
















 Home
HomeMaster Large Text Summarization with OpenAI: Ultimate Guide & Techniques
In today's data-driven world, efficiently processing large volumes of information is critical. This comprehensive guide demonstrates how to utilize OpenAI's advanced API technology for summarizing diverse text sources, from basic TXT files to complex PDF documents. We'll explore proven methods for managing oversized documents, segmenting them strategically, and producing insightful summaries through artificial intelligence. Ideal for professionals handling technical reports, academic research, or legal contracts, these techniques provide actionable solutions for transforming overwhelming content into valuable insights.
Key Highlights
TXT/PDF Summarization: Master document condensation techniques for multiple file formats.
PDF Conversion: Learn reliable methods for extracting text from PDF documents.
Document Segmentation: Discover optimal approaches for dividing large files.
API Integration: Implement OpenAI's powerful summarization capabilities.
Encoding Considerations: Understand critical aspects of character set handling.
Summary Synthesis: Combine partial summaries into coherent overviews.
AI-Powered Document Summarization Techniques
Overcoming Large-Scale Summarization Challenges
The summarization of extensive documents presents distinctive obstacles that traditional methods often fail to address adequately. Modern AI solutions, particularly through OpenAI's API, provide scalable alternatives that overcome processing constraints while maintaining accuracy.
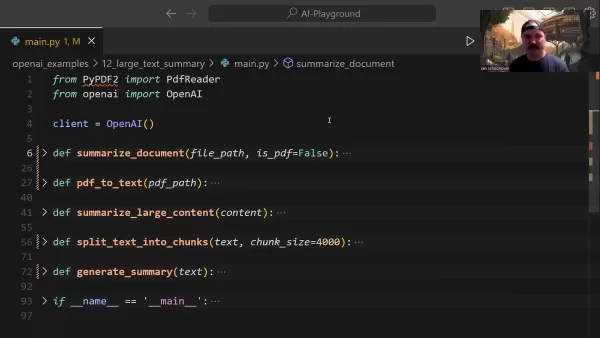
Effective summarization requires extracting essential information while preserving context and meaning. Professionals across industries - including researchers analyzing studies and attorneys reviewing contracts - benefit from these advanced capabilities.
The methodology involves intelligent document segmentation, enabling systematic processing of manageable content sections while respecting API limitations. This structured approach guarantees comprehensive coverage without sacrificing critical details, regardless of original document length.
Core Summarization Process Components
The document condensation workflow incorporates several fundamental elements:
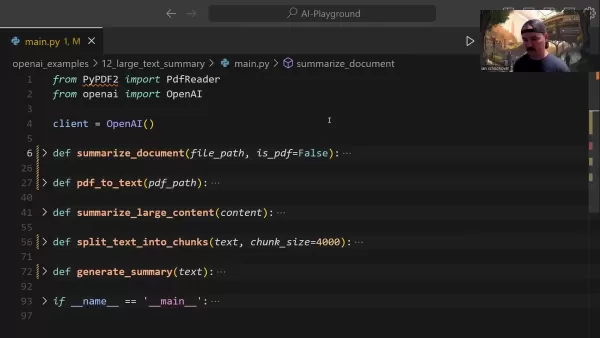
- Document Input Handling: Supports both TXT and PDF formats with automatic detection
- PDF Conversion: Transforms PDF content into analyzable text while maintaining layout integrity
- Content Segmentation: Strategically divides oversized documents into optimal processing units
- API Processing: Harnesses OpenAI's algorithms for intelligent content extraction
- Summary Integration: Combines partial summaries into unified, coherent overviews
Implementation Details
Main Summarization Function
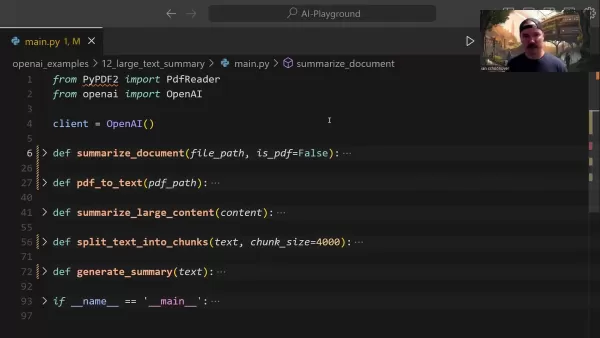
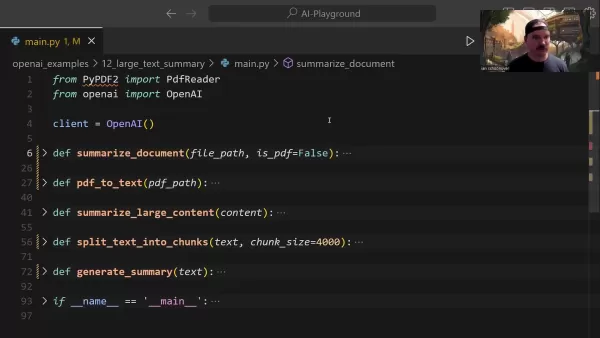
The central summarize_document function manages the entire summarization pipeline:
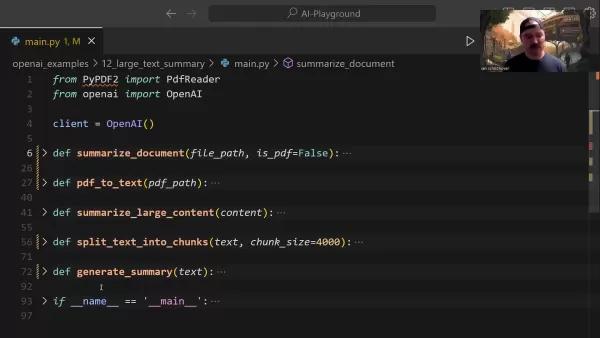
This function intelligently handles format detection, delegates conversion tasks when necessary, and determines appropriate summarization strategies based on document size.
PDF Conversion Methodology
The PDF text extraction process employs specialized libraries:
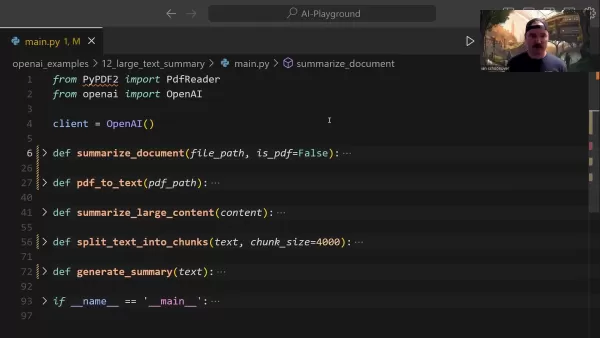
Using PyPDF2, the conversion maintains paragraph structure while efficiently removing unnecessary formatting elements.
Large Document Handling
For oversized content, the system implements strategic segmentation:
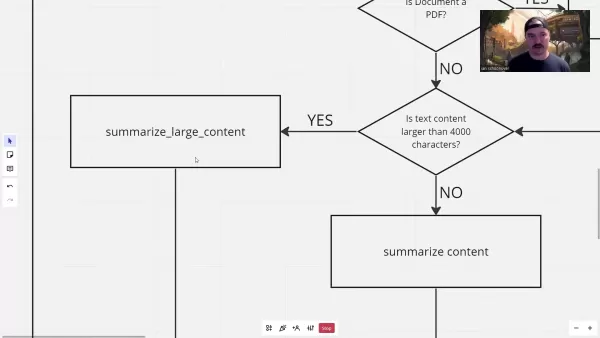
This approach combines preliminary chunk summarization with final consolidation to maintain context throughout lengthy documents.
Content Segmentation
The chunking algorithm ensures optimal sizing:
Configurable chunk sizes accommodate different document types while respecting API constraints.
AI Integration
The API communication component delivers intelligent summarization:
Careful parameter configuration balances detail preservation with conciseness.
Advantages and Considerations
Benefits
- Scalable Processing: Handles documents of virtually any size effectively
- Intelligent Extraction: Identifies and preserves critical information accurately
- Format Flexibility: Adapts to various document structures and layouts
- Efficiency Gains: Dramatically reduces manual summarization time
- Accessibility: Makes dense information more digestible
Limitations
- Cost Structure: Charges apply based on processing volume
- Connectivity Requirements: Dependent on stable internet access
- Contextual Limitations: May occasionally miss specialized nuance
- Data Sensitivity: Requires caution with confidential information
Common Questions
Supported File Types
The system currently processes standard TXT and PDF documents.
Size Restrictions
Intelligent segmentation allows summarization of arbitrarily large documents.
Model Specifications
The implementation utilizes OpenAI's gpt-3.5-turbo-1106 model.
Implementation Guidance
PDF Summarization Process
Enable PDF processing via the boolean flag:
document_summary = summarize_document('/document/location/file.pdf', is_pdf=True)
Related article
 China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Related Special Topic Recommendations
writing
China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Related Special Topic Recommendations
writing
 Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
 10 tools
10 tools
 xix.ai
code
AI Mobile App Coding Tools: Generate Cross-Platform Flutter & React Native Code from Prompts
xix.ai
code
AI Mobile App Coding Tools: Generate Cross-Platform Flutter & React Native Code from Prompts
Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
10 tools
xix.ai
code
Best AI Chrome Extension Generators: Create Custom Browser Add-ons with Zero Coding Experience
Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
10 tools
xix.ai
Text-to-speech
Best AI Multilingual TTS: Generate Authentic Native-Accent Speech in 50+ Languages
Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
10 tools
xix.ai
Meeting Assistant
Best AI Meeting Automation Tools for Smarter and Faster Collaboration
Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
10 tools
xix.ai
Prompt
AI Prompts for Infrastructure-as-Code: Deploy Terraform & Docker Configurations Safely
Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
10 tools
xix.ai

 Comments (1)
0/500
Comments (1)
0/500
![EmmaTurner]()
この記事を読んで、大規模テキスト要約の可能性にますます興味が湧きました!特に基本テキストファイルから複雑な文章まで扱える柔軟性が素晴らしいですね。私は実際に大量のリサーチ論文を要約する必要があって、OpenAIの技術はまさに救世主です🎯。でも、長文要約の精度ってどれくらいなんだろう?細部のニュアンスが抜け落ちないか心配な面もあります。今度試してみたいと思います。
In today's data-driven world, efficiently processing large volumes of information is critical. This comprehensive guide demonstrates how to utilize OpenAI's advanced API technology for summarizing diverse text sources, from basic TXT files to complex PDF documents. We'll explore proven methods for managing oversized documents, segmenting them strategically, and producing insightful summaries through artificial intelligence. Ideal for professionals handling technical reports, academic research, or legal contracts, these techniques provide actionable solutions for transforming overwhelming content into valuable insights.
Key Highlights
TXT/PDF Summarization: Master document condensation techniques for multiple file formats.
PDF Conversion: Learn reliable methods for extracting text from PDF documents.
Document Segmentation: Discover optimal approaches for dividing large files.
API Integration: Implement OpenAI's powerful summarization capabilities.
Encoding Considerations: Understand critical aspects of character set handling.
Summary Synthesis: Combine partial summaries into coherent overviews.
AI-Powered Document Summarization Techniques
Overcoming Large-Scale Summarization Challenges
The summarization of extensive documents presents distinctive obstacles that traditional methods often fail to address adequately. Modern AI solutions, particularly through OpenAI's API, provide scalable alternatives that overcome processing constraints while maintaining accuracy.
Effective summarization requires extracting essential information while preserving context and meaning. Professionals across industries - including researchers analyzing studies and attorneys reviewing contracts - benefit from these advanced capabilities.
The methodology involves intelligent document segmentation, enabling systematic processing of manageable content sections while respecting API limitations. This structured approach guarantees comprehensive coverage without sacrificing critical details, regardless of original document length.
Core Summarization Process Components
The document condensation workflow incorporates several fundamental elements:
- Document Input Handling: Supports both TXT and PDF formats with automatic detection
- PDF Conversion: Transforms PDF content into analyzable text while maintaining layout integrity
- Content Segmentation: Strategically divides oversized documents into optimal processing units
- API Processing: Harnesses OpenAI's algorithms for intelligent content extraction
- Summary Integration: Combines partial summaries into unified, coherent overviews
Implementation Details
Main Summarization Function
The central summarize_document function manages the entire summarization pipeline:
This function intelligently handles format detection, delegates conversion tasks when necessary, and determines appropriate summarization strategies based on document size.
PDF Conversion Methodology
The PDF text extraction process employs specialized libraries:
Using PyPDF2, the conversion maintains paragraph structure while efficiently removing unnecessary formatting elements.
Large Document Handling
For oversized content, the system implements strategic segmentation:
This approach combines preliminary chunk summarization with final consolidation to maintain context throughout lengthy documents.
Content Segmentation
The chunking algorithm ensures optimal sizing:
Configurable chunk sizes accommodate different document types while respecting API constraints.
AI Integration
The API communication component delivers intelligent summarization:
Careful parameter configuration balances detail preservation with conciseness.
Advantages and Considerations
Benefits
- Scalable Processing: Handles documents of virtually any size effectively
- Intelligent Extraction: Identifies and preserves critical information accurately
- Format Flexibility: Adapts to various document structures and layouts
- Efficiency Gains: Dramatically reduces manual summarization time
- Accessibility: Makes dense information more digestible
Limitations
- Cost Structure: Charges apply based on processing volume
- Connectivity Requirements: Dependent on stable internet access
- Contextual Limitations: May occasionally miss specialized nuance
- Data Sensitivity: Requires caution with confidential information
Common Questions
Supported File Types
The system currently processes standard TXT and PDF documents.
Size Restrictions
Intelligent segmentation allows summarization of arbitrarily large documents.
Model Specifications
The implementation utilizes OpenAI's gpt-3.5-turbo-1106 model.
Implementation Guidance
PDF Summarization Process
Enable PDF processing via the boolean flag:
document_summary = summarize_document('/document/location/file.pdf', is_pdf=True)










 China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
 Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
 Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i

Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
10 tools
xix.ai

Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
10 tools
xix.ai

Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
10 tools
xix.ai

Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
10 tools
xix.ai

Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
10 tools
xix.ai

この記事を読んで、大規模テキスト要約の可能性にますます興味が湧きました!特に基本テキストファイルから複雑な文章まで扱える柔軟性が素晴らしいですね。私は実際に大量のリサーチ論文を要約する必要があって、OpenAIの技術はまさに救世主です🎯。でも、長文要約の精度ってどれくらいなんだろう?細部のニュアンスが抜け落ちないか心配な面もあります。今度試してみたいと思います。













