
















 Heim
HeimZusammenfassen großer Texte mit OpenAI: Ultimative Anleitung und Techniken
In der heutigen datengesteuerten Welt ist die effiziente Verarbeitung großer Mengen an Informationen von entscheidender Bedeutung. Dieser umfassende Leitfaden zeigt, wie Sie die fortschrittliche API-Technologie von OpenAI für die Zusammenfassung verschiedener Textquellen nutzen können, von einfachen TXT-Dateien bis hin zu komplexen PDF-Dokumenten. Es werden bewährte Methoden zur Verwaltung übergroßer Dokumente, zu deren strategischer Segmentierung und zur Erstellung aufschlussreicher Zusammenfassungen durch künstliche Intelligenz vorgestellt. Diese Techniken sind ideal für Fachleute, die mit technischen Berichten, akademischer Forschung oder juristischen Verträgen zu tun haben, und bieten praktikable Lösungen für die Umwandlung überwältigender Inhalte in wertvolle Erkenntnisse.
Wichtigste Highlights
TXT/PDF-Zusammenfassung: Meisterhafte Techniken zur Dokumentenkondensation für mehrere Dateiformate.
PDF-Konvertierung: Lernen Sie zuverlässige Methoden zur Extraktion von Text aus PDF-Dokumenten.
Dokumentensegmentierung: Entdecken Sie optimale Ansätze für die Aufteilung großer Dateien.
API-Integration: Implementieren Sie die leistungsstarken Zusammenfassungsfunktionen von OpenAI.
Überlegungen zur Kodierung: Verstehen Sie die kritischen Aspekte der Zeichensatzbehandlung.
Synthese von Zusammenfassungen: Kombinieren Sie Teilzusammenfassungen zu kohärenten Übersichten.
KI-gestützte Techniken zur Dokumentenzusammenfassung
Überwindung der Herausforderungen bei der Zusammenfassung von großen Dokumenten
Die Zusammenfassung umfangreicher Dokumente birgt besondere Hindernisse, die mit herkömmlichen Methoden oft nicht angemessen bewältigt werden können. Moderne KI-Lösungen, insbesondere über die API von OpenAI, bieten skalierbare Alternativen, die Verarbeitungsbeschränkungen überwinden und gleichzeitig die Genauigkeit beibehalten.
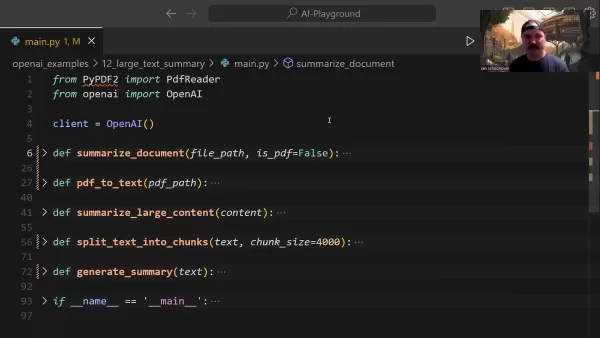
Effektive Zusammenfassungen erfordern die Extraktion wesentlicher Informationen unter Beibehaltung von Kontext und Bedeutung. Fachleute aus verschiedenen Branchen - darunter Forscher, die Studien analysieren, und Anwälte, die Verträge prüfen - profitieren von diesen fortschrittlichen Fähigkeiten.
Die Methodik umfasst eine intelligente Dokumentensegmentierung, die eine systematische Verarbeitung überschaubarer Inhaltsabschnitte unter Berücksichtigung der API-Einschränkungen ermöglicht. Dieser strukturierte Ansatz garantiert eine umfassende Abdeckung, ohne dass wichtige Details verloren gehen, unabhängig von der Länge des Originaldokuments.
Kernkomponenten des Verdichtungsprozesses
Der Arbeitsablauf der Dokumentenkondensation umfasst mehrere grundlegende Elemente:
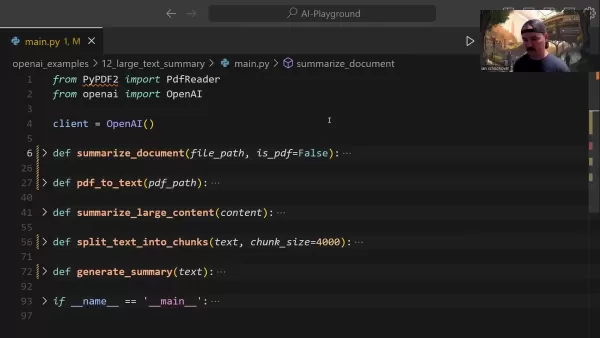
- Verarbeitung der Dokumenteneingabe: Unterstützt sowohl TXT- als auch PDF-Formate mit automatischer Erkennung
- PDF-Konvertierung: Umwandlung von PDF-Inhalten in analysierbaren Text unter Beibehaltung der Layout-Integrität
- Segmentierung des Inhalts: Strategische Aufteilung übergroßer Dokumente in optimale Verarbeitungseinheiten
- API-Verarbeitung: Nutzt die Algorithmen von OpenAI für die intelligente Extraktion von Inhalten
- Integration von Zusammenfassungen: Kombiniert Teilzusammenfassungen zu einheitlichen, kohärenten Übersichten
Details zur Implementierung
Zentrale Zusammenfassungsfunktion
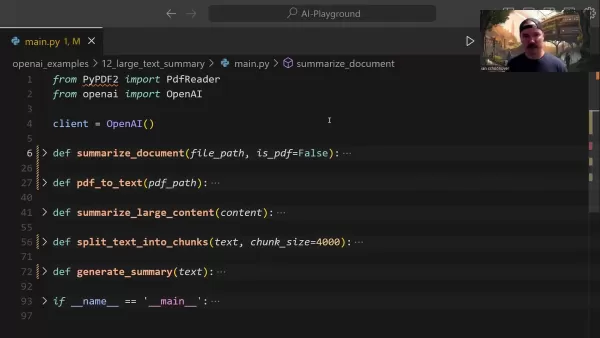
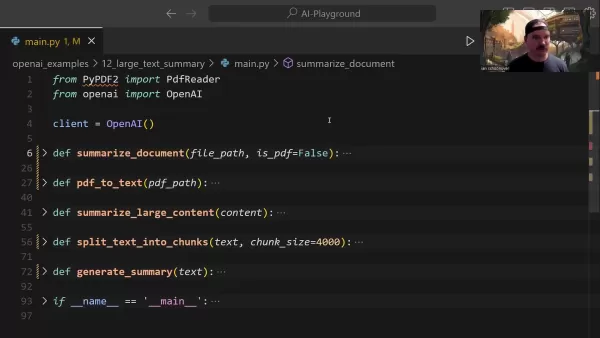
Die zentrale Funktion summarize_document verwaltet die gesamte Zusammenfassungspipeline:
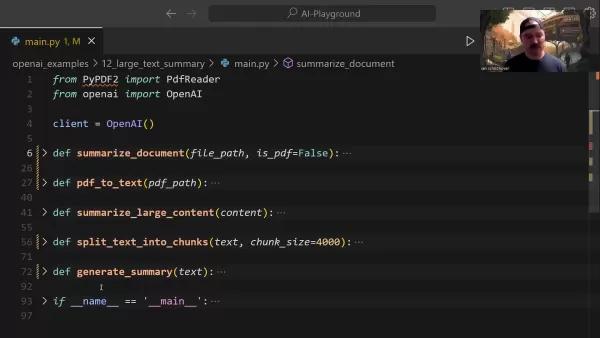
Diese Funktion handhabt die Formaterkennung auf intelligente Weise, delegiert bei Bedarf Konvertierungsaufgaben und bestimmt geeignete Verdichtungsstrategien auf der Grundlage der Dokumentengröße.
Methodik der PDF-Konvertierung
Für die PDF-Textextraktion werden spezielle Bibliotheken verwendet:
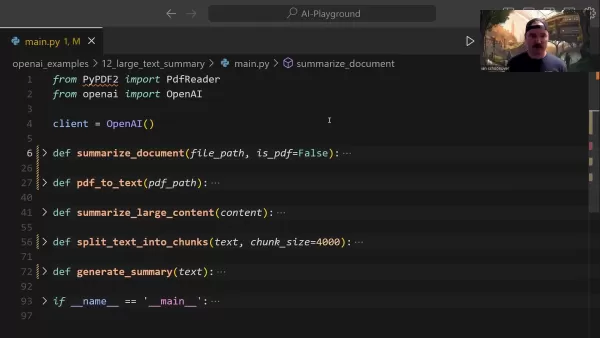
Unter Verwendung von PyPDF2 bleibt bei der Konvertierung die Absatzstruktur erhalten, während unnötige Formatierungselemente effizient entfernt werden.
Handhabung großer Dokumente
Bei übergroßen Inhalten implementiert das System eine strategische Segmentierung:
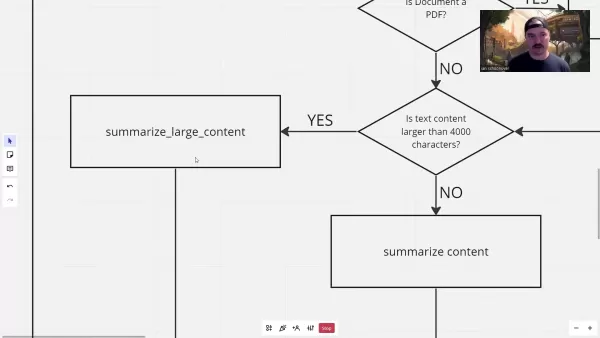
Dieser Ansatz kombiniert eine vorläufige Zusammenfassung von Chunks mit einer abschließenden Konsolidierung, um den Kontext in langen Dokumenten zu erhalten.
Segmentierung von Inhalten
Der Chunking-Algorithmus sorgt für eine optimale Größenbestimmung:
Konfigurierbare Chunk-Größen passen sich verschiedenen Dokumenttypen an und berücksichtigen gleichzeitig API-Einschränkungen.
KI-Integration
Die API-Kommunikationskomponente sorgt für intelligente Zusammenfassungen:
Eine sorgfältige Parameterkonfiguration sorgt für ein Gleichgewicht zwischen Detailtreue und Prägnanz.
Vorteile und Überlegungen
Vorteile
- Skalierbare Verarbeitung: Effektive Verarbeitung von Dokumenten praktisch jeder Größe
- Intelligente Extraktion: Identifiziert und bewahrt wichtige Informationen genau
- Format-Flexibilität: Passt sich an verschiedene Dokumentenstrukturen und -layouts an
- Höhere Effizienz: Drastische Reduzierung der Zeit für manuelle Zusammenfassungen
- Zugänglichkeit: Macht dichte Informationen leichter verdaulich
Beschränkungen
- Kostenstruktur: Gebühren werden je nach Verarbeitungsvolumen erhoben
- Konnektivitätsanforderungen: Abhängig von einem stabilen Internetzugang
- Kontextbedingte Einschränkungen: Kann gelegentlich spezielle Nuancen übersehen
- Sensibilität der Daten: Erfordert Vorsicht im Umgang mit vertraulichen Informationen
Allgemeine Fragen
Unterstützte Dateitypen
Das System verarbeitet derzeit Standard-TXT- und PDF-Dokumente.
Größenbeschränkungen
Intelligente Segmentierung ermöglicht die Zusammenfassung von beliebig großen Dokumenten.
Modell-Spezifikationen
Die Implementierung verwendet das Modell gpt-3.5-turbo-1106 von OpenAI.
Anleitung zur Implementierung
PDF-Summarisierungsprozess
Aktivieren Sie die PDF-Verarbeitung über das boolesche Flag:
document_summary = summarize_document('/document/location/file.pdf', is_pdf=True)
Verwandter Artikel
 Google stellt Gemini Notebooks vor und vereint NotebookLM mit einer persönlichen Wissensdatenbank
Google hat kürzlich die Funktion „Notebooks“ für Gemini eingeführt, die Nutzern helfen soll, komplexe Projekte durch die Erstellung einer personalisierten Wissensdatenbank zu verwalten. Dieses Update
Luma AI stellt das autoregressive Modell „Uni-1“ vor, das gleichzeitig Text und Pixel generiert
Luma Labs hat am 23. März sein Bildgenerierungsmodell Uni-1 vorgestellt – das erste öffentlich zugängliche Modell des Unternehmens, das auf der Unified-Intelligence-Architektur basiert. Auf der offizi
Xinzhou Wu von NVIDIA: Der „ChatGPT-Moment“ des autonomen Fahrens ist gekommen – die Serienproduktion von Level-4-Fahrzeugen ist kein Traum mehr
Im sich rasch entwickelnden Bereich der physikalischen KI wird das autonome Fahren oft als die erste große Herausforderung angesehen, die es zu bewältigen gilt. Kürzlich skizzierte Wu Xinzhou, Vizeprä
Empfehlungen zu verwandten Spezialthemen
Chatbot
Google stellt Gemini Notebooks vor und vereint NotebookLM mit einer persönlichen Wissensdatenbank
Google hat kürzlich die Funktion „Notebooks“ für Gemini eingeführt, die Nutzern helfen soll, komplexe Projekte durch die Erstellung einer personalisierten Wissensdatenbank zu verwalten. Dieses Update
Luma AI stellt das autoregressive Modell „Uni-1“ vor, das gleichzeitig Text und Pixel generiert
Luma Labs hat am 23. März sein Bildgenerierungsmodell Uni-1 vorgestellt – das erste öffentlich zugängliche Modell des Unternehmens, das auf der Unified-Intelligence-Architektur basiert. Auf der offizi
Xinzhou Wu von NVIDIA: Der „ChatGPT-Moment“ des autonomen Fahrens ist gekommen – die Serienproduktion von Level-4-Fahrzeugen ist kein Traum mehr
Im sich rasch entwickelnden Bereich der physikalischen KI wird das autonome Fahren oft als die erste große Herausforderung angesehen, die es zu bewältigen gilt. Kürzlich skizzierte Wu Xinzhou, Vizeprä
Empfehlungen zu verwandten Spezialthemen
Chatbot
 Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
 10 Tools
10 Tools
 xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai
Datenanalyse
Die besten KI-Tools zur Datenvisualisierung: Interaktive BI-Dashboards automatisch aus Rohdaten generieren
Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai
Soziale Medien
KI-Branding-Kits für soziale Medien: Sorgen Sie für ein einheitliches Markenbild auf allen Kanälen
Entdecken Sie die besten KI-Branding-Kits für Social Media im Jahr 2026. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie ein einheitliches Markenbild auf allen Kanälen gewährleisten können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Verschaffen Sie Ihrer Marke noch heute einen visuellen Vorsprung.
10 Tools
xix.ai

 Kommentare (1)
Kommentare (1)
![EmmaTurner]()
この記事を読んで、大規模テキスト要約の可能性にますます興味が湧きました!特に基本テキストファイルから複雑な文章まで扱える柔軟性が素晴らしいですね。私は実際に大量のリサーチ論文を要約する必要があって、OpenAIの技術はまさに救世主です🎯。でも、長文要約の精度ってどれくらいなんだろう?細部のニュアンスが抜け落ちないか心配な面もあります。今度試してみたいと思います。
In der heutigen datengesteuerten Welt ist die effiziente Verarbeitung großer Mengen an Informationen von entscheidender Bedeutung. Dieser umfassende Leitfaden zeigt, wie Sie die fortschrittliche API-Technologie von OpenAI für die Zusammenfassung verschiedener Textquellen nutzen können, von einfachen TXT-Dateien bis hin zu komplexen PDF-Dokumenten. Es werden bewährte Methoden zur Verwaltung übergroßer Dokumente, zu deren strategischer Segmentierung und zur Erstellung aufschlussreicher Zusammenfassungen durch künstliche Intelligenz vorgestellt. Diese Techniken sind ideal für Fachleute, die mit technischen Berichten, akademischer Forschung oder juristischen Verträgen zu tun haben, und bieten praktikable Lösungen für die Umwandlung überwältigender Inhalte in wertvolle Erkenntnisse.
Wichtigste Highlights
TXT/PDF-Zusammenfassung: Meisterhafte Techniken zur Dokumentenkondensation für mehrere Dateiformate.
PDF-Konvertierung: Lernen Sie zuverlässige Methoden zur Extraktion von Text aus PDF-Dokumenten.
Dokumentensegmentierung: Entdecken Sie optimale Ansätze für die Aufteilung großer Dateien.
API-Integration: Implementieren Sie die leistungsstarken Zusammenfassungsfunktionen von OpenAI.
Überlegungen zur Kodierung: Verstehen Sie die kritischen Aspekte der Zeichensatzbehandlung.
Synthese von Zusammenfassungen: Kombinieren Sie Teilzusammenfassungen zu kohärenten Übersichten.
KI-gestützte Techniken zur Dokumentenzusammenfassung
Überwindung der Herausforderungen bei der Zusammenfassung von großen Dokumenten
Die Zusammenfassung umfangreicher Dokumente birgt besondere Hindernisse, die mit herkömmlichen Methoden oft nicht angemessen bewältigt werden können. Moderne KI-Lösungen, insbesondere über die API von OpenAI, bieten skalierbare Alternativen, die Verarbeitungsbeschränkungen überwinden und gleichzeitig die Genauigkeit beibehalten.
Effektive Zusammenfassungen erfordern die Extraktion wesentlicher Informationen unter Beibehaltung von Kontext und Bedeutung. Fachleute aus verschiedenen Branchen - darunter Forscher, die Studien analysieren, und Anwälte, die Verträge prüfen - profitieren von diesen fortschrittlichen Fähigkeiten.
Die Methodik umfasst eine intelligente Dokumentensegmentierung, die eine systematische Verarbeitung überschaubarer Inhaltsabschnitte unter Berücksichtigung der API-Einschränkungen ermöglicht. Dieser strukturierte Ansatz garantiert eine umfassende Abdeckung, ohne dass wichtige Details verloren gehen, unabhängig von der Länge des Originaldokuments.
Kernkomponenten des Verdichtungsprozesses
Der Arbeitsablauf der Dokumentenkondensation umfasst mehrere grundlegende Elemente:
- Verarbeitung der Dokumenteneingabe: Unterstützt sowohl TXT- als auch PDF-Formate mit automatischer Erkennung
- PDF-Konvertierung: Umwandlung von PDF-Inhalten in analysierbaren Text unter Beibehaltung der Layout-Integrität
- Segmentierung des Inhalts: Strategische Aufteilung übergroßer Dokumente in optimale Verarbeitungseinheiten
- API-Verarbeitung: Nutzt die Algorithmen von OpenAI für die intelligente Extraktion von Inhalten
- Integration von Zusammenfassungen: Kombiniert Teilzusammenfassungen zu einheitlichen, kohärenten Übersichten
Details zur Implementierung
Zentrale Zusammenfassungsfunktion
Die zentrale Funktion summarize_document verwaltet die gesamte Zusammenfassungspipeline:
Diese Funktion handhabt die Formaterkennung auf intelligente Weise, delegiert bei Bedarf Konvertierungsaufgaben und bestimmt geeignete Verdichtungsstrategien auf der Grundlage der Dokumentengröße.
Methodik der PDF-Konvertierung
Für die PDF-Textextraktion werden spezielle Bibliotheken verwendet:
Unter Verwendung von PyPDF2 bleibt bei der Konvertierung die Absatzstruktur erhalten, während unnötige Formatierungselemente effizient entfernt werden.
Handhabung großer Dokumente
Bei übergroßen Inhalten implementiert das System eine strategische Segmentierung:
Dieser Ansatz kombiniert eine vorläufige Zusammenfassung von Chunks mit einer abschließenden Konsolidierung, um den Kontext in langen Dokumenten zu erhalten.
Segmentierung von Inhalten
Der Chunking-Algorithmus sorgt für eine optimale Größenbestimmung:
Konfigurierbare Chunk-Größen passen sich verschiedenen Dokumenttypen an und berücksichtigen gleichzeitig API-Einschränkungen.
KI-Integration
Die API-Kommunikationskomponente sorgt für intelligente Zusammenfassungen:
Eine sorgfältige Parameterkonfiguration sorgt für ein Gleichgewicht zwischen Detailtreue und Prägnanz.
Vorteile und Überlegungen
Vorteile
- Skalierbare Verarbeitung: Effektive Verarbeitung von Dokumenten praktisch jeder Größe
- Intelligente Extraktion: Identifiziert und bewahrt wichtige Informationen genau
- Format-Flexibilität: Passt sich an verschiedene Dokumentenstrukturen und -layouts an
- Höhere Effizienz: Drastische Reduzierung der Zeit für manuelle Zusammenfassungen
- Zugänglichkeit: Macht dichte Informationen leichter verdaulich
Beschränkungen
- Kostenstruktur: Gebühren werden je nach Verarbeitungsvolumen erhoben
- Konnektivitätsanforderungen: Abhängig von einem stabilen Internetzugang
- Kontextbedingte Einschränkungen: Kann gelegentlich spezielle Nuancen übersehen
- Sensibilität der Daten: Erfordert Vorsicht im Umgang mit vertraulichen Informationen
Allgemeine Fragen
Unterstützte Dateitypen
Das System verarbeitet derzeit Standard-TXT- und PDF-Dokumente.
Größenbeschränkungen
Intelligente Segmentierung ermöglicht die Zusammenfassung von beliebig großen Dokumenten.
Modell-Spezifikationen
Die Implementierung verwendet das Modell gpt-3.5-turbo-1106 von OpenAI.
Anleitung zur Implementierung
PDF-Summarisierungsprozess
Aktivieren Sie die PDF-Verarbeitung über das boolesche Flag:
document_summary = summarize_document('/document/location/file.pdf', is_pdf=True)










 Google stellt Gemini Notebooks vor und vereint NotebookLM mit einer persönlichen Wissensdatenbank
Google hat kürzlich die Funktion „Notebooks“ für Gemini eingeführt, die Nutzern helfen soll, komplexe Projekte durch die Erstellung einer personalisierten Wissensdatenbank zu verwalten. Dieses Update
Google stellt Gemini Notebooks vor und vereint NotebookLM mit einer persönlichen Wissensdatenbank
Google hat kürzlich die Funktion „Notebooks“ für Gemini eingeführt, die Nutzern helfen soll, komplexe Projekte durch die Erstellung einer personalisierten Wissensdatenbank zu verwalten. Dieses Update
 Luma AI stellt das autoregressive Modell „Uni-1“ vor, das gleichzeitig Text und Pixel generiert
Luma Labs hat am 23. März sein Bildgenerierungsmodell Uni-1 vorgestellt – das erste öffentlich zugängliche Modell des Unternehmens, das auf der Unified-Intelligence-Architektur basiert. Auf der offizi
Luma AI stellt das autoregressive Modell „Uni-1“ vor, das gleichzeitig Text und Pixel generiert
Luma Labs hat am 23. März sein Bildgenerierungsmodell Uni-1 vorgestellt – das erste öffentlich zugängliche Modell des Unternehmens, das auf der Unified-Intelligence-Architektur basiert. Auf der offizi
 Xinzhou Wu von NVIDIA: Der „ChatGPT-Moment“ des autonomen Fahrens ist gekommen – die Serienproduktion von Level-4-Fahrzeugen ist kein Traum mehr
Im sich rasch entwickelnden Bereich der physikalischen KI wird das autonome Fahren oft als die erste große Herausforderung angesehen, die es zu bewältigen gilt. Kürzlich skizzierte Wu Xinzhou, Vizeprä
Xinzhou Wu von NVIDIA: Der „ChatGPT-Moment“ des autonomen Fahrens ist gekommen – die Serienproduktion von Level-4-Fahrzeugen ist kein Traum mehr
Im sich rasch entwickelnden Bereich der physikalischen KI wird das autonome Fahren oft als die erste große Herausforderung angesehen, die es zu bewältigen gilt. Kürzlich skizzierte Wu Xinzhou, Vizeprä

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

Entdecken Sie die besten KI-Branding-Kits für Social Media im Jahr 2026. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie ein einheitliches Markenbild auf allen Kanälen gewährleisten können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Verschaffen Sie Ihrer Marke noch heute einen visuellen Vorsprung.
10 Tools
xix.ai

この記事を読んで、大規模テキスト要約の可能性にますます興味が湧きました!特に基本テキストファイルから複雑な文章まで扱える柔軟性が素晴らしいですね。私は実際に大量のリサーチ論文を要約する必要があって、OpenAIの技術はまさに救世主です🎯。でも、長文要約の精度ってどれくらいなんだろう?細部のニュアンスが抜け落ちないか心配な面もあります。今度試してみたいと思います。













