
















 Lar
LarReconhecimento facial em 2025: Redes siamesas ou classificação binária?
O reconhecimento facial desempenha um papel fundamental em aplicações que vão desde sistemas de segurança até mídias sociais. Embora a perda tripla seja um método amplamente usado para treinar redes neurais convolucionais (CNNs) para essa finalidade, uma estratégia alternativa enquadra a tarefa como um problema de classificação binária. Essa abordagem aproveita as redes siamesas, oferecendo uma maneira distinta de aprender os parâmetros necessários para a verificação eficaz de rostos. A seguir, exploramos como isso é feito empregando um par de redes neurais para gerar embeddings.
Pontos principais
As redes siamesas são eficazes para a verificação de faces.
O reconhecimento facial pode ser modelado como uma tarefa de classificação binária.
O aprendizado de funções de similaridade incorpora a regressão logística.
O cálculo prévio de embeddings aumenta a eficiência da implementação.
Os processos incluem coleta de dados, treinamento de modelos, avaliação e implementação.
Tanto a verificação quanto o reconhecimento de faces podem ser treinados usando a classificação binária como uma alternativa à perda de tripletos.
Entendendo o reconhecimento e a verificação de faces
Reconhecimento de faces como classificação binária

O reconhecimento facial envolve mais do que apenas identificar um indivíduo; ele verifica a identidade reivindicada por uma pessoa. Isso é conhecido como verificação de face. Uma abordagem prática trata a verificação como um problema de classificação binária. Em vez de distinguir entre vários rostos, o sistema responde a uma pergunta simples: "Esses dois rostos pertencem à mesma pessoa?" Esse enquadramento binário simplifica o problema e melhora a eficiência computacional. A técnica se baseia em uma rede siamesa, composta por duas redes neurais idênticas com pesos e arquitetura compartilhados. Cada rede processa uma imagem de entrada e suas saídas são comparadas para gerar uma pontuação de similaridade. Se a pontuação ultrapassar um limite definido, os rostos são considerados compatíveis; caso contrário, são classificados como diferentes. A rede é treinada para produzir 1 para identidades correspondentes e 0 para identidades não correspondentes. Isso contrasta com sistemas mais complexos que precisam diferenciar uma grande variedade de indivíduos conhecidos.
A arquitetura da rede siamesa
O método é centrado na arquitetura de rede siamesa.
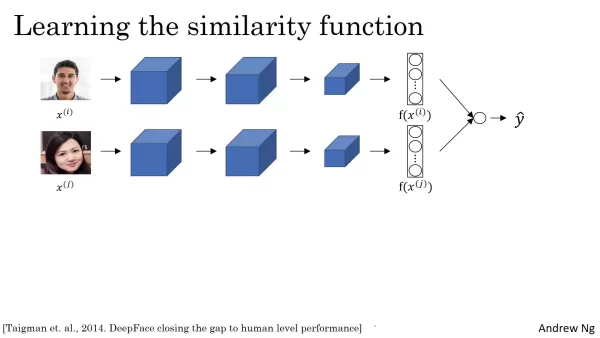
Essa arquitetura combina duas redes neurais idênticas, cada uma processando uma das duas imagens de entrada. Essas redes calculam os embeddings, que são vetores de alta dimensão que codificam traços faciais exclusivos. Ao comparar esses embeddings, o sistema avalia a semelhança facial. O processo de incorporação geralmente inclui camadas convolucionais, de agrupamento e totalmente conectadas, cada uma extraindo recursos progressivamente complexos da imagem. O resultado final é um vetor, geralmente de 128 dimensões, que captura as características faciais essenciais. Dimensões maiores também podem ser usadas para detectar detalhes mais finos. O mais importante é que as duas redes na configuração siamesa compartilham parâmetros idênticos, garantindo que os embeddings sejam gerados pelo mesmo processo de extração de recursos e sejam diretamente comparáveis.
Aprendendo funções de similaridade com regressão logística
Uso da regressão logística
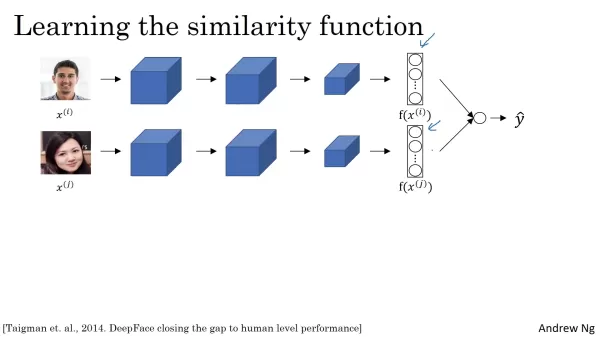
Para determinar se dois rostos representam a mesma pessoa, os embeddings da rede siamesa devem ser comparados. Uma unidade de regressão logística aplica uma função sigmoide a esses embeddings, produzindo uma pontuação de probabilidade que reflete a probabilidade de uma correspondência. A entrada para essa unidade não são os embeddings brutos, mas os recursos derivados deles. Um método comum é calcular a diferença absoluta por elemento entre os dois embeddings, enfatizando os recursos com as maiores disparidades. A similaridade do qui-quadrado é outra técnica usada. O objetivo é formar recursos altamente discriminativos que permitam que a unidade de regressão logística faça previsões precisas. As diferenças entre os elementos alimentam o modelo de regressão logística, que aprende a atribuir pesos apropriados. Se as diferenças forem mínimas, a unidade atribui uma probabilidade alta, indicando a mesma pessoa; se as diferenças forem significativas, ela atribui uma probabilidade baixa, indicando indivíduos diferentes.
Treinamento da rede siamesa e da regressão logística
Processo de treinamento passo a passo
- Coleta de dados de treinamento: Comece compilando um conjunto de dados de imagens de rostos, com rótulos que indiquem se os pares de imagens representam a mesma pessoa ou pessoas diferentes. Esse conjunto de dados treina a rede siamesa e a unidade de regressão logística.
- Configuração da rede siamesa: Configure duas CNNs idênticas com a mesma arquitetura e pesos compartilhados. Essas redes aprenderão a gerar embeddings a partir de imagens de rosto de entrada.
- Cálculo das diferenças de recursos: Determine as diferenças absolutas, em termos de elementos, entre os embeddings gerados pelas duas CNNs para cada par de imagens. Essas diferenças tornam-se os recursos de entrada para a unidade de regressão logística.
- Integração da regressão logística: Empregar um modelo de regressão logística para converter as diferenças de recursos em uma pontuação de probabilidade, indicando se os rostos coincidem.
- Ajuste fino: Refinar a camada de regressão logística ajustando os pesos atribuídos aos recursos (como aqueles em uma incorporação de 128 dimensões).
- Treinamento de retropropagação: Treine o sistema completo - CNNs e unidade de regressão logística - usando backpropagation. Isso minimiza uma função de perda que penaliza os erros de previsão, melhorando gradualmente a precisão por meio da otimização dos pesos e das tendências da rede.
- Ajuste de pesos: O modelo final de regressão logística pode incluir parâmetros adicionais como peso (W) e polarização (B).
- Pré-cálculo de Embeddings: Para uma implementação mais rápida, pré-computar os embeddings para permitir comparações rápidas.
Vantagens e desvantagens das redes siamesas para reconhecimento facial
Prós
Eficiência computacional
Aborda diretamente a verificação de faces
Extração eficaz de recursos
Contras
Requisitos de dados de treinamento
Possibilidade de ajuste excessivo
Generalização limitada
Perguntas frequentes
O que são redes siamesas e como elas funcionam no reconhecimento facial?
As redes siamesas são redes neurais compostas por duas ou mais sub-redes idênticas. Cada sub-rede recebe uma entrada distinta, mas compartilha pesos com as outras. No reconhecimento de faces, essas redes processam pares de imagens de faces para produzir embeddings, que são então avaliados quanto à similaridade.
Por que o reconhecimento facial às vezes é enquadrado como um problema de classificação binária?
Considerar o reconhecimento facial como um problema de classificação binária simplifica a determinação da correspondência de dois rostos, aumentando a eficiência em comparação com a distinção entre muitos indivíduos. Esse método usa redes siamesas para comparar pares de imagens de rostos.
Qual é o papel da regressão logística no aprendizado de funções de similaridade para o reconhecimento facial?
A regressão logística mapeia as diferenças entre os embeddings das redes siamesas para uma pontuação de probabilidade. Essa pontuação estima a probabilidade de que os dois rostos sejam a mesma pessoa, apoiando uma decisão binária.
Perguntas relacionadas
Como essa abordagem de rede siamesa se compara aos métodos tradicionais, como a perda de tripletos?
Os métodos tradicionais, como a perda de tripletos, visam aprender um espaço de incorporação em que os rostos da mesma pessoa estão mais próximos e os de pessoas diferentes estão mais distantes. As redes siamesas, estruturadas para classificação binária, concentram-se em verificar se dois rostos são idênticos, oferecendo vantagens computacionais. A melhor opção depende das características específicas do aplicativo e do conjunto de dados.
Existem outros métodos para avaliar a semelhança dos embeddings?
Sim, as alternativas incluem a similaridade de cosseno, a distância euclidiana e a similaridade do qui-quadrado. A fórmula de similaridade do qui-quadrado oferece outra maneira de abordar o reconhecimento facial. Cada técnica tem seus pontos fortes e é adequada a diferentes tipos de dados e casos de uso. Por exemplo, a similaridade de cosseno funciona bem com dados de alta dimensão, enquanto a distância euclidiana é eficaz em dimensões menores.
O que está envolvido na implantação efetiva do sistema treinado?
A implementação envolve a pré-computação de embeddings para evitar o armazenamento de imagens brutas. O sistema, desenvolvido em uma arquitetura de rede siamesa, foi projetado para comparar esses embeddings de forma eficiente.
Artigo relacionado
 A Luma AI apresenta o modelo autorregressivo Uni-1, capaz de gerar texto e pixels simultaneamente
A Luma Labs lançou seu modelo de geração de imagens Uni-1 em 23 de março, marcando o primeiro modelo da empresa disponível ao público desenvolvido com base na arquitetura Unified Intelligence. O acess
Xinzhou Wu, da NVIDIA: chegou o momento “ChatGPT” da direção autônoma; a produção em massa do nível 4 não é mais um sonho
No campo da IA física, em rápida evolução, a direção autônoma é frequentemente vista como o primeiro grande desafio a ser superado. Recentemente, Wu Xinzhou, vice-presidente da NVIDIA, apresentou a am
A Anthropic aumenta discretamente os preços do Claude Code; taxas diárias para desenvolvedores dobram
As pressões de custo na programação de IA estão se tornando cada vez mais evidentes. A Anthropic, uma empresa líder no setor de IA, ajustou recentemente os preços de sua ferramenta de programação de I
Recomendações de tópicos especiais relacionados
chatbot
A Luma AI apresenta o modelo autorregressivo Uni-1, capaz de gerar texto e pixels simultaneamente
A Luma Labs lançou seu modelo de geração de imagens Uni-1 em 23 de março, marcando o primeiro modelo da empresa disponível ao público desenvolvido com base na arquitetura Unified Intelligence. O acess
Xinzhou Wu, da NVIDIA: chegou o momento “ChatGPT” da direção autônoma; a produção em massa do nível 4 não é mais um sonho
No campo da IA física, em rápida evolução, a direção autônoma é frequentemente vista como o primeiro grande desafio a ser superado. Recentemente, Wu Xinzhou, vice-presidente da NVIDIA, apresentou a am
A Anthropic aumenta discretamente os preços do Claude Code; taxas diárias para desenvolvedores dobram
As pressões de custo na programação de IA estão se tornando cada vez mais evidentes. A Anthropic, uma empresa líder no setor de IA, ajustou recentemente os preços de sua ferramenta de programação de I
Recomendações de tópicos especiais relacionados
chatbot
 Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
 10 ferramentas
10 ferramentas
 xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai
Análise de dados
As melhores ferramentas de visualização de dados com IA: gere automaticamente painéis interativos de BI a partir de arquivos brutos
Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai
Mídias Sociais
Kits de identidade visual com IA para redes sociais: mantenha a identidade visual da marca consistente em todos os canais
Descubra os melhores kits de branding com IA para redes sociais de 2026. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias para manter uma identidade visual de marca perfeitamente consistente em todos os canais. Compare opções gratuitas e pagas com testes práticos. Destaque-se visualmente com sua marca hoje mesmo.
10 ferramentas
xix.ai

 Comentários (2)
Comentários (2)
![PaulMartínez]()
Interessant, dass hier Siamese Networks und binäre Klassifikation verglichen werden. Ich frage mich, ob die Wahl je nach Anwendungsfall variieren sollte – vielleicht ist der eine Ansatz für Sicherheitssysteme besser, der andere für Social Media? 🤔 Die Diskussion um Triplet Loss vs. Alternativen zeigt, wie dynamisch das Feld noch ist. Hoffentlich bleibt die Ethik dabei nicht auf der Strecke, gerade bei Gesichtserkennung.
![JohnRoberts]()
¿Redes Siamesas vs. clasificación binaria en 2025? Me pregunto si esto afectará cómo funcionan los desbloqueos faciales en nuestros móviles 🤔 ¿Será más rápido o más seguro? Alguien que sepa del tema que comente!
O reconhecimento facial desempenha um papel fundamental em aplicações que vão desde sistemas de segurança até mídias sociais. Embora a perda tripla seja um método amplamente usado para treinar redes neurais convolucionais (CNNs) para essa finalidade, uma estratégia alternativa enquadra a tarefa como um problema de classificação binária. Essa abordagem aproveita as redes siamesas, oferecendo uma maneira distinta de aprender os parâmetros necessários para a verificação eficaz de rostos. A seguir, exploramos como isso é feito empregando um par de redes neurais para gerar embeddings.
Pontos principais
As redes siamesas são eficazes para a verificação de faces.
O reconhecimento facial pode ser modelado como uma tarefa de classificação binária.
O aprendizado de funções de similaridade incorpora a regressão logística.
O cálculo prévio de embeddings aumenta a eficiência da implementação.
Os processos incluem coleta de dados, treinamento de modelos, avaliação e implementação.
Tanto a verificação quanto o reconhecimento de faces podem ser treinados usando a classificação binária como uma alternativa à perda de tripletos.
Entendendo o reconhecimento e a verificação de faces
Reconhecimento de faces como classificação binária
O reconhecimento facial envolve mais do que apenas identificar um indivíduo; ele verifica a identidade reivindicada por uma pessoa. Isso é conhecido como verificação de face. Uma abordagem prática trata a verificação como um problema de classificação binária. Em vez de distinguir entre vários rostos, o sistema responde a uma pergunta simples: "Esses dois rostos pertencem à mesma pessoa?" Esse enquadramento binário simplifica o problema e melhora a eficiência computacional. A técnica se baseia em uma rede siamesa, composta por duas redes neurais idênticas com pesos e arquitetura compartilhados. Cada rede processa uma imagem de entrada e suas saídas são comparadas para gerar uma pontuação de similaridade. Se a pontuação ultrapassar um limite definido, os rostos são considerados compatíveis; caso contrário, são classificados como diferentes. A rede é treinada para produzir 1 para identidades correspondentes e 0 para identidades não correspondentes. Isso contrasta com sistemas mais complexos que precisam diferenciar uma grande variedade de indivíduos conhecidos.
A arquitetura da rede siamesa
O método é centrado na arquitetura de rede siamesa.
Essa arquitetura combina duas redes neurais idênticas, cada uma processando uma das duas imagens de entrada. Essas redes calculam os embeddings, que são vetores de alta dimensão que codificam traços faciais exclusivos. Ao comparar esses embeddings, o sistema avalia a semelhança facial. O processo de incorporação geralmente inclui camadas convolucionais, de agrupamento e totalmente conectadas, cada uma extraindo recursos progressivamente complexos da imagem. O resultado final é um vetor, geralmente de 128 dimensões, que captura as características faciais essenciais. Dimensões maiores também podem ser usadas para detectar detalhes mais finos. O mais importante é que as duas redes na configuração siamesa compartilham parâmetros idênticos, garantindo que os embeddings sejam gerados pelo mesmo processo de extração de recursos e sejam diretamente comparáveis.
Aprendendo funções de similaridade com regressão logística
Uso da regressão logística
Para determinar se dois rostos representam a mesma pessoa, os embeddings da rede siamesa devem ser comparados. Uma unidade de regressão logística aplica uma função sigmoide a esses embeddings, produzindo uma pontuação de probabilidade que reflete a probabilidade de uma correspondência. A entrada para essa unidade não são os embeddings brutos, mas os recursos derivados deles. Um método comum é calcular a diferença absoluta por elemento entre os dois embeddings, enfatizando os recursos com as maiores disparidades. A similaridade do qui-quadrado é outra técnica usada. O objetivo é formar recursos altamente discriminativos que permitam que a unidade de regressão logística faça previsões precisas. As diferenças entre os elementos alimentam o modelo de regressão logística, que aprende a atribuir pesos apropriados. Se as diferenças forem mínimas, a unidade atribui uma probabilidade alta, indicando a mesma pessoa; se as diferenças forem significativas, ela atribui uma probabilidade baixa, indicando indivíduos diferentes.
Treinamento da rede siamesa e da regressão logística
Processo de treinamento passo a passo
- Coleta de dados de treinamento: Comece compilando um conjunto de dados de imagens de rostos, com rótulos que indiquem se os pares de imagens representam a mesma pessoa ou pessoas diferentes. Esse conjunto de dados treina a rede siamesa e a unidade de regressão logística.
- Configuração da rede siamesa: Configure duas CNNs idênticas com a mesma arquitetura e pesos compartilhados. Essas redes aprenderão a gerar embeddings a partir de imagens de rosto de entrada.
- Cálculo das diferenças de recursos: Determine as diferenças absolutas, em termos de elementos, entre os embeddings gerados pelas duas CNNs para cada par de imagens. Essas diferenças tornam-se os recursos de entrada para a unidade de regressão logística.
- Integração da regressão logística: Empregar um modelo de regressão logística para converter as diferenças de recursos em uma pontuação de probabilidade, indicando se os rostos coincidem.
- Ajuste fino: Refinar a camada de regressão logística ajustando os pesos atribuídos aos recursos (como aqueles em uma incorporação de 128 dimensões).
- Treinamento de retropropagação: Treine o sistema completo - CNNs e unidade de regressão logística - usando backpropagation. Isso minimiza uma função de perda que penaliza os erros de previsão, melhorando gradualmente a precisão por meio da otimização dos pesos e das tendências da rede.
- Ajuste de pesos: O modelo final de regressão logística pode incluir parâmetros adicionais como peso (W) e polarização (B).
- Pré-cálculo de Embeddings: Para uma implementação mais rápida, pré-computar os embeddings para permitir comparações rápidas.
Vantagens e desvantagens das redes siamesas para reconhecimento facial
Prós
Eficiência computacional
Aborda diretamente a verificação de faces
Extração eficaz de recursos
Contras
Requisitos de dados de treinamento
Possibilidade de ajuste excessivo
Generalização limitada
Perguntas frequentes
O que são redes siamesas e como elas funcionam no reconhecimento facial?
As redes siamesas são redes neurais compostas por duas ou mais sub-redes idênticas. Cada sub-rede recebe uma entrada distinta, mas compartilha pesos com as outras. No reconhecimento de faces, essas redes processam pares de imagens de faces para produzir embeddings, que são então avaliados quanto à similaridade.
Por que o reconhecimento facial às vezes é enquadrado como um problema de classificação binária?
Considerar o reconhecimento facial como um problema de classificação binária simplifica a determinação da correspondência de dois rostos, aumentando a eficiência em comparação com a distinção entre muitos indivíduos. Esse método usa redes siamesas para comparar pares de imagens de rostos.
Qual é o papel da regressão logística no aprendizado de funções de similaridade para o reconhecimento facial?
A regressão logística mapeia as diferenças entre os embeddings das redes siamesas para uma pontuação de probabilidade. Essa pontuação estima a probabilidade de que os dois rostos sejam a mesma pessoa, apoiando uma decisão binária.
Perguntas relacionadas
Como essa abordagem de rede siamesa se compara aos métodos tradicionais, como a perda de tripletos?
Os métodos tradicionais, como a perda de tripletos, visam aprender um espaço de incorporação em que os rostos da mesma pessoa estão mais próximos e os de pessoas diferentes estão mais distantes. As redes siamesas, estruturadas para classificação binária, concentram-se em verificar se dois rostos são idênticos, oferecendo vantagens computacionais. A melhor opção depende das características específicas do aplicativo e do conjunto de dados.
Existem outros métodos para avaliar a semelhança dos embeddings?
Sim, as alternativas incluem a similaridade de cosseno, a distância euclidiana e a similaridade do qui-quadrado. A fórmula de similaridade do qui-quadrado oferece outra maneira de abordar o reconhecimento facial. Cada técnica tem seus pontos fortes e é adequada a diferentes tipos de dados e casos de uso. Por exemplo, a similaridade de cosseno funciona bem com dados de alta dimensão, enquanto a distância euclidiana é eficaz em dimensões menores.
O que está envolvido na implantação efetiva do sistema treinado?
A implementação envolve a pré-computação de embeddings para evitar o armazenamento de imagens brutas. O sistema, desenvolvido em uma arquitetura de rede siamesa, foi projetado para comparar esses embeddings de forma eficiente.










 A Luma AI apresenta o modelo autorregressivo Uni-1, capaz de gerar texto e pixels simultaneamente
A Luma Labs lançou seu modelo de geração de imagens Uni-1 em 23 de março, marcando o primeiro modelo da empresa disponível ao público desenvolvido com base na arquitetura Unified Intelligence. O acess
A Luma AI apresenta o modelo autorregressivo Uni-1, capaz de gerar texto e pixels simultaneamente
A Luma Labs lançou seu modelo de geração de imagens Uni-1 em 23 de março, marcando o primeiro modelo da empresa disponível ao público desenvolvido com base na arquitetura Unified Intelligence. O acess
 Xinzhou Wu, da NVIDIA: chegou o momento “ChatGPT” da direção autônoma; a produção em massa do nível 4 não é mais um sonho
No campo da IA física, em rápida evolução, a direção autônoma é frequentemente vista como o primeiro grande desafio a ser superado. Recentemente, Wu Xinzhou, vice-presidente da NVIDIA, apresentou a am
Xinzhou Wu, da NVIDIA: chegou o momento “ChatGPT” da direção autônoma; a produção em massa do nível 4 não é mais um sonho
No campo da IA física, em rápida evolução, a direção autônoma é frequentemente vista como o primeiro grande desafio a ser superado. Recentemente, Wu Xinzhou, vice-presidente da NVIDIA, apresentou a am
 A Anthropic aumenta discretamente os preços do Claude Code; taxas diárias para desenvolvedores dobram
As pressões de custo na programação de IA estão se tornando cada vez mais evidentes. A Anthropic, uma empresa líder no setor de IA, ajustou recentemente os preços de sua ferramenta de programação de I
A Anthropic aumenta discretamente os preços do Claude Code; taxas diárias para desenvolvedores dobram
As pressões de custo na programação de IA estão se tornando cada vez mais evidentes. A Anthropic, uma empresa líder no setor de IA, ajustou recentemente os preços de sua ferramenta de programação de I

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores kits de branding com IA para redes sociais de 2026. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias para manter uma identidade visual de marca perfeitamente consistente em todos os canais. Compare opções gratuitas e pagas com testes práticos. Destaque-se visualmente com sua marca hoje mesmo.
10 ferramentas
xix.ai

Interessant, dass hier Siamese Networks und binäre Klassifikation verglichen werden. Ich frage mich, ob die Wahl je nach Anwendungsfall variieren sollte – vielleicht ist der eine Ansatz für Sicherheitssysteme besser, der andere für Social Media? 🤔 Die Diskussion um Triplet Loss vs. Alternativen zeigt, wie dynamisch das Feld noch ist. Hoffentlich bleibt die Ethik dabei nicht auf der Strecke, gerade bei Gesichtserkennung.
¿Redes Siamesas vs. clasificación binaria en 2025? Me pregunto si esto afectará cómo funcionan los desbloqueos faciales en nuestros móviles 🤔 ¿Será más rápido o más seguro? Alguien que sepa del tema que comente!













