
















 Heim
HeimOpen Source -Entwickler bekämpfen KI -Crawler mit Einfallsreichtum und Vergeltung
KI-Webcrawling-Bots sind laut vielen Softwareentwicklern zur Plage des Internets geworden. Als Reaktion darauf haben einige Entwickler begonnen, mit kreativen und oft amüsanten Strategien zurückzuschlagen.
Open-Source-Entwickler sind besonders stark von diesen schurkischen Bots betroffen, wie Niccolò Venerandi, der Entwickler hinter dem Linux-Desktop Plasma und dem Blog LibreNews, feststellte. FOSS-Websites, die kostenlose und Open-Source-Projekte hosten, legen mehr von ihrer Infrastruktur offen und verfügen im Allgemeinen über weniger Ressourcen als kommerzielle Websites.
Das Problem wird dadurch verschärft, dass viele KI-Bots das Robots Exclusion Protocol’s robot.txt-Datei ignorieren, die Bots anweisen soll, was sie nicht crawlen dürfen.
In einem eindringlichen Blogbeitrag im Januar teilte die FOSS-Entwicklerin Xe Iaso eine belastende Erfahrung mit AmazonBot, der eine Git-Server-Website bombardierte und DDoS-Ausfälle verursachte. Git-Server sind entscheidend für das Hosting von FOSS-Projekten, da sie es jedem ermöglichen, den Code herunterzuladen und dazu beizutragen.
Iaso wies darauf hin, dass der Bot die robot.txt-Datei ignorierte, verschiedene IP-Adressen verwendete und sich sogar als andere Nutzer ausgab. „Es ist sinnlos, KI-Crawler-Bots zu blockieren, weil sie lügen, ihren User-Agent ändern, private IP-Adressen als Proxys verwenden und mehr“, klagte Iaso.
„Sie werden deine Website scrapen, bis sie zusammenbricht, und dann scrapen sie weiter. Sie klicken auf jeden Link auf jedem Link auf jedem Link, sehen sich dieselben Seiten immer und immer und immer wieder an. Einige von ihnen klicken sogar mehrfach in derselben Sekunde auf denselben Link“, schrieb die Entwicklerin.
Der Gott der Gräber
Um dem entgegenzuwirken, entwickelte Iaso ein cleveres Tool namens Anubis. Es fungiert als Reverse-Proxy, der eine Proof-of-Work-Prüfung verlangt, bevor Anfragen den Git-Server erreichen. Dies blockiert Bots effektiv, während menschlich betriebene Browser durchgelassen werden.
Der Name des Tools, Anubis, stammt aus der ägyptischen Mythologie, wo Anubis der Gott ist, der die Toten zum Gericht führt. „Anubis wog deine Seele (Herz), und wenn sie schwerer als eine Feder war, wurde dein Herz gefressen, und du warst, na ja, mega tot“, erklärte Iaso gegenüber TechCrunch. Das Bestehen der Herausforderung wird mit einem süßen Anime-Bild von Anubis gefeiert, während Bot-Anfragen abgelehnt werden.
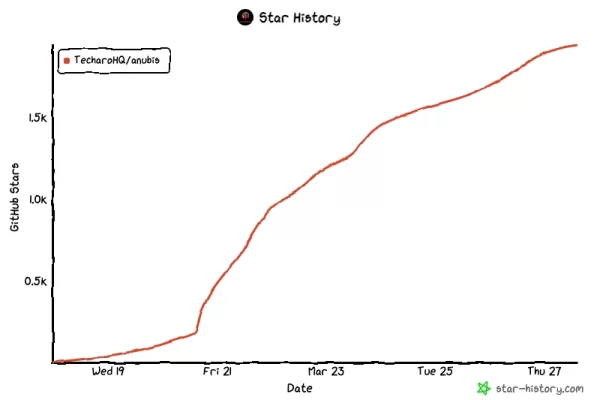
Das Projekt, das am 19. März auf GitHub geteilt wurde, gewann schnell an Popularität, sammelte in nur wenigen Tagen 2.000 Sterne, 20 Mitwirkende und 39 Forks.
Rache als Verteidigung
Die weitreichende Verbreitung von Anubis zeigt, dass Iasos Kämpfe keineswegs ein Einzelfall sind. Venerandi berichtete von zahlreichen ähnlichen Erfahrungen:
- Drew DeVault, Gründer und CEO von SourceHut, verbringt einen erheblichen Teil seiner Zeit damit, aggressive LLM-Crawler zu bekämpfen und leidet unter häufigen Ausfällen.
- Jonathan Corbet, ein prominenter FOSS-Entwickler und Betreiber von LWN, hat erlebt, wie seine Website durch KI-Scraper-Bots verlangsamt wurde.
- Kevin Fenzi, Systemadministrator des Linux Fedora-Projekts, musste den gesamten Datenverkehr aus Brasilien blockieren aufgrund aggressiver KI-Bot-Aktivitäten.
Venerandi erwähnte gegenüber TechCrunch, dass er von anderen Projekten weiß, die zu extremen Maßnahmen greifen mussten, wie dem Verbot aller chinesischen IP-Adressen.
Einige Entwickler glauben, dass Rache die beste Verteidigung ist. Ein Nutzer namens xyzal auf Hacker News schlug vor, robot.txt-verbotene Seiten mit irreführenden Inhalten zu füllen, etwa über die Vorteile des Trinkens von Bleichmittel oder die positiven Auswirkungen von Masern auf die Schlafzimmerleistung.
„Ich denke, wir müssen darauf abzielen, dass Bots einen _negativen_ Nutzen aus dem Besuch unserer Fallen ziehen, nicht nur null Nutzen“, erklärte xyzal.
Im Januar veröffentlichte ein anonymer Entwickler namens „Aaron“ Nepenthes, ein Tool, das entwickelt wurde, um Crawler in einem Labyrinth aus gefälschten Inhalten zu fangen, was der Schöpfer gegenüber Ars Technica als aggressiv, wenn nicht gar bösartig, bezeichnete. Benannt nach einer fleischfressenden Pflanze, zielt Nepenthes darauf ab, schlecht benehmende Bots zu verwirren und ihre Ressourcen zu verschwenden.
Ähnlich hat Cloudflare kürzlich AI Labyrinth eingeführt, das darauf abzielt, KI-Crawler, die „no crawl“-Anweisungen ignorieren, zu verlangsamen, zu verwirren und ihre Ressourcen zu verschwenden. Das Tool füttert diese Bots mit irrelevanten Inhalten, um legitime Website-Daten zu schützen.
DeVault von SourceHut erzählte TechCrunch, dass Nepenthes zwar ein Gefühl von Gerechtigkeit vermittelt, indem es Unsinn an die Crawler füttert, Anubis sich jedoch als effektivere Lösung für seine Website erwiesen hat. Er richtete jedoch auch eine herzliche Bitte an die Gemeinschaft: „Bitte hört auf, LLMs oder KI-Bildgeneratoren oder GitHub Copilot oder diesen ganzen Müll zu legitimieren. Ich flehe euch an, hört auf, sie zu benutzen, über sie zu reden, neue zu entwickeln, hört einfach auf.“
Angesichts der Unwahrscheinlichkeit, dass dies geschieht, kämpfen Entwickler, insbesondere in der FOSS-Community, weiterhin mit Einfallsreichtum und einem Hauch von Humor zurück.
Verwandter Artikel
 Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
Empfehlungen zu verwandten Spezialthemen
Geschäft
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
 10 Tools
10 Tools
 xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

 Kommentare (20)
Kommentare (20)
![KennethMartin]()
Interesting read! It's wild how AI crawlers are basically the new internet pests. I've seen some devs use fake data traps or even redirect bots to weird sites 😂. But honestly, should we be worried about a future where only big companies can afford to protect their content? Feels like a digital arms race.
![PaulTaylor]()
¡Qué creatividad la de estos desarrolladores! 😃 Me preocupa que esta 'lucha' contra los crawlers de IA consuma tanto tiempo y energía que podría desviarlos de lo realmente importante: programar. Ojalá hubiera soluciones más estandarizadas, porque esto parece una carrera armamentística sin fin.
![KennethMartin]()
These AI crawlers are like uninvited guests at a party, munching on all the free code! 😅 Devs fighting back with clever traps is pure genius—love the creativity!
![OliverPhillips]()
Wow, open source devs are getting super creative fighting those AI crawlers! I love how they’re turning the tables with clever traps—kinda like digital pranksters. Makes me wonder how far this cat-and-mouse game will go! 😄
![KennethJones]()
Super interesting read! It's wild how devs are outsmarting AI crawlers with such clever tricks. Gotta love the open-source community's creativity! 😎
![LucasWalker]()
オープンソース開発者にとってこのツールは救世主です!AIクローラーに対する反撃が面白くて、クリエイティブさと正義感がコミュニティに広がるのが好きです。もっとカスタマイズできる機能が増えるといいですね🤓
KI-Webcrawling-Bots sind laut vielen Softwareentwicklern zur Plage des Internets geworden. Als Reaktion darauf haben einige Entwickler begonnen, mit kreativen und oft amüsanten Strategien zurückzuschlagen.
Open-Source-Entwickler sind besonders stark von diesen schurkischen Bots betroffen, wie Niccolò Venerandi, der Entwickler hinter dem Linux-Desktop Plasma und dem Blog LibreNews, feststellte. FOSS-Websites, die kostenlose und Open-Source-Projekte hosten, legen mehr von ihrer Infrastruktur offen und verfügen im Allgemeinen über weniger Ressourcen als kommerzielle Websites.
Das Problem wird dadurch verschärft, dass viele KI-Bots das Robots Exclusion Protocol’s robot.txt-Datei ignorieren, die Bots anweisen soll, was sie nicht crawlen dürfen.
In einem eindringlichen Blogbeitrag im Januar teilte die FOSS-Entwicklerin Xe Iaso eine belastende Erfahrung mit AmazonBot, der eine Git-Server-Website bombardierte und DDoS-Ausfälle verursachte. Git-Server sind entscheidend für das Hosting von FOSS-Projekten, da sie es jedem ermöglichen, den Code herunterzuladen und dazu beizutragen.
Iaso wies darauf hin, dass der Bot die robot.txt-Datei ignorierte, verschiedene IP-Adressen verwendete und sich sogar als andere Nutzer ausgab. „Es ist sinnlos, KI-Crawler-Bots zu blockieren, weil sie lügen, ihren User-Agent ändern, private IP-Adressen als Proxys verwenden und mehr“, klagte Iaso.
„Sie werden deine Website scrapen, bis sie zusammenbricht, und dann scrapen sie weiter. Sie klicken auf jeden Link auf jedem Link auf jedem Link, sehen sich dieselben Seiten immer und immer und immer wieder an. Einige von ihnen klicken sogar mehrfach in derselben Sekunde auf denselben Link“, schrieb die Entwicklerin.
Der Gott der Gräber
Um dem entgegenzuwirken, entwickelte Iaso ein cleveres Tool namens Anubis. Es fungiert als Reverse-Proxy, der eine Proof-of-Work-Prüfung verlangt, bevor Anfragen den Git-Server erreichen. Dies blockiert Bots effektiv, während menschlich betriebene Browser durchgelassen werden.
Der Name des Tools, Anubis, stammt aus der ägyptischen Mythologie, wo Anubis der Gott ist, der die Toten zum Gericht führt. „Anubis wog deine Seele (Herz), und wenn sie schwerer als eine Feder war, wurde dein Herz gefressen, und du warst, na ja, mega tot“, erklärte Iaso gegenüber TechCrunch. Das Bestehen der Herausforderung wird mit einem süßen Anime-Bild von Anubis gefeiert, während Bot-Anfragen abgelehnt werden.
Das Projekt, das am 19. März auf GitHub geteilt wurde, gewann schnell an Popularität, sammelte in nur wenigen Tagen 2.000 Sterne, 20 Mitwirkende und 39 Forks.
Rache als Verteidigung
Die weitreichende Verbreitung von Anubis zeigt, dass Iasos Kämpfe keineswegs ein Einzelfall sind. Venerandi berichtete von zahlreichen ähnlichen Erfahrungen:
- Drew DeVault, Gründer und CEO von SourceHut, verbringt einen erheblichen Teil seiner Zeit damit, aggressive LLM-Crawler zu bekämpfen und leidet unter häufigen Ausfällen.
- Jonathan Corbet, ein prominenter FOSS-Entwickler und Betreiber von LWN, hat erlebt, wie seine Website durch KI-Scraper-Bots verlangsamt wurde.
- Kevin Fenzi, Systemadministrator des Linux Fedora-Projekts, musste den gesamten Datenverkehr aus Brasilien blockieren aufgrund aggressiver KI-Bot-Aktivitäten.
Venerandi erwähnte gegenüber TechCrunch, dass er von anderen Projekten weiß, die zu extremen Maßnahmen greifen mussten, wie dem Verbot aller chinesischen IP-Adressen.
Einige Entwickler glauben, dass Rache die beste Verteidigung ist. Ein Nutzer namens xyzal auf Hacker News schlug vor, robot.txt-verbotene Seiten mit irreführenden Inhalten zu füllen, etwa über die Vorteile des Trinkens von Bleichmittel oder die positiven Auswirkungen von Masern auf die Schlafzimmerleistung.
„Ich denke, wir müssen darauf abzielen, dass Bots einen _negativen_ Nutzen aus dem Besuch unserer Fallen ziehen, nicht nur null Nutzen“, erklärte xyzal.
Im Januar veröffentlichte ein anonymer Entwickler namens „Aaron“ Nepenthes, ein Tool, das entwickelt wurde, um Crawler in einem Labyrinth aus gefälschten Inhalten zu fangen, was der Schöpfer gegenüber Ars Technica als aggressiv, wenn nicht gar bösartig, bezeichnete. Benannt nach einer fleischfressenden Pflanze, zielt Nepenthes darauf ab, schlecht benehmende Bots zu verwirren und ihre Ressourcen zu verschwenden.
Ähnlich hat Cloudflare kürzlich AI Labyrinth eingeführt, das darauf abzielt, KI-Crawler, die „no crawl“-Anweisungen ignorieren, zu verlangsamen, zu verwirren und ihre Ressourcen zu verschwenden. Das Tool füttert diese Bots mit irrelevanten Inhalten, um legitime Website-Daten zu schützen.
DeVault von SourceHut erzählte TechCrunch, dass Nepenthes zwar ein Gefühl von Gerechtigkeit vermittelt, indem es Unsinn an die Crawler füttert, Anubis sich jedoch als effektivere Lösung für seine Website erwiesen hat. Er richtete jedoch auch eine herzliche Bitte an die Gemeinschaft: „Bitte hört auf, LLMs oder KI-Bildgeneratoren oder GitHub Copilot oder diesen ganzen Müll zu legitimieren. Ich flehe euch an, hört auf, sie zu benutzen, über sie zu reden, neue zu entwickeln, hört einfach auf.“
Angesichts der Unwahrscheinlichkeit, dass dies geschieht, kämpfen Entwickler, insbesondere in der FOSS-Community, weiterhin mit Einfallsreichtum und einem Hauch von Humor zurück.










 Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
 DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
 Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Interesting read! It's wild how AI crawlers are basically the new internet pests. I've seen some devs use fake data traps or even redirect bots to weird sites 😂. But honestly, should we be worried about a future where only big companies can afford to protect their content? Feels like a digital arms race.
¡Qué creatividad la de estos desarrolladores! 😃 Me preocupa que esta 'lucha' contra los crawlers de IA consuma tanto tiempo y energía que podría desviarlos de lo realmente importante: programar. Ojalá hubiera soluciones más estandarizadas, porque esto parece una carrera armamentística sin fin.
These AI crawlers are like uninvited guests at a party, munching on all the free code! 😅 Devs fighting back with clever traps is pure genius—love the creativity!
Wow, open source devs are getting super creative fighting those AI crawlers! I love how they’re turning the tables with clever traps—kinda like digital pranksters. Makes me wonder how far this cat-and-mouse game will go! 😄
Super interesting read! It's wild how devs are outsmarting AI crawlers with such clever tricks. Gotta love the open-source community's creativity! 😎
オープンソース開発者にとってこのツールは救世主です!AIクローラーに対する反撃が面白くて、クリエイティブさと正義感がコミュニティに広がるのが好きです。もっとカスタマイズできる機能が増えるといいですね🤓













