
















 家
家OpenAIで大規模テキストの要約をマスター:究極のガイドとテクニック
今日のデータ主導の世界では、大量の情報を効率的に処理することが重要です。この包括的なガイドでは、基本的なTXTファイルから複雑なPDF文書まで、多様なテキストソースを要約するためのOpenAIの高度なAPI技術の活用方法を示します。大量のドキュメントを管理し、戦略的にセグメント化し、人工知能を通して洞察力のある要約を作成するための実証済みの方法を探ります。技術レポート、学術研究、または法的契約を扱う専門家に最適なこれらのテクニックは、圧倒的なコンテンツを価値ある洞察に変換するための実用的なソリューションを提供します。
主なハイライト
TXT/PDF要約:複数のファイル形式に対応した文書要約テクニックをマスターします。
PDF変換:PDF文書からテキストを抽出する信頼性の高い方法を習得します。
ドキュメントの分割大きなファイルを分割するための最適なアプローチを発見します。
APIの統合OpenAIの強力な要約機能を実装します。
エンコーディングの考慮文字セット処理の重要な側面を理解します。
要約の統合部分的な要約を首尾一貫した概要にまとめます。
AIによる文書要約技術
大規模要約の課題を克服する
膨大な文書の要約には、従来の方法ではしばしば適切に対処できない特有の障害があります。最新のAIソリューションは、特にOpenAIのAPIを通じて、精度を維持しながら処理の制約を克服するスケーラブルな代替手段を提供する。
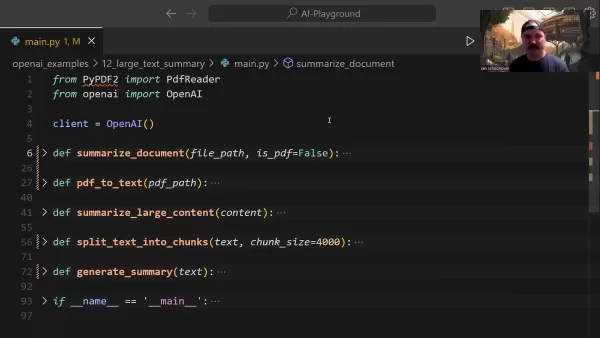
効果的な要約には、文脈と意味を保ちながら必要な情報を抽出する必要があります。研究を分析する研究者や契約を見直す弁護士など、業界を問わず専門家は、これらの高度な機能から利益を得ている。
この方法論には、インテリジェントなドキュメントのセグメンテーションが含まれ、APIの制限を尊重しながら、管理可能なコンテンツセクションの体系的な処理を可能にします。この構造化されたアプローチは、元のドキュメントの長さに関係なく、重要な詳細を犠牲にすることなく、包括的なカバレッジを保証します。
要約プロセスのコアコンポーネント
ドキュメントの要約ワークフローには、いくつかの基本的な要素が組み込まれています:
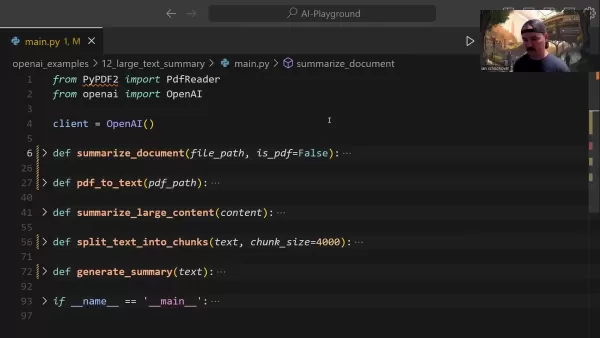
- ドキュメント入力処理:自動検出により、TXTとPDFの両方の形式をサポートします。
- PDF変換:レイアウトの整合性を維持しながら、PDFコンテンツを分析可能なテキストに変換します。
- コンテンツの分割:特大文書を最適な処理単位に戦略的に分割
- API処理:インテリジェントなコンテンツ抽出にOpenAIのアルゴリズムを活用
- 要約の統合:部分的な要約を統一された首尾一貫した概要に統合する
実装の詳細
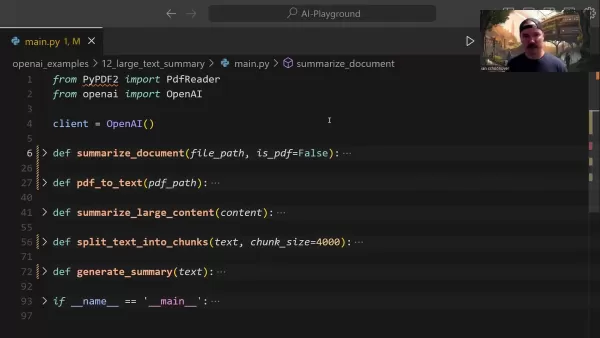
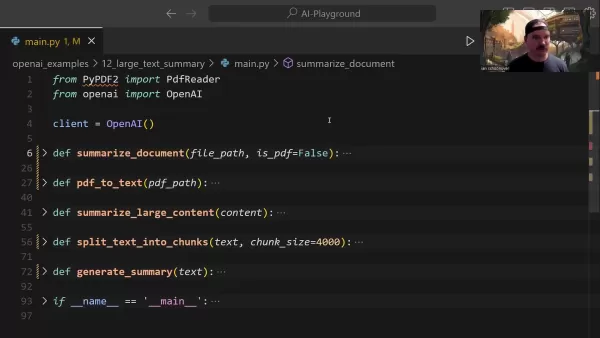
主な要約機能
中心となるsummarize_document関数は要約パイプライン全体を管理する:
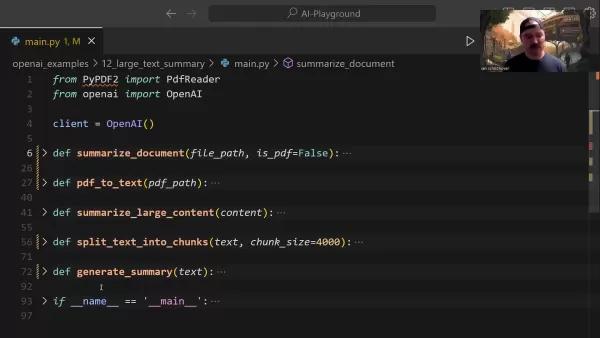
この関数はインテリジェントにフォーマット検出を処理し、必要に応じて変換タスクを委譲し、文書のサイズに基づいて適切な要約戦略を決定する。
PDF 変換手法
PDFテキスト抽出プロセスでは、専用のライブラリを使用しています:
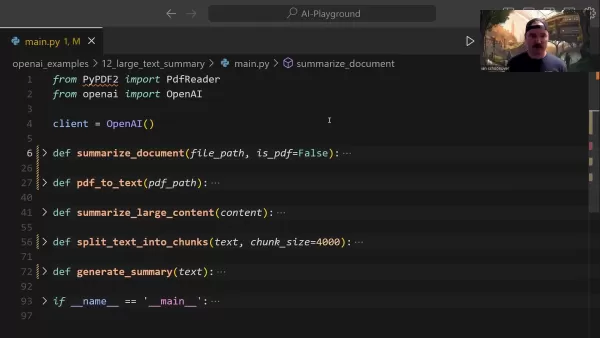
PyPDF2を使用して、不要な書式要素を効率的に削除しながら段落構造を維持します。
大型文書の処理
巨大なコンテンツに対して、システムは戦略的セグメンテーションを実装しています:
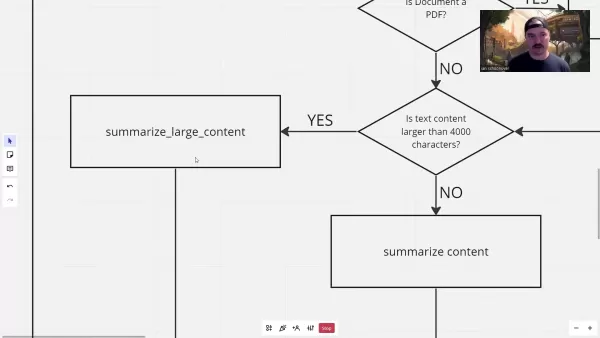
このアプローチでは、予備的なチャンクの要約と最終的な統合を組み合わせることで、長い文書全体の文脈を維持します。
コンテンツのセグメンテーション
チャンキングアルゴリズムにより、最適なサイズ設定が可能です:
設定可能なチャンクサイズは、APIの制約を尊重しながら、さまざまな種類のドキュメントに対応します。
AIインテグレーション
API通信コンポーネントがインテリジェントな要約を実現します:
注意深くパラメータを設定することで、詳細の保持と簡潔さのバランスを保ちます。
利点と考慮点
利点
- スケーラブルな処理:事実上あらゆるサイズのドキュメントを効果的に処理
- インテリジェントな抽出:重要な情報を正確に特定し、保存
- フォーマットの柔軟性:さまざまな文書構造やレイアウトに対応
- 効率性の向上:手作業による要約時間を大幅に短縮
- アクセシビリティ:濃い情報をより消化しやすくする
制限事項
- コスト構造:処理量に応じて課金
- 接続要件:安定したインターネットアクセスに依存
- 文脈上の制限:専門的なニュアンスを見逃すことがある
- データの機密性:機密情報の取り扱いに注意が必要
よくある質問
サポートされるファイルタイプ
システムは現在、標準的なTXTおよびPDF文書を処理します。
サイズの制限
インテリジェントなセグメンテーションにより、任意のサイズの文書を要約できます。
モデルの仕様
実装はOpenAIのgpt-3.5-turbo-1106モデルを利用しています。
実装ガイダンス
PDF要約処理
booleanフラグでPDF処理を有効にします:
document_summary = summarize_document('/document/location/file.pdf', is_pdf=True)
関連記事
 Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
Luma AI、テキストとピクセルを同時に生成する自己回帰モデル「Uni-1」を発表
Luma Labsは3月23日、画像生成モデル「Uni-1」をリリースしました。これは、同社の「Unified Intelligence」アーキテクチャに基づいて構築された、初の一般公開モデルとなります。現在、公式サイトにて無料トライアルの提供が開始されており、APIの料金体系も発表されました。また、企業向けアクセスチャネルも順次展開される予定です。アーキテクチャの転換:拡散モデルから自己回帰モデ
NVIDIAのウー・シンジョウ氏:自動運転における「ChatGPT的瞬間」が到来、レベル4の量産はもはや夢ではない
急速に進化する物理AIの分野において、自動運転は克服すべき最初の大きな課題と見なされることが多い。 最近、NVIDIAの副社長であるウー・シンジョウ氏は、北京で開催されたイベントで、同社のインテリジェント・ドライビングに関する野心的なビジョンを概説した。同氏は、運転支援を支える「5層ケーキ」アーキテクチャについて説明しただけでなく、レベル4の自動運転の展開に向けた明確なロードマップも提示した。「5
関連特集おすすめ
チャットボット
Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
Luma AI、テキストとピクセルを同時に生成する自己回帰モデル「Uni-1」を発表
Luma Labsは3月23日、画像生成モデル「Uni-1」をリリースしました。これは、同社の「Unified Intelligence」アーキテクチャに基づいて構築された、初の一般公開モデルとなります。現在、公式サイトにて無料トライアルの提供が開始されており、APIの料金体系も発表されました。また、企業向けアクセスチャネルも順次展開される予定です。アーキテクチャの転換:拡散モデルから自己回帰モデ
NVIDIAのウー・シンジョウ氏:自動運転における「ChatGPT的瞬間」が到来、レベル4の量産はもはや夢ではない
急速に進化する物理AIの分野において、自動運転は克服すべき最初の大きな課題と見なされることが多い。 最近、NVIDIAの副社長であるウー・シンジョウ氏は、北京で開催されたイベントで、同社のインテリジェント・ドライビングに関する野心的なビジョンを概説した。同氏は、運転支援を支える「5層ケーキ」アーキテクチャについて説明しただけでなく、レベル4の自動運転の展開に向けた明確なロードマップも提示した。「5
関連特集おすすめ
チャットボット
 高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
 10 ツール
10 ツール
 xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai
ソーシャルメディア
ソーシャルメディア向けAIブランディングキット:すべてのチャネルで一貫したブランドビジュアルを維持
2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![EmmaTurner]()
この記事を読んで、大規模テキスト要約の可能性にますます興味が湧きました!特に基本テキストファイルから複雑な文章まで扱える柔軟性が素晴らしいですね。私は実際に大量のリサーチ論文を要約する必要があって、OpenAIの技術はまさに救世主です🎯。でも、長文要約の精度ってどれくらいなんだろう?細部のニュアンスが抜け落ちないか心配な面もあります。今度試してみたいと思います。
今日のデータ主導の世界では、大量の情報を効率的に処理することが重要です。この包括的なガイドでは、基本的なTXTファイルから複雑なPDF文書まで、多様なテキストソースを要約するためのOpenAIの高度なAPI技術の活用方法を示します。大量のドキュメントを管理し、戦略的にセグメント化し、人工知能を通して洞察力のある要約を作成するための実証済みの方法を探ります。技術レポート、学術研究、または法的契約を扱う専門家に最適なこれらのテクニックは、圧倒的なコンテンツを価値ある洞察に変換するための実用的なソリューションを提供します。
主なハイライト
TXT/PDF要約:複数のファイル形式に対応した文書要約テクニックをマスターします。
PDF変換:PDF文書からテキストを抽出する信頼性の高い方法を習得します。
ドキュメントの分割大きなファイルを分割するための最適なアプローチを発見します。
APIの統合OpenAIの強力な要約機能を実装します。
エンコーディングの考慮文字セット処理の重要な側面を理解します。
要約の統合部分的な要約を首尾一貫した概要にまとめます。
AIによる文書要約技術
大規模要約の課題を克服する
膨大な文書の要約には、従来の方法ではしばしば適切に対処できない特有の障害があります。最新のAIソリューションは、特にOpenAIのAPIを通じて、精度を維持しながら処理の制約を克服するスケーラブルな代替手段を提供する。
効果的な要約には、文脈と意味を保ちながら必要な情報を抽出する必要があります。研究を分析する研究者や契約を見直す弁護士など、業界を問わず専門家は、これらの高度な機能から利益を得ている。
この方法論には、インテリジェントなドキュメントのセグメンテーションが含まれ、APIの制限を尊重しながら、管理可能なコンテンツセクションの体系的な処理を可能にします。この構造化されたアプローチは、元のドキュメントの長さに関係なく、重要な詳細を犠牲にすることなく、包括的なカバレッジを保証します。
要約プロセスのコアコンポーネント
ドキュメントの要約ワークフローには、いくつかの基本的な要素が組み込まれています:
- ドキュメント入力処理:自動検出により、TXTとPDFの両方の形式をサポートします。
- PDF変換:レイアウトの整合性を維持しながら、PDFコンテンツを分析可能なテキストに変換します。
- コンテンツの分割:特大文書を最適な処理単位に戦略的に分割
- API処理:インテリジェントなコンテンツ抽出にOpenAIのアルゴリズムを活用
- 要約の統合:部分的な要約を統一された首尾一貫した概要に統合する
実装の詳細
主な要約機能
中心となるsummarize_document関数は要約パイプライン全体を管理する:
この関数はインテリジェントにフォーマット検出を処理し、必要に応じて変換タスクを委譲し、文書のサイズに基づいて適切な要約戦略を決定する。
PDF 変換手法
PDFテキスト抽出プロセスでは、専用のライブラリを使用しています:
PyPDF2を使用して、不要な書式要素を効率的に削除しながら段落構造を維持します。
大型文書の処理
巨大なコンテンツに対して、システムは戦略的セグメンテーションを実装しています:
このアプローチでは、予備的なチャンクの要約と最終的な統合を組み合わせることで、長い文書全体の文脈を維持します。
コンテンツのセグメンテーション
チャンキングアルゴリズムにより、最適なサイズ設定が可能です:
設定可能なチャンクサイズは、APIの制約を尊重しながら、さまざまな種類のドキュメントに対応します。
AIインテグレーション
API通信コンポーネントがインテリジェントな要約を実現します:
注意深くパラメータを設定することで、詳細の保持と簡潔さのバランスを保ちます。
利点と考慮点
利点
- スケーラブルな処理:事実上あらゆるサイズのドキュメントを効果的に処理
- インテリジェントな抽出:重要な情報を正確に特定し、保存
- フォーマットの柔軟性:さまざまな文書構造やレイアウトに対応
- 効率性の向上:手作業による要約時間を大幅に短縮
- アクセシビリティ:濃い情報をより消化しやすくする
制限事項
- コスト構造:処理量に応じて課金
- 接続要件:安定したインターネットアクセスに依存
- 文脈上の制限:専門的なニュアンスを見逃すことがある
- データの機密性:機密情報の取り扱いに注意が必要
よくある質問
サポートされるファイルタイプ
システムは現在、標準的なTXTおよびPDF文書を処理します。
サイズの制限
インテリジェントなセグメンテーションにより、任意のサイズの文書を要約できます。
モデルの仕様
実装はOpenAIのgpt-3.5-turbo-1106モデルを利用しています。
実装ガイダンス
PDF要約処理
booleanフラグでPDF処理を有効にします:
document_summary = summarize_document('/document/location/file.pdf', is_pdf=True)










 Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
 Luma AI、テキストとピクセルを同時に生成する自己回帰モデル「Uni-1」を発表
Luma Labsは3月23日、画像生成モデル「Uni-1」をリリースしました。これは、同社の「Unified Intelligence」アーキテクチャに基づいて構築された、初の一般公開モデルとなります。現在、公式サイトにて無料トライアルの提供が開始されており、APIの料金体系も発表されました。また、企業向けアクセスチャネルも順次展開される予定です。アーキテクチャの転換:拡散モデルから自己回帰モデ
Luma AI、テキストとピクセルを同時に生成する自己回帰モデル「Uni-1」を発表
Luma Labsは3月23日、画像生成モデル「Uni-1」をリリースしました。これは、同社の「Unified Intelligence」アーキテクチャに基づいて構築された、初の一般公開モデルとなります。現在、公式サイトにて無料トライアルの提供が開始されており、APIの料金体系も発表されました。また、企業向けアクセスチャネルも順次展開される予定です。アーキテクチャの転換:拡散モデルから自己回帰モデ
 NVIDIAのウー・シンジョウ氏:自動運転における「ChatGPT的瞬間」が到来、レベル4の量産はもはや夢ではない
急速に進化する物理AIの分野において、自動運転は克服すべき最初の大きな課題と見なされることが多い。 最近、NVIDIAの副社長であるウー・シンジョウ氏は、北京で開催されたイベントで、同社のインテリジェント・ドライビングに関する野心的なビジョンを概説した。同氏は、運転支援を支える「5層ケーキ」アーキテクチャについて説明しただけでなく、レベル4の自動運転の展開に向けた明確なロードマップも提示した。「5
NVIDIAのウー・シンジョウ氏:自動運転における「ChatGPT的瞬間」が到来、レベル4の量産はもはや夢ではない
急速に進化する物理AIの分野において、自動運転は克服すべき最初の大きな課題と見なされることが多い。 最近、NVIDIAの副社長であるウー・シンジョウ氏は、北京で開催されたイベントで、同社のインテリジェント・ドライビングに関する野心的なビジョンを概説した。同氏は、運転支援を支える「5層ケーキ」アーキテクチャについて説明しただけでなく、レベル4の自動運転の展開に向けた明確なロードマップも提示した。「5

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

この記事を読んで、大規模テキスト要約の可能性にますます興味が湧きました!特に基本テキストファイルから複雑な文章まで扱える柔軟性が素晴らしいですね。私は実際に大量のリサーチ論文を要約する必要があって、OpenAIの技術はまさに救世主です🎯。でも、長文要約の精度ってどれくらいなんだろう?細部のニュアンスが抜け落ちないか心配な面もあります。今度試してみたいと思います。













