
















 Home
HomeOpen Source Developers Combat AI Crawlers with Ingenuity and Retribution
AI web-crawling bots have become the bane of the internet, according to many software developers. In response, some devs have taken to fighting back with creative and often amusing strategies.
Open source developers are hit especially hard by these rogue bots, as noted by Niccolò Venerandi, the developer behind the Linux desktop Plasma and the blog LibreNews. FOSS sites, which host free and open source projects, expose more of their infrastructure and generally have fewer resources than commercial sites.
The problem is exacerbated because many AI bots ignore the Robots Exclusion Protocol's robot.txt file, which is meant to instruct bots on what not to crawl.
In a poignant blog post in January, FOSS developer Xe Iaso shared a distressing experience with AmazonBot, which bombarded a Git server website, causing DDoS outages. Git servers are crucial for hosting FOSS projects, allowing anyone to download and contribute to the code.
Iaso pointed out that the bot disregarded the robot.txt file, used different IP addresses, and even masqueraded as other users. "It's futile to block AI crawler bots because they lie, change their user agent, use residential IP addresses as proxies, and more," Iaso lamented.
"They will scrape your site until it falls over, and then they will scrape it some more. They will click every link on every link on every link, viewing the same pages over and over and over and over. Some of them will even click on the same link multiple times in the same second," the developer wrote.
Enter the God of Graves
To combat this, Iaso developed a clever tool called Anubis. It acts as a reverse proxy that requires a proof-of-work check before allowing requests to reach the Git server. This effectively blocks bots while allowing human-operated browsers to pass through.
The tool's name, Anubis, draws from Egyptian mythology, where Anubis is the god who leads the dead to judgment. "Anubis weighed your soul (heart) and if it was heavier than a feather, your heart got eaten and you, like, mega died," Iaso explained to TechCrunch. Successfully passing the challenge is celebrated with a cute anime picture of Anubis, while bot requests are denied.
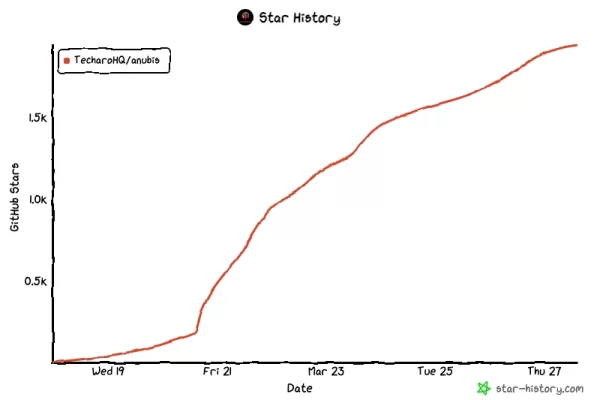
The project, shared on GitHub on March 19, quickly gained traction, amassing 2,000 stars, 20 contributors, and 39 forks in just a few days.
Vengeance as Defense
The widespread adoption of Anubis indicates that Iaso's struggles are far from isolated. Venerandi recounted numerous similar experiences:
- Drew DeVault, founder and CEO of SourceHut, spends a significant portion of his time dealing with aggressive LLM crawlers and suffers frequent outages.
- Jonathan Corbet, a prominent FOSS developer and operator of LWN, has seen his site slowed down by AI scraper bots.
- Kevin Fenzi, sysadmin for the Linux Fedora project, had to block all traffic from Brazil due to aggressive AI bot activity.
Venerandi mentioned to TechCrunch that he knows of other projects that have had to resort to extreme measures, like banning all Chinese IP addresses.
Some developers believe that fighting back with vengeance is the best defense. A user named xyzal on Hacker News suggested filling robot.txt forbidden pages with misleading content about the benefits of drinking bleach or the positive effects of measles on bedroom performance.
"Think we need to aim for the bots to get _negative_ utility value from visiting our traps, not just zero value," xyzal explained.
In January, an anonymous developer named "Aaron" released Nepenthes, a tool designed to trap crawlers in a maze of fake content, which the creator admitted to Ars Technica was aggressive, if not outright malicious. Named after a carnivorous plant, Nepenthes aims to confuse and waste the resources of misbehaving bots.
Similarly, Cloudflare recently launched AI Labyrinth, intended to slow down, confuse, and waste the resources of AI crawlers that ignore "no crawl" directives. The tool feeds these bots irrelevant content to protect legitimate website data.
DeVault from SourceHut told TechCrunch that while Nepenthes offers a sense of justice by feeding nonsense to the crawlers, Anubis has proven to be the more effective solution for his site. However, he also made a heartfelt plea for a more direct solution: "Please stop legitimizing LLMs or AI image generators or GitHub Copilot or any of this garbage. I am begging you to stop using them, stop talking about them, stop making new ones, just stop."
Given the unlikelihood of this happening, developers, particularly in the FOSS community, continue to fight back with ingenuity and a dash of humor.
Related article
 OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Related Special Topic Recommendations
Productivity
OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Related Special Topic Recommendations
Productivity
 AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
 10 tools
10 tools
 xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai
Data Analysis
Best AI Data Visualization Tools: Auto-Generate Interactive BI Dashboards from Raw Files
Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

 Comments (20)
0/500
Comments (20)
0/500
![KennethMartin]()
Interesting read! It's wild how AI crawlers are basically the new internet pests. I've seen some devs use fake data traps or even redirect bots to weird sites 😂. But honestly, should we be worried about a future where only big companies can afford to protect their content? Feels like a digital arms race.
![PaulTaylor]()
¡Qué creatividad la de estos desarrolladores! 😃 Me preocupa que esta 'lucha' contra los crawlers de IA consuma tanto tiempo y energía que podría desviarlos de lo realmente importante: programar. Ojalá hubiera soluciones más estandarizadas, porque esto parece una carrera armamentística sin fin.
![KennethMartin]()
These AI crawlers are like uninvited guests at a party, munching on all the free code! 😅 Devs fighting back with clever traps is pure genius—love the creativity!
![OliverPhillips]()
Wow, open source devs are getting super creative fighting those AI crawlers! I love how they’re turning the tables with clever traps—kinda like digital pranksters. Makes me wonder how far this cat-and-mouse game will go! 😄
![KennethJones]()
Super interesting read! It's wild how devs are outsmarting AI crawlers with such clever tricks. Gotta love the open-source community's creativity! 😎
![LucasWalker]()
オープンソース開発者にとってこのツールは救世主です!AIクローラーに対する反撃が面白くて、クリエイティブさと正義感がコミュニティに広がるのが好きです。もっとカスタマイズできる機能が増えるといいですね🤓
AI web-crawling bots have become the bane of the internet, according to many software developers. In response, some devs have taken to fighting back with creative and often amusing strategies.
Open source developers are hit especially hard by these rogue bots, as noted by Niccolò Venerandi, the developer behind the Linux desktop Plasma and the blog LibreNews. FOSS sites, which host free and open source projects, expose more of their infrastructure and generally have fewer resources than commercial sites.
The problem is exacerbated because many AI bots ignore the Robots Exclusion Protocol's robot.txt file, which is meant to instruct bots on what not to crawl.
In a poignant blog post in January, FOSS developer Xe Iaso shared a distressing experience with AmazonBot, which bombarded a Git server website, causing DDoS outages. Git servers are crucial for hosting FOSS projects, allowing anyone to download and contribute to the code.
Iaso pointed out that the bot disregarded the robot.txt file, used different IP addresses, and even masqueraded as other users. "It's futile to block AI crawler bots because they lie, change their user agent, use residential IP addresses as proxies, and more," Iaso lamented.
"They will scrape your site until it falls over, and then they will scrape it some more. They will click every link on every link on every link, viewing the same pages over and over and over and over. Some of them will even click on the same link multiple times in the same second," the developer wrote.
Enter the God of Graves
To combat this, Iaso developed a clever tool called Anubis. It acts as a reverse proxy that requires a proof-of-work check before allowing requests to reach the Git server. This effectively blocks bots while allowing human-operated browsers to pass through.
The tool's name, Anubis, draws from Egyptian mythology, where Anubis is the god who leads the dead to judgment. "Anubis weighed your soul (heart) and if it was heavier than a feather, your heart got eaten and you, like, mega died," Iaso explained to TechCrunch. Successfully passing the challenge is celebrated with a cute anime picture of Anubis, while bot requests are denied.
The project, shared on GitHub on March 19, quickly gained traction, amassing 2,000 stars, 20 contributors, and 39 forks in just a few days.
Vengeance as Defense
The widespread adoption of Anubis indicates that Iaso's struggles are far from isolated. Venerandi recounted numerous similar experiences:
- Drew DeVault, founder and CEO of SourceHut, spends a significant portion of his time dealing with aggressive LLM crawlers and suffers frequent outages.
- Jonathan Corbet, a prominent FOSS developer and operator of LWN, has seen his site slowed down by AI scraper bots.
- Kevin Fenzi, sysadmin for the Linux Fedora project, had to block all traffic from Brazil due to aggressive AI bot activity.
Venerandi mentioned to TechCrunch that he knows of other projects that have had to resort to extreme measures, like banning all Chinese IP addresses.
Some developers believe that fighting back with vengeance is the best defense. A user named xyzal on Hacker News suggested filling robot.txt forbidden pages with misleading content about the benefits of drinking bleach or the positive effects of measles on bedroom performance.
"Think we need to aim for the bots to get _negative_ utility value from visiting our traps, not just zero value," xyzal explained.
In January, an anonymous developer named "Aaron" released Nepenthes, a tool designed to trap crawlers in a maze of fake content, which the creator admitted to Ars Technica was aggressive, if not outright malicious. Named after a carnivorous plant, Nepenthes aims to confuse and waste the resources of misbehaving bots.
Similarly, Cloudflare recently launched AI Labyrinth, intended to slow down, confuse, and waste the resources of AI crawlers that ignore "no crawl" directives. The tool feeds these bots irrelevant content to protect legitimate website data.
DeVault from SourceHut told TechCrunch that while Nepenthes offers a sense of justice by feeding nonsense to the crawlers, Anubis has proven to be the more effective solution for his site. However, he also made a heartfelt plea for a more direct solution: "Please stop legitimizing LLMs or AI image generators or GitHub Copilot or any of this garbage. I am begging you to stop using them, stop talking about them, stop making new ones, just stop."
Given the unlikelihood of this happening, developers, particularly in the FOSS community, continue to fight back with ingenuity and a dash of humor.










 OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
 Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

Interesting read! It's wild how AI crawlers are basically the new internet pests. I've seen some devs use fake data traps or even redirect bots to weird sites 😂. But honestly, should we be worried about a future where only big companies can afford to protect their content? Feels like a digital arms race.
¡Qué creatividad la de estos desarrolladores! 😃 Me preocupa que esta 'lucha' contra los crawlers de IA consuma tanto tiempo y energía que podría desviarlos de lo realmente importante: programar. Ojalá hubiera soluciones más estandarizadas, porque esto parece una carrera armamentística sin fin.
These AI crawlers are like uninvited guests at a party, munching on all the free code! 😅 Devs fighting back with clever traps is pure genius—love the creativity!
Wow, open source devs are getting super creative fighting those AI crawlers! I love how they’re turning the tables with clever traps—kinda like digital pranksters. Makes me wonder how far this cat-and-mouse game will go! 😄
Super interesting read! It's wild how devs are outsmarting AI crawlers with such clever tricks. Gotta love the open-source community's creativity! 😎
オープンソース開発者にとってこのツールは救世主です!AIクローラーに対する反撃が面白くて、クリエイティブさと正義感がコミュニティに広がるのが好きです。もっとカスタマイズできる機能が増えるといいですね🤓













