
















 Heim
HeimGesichtserkennung im Jahr 2025: Siamesische Netze oder binäre Klassifizierung?
Die Gesichtserkennung spielt eine wichtige Rolle in Anwendungen, die von Sicherheitssystemen bis zu sozialen Medien reichen. Während Triplet Loss eine weit verbreitete Methode für das Training von Faltungsneuronalen Netzen (CNNs) zu diesem Zweck ist, stellt eine alternative Strategie die Aufgabe als binäres Klassifikationsproblem dar. Dieser Ansatz nutzt Siamesische Netze, um die für eine effektive Gesichtsüberprüfung erforderlichen Parameter zu erlernen. Im Folgenden wird untersucht, wie dies durch den Einsatz eines Paars neuronaler Netze zur Erzeugung von Einbettungen erreicht werden kann.
Wichtige Punkte
Siamesische Netze sind effektiv für die Gesichtsverifikation.
Die Gesichtserkennung kann als binäre Klassifizierungsaufgabe modelliert werden.
Das Lernen von Ähnlichkeitsfunktionen beinhaltet logistische Regression.
Die Vorberechnung von Einbettungen erhöht die Effizienz des Einsatzes.
Zu den Prozessen gehören Datenerfassung, Modelltraining, Bewertung und Einsatz.
Sowohl die Gesichtsverifikation als auch die Gesichtserkennung können mit binärer Klassifikation als Alternative zu Triplet Loss trainiert werden.
Verständnis von Gesichtserkennung und -verifizierung
Gesichtserkennung als binäre Klassifizierung

Bei der Gesichtserkennung geht es nicht nur um die Identifizierung einer Person, sondern auch um die Überprüfung der behaupteten Identität einer Person. Dies wird als Gesichtsverifizierung bezeichnet. Ein praktischer Ansatz behandelt die Verifizierung als ein binäres Klassifizierungsproblem. Anstatt zwischen vielen Gesichtern zu unterscheiden, beantwortet das System eine einfache Frage: "Gehören diese beiden Gesichter zu ein und derselben Person?" Dieser binäre Rahmen vereinfacht das Problem und verbessert die Berechnungseffizienz. Die Technik basiert auf einem Siamesischen Netz, das aus zwei identischen neuronalen Netzen mit gleichen Gewichten und gleicher Architektur besteht. Jedes Netz verarbeitet ein Eingangsbild, und die Ergebnisse werden miteinander verglichen, um einen Ähnlichkeitswert zu ermitteln. Übersteigt der Wert einen festgelegten Schwellenwert, werden die Gesichter als übereinstimmend betrachtet, andernfalls werden sie als unterschiedlich eingestuft. Das Netz ist so trainiert, dass es bei übereinstimmenden Identitäten 1 und bei nicht übereinstimmenden 0 ausgibt. Dies steht im Gegensatz zu komplexeren Systemen, die eine Vielzahl von bekannten Personen unterscheiden müssen.
Die Architektur des Siamesischen Netzes
Die Methode basiert auf der Architektur des Siamesischen Netzes.
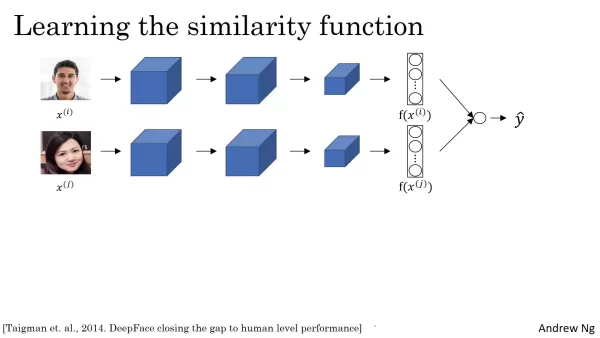
Bei dieser Architektur werden zwei identische neuronale Netze gepaart, die jeweils eines von zwei Eingabebildern verarbeiten. Diese Netzwerke berechnen Einbettungen, d. h. hochdimensionale Vektoren, die einzigartige Gesichtsmerkmale kodieren. Durch den Vergleich dieser Einbettungen bewertet das System die Ähnlichkeit der Gesichter. Der Einbettungsprozess umfasst in der Regel Faltungsschichten, Pooling-Schichten und vollständig verknüpfte Schichten, die jeweils zunehmend kompliziertere Merkmale aus dem Bild extrahieren. Das Endergebnis ist ein Vektor - oft 128-dimensional - der die wesentlichen Gesichtsmerkmale erfasst. Größere Dimensionen können auch verwendet werden, um feinere Details zu erkennen. Entscheidend ist, dass beide Netzwerke in der siamesischen Anordnung identische Parameter haben, wodurch sichergestellt wird, dass die Einbettungen durch denselben Merkmalsextraktionsprozess erzeugt werden und direkt vergleichbar sind.
Lernen von Ähnlichkeitsfunktionen mit logistischer Regression
Logistische Regression verwenden
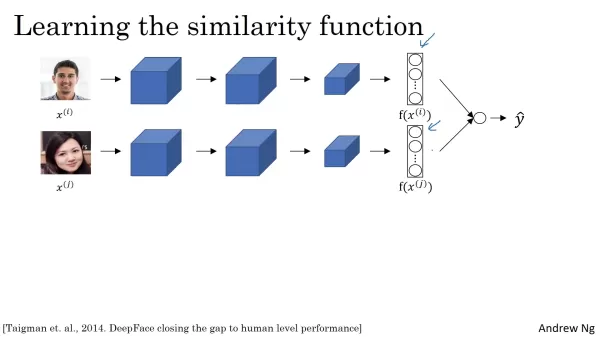
Um festzustellen, ob zwei Gesichter dieselbe Person darstellen, müssen die Einbettungen aus dem siamesischen Netzwerk verglichen werden. Eine logistische Regressionseinheit wendet eine Sigmoidfunktion auf diese Einbettungen an und erzeugt einen Wahrscheinlichkeitswert, der die Wahrscheinlichkeit einer Übereinstimmung widerspiegelt. Die Eingabe für diese Einheit sind nicht die rohen Einbettungen, sondern daraus abgeleitete Merkmale. Eine gängige Methode besteht darin, die elementweise absolute Differenz zwischen den beiden Einbettungen zu berechnen, wobei die Merkmale mit den größten Unterschieden hervorgehoben werden. Die Chi-Quadrat-Ähnlichkeit ist ein weiteres Verfahren. Ziel ist es, hochdiskriminierende Merkmale zu bilden, die es der logistischen Regressionseinheit ermöglichen, präzise Vorhersagen zu treffen. Die elementweisen Unterschiede fließen in das logistische Regressionsmodell ein, das lernt, geeignete Gewichte zuzuweisen. Wenn die Unterschiede minimal sind, weist die Einheit eine hohe Wahrscheinlichkeit zu, was auf dieselbe Person hindeutet; wenn die Unterschiede signifikant sind, weist sie eine niedrige Wahrscheinlichkeit zu, was auf unterschiedliche Personen hindeutet.
Training des Siamesischen Netzes und der logistischen Regression
Schritt-für-Schritt-Trainingsprozess
- Sammeln von Trainingsdaten: Beginnen Sie mit der Zusammenstellung eines Datensatzes von Gesichtsbildern, wobei die Beschriftung angibt, ob die Bildpaare dieselbe Person oder unterschiedliche Personen darstellen. Mit diesem Datensatz werden das Siamesische Netzwerk und die logistische Regression trainiert.
- Einrichten des Siamesischen Netzwerks: Konfigurieren Sie zwei identische CNNs mit der gleichen Architektur und gemeinsamen Gewichten. Diese Netzwerke werden lernen, Einbettungen aus den eingegebenen Gesichtsbildern zu erzeugen.
- Berechnen der Merkmalsunterschiede: Bestimmen Sie die elementweisen absoluten Unterschiede zwischen den Einbettungen, die von den beiden CNNs für jedes Bildpaar erzeugt wurden. Diese Unterschiede werden zu den Eingangsmerkmalen für die logistische Regressionseinheit.
- Integration der logistischen Regression: Verwendung eines logistischen Regressionsmodells, um die Merkmalsunterschiede in eine Wahrscheinlichkeitsbewertung umzuwandeln, die angibt, ob die Gesichter übereinstimmen.
- Feinabstimmung: Verfeinern der logistischen Regressionsschicht durch Anpassen der den Merkmalen zugewiesenen Gewichte (z. B. in einer 128-dimensionalen Einbettung).
- Backpropagation-Training: Trainieren Sie das gesamte System - CNNs und logistische Regressionseinheit - mit Backpropagation. Dadurch wird eine Verlustfunktion minimiert, die Vorhersagefehler bestraft und die Genauigkeit durch Optimierung der Netzwerkgewichte und Verzerrungen schrittweise verbessert.
- Anpassen der Gewichte: Das endgültige logistische Regressionsmodell kann zusätzliche Parameter wie Gewichte (W) und Verzerrungen (B) enthalten.
- Vorberechnung von Einbettungen: Für eine schnellere Bereitstellung können Sie die Einbettungen vorberechnen, um schnelle Vergleiche zu ermöglichen.
Vor- und Nachteile von Siamesischen Netzen für die Gesichtserkennnung
Vorteile
Effiziente Berechnung
Direkte Adressierung der Gesichtsverifikation
Effektive Merkmalsextraktion
Nachteile
Anforderungen an die Trainingsdaten
Potenzielle Überanpassung
Begrenzte Verallgemeinerung
Häufig gestellte Fragen
Was sind Siamesische Netze, und wie funktionieren sie bei der Gesichtserkennung?
Siamesische Netze sind neuronale Netze, die aus zwei oder mehr identischen Teilnetzen bestehen. Jedes Teilnetz erhält eine eigene Eingabe, teilt aber die Gewichte mit den anderen. Bei der Gesichtserkennung verarbeiten diese Netze Paare von Gesichtsbildern, um Einbettungen zu erzeugen, die dann auf Ähnlichkeit geprüft werden.
Warum wird die Gesichtserkennung manchmal als ein binäres Klassifizierungsproblem betrachtet?
Die Betrachtung der Gesichtserkennung als binäres Klassifizierungsproblem vereinfacht sie auf die Feststellung, ob zwei Gesichter übereinstimmen, was die Effizienz im Vergleich zur Unterscheidung zwischen vielen Individuen erhöht. Diese Methode verwendet Siamesische Netze, um Paare von Gesichtsbildern zu vergleichen.
Welche Rolle spielt die logistische Regression beim Lernen von Ähnlichkeitsfunktionen für die Gesichtserkennung?
Bei der logistischen Regression werden die Unterschiede zwischen den Einbettungen der Siamesischen Netze auf einen Wahrscheinlichkeitswert übertragen. Dieser Wert schätzt die Wahrscheinlichkeit, dass es sich bei den beiden Gesichtern um dieselbe Person handelt, und unterstützt eine binäre Entscheidung.
Verwandte Fragen
Wie verhält sich dieser Ansatz des Siamesischen Netzes im Vergleich zu traditionellen Methoden wie Triplet Loss?
Herkömmliche Methoden wie Triplet Loss zielen darauf ab, einen Einbettungsraum zu erlernen, in dem Gesichter derselben Person näher beieinander liegen und Gesichter unterschiedlicher Personen weiter voneinander entfernt sind. Siamesische Netze, die für die binäre Klassifizierung strukturiert sind, konzentrieren sich auf die Überprüfung, ob zwei Gesichter identisch sind, und bieten damit rechnerische Vorteile. Die beste Wahl hängt von der spezifischen Anwendung und den Merkmalen des Datensatzes ab.
Gibt es andere Methoden zur Bewertung der Ähnlichkeit der Einbettungen?
Ja, zu den Alternativen gehören die Kosinus-Ähnlichkeit, der euklidische Abstand und die Chi-Quadrat-Ähnlichkeit. Die Chi-Quadrat-Ähnlichkeitsformel bietet eine weitere Möglichkeit, sich der Gesichtserkennung zu nähern. Jede Technik hat ihre Stärken und eignet sich für unterschiedliche Datentypen und Anwendungsfälle. Die kosinusförmige Ähnlichkeit eignet sich beispielsweise gut für hochdimensionale Daten, während der euklidische Abstand bei niedrigeren Dimensionen effektiv ist.
Wie wird das trainierte System tatsächlich eingesetzt?
Der Einsatz beinhaltet die Vorberechnung von Einbettungen, um die Speicherung von Rohbildern zu vermeiden. Das System, das auf einer Siamesischen Netzwerkarchitektur aufbaut, ist darauf ausgelegt, diese Einbettungen effizient zu vergleichen.
Verwandter Artikel
 China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Glean nimmt die KI-Infrastruktur von Unternehmen ins Visier
Der Wettlauf um die Vorherrschaft im Bereich der Unternehmens-KI gewinnt an Fahrt. Microsoft integriert Copilot in Office, Google bindet Gemini in Workspace ein, und sowohl OpenAI als auch Anthropic v
Empfehlungen zu verwandten Spezialthemen
Schreiben
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Glean nimmt die KI-Infrastruktur von Unternehmen ins Visier
Der Wettlauf um die Vorherrschaft im Bereich der Unternehmens-KI gewinnt an Fahrt. Microsoft integriert Copilot in Office, Google bindet Gemini in Workspace ein, und sowohl OpenAI als auch Anthropic v
Empfehlungen zu verwandten Spezialthemen
Schreiben
 Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
 10 Tools
10 Tools
 xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai
Code
Die besten KI-Generatoren für Chrome-Erweiterungen: Erstellen Sie individuelle Browser-Erweiterungen ganz ohne Programmierkenntnisse
Entdecken Sie die besten KI-Generatoren für Chrome-Erweiterungen des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, unverzichtbare Tools, mit denen Sie ganz ohne Programmierkenntnisse individuelle Browser-Erweiterungen erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich Praxistests an und steigern Sie Ihre Produktivität. Entdecken Sie die aktuellen Rankings und finden Sie noch heute das perfekte Tool für sich!
10 Tools
xix.ai
Text-zu-Sprache
Die beste künstliche Intelligenz für mehrsprachige TTS-Technologie: Erzeugung authentischer Sprache mit Muttersprachakzent in über 50 Sprachen
Entdecken Sie die besten KI-basierten, mehrsprachigen TTS-Tools von 2026 – sie ermöglichen eine authentische Aussprache in natürlicher Muttersprachentonart in über 50 Sprachen. Erfahren Sie mehr über unsere hochrangig bewerteten und sorgfältig ausgewählten Tools, inklusive Vergleichen zwischen kostenlosen und kostenpflichtigen Varianten sowie Ergebnissen aus realen Tests. Finden Sie das perfekte Tool für Ihre Bedürfnisse auf XIX.AI und öffnen Sie so neue Möglichkeiten für die globale Kommunikation – noch heute!
10 Tools
xix.ai
Besprechungsassistent
Die besten AI-Tools für die Automatisierung von Besprechungen – für eine schlauere und schnellere Zusammenarbeit
Entdecken Sie die besten und am meisten bewerteten AI-Tools für die Automatisierung von Besprechungen im Jahr 2026 – sie ermöglichen eine intelligente und schnellere Zusammenarbeit. Unsere sorgfältig ausgewählte Liste bietet leistungsstarke Lösungen, mit denen Sie Notizen, Zusammenfassungen und Aufgaben automatisch erstellen können. Vergleichen Sie kostenlose und bezahlte Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings – so steigern Sie die Produktivität Ihres Teams. Entdecken Sie die besten Tools jetzt bei XIX.AI.
10 Tools
xix.ai
Prompt
KI-Vorgaben für Infrastructure-as-Code: Terraform- und Docker-Konfigurationen sicher bereitstellen
Entdecken Sie die aktuellsten und am besten bewerteten KI-Prompts für Infrastructure-as-Code aus dem Jahr 2026. Die von XIX.AI zusammengestellte Auswahl hilft Ihnen dabei, Terraform- und Docker-Konfigurationen sicher bereitzustellen, Cloud-Setups zu automatisieren und die DevOps-Produktivität zu steigern. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entdecken Sie die Möglichkeiten jetzt und sichern Sie sich Ihren KI-Vorteil.
10 Tools
xix.ai

 Kommentare (2)
Kommentare (2)
![PaulMartínez]()
Interessant, dass hier Siamese Networks und binäre Klassifikation verglichen werden. Ich frage mich, ob die Wahl je nach Anwendungsfall variieren sollte – vielleicht ist der eine Ansatz für Sicherheitssysteme besser, der andere für Social Media? 🤔 Die Diskussion um Triplet Loss vs. Alternativen zeigt, wie dynamisch das Feld noch ist. Hoffentlich bleibt die Ethik dabei nicht auf der Strecke, gerade bei Gesichtserkennung.
![JohnRoberts]()
¿Redes Siamesas vs. clasificación binaria en 2025? Me pregunto si esto afectará cómo funcionan los desbloqueos faciales en nuestros móviles 🤔 ¿Será más rápido o más seguro? Alguien que sepa del tema que comente!
Die Gesichtserkennung spielt eine wichtige Rolle in Anwendungen, die von Sicherheitssystemen bis zu sozialen Medien reichen. Während Triplet Loss eine weit verbreitete Methode für das Training von Faltungsneuronalen Netzen (CNNs) zu diesem Zweck ist, stellt eine alternative Strategie die Aufgabe als binäres Klassifikationsproblem dar. Dieser Ansatz nutzt Siamesische Netze, um die für eine effektive Gesichtsüberprüfung erforderlichen Parameter zu erlernen. Im Folgenden wird untersucht, wie dies durch den Einsatz eines Paars neuronaler Netze zur Erzeugung von Einbettungen erreicht werden kann.
Wichtige Punkte
Siamesische Netze sind effektiv für die Gesichtsverifikation.
Die Gesichtserkennung kann als binäre Klassifizierungsaufgabe modelliert werden.
Das Lernen von Ähnlichkeitsfunktionen beinhaltet logistische Regression.
Die Vorberechnung von Einbettungen erhöht die Effizienz des Einsatzes.
Zu den Prozessen gehören Datenerfassung, Modelltraining, Bewertung und Einsatz.
Sowohl die Gesichtsverifikation als auch die Gesichtserkennung können mit binärer Klassifikation als Alternative zu Triplet Loss trainiert werden.
Verständnis von Gesichtserkennung und -verifizierung
Gesichtserkennung als binäre Klassifizierung
Bei der Gesichtserkennung geht es nicht nur um die Identifizierung einer Person, sondern auch um die Überprüfung der behaupteten Identität einer Person. Dies wird als Gesichtsverifizierung bezeichnet. Ein praktischer Ansatz behandelt die Verifizierung als ein binäres Klassifizierungsproblem. Anstatt zwischen vielen Gesichtern zu unterscheiden, beantwortet das System eine einfache Frage: "Gehören diese beiden Gesichter zu ein und derselben Person?" Dieser binäre Rahmen vereinfacht das Problem und verbessert die Berechnungseffizienz. Die Technik basiert auf einem Siamesischen Netz, das aus zwei identischen neuronalen Netzen mit gleichen Gewichten und gleicher Architektur besteht. Jedes Netz verarbeitet ein Eingangsbild, und die Ergebnisse werden miteinander verglichen, um einen Ähnlichkeitswert zu ermitteln. Übersteigt der Wert einen festgelegten Schwellenwert, werden die Gesichter als übereinstimmend betrachtet, andernfalls werden sie als unterschiedlich eingestuft. Das Netz ist so trainiert, dass es bei übereinstimmenden Identitäten 1 und bei nicht übereinstimmenden 0 ausgibt. Dies steht im Gegensatz zu komplexeren Systemen, die eine Vielzahl von bekannten Personen unterscheiden müssen.
Die Architektur des Siamesischen Netzes
Die Methode basiert auf der Architektur des Siamesischen Netzes.
Bei dieser Architektur werden zwei identische neuronale Netze gepaart, die jeweils eines von zwei Eingabebildern verarbeiten. Diese Netzwerke berechnen Einbettungen, d. h. hochdimensionale Vektoren, die einzigartige Gesichtsmerkmale kodieren. Durch den Vergleich dieser Einbettungen bewertet das System die Ähnlichkeit der Gesichter. Der Einbettungsprozess umfasst in der Regel Faltungsschichten, Pooling-Schichten und vollständig verknüpfte Schichten, die jeweils zunehmend kompliziertere Merkmale aus dem Bild extrahieren. Das Endergebnis ist ein Vektor - oft 128-dimensional - der die wesentlichen Gesichtsmerkmale erfasst. Größere Dimensionen können auch verwendet werden, um feinere Details zu erkennen. Entscheidend ist, dass beide Netzwerke in der siamesischen Anordnung identische Parameter haben, wodurch sichergestellt wird, dass die Einbettungen durch denselben Merkmalsextraktionsprozess erzeugt werden und direkt vergleichbar sind.
Lernen von Ähnlichkeitsfunktionen mit logistischer Regression
Logistische Regression verwenden
Um festzustellen, ob zwei Gesichter dieselbe Person darstellen, müssen die Einbettungen aus dem siamesischen Netzwerk verglichen werden. Eine logistische Regressionseinheit wendet eine Sigmoidfunktion auf diese Einbettungen an und erzeugt einen Wahrscheinlichkeitswert, der die Wahrscheinlichkeit einer Übereinstimmung widerspiegelt. Die Eingabe für diese Einheit sind nicht die rohen Einbettungen, sondern daraus abgeleitete Merkmale. Eine gängige Methode besteht darin, die elementweise absolute Differenz zwischen den beiden Einbettungen zu berechnen, wobei die Merkmale mit den größten Unterschieden hervorgehoben werden. Die Chi-Quadrat-Ähnlichkeit ist ein weiteres Verfahren. Ziel ist es, hochdiskriminierende Merkmale zu bilden, die es der logistischen Regressionseinheit ermöglichen, präzise Vorhersagen zu treffen. Die elementweisen Unterschiede fließen in das logistische Regressionsmodell ein, das lernt, geeignete Gewichte zuzuweisen. Wenn die Unterschiede minimal sind, weist die Einheit eine hohe Wahrscheinlichkeit zu, was auf dieselbe Person hindeutet; wenn die Unterschiede signifikant sind, weist sie eine niedrige Wahrscheinlichkeit zu, was auf unterschiedliche Personen hindeutet.
Training des Siamesischen Netzes und der logistischen Regression
Schritt-für-Schritt-Trainingsprozess
- Sammeln von Trainingsdaten: Beginnen Sie mit der Zusammenstellung eines Datensatzes von Gesichtsbildern, wobei die Beschriftung angibt, ob die Bildpaare dieselbe Person oder unterschiedliche Personen darstellen. Mit diesem Datensatz werden das Siamesische Netzwerk und die logistische Regression trainiert.
- Einrichten des Siamesischen Netzwerks: Konfigurieren Sie zwei identische CNNs mit der gleichen Architektur und gemeinsamen Gewichten. Diese Netzwerke werden lernen, Einbettungen aus den eingegebenen Gesichtsbildern zu erzeugen.
- Berechnen der Merkmalsunterschiede: Bestimmen Sie die elementweisen absoluten Unterschiede zwischen den Einbettungen, die von den beiden CNNs für jedes Bildpaar erzeugt wurden. Diese Unterschiede werden zu den Eingangsmerkmalen für die logistische Regressionseinheit.
- Integration der logistischen Regression: Verwendung eines logistischen Regressionsmodells, um die Merkmalsunterschiede in eine Wahrscheinlichkeitsbewertung umzuwandeln, die angibt, ob die Gesichter übereinstimmen.
- Feinabstimmung: Verfeinern der logistischen Regressionsschicht durch Anpassen der den Merkmalen zugewiesenen Gewichte (z. B. in einer 128-dimensionalen Einbettung).
- Backpropagation-Training: Trainieren Sie das gesamte System - CNNs und logistische Regressionseinheit - mit Backpropagation. Dadurch wird eine Verlustfunktion minimiert, die Vorhersagefehler bestraft und die Genauigkeit durch Optimierung der Netzwerkgewichte und Verzerrungen schrittweise verbessert.
- Anpassen der Gewichte: Das endgültige logistische Regressionsmodell kann zusätzliche Parameter wie Gewichte (W) und Verzerrungen (B) enthalten.
- Vorberechnung von Einbettungen: Für eine schnellere Bereitstellung können Sie die Einbettungen vorberechnen, um schnelle Vergleiche zu ermöglichen.
Vor- und Nachteile von Siamesischen Netzen für die Gesichtserkennnung
Vorteile
Effiziente Berechnung
Direkte Adressierung der Gesichtsverifikation
Effektive Merkmalsextraktion
Nachteile
Anforderungen an die Trainingsdaten
Potenzielle Überanpassung
Begrenzte Verallgemeinerung
Häufig gestellte Fragen
Was sind Siamesische Netze, und wie funktionieren sie bei der Gesichtserkennung?
Siamesische Netze sind neuronale Netze, die aus zwei oder mehr identischen Teilnetzen bestehen. Jedes Teilnetz erhält eine eigene Eingabe, teilt aber die Gewichte mit den anderen. Bei der Gesichtserkennung verarbeiten diese Netze Paare von Gesichtsbildern, um Einbettungen zu erzeugen, die dann auf Ähnlichkeit geprüft werden.
Warum wird die Gesichtserkennung manchmal als ein binäres Klassifizierungsproblem betrachtet?
Die Betrachtung der Gesichtserkennung als binäres Klassifizierungsproblem vereinfacht sie auf die Feststellung, ob zwei Gesichter übereinstimmen, was die Effizienz im Vergleich zur Unterscheidung zwischen vielen Individuen erhöht. Diese Methode verwendet Siamesische Netze, um Paare von Gesichtsbildern zu vergleichen.
Welche Rolle spielt die logistische Regression beim Lernen von Ähnlichkeitsfunktionen für die Gesichtserkennung?
Bei der logistischen Regression werden die Unterschiede zwischen den Einbettungen der Siamesischen Netze auf einen Wahrscheinlichkeitswert übertragen. Dieser Wert schätzt die Wahrscheinlichkeit, dass es sich bei den beiden Gesichtern um dieselbe Person handelt, und unterstützt eine binäre Entscheidung.
Verwandte Fragen
Wie verhält sich dieser Ansatz des Siamesischen Netzes im Vergleich zu traditionellen Methoden wie Triplet Loss?
Herkömmliche Methoden wie Triplet Loss zielen darauf ab, einen Einbettungsraum zu erlernen, in dem Gesichter derselben Person näher beieinander liegen und Gesichter unterschiedlicher Personen weiter voneinander entfernt sind. Siamesische Netze, die für die binäre Klassifizierung strukturiert sind, konzentrieren sich auf die Überprüfung, ob zwei Gesichter identisch sind, und bieten damit rechnerische Vorteile. Die beste Wahl hängt von der spezifischen Anwendung und den Merkmalen des Datensatzes ab.
Gibt es andere Methoden zur Bewertung der Ähnlichkeit der Einbettungen?
Ja, zu den Alternativen gehören die Kosinus-Ähnlichkeit, der euklidische Abstand und die Chi-Quadrat-Ähnlichkeit. Die Chi-Quadrat-Ähnlichkeitsformel bietet eine weitere Möglichkeit, sich der Gesichtserkennung zu nähern. Jede Technik hat ihre Stärken und eignet sich für unterschiedliche Datentypen und Anwendungsfälle. Die kosinusförmige Ähnlichkeit eignet sich beispielsweise gut für hochdimensionale Daten, während der euklidische Abstand bei niedrigeren Dimensionen effektiv ist.
Wie wird das trainierte System tatsächlich eingesetzt?
Der Einsatz beinhaltet die Vorberechnung von Einbettungen, um die Speicherung von Rohbildern zu vermeiden. Das System, das auf einer Siamesischen Netzwerkarchitektur aufbaut, ist darauf ausgelegt, diese Einbettungen effizient zu vergleichen.










 China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
 Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
 Glean nimmt die KI-Infrastruktur von Unternehmen ins Visier
Der Wettlauf um die Vorherrschaft im Bereich der Unternehmens-KI gewinnt an Fahrt. Microsoft integriert Copilot in Office, Google bindet Gemini in Workspace ein, und sowohl OpenAI als auch Anthropic v
Glean nimmt die KI-Infrastruktur von Unternehmen ins Visier
Der Wettlauf um die Vorherrschaft im Bereich der Unternehmens-KI gewinnt an Fahrt. Microsoft integriert Copilot in Office, Google bindet Gemini in Workspace ein, und sowohl OpenAI als auch Anthropic v

Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
10 Tools
xix.ai

Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai

Entdecken Sie die besten KI-Generatoren für Chrome-Erweiterungen des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, unverzichtbare Tools, mit denen Sie ganz ohne Programmierkenntnisse individuelle Browser-Erweiterungen erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich Praxistests an und steigern Sie Ihre Produktivität. Entdecken Sie die aktuellen Rankings und finden Sie noch heute das perfekte Tool für sich!
10 Tools
xix.ai

Entdecken Sie die besten KI-basierten, mehrsprachigen TTS-Tools von 2026 – sie ermöglichen eine authentische Aussprache in natürlicher Muttersprachentonart in über 50 Sprachen. Erfahren Sie mehr über unsere hochrangig bewerteten und sorgfältig ausgewählten Tools, inklusive Vergleichen zwischen kostenlosen und kostenpflichtigen Varianten sowie Ergebnissen aus realen Tests. Finden Sie das perfekte Tool für Ihre Bedürfnisse auf XIX.AI und öffnen Sie so neue Möglichkeiten für die globale Kommunikation – noch heute!
10 Tools
xix.ai

Entdecken Sie die besten und am meisten bewerteten AI-Tools für die Automatisierung von Besprechungen im Jahr 2026 – sie ermöglichen eine intelligente und schnellere Zusammenarbeit. Unsere sorgfältig ausgewählte Liste bietet leistungsstarke Lösungen, mit denen Sie Notizen, Zusammenfassungen und Aufgaben automatisch erstellen können. Vergleichen Sie kostenlose und bezahlte Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings – so steigern Sie die Produktivität Ihres Teams. Entdecken Sie die besten Tools jetzt bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie die aktuellsten und am besten bewerteten KI-Prompts für Infrastructure-as-Code aus dem Jahr 2026. Die von XIX.AI zusammengestellte Auswahl hilft Ihnen dabei, Terraform- und Docker-Konfigurationen sicher bereitzustellen, Cloud-Setups zu automatisieren und die DevOps-Produktivität zu steigern. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entdecken Sie die Möglichkeiten jetzt und sichern Sie sich Ihren KI-Vorteil.
10 Tools
xix.ai

Interessant, dass hier Siamese Networks und binäre Klassifikation verglichen werden. Ich frage mich, ob die Wahl je nach Anwendungsfall variieren sollte – vielleicht ist der eine Ansatz für Sicherheitssysteme besser, der andere für Social Media? 🤔 Die Diskussion um Triplet Loss vs. Alternativen zeigt, wie dynamisch das Feld noch ist. Hoffentlich bleibt die Ethik dabei nicht auf der Strecke, gerade bei Gesichtserkennung.
¿Redes Siamesas vs. clasificación binaria en 2025? Me pregunto si esto afectará cómo funcionan los desbloqueos faciales en nuestros móviles 🤔 ¿Será más rápido o más seguro? Alguien que sepa del tema que comente!













