




Освойте обобщение больших текстов с помощью OpenAI: руководство и методики
В современном мире, основанном на данных, эффективная обработка больших объемов информации имеет решающее значение. В этом комплексном руководстве показано, как использовать передовую технологию API OpenAI для обобщения различных текстовых источников, от простых TXT-файлов до сложных PDF-документов. Мы рассмотрим проверенные методы управления огромными документами, их стратегического сегментирования и создания проницательных резюме с помощью искусственного интеллекта. Эти методы идеально подходят для специалистов, работающих с техническими отчетами, академическими исследованиями или юридическими контрактами. Они предлагают практические решения для преобразования перегруженного контента в ценные сведения.
Ключевые моменты
Резюме TXT/PDF: Освоение методов сжатия документов для различных форматов файлов.
Преобразование PDF: Узнайте надежные методы извлечения текста из PDF-документов.
Сегментация документов: Откройте для себя оптимальные подходы к разделению больших файлов.
Интеграция API: Реализуйте мощные возможности обобщения OpenAI.
Учет кодировок: Поймите критические аспекты работы с наборами символов.
Синтез резюме: Объединение частичных резюме в целостные обзоры.
Методы обобщения документов с помощью ИИ
Преодоление проблем крупномасштабного суммирования
Резюмирование объемных документов сопряжено с серьезными препятствиями, которые традиционные методы зачастую не могут решить в должной мере. Современные решения на основе ИИ, в частности API OpenAI, предлагают масштабируемые альтернативы, которые позволяют преодолеть ограничения на обработку, сохраняя при этом точность.
Эффективное обобщение требует извлечения важной информации с сохранением контекста и смысла. Специалисты разных отраслей, в том числе ученые, анализирующие исследования, и адвокаты, изучающие контракты, выигрывают от использования этих передовых возможностей.
Методология включает в себя интеллектуальную сегментацию документов, позволяющую систематически обрабатывать управляемые участки контента, соблюдая при этом ограничения API. Такой структурированный подход гарантирует всесторонний охват без ущерба для критически важных деталей, независимо от длины исходного документа.
Основные компоненты процесса суммирования
Рабочий процесс сжатия документов включает в себя несколько основных элементов:
- Обработка входного документа: Поддержка форматов TXT и PDF с автоматическим распознаванием.
- Преобразование PDF: Преобразование содержимого PDF в анализируемый текст с сохранением целостности макета
- Сегментация содержимого: Стратегическое разделение больших документов на оптимальные блоки обработки
- Обработка API: Использование алгоритмов OpenAI для интеллектуального извлечения контента
- Интеграция резюме: Объединяет частичные резюме в единые, целостные обзоры
Детали реализации
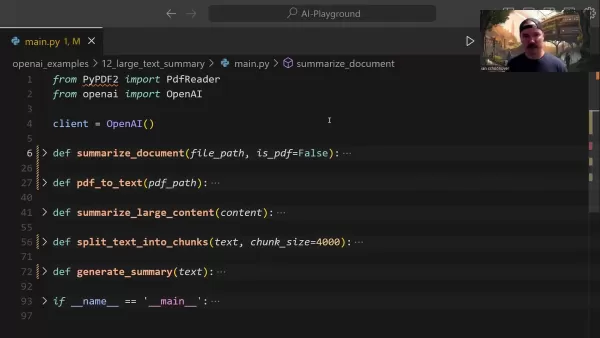
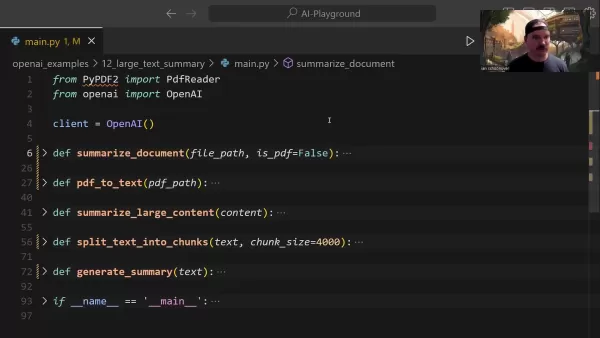
Основная функция подведения итогов
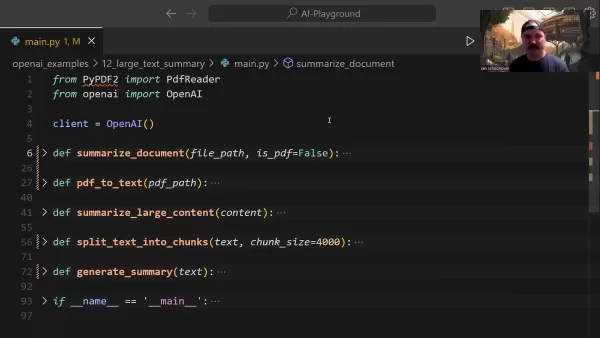
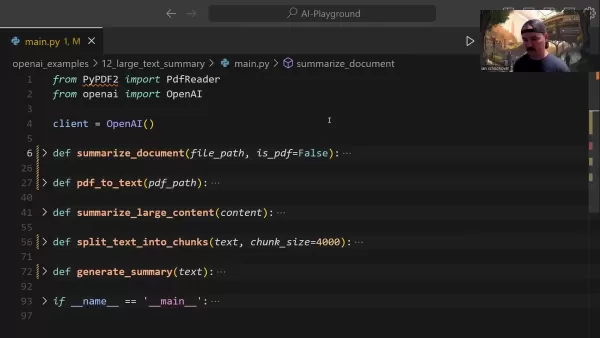
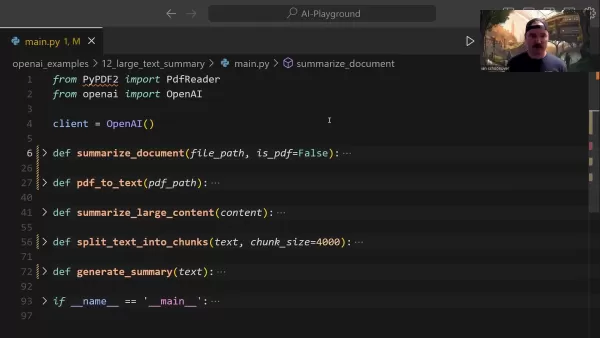
Центральная функция summarize_document управляет всем конвейером обобщения:
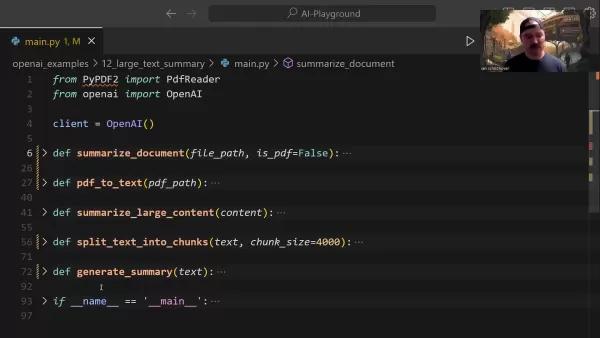
Эта функция интеллектуально обрабатывает распознавание форматов, при необходимости делегирует задачи преобразования и определяет подходящие стратегии обобщения в зависимости от размера документа.
Методология преобразования PDF
В процессе извлечения текста из PDF используются специализированные библиотеки:
Используя PyPDF2, преобразование сохраняет структуру абзацев, эффективно удаляя ненужные элементы форматирования.
Обработка больших документов
Для работы с большим контентом в системе реализована стратегическая сегментация:
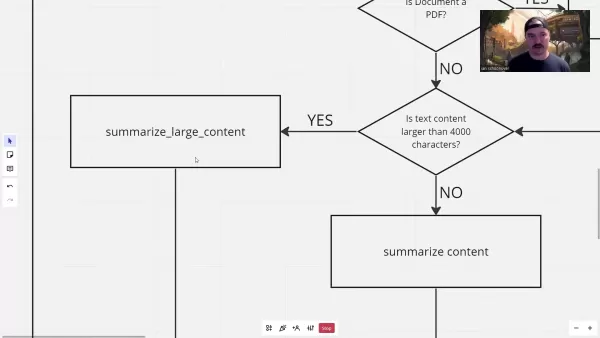
Этот подход сочетает предварительное обобщение фрагментов с окончательной консолидацией для сохранения контекста во всех объемных документах.
Сегментация контента
Алгоритм разбиения на куски обеспечивает оптимальный размер:
Настраиваемые размеры кусков позволяют использовать различные типы документов, соблюдая при этом ограничения API.
Интеграция искусственного интеллекта
Компонент взаимодействия с API обеспечивает интеллектуальное обобщение:
Тщательная настройка параметров обеспечивает баланс между сохранением деталей и краткостью.
Преимущества и соображения
Преимущества
- Масштабируемая обработка: Эффективно обрабатывает документы практически любого размера
- Интеллектуальное извлечение: Точная идентификация и сохранение важной информации
- Гибкость формата: Адаптация к различным структурам и макетам документов
- Повышение эффективности: Значительное сокращение времени на ручное обобщение
- Доступность: Делает плотную информацию более удобоваримой
Ограничения
- Структура затрат: Плата взимается в зависимости от объема обработки
- Требования к подключению: Зависит от стабильного доступа в Интернет
- Контекстные ограничения: Иногда могут быть упущены специализированные нюансы
- Чувствительность данных: Требуется осторожность при работе с конфиденциальной информацией
Общие вопросы
Поддерживаемые типы файлов
В настоящее время система обрабатывает стандартные документы TXT и PDF.
Ограничения по размеру
Интеллектуальная сегментация позволяет обобщать документы произвольного размера.
Спецификации моделей
В реализации используется модель OpenAI gpt-3.5-turbo-1106.
Руководство по реализации
Процесс обобщения PDF
Включите обработку PDF с помощью булевого флага:
document_summary = summarize_document('/document/location/file.pdf', is_pdf=True)
Связанная статья
 Модные короткие стрижки: Лучшие стрижки боб и пикси для любой формы лица
Готовы преобразить свой образ с помощью стильной, но не требующей особого ухода стрижки? Шикарные короткие стрижки доминируют на сцене красоты в 2024 году, предлагая все: от нестареющих бобов до эдаки
Как создать автоматизированную систему голосового искусственного интеллекта - полное руководство
В современной гиперконкурентной бизнес-среде автоматизация стала необходимым условием операционной эффективности и роста доходов. Технология голосового искусственного интеллекта революционизирует взаи
Анализ изображений с помощью искусственного интеллекта преобразует визуальную диагностику с революционной точностью
Искусственный интеллект революционизирует здравоохранение, предоставляя расширенные возможности визуальной диагностики с помощью технологии анализа изображений. Этот инновационный подход позволяет пац
Комментарии (0)
Модные короткие стрижки: Лучшие стрижки боб и пикси для любой формы лица
Готовы преобразить свой образ с помощью стильной, но не требующей особого ухода стрижки? Шикарные короткие стрижки доминируют на сцене красоты в 2024 году, предлагая все: от нестареющих бобов до эдаки
Как создать автоматизированную систему голосового искусственного интеллекта - полное руководство
В современной гиперконкурентной бизнес-среде автоматизация стала необходимым условием операционной эффективности и роста доходов. Технология голосового искусственного интеллекта революционизирует взаи
Анализ изображений с помощью искусственного интеллекта преобразует визуальную диагностику с революционной точностью
Искусственный интеллект революционизирует здравоохранение, предоставляя расширенные возможности визуальной диагностики с помощью технологии анализа изображений. Этот инновационный подход позволяет пац
Комментарии (0)
В современном мире, основанном на данных, эффективная обработка больших объемов информации имеет решающее значение. В этом комплексном руководстве показано, как использовать передовую технологию API OpenAI для обобщения различных текстовых источников, от простых TXT-файлов до сложных PDF-документов. Мы рассмотрим проверенные методы управления огромными документами, их стратегического сегментирования и создания проницательных резюме с помощью искусственного интеллекта. Эти методы идеально подходят для специалистов, работающих с техническими отчетами, академическими исследованиями или юридическими контрактами. Они предлагают практические решения для преобразования перегруженного контента в ценные сведения.
Ключевые моменты
Резюме TXT/PDF: Освоение методов сжатия документов для различных форматов файлов.
Преобразование PDF: Узнайте надежные методы извлечения текста из PDF-документов.
Сегментация документов: Откройте для себя оптимальные подходы к разделению больших файлов.
Интеграция API: Реализуйте мощные возможности обобщения OpenAI.
Учет кодировок: Поймите критические аспекты работы с наборами символов.
Синтез резюме: Объединение частичных резюме в целостные обзоры.
Методы обобщения документов с помощью ИИ
Преодоление проблем крупномасштабного суммирования
Резюмирование объемных документов сопряжено с серьезными препятствиями, которые традиционные методы зачастую не могут решить в должной мере. Современные решения на основе ИИ, в частности API OpenAI, предлагают масштабируемые альтернативы, которые позволяют преодолеть ограничения на обработку, сохраняя при этом точность.
Эффективное обобщение требует извлечения важной информации с сохранением контекста и смысла. Специалисты разных отраслей, в том числе ученые, анализирующие исследования, и адвокаты, изучающие контракты, выигрывают от использования этих передовых возможностей.
Методология включает в себя интеллектуальную сегментацию документов, позволяющую систематически обрабатывать управляемые участки контента, соблюдая при этом ограничения API. Такой структурированный подход гарантирует всесторонний охват без ущерба для критически важных деталей, независимо от длины исходного документа.
Основные компоненты процесса суммирования
Рабочий процесс сжатия документов включает в себя несколько основных элементов:
- Обработка входного документа: Поддержка форматов TXT и PDF с автоматическим распознаванием.
- Преобразование PDF: Преобразование содержимого PDF в анализируемый текст с сохранением целостности макета
- Сегментация содержимого: Стратегическое разделение больших документов на оптимальные блоки обработки
- Обработка API: Использование алгоритмов OpenAI для интеллектуального извлечения контента
- Интеграция резюме: Объединяет частичные резюме в единые, целостные обзоры
Детали реализации
Основная функция подведения итогов
Центральная функция summarize_document управляет всем конвейером обобщения:
Эта функция интеллектуально обрабатывает распознавание форматов, при необходимости делегирует задачи преобразования и определяет подходящие стратегии обобщения в зависимости от размера документа.
Методология преобразования PDF
В процессе извлечения текста из PDF используются специализированные библиотеки:
Используя PyPDF2, преобразование сохраняет структуру абзацев, эффективно удаляя ненужные элементы форматирования.
Обработка больших документов
Для работы с большим контентом в системе реализована стратегическая сегментация:
Этот подход сочетает предварительное обобщение фрагментов с окончательной консолидацией для сохранения контекста во всех объемных документах.
Сегментация контента
Алгоритм разбиения на куски обеспечивает оптимальный размер:
Настраиваемые размеры кусков позволяют использовать различные типы документов, соблюдая при этом ограничения API.
Интеграция искусственного интеллекта
Компонент взаимодействия с API обеспечивает интеллектуальное обобщение:
Тщательная настройка параметров обеспечивает баланс между сохранением деталей и краткостью.
Преимущества и соображения
Преимущества
- Масштабируемая обработка: Эффективно обрабатывает документы практически любого размера
- Интеллектуальное извлечение: Точная идентификация и сохранение важной информации
- Гибкость формата: Адаптация к различным структурам и макетам документов
- Повышение эффективности: Значительное сокращение времени на ручное обобщение
- Доступность: Делает плотную информацию более удобоваримой
Ограничения
- Структура затрат: Плата взимается в зависимости от объема обработки
- Требования к подключению: Зависит от стабильного доступа в Интернет
- Контекстные ограничения: Иногда могут быть упущены специализированные нюансы
- Чувствительность данных: Требуется осторожность при работе с конфиденциальной информацией
Общие вопросы
Поддерживаемые типы файлов
В настоящее время система обрабатывает стандартные документы TXT и PDF.
Ограничения по размеру
Интеллектуальная сегментация позволяет обобщать документы произвольного размера.
Спецификации моделей
В реализации используется модель OpenAI gpt-3.5-turbo-1106.
Руководство по реализации
Процесс обобщения PDF
Включите обработку PDF с помощью булевого флага:
document_summary = summarize_document('/document/location/file.pdf', is_pdf=True)










 Модные короткие стрижки: Лучшие стрижки боб и пикси для любой формы лица
Готовы преобразить свой образ с помощью стильной, но не требующей особого ухода стрижки? Шикарные короткие стрижки доминируют на сцене красоты в 2024 году, предлагая все: от нестареющих бобов до эдаки
Модные короткие стрижки: Лучшие стрижки боб и пикси для любой формы лица
Готовы преобразить свой образ с помощью стильной, но не требующей особого ухода стрижки? Шикарные короткие стрижки доминируют на сцене красоты в 2024 году, предлагая все: от нестареющих бобов до эдаки
 Как создать автоматизированную систему голосового искусственного интеллекта - полное руководство
В современной гиперконкурентной бизнес-среде автоматизация стала необходимым условием операционной эффективности и роста доходов. Технология голосового искусственного интеллекта революционизирует взаи
Как создать автоматизированную систему голосового искусственного интеллекта - полное руководство
В современной гиперконкурентной бизнес-среде автоматизация стала необходимым условием операционной эффективности и роста доходов. Технология голосового искусственного интеллекта революционизирует взаи
 Анализ изображений с помощью искусственного интеллекта преобразует визуальную диагностику с революционной точностью
Искусственный интеллект революционизирует здравоохранение, предоставляя расширенные возможности визуальной диагностики с помощью технологии анализа изображений. Этот инновационный подход позволяет пац
Анализ изображений с помощью искусственного интеллекта преобразует визуальную диагностику с революционной точностью
Искусственный интеллект революционизирует здравоохранение, предоставляя расширенные возможности визуальной диагностики с помощью технологии анализа изображений. Этот инновационный подход позволяет пац













