diverses applications de vision par ordinateur. Leurs couches convolutives uniques les distinguent des autres types de réseaux neuronaux.
L'importance de conserver les informations 2D
Les réseaux neuronaux traditionnels convertissent généralement les images en tableaux de pixels unidimensionnels, sacrifiant ainsi la structure bidimensionnelle cruciale et les relations de voisinage. Imaginez que vous essayiez de comprendre une peinture en ne connaissant que les couleurs des points individuels sans voir leur disposition - vous manqueriez le contexte et la composition globale.
Les CNN tirent leur force de la préservation de cette structure bidimensionnelle. En employant des noyaux qui analysent des régions localisées de l'image, le réseau capture les dépendances spatiales entre les pixels. Cela permet d'identifier avec précision les bords, les coins et les textures, quelle que soit leur position dans l'image.
Cons
ider une tasse de café. Notre cerveau l'identifie comme une tasse à café, qu'elle soit placée à gauche ou à droite. Les CNN imitent cette capacité. En conservant les informations 2D, les CNN deviennent plus résistants aux variations de positionnement, d'échelle et d'orientation des objets. Cette connaissance de l'espace améliore considérablement la capacité du réseau à généraliser et à obtenir des résultats précis sur des données inconnues.Noyaux : Les extracteurs de caractéristiques
Le noyau constitue le cœur de chaque couche convolutive. Il s'agit d'une matrice de poids compacte qui sert de détecteur de motifs. Il s'agit d'une matrice de poids compacte qui sert de détecteur de modèle. Chaque noyau identifie des caractéristiques spécifiques telles que les bords, les coins ou les textures.
Un noyau est fondamentalement une matrice de poids. Chaque valeur de la matrice contient un poids qui se multiplie avec les pixels correspondants de l'image d'entrée, ce qui permet de capturer la structure photographique en 2D pour l'extraction d'informations.
Le noyau parcourt l'image d'entrée, exécutant des opérations de convolution à chaque endroit. Au cours de ce processus, chaque élément du noyau se multiplie avec les valeurs des pixels correspondants dans les régions locales de l'image. Ces produits s'additionnent pour créer des valeurs uniques qui alimentent la carte des caractéristiques de sortie.
En ajustant précisément les poids des noyaux, le réseau apprend à reconnaître les caractéristiques pertinentes pour la tâche. Par exemple, le noyau d'un détecteur de bords horizontaux contient des poids positifs le long d'une ligne horizontale et des poids négatifs au-dessus et en dessous de celle-ci.
Les noyaux fonctionnent donc comme des mécanismes de filtrage pour l'extraction d'informations.
La couche convolutive en action
La couche convolutive applique des noyaux à l'ensemble des images d'entrée. Cette approche par fenêtre coulissante, combinée à la convolution, permet de détecter des caractéristiques sur l'ensemble de l'image.
Lorsque les noyaux se déplacent sur les images, ils génèrent des cartes de caractéristiques indiquant la présence et l'intensité des caractéristiques détectées. Chaque valeur de carte de caractéristiques correspond à un emplacement de l'image d'entrée, l'ampleur reflétant le degré de correspondance entre le modèle du noyau et le contenu local de l'image.
Considérons le positionnement de notre noyau au premier coin de l'image, qui comprend six pixels. Les poids du noyau se multiplient avec ces pixels et la somme devient un seul pixel dans la nouvelle image. Ce processus ressemble à l'application de filtres d'image.
Les différents noyaux d'une même couche convolutive détectent des caractéristiques distinctes. Ces caractéristiques créent collectivement des représentations complètes de l'image. L'application de plusieurs noyaux pour générer diverses cartes de caractéristiques permet aux CNN d'apprendre des modèles visuels complexes.
En résumé, chaque noyau se réplique sur plusieurs canaux au cours de la formation.
Mise en commun des couches : Simplifier la représentation
Les couches de mise en commun réduisent considérablement les dimensions spatiales des cartes de caractéristiques issues des couches convolutives. Cette réduction de la dimensionnalité sert plusieurs objectifs :
- Réduction des calculs : La réduction de la taille des cartes de caractéristiques diminue considérablement les paramètres et la complexité de calcul.
- Invariance de la traduction : Les couches de mise en commun aident les réseaux à devenir insensibles aux changements mineurs de l'entrée. Par exemple, la mise en commun maximale sélectionne les valeurs maximales des régions locales, réduisant ainsi la sensibilité au positionnement exact des caractéristiques.
- Généralisation améliorée : En résumant les informations relatives aux régions locales, le pooling favorise l'apprentissage de caractéristiques robustes et généralisables qui résistent à l'overfitting.
La mise en commun maximale extrait les valeurs maximales, moyennes ou minimales des groupes de pixels. Avec une définition de pool 2x2, quatre pixels sont réduits à deux, ce qui divise par deux le nombre de pixels tout en préservant les informations essentielles.
Les variantes de pooling les plus courantes sont le pooling max, le pooling average et le pooling min. Le pooling max prévaut particulièrement pour son efficacité à préserver les caractéristiques cruciales lors de la réduction de la dimensionnalité. Cela permet de maintenir l'efficacité tout en conservant des représentations précises.
Visualiser les CNN avec CNN Explainer
Exploiter CNN Explainer pour une meilleure compréhension
Comprendre les processus internes des CNN peut s'avérer difficile. Heureusement, des outils comme CNN Explainer offrent des interfaces visuelles qui clarifient les opérations du réseau.
CNN Explainer permet de visualiser les transformations de chaque couche, ce qui en fait un excellent outil pédagogique pour comprendre les réseaux neuronaux convolutifs.
Avantages de l'utilisation de CNN Explainer :
- Visualisation des cartes de caractéristiques : Observez les cartes de caractéristiques de chaque couche convolutive pour comprendre les modèles appris par le réseau.
- Comprendre les opérations du noyau : Survolez les matrices pour observer les effets des noyaux sur les images d'entrée et leurs contributions aux cartes de caractéristiques.
- Explorer différentes architectures : Testez différentes configurations de CNN et observez leurs effets sur les caractéristiques apprises.
Grâce à son interface visuelle interactive, CNN Explainer facilite la compréhension des fonctionnalités des CNN.
Codage des CNN avec Keras
Étapes de codage d'un modèle Conv2D
Programmer des CNN à partir de zéro peut être exigeant. Des frameworks comme Keras - étroitement intégré à TensorFlow - simplifient ce processus grâce à des API de haut niveau pour la définition et l'entraînement des réseaux.
Commencez par configurer TensorFlow. Procédez ensuite aux étapes suivantes :
- Ajoutez une couche de convolution 2D.
- Spécifiez la quantité de filtres souhaitée.
- Définissez le nombre de filtres (par exemple, 10 pour un CNN de démonstration).
- Définissez les spécifications du noyau et les dimensions d'entrée.
L'utilisation de ces API de haut niveau permet de développer rapidement des CNN puissants pour diverses applications de vision par ordinateur.
Avantages et inconvénients de l'utilisation des CNN
Avantages
Extraction automatique des caractéristiques : Les CNN apprennent de manière autonome les caractéristiques pertinentes, ce qui minimise les besoins en ingénierie manuelle.
Conscience spatiale : Les CNN conservent les relations spatiales entre les pixels, ce qui leur permet de résister aux changements de position, d'échelle et d'orientation des objets.
Précision élevée : Les CNN offrent des performances de pointe dans de nombreuses tâches de vision artificielle, notamment la classification d'images et la détection d'objets.
Généralisation : Les CNN s'adaptent efficacement aux données non familières, ce qui les rend pratiques pour les implémentations dans le monde réel.
Inconvénients
Complexité informatique : L'apprentissage des CNN nécessite des ressources informatiques considérables, en particulier pour les grands ensembles de données et les architectures complexes.
Exigences en matière de données : Les CNN ont généralement besoin d'un grand nombre de données étiquetées pour obtenir des résultats optimaux.
Interprétabilité : Il peut être difficile de comprendre les processus décisionnels des CNN.
Surajustement : Les CNN sont souvent surajoutés lorsqu'ils sont formés sur des ensembles de données limités.
Questions fréquemment posées
Quelles sont les principales différences entre les CNN et les réseaux neuronaux traditionnels ?
Les CNN sont spécialisés dans le traitement des données visuelles tout en conservant les relations spatiales 2D, alors que les réseaux traditionnels traitent les images comme des tableaux 1D. Les CNN automatisent également l'apprentissage des caractéristiques, contrairement aux réseaux traditionnels qui nécessitent souvent une ingénierie manuelle des caractéristiques.
Quel est le rôle des fonctions d'activation dans les CNN ?
Les fonctions d'activation introduisent la non-linéarité, ce qui permet une reconnaissance complexe des formes. Sans elles, les réseaux ne comprendraient que des relations linéaires, ce qui limiterait leur potentiel de résolution de problèmes.
Pourquoi Google Colab est-il recommandé pour l'entraînement des CNN ?
L'entraînement des CNN nécessite des calculs intensifs. Google Colab offre un accès gratuit aux GPU et TPU, ce qui accélère considérablement la formation par rapport aux processeurs standard.
Questions connexes
Les CNN peuvent-ils être utilisés pour des tâches autres que la reconnaissance d'images ?
Bien que les CNN excellent dans la vision par ordinateur, ils s'adaptent à d'autres domaines tels que le traitement du langage naturel et l'analyse audio. Ces applications convertissent les données d'entrée en structures de type grille pouvant être traitées par des couches convolutives. Dans le traitement du langage naturel, par exemple, le texte devient une matrice où les lignes représentent les mots et les colonnes les caractéristiques telles que les enchâssements de mots. Le principe sous-jacent persiste : Les CNN extraient de manière remarquable des modèles des régions locales des données d'entrée. Leur flexibilité architecturale les rend précieux pour diverses applications d'apprentissage automatique.










 China Telecom investit dans Mianbi Intelligence et porte son capital à 713 000 yuans pour développer des modèles de langage de grande envergure (LLM) et une infrastructure de données
L'«équipe nationale» et la figure de proue de l'université Tsinghua dans le domaine des grands modèles renforcent leur alliance stratégique. Le 1er mars 2026, selon les dernières données d'enregistrem
China Telecom investit dans Mianbi Intelligence et porte son capital à 713 000 yuans pour développer des modèles de langage de grande envergure (LLM) et une infrastructure de données
L'«équipe nationale» et la figure de proue de l'université Tsinghua dans le domaine des grands modèles renforcent leur alliance stratégique. Le 1er mars 2026, selon les dernières données d'enregistrem
 Le groupe Taotian accélère sa restructuration axée sur l'IA et offre des quotas de jetons gratuits à ses stagiaires
Le groupe TaoTian a récemment lancé le « Plan de productivité IA », conçu pour accélérer l'intégration de la technologie IA dans les opérations de commerce électronique et les processus de R&D grâce à
Le groupe Taotian accélère sa restructuration axée sur l'IA et offre des quotas de jetons gratuits à ses stagiaires
Le groupe TaoTian a récemment lancé le « Plan de productivité IA », conçu pour accélérer l'intégration de la technologie IA dans les opérations de commerce électronique et les processus de R&D grâce à
 Glean vise les infrastructures d'IA d'entreprise dans une course à l'acquisition de parts de marché
La course à la domination du marché de l'IA d'entreprise s'accélère. Microsoft intègre Copilot à Office, Google intègre Gemini à Workspace, tandis qu'OpenAI et Anthropic commercialisent leurs produits
Glean vise les infrastructures d'IA d'entreprise dans une course à l'acquisition de parts de marché
La course à la domination du marché de l'IA d'entreprise s'accélère. Microsoft intègre Copilot à Office, Google intègre Gemini à Workspace, tandis qu'OpenAI et Anthropic commercialisent leurs produits

Découvrez les meilleurs assistants IA de 2026 pour créer des récits épiques de xianxia et de wuxia. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants pour maîtriser la progression dans la voie de la cultivation et la chorégraphie des arts martiaux. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez à écrire dès aujourd'hui !
10 outils
xix.ai

Découvrez les 20 meilleurs outils de codage pour applications mobiles basées sur l'IA en 2026, conçus pour Flutter et React Native. Notre liste, soigneusement sélectionnée et hautement réputée, met en avant des solutions puissantes qui permettent de générer du code multiplateforme à partir de simples instructions. Comparez les options gratuites et payantes grâce à des tests pratiques. Accélérez votre développement et créez de meilleures applications. Consultez le classement sur XIX.AI dès maintenant !
10 outils
xix.ai

Découvrez les meilleurs générateurs d'extensions Chrome basés sur l'IA de 2026 sur XIX.AI. Notre sélection comprend les outils les mieux notés et incontournables qui vous permettent de créer des extensions de navigateur personnalisées sans aucune connaissance en programmation. Comparez les options gratuites et payantes, consultez des tests en conditions réelles et boostez votre productivité. Explorez les derniers classements et trouvez l'outil idéal dès aujourd'hui !
10 outils
xix.ai

Découvrez les meilleurs outils de synthèse vocale multilingues basés sur l'IA en 2026, qui permettent d'obtenir des prononciations authentiques avec l'accent natif dans plus de 50 langues. Explorez nos classements sélectionnés, accompagnés de comparaisons entre les versions gratuites et payantes ainsi que de tests réalisés dans le monde réel. Trouvez l'outil vocal idéal sur XIX.AI et déclenchez dès aujourd'hui une communication mondiale sans limites.
10 outils
xix.ai

Découvrez les derniers outils d’automatisation de réunions basés sur l’intelligence artificielle, hautement recommandés en 2026, pour une collaboration plus intelligente et plus rapide. Notre sélection met en avant des solutions puissantes et révolutionnaires permettant d’automatiser la prise de notes, la rédaction de résumés et l’organisation des tâches à accomplir. Comparez les options gratuites et payantes grâce à des tests pratiques et aux classements mises à jour chaque semaine. Optimisez ainsi la productivité de votre équipe. Découvrez nos meilleurs choix dès maintenant sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleures suggestions d'IA de 2026 pour l'Infrastructure-as-Code. La sélection soigneusement préparée par XIX.AI vous aide à déployer en toute sécurité des configurations Terraform et Docker, à automatiser les configurations cloud et à booster la productivité DevOps. Comparez les options gratuites et payantes grâce à des tests concrets. Explorez dès maintenant et exploitez tout le potentiel de l'IA.
10 outils
xix.ai













