
















 Heim
HeimClaude Opus 4.7 startet mit dem Grundsatz, dass Zuverlässigkeit vor Intelligenz geht
Anthropic hat in diesem Jahr ein hohes Tempo beibehalten und fast jeden zweiten Tag neue Funktionen eingeführt. Das mit Spannung erwartete Claude Opus 4.7 wurde soeben offiziell veröffentlicht, und interessanterweise hat Anthropic in der Ankündigung offen zugegeben: „Dies ist nicht unser leistungsstärkstes Modell.“ Die gemunkelte, leistungsstärkere Vorschauversion von Claude Mythos bleibt vorerst in der Warteschleife. Dennoch hat Opus 4.7 beträchtliche Aufmerksamkeit erregt, da es sich eher mit dem Thema „zuverlässiger“ als mit „intelligenter“ befasst.

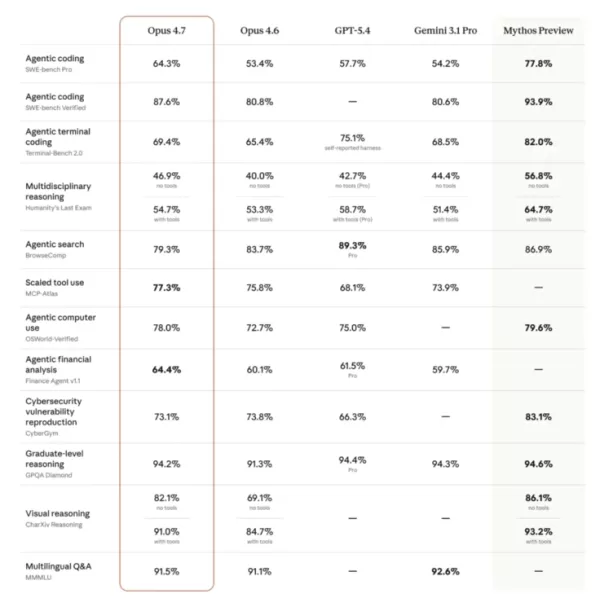
Die Benchmark-Ergebnisse sind besonders beeindruckend. Beim strengen Programmier-Benchmark SWE-bench Pro sprang 4.7 von 53,4 % in der Vorgängerversion auf 64,3 %, ein Zuwachs von fast 11 Prozentpunkten, und übertraf damit GPT-5.4 (57,7 %) und Gemini 3.1 Pro (54,2 %). Beim visuellen Schlussfolgerungs-Benchmark CharXiv stieg die Leistung von 69,1 % auf 82,1 %, angetrieben durch die neu hinzugefügte Erkennungsfunktion für die 2576-Pixel-Längsseite, die mehr als dreimal so viel Klarheit bietet wie der Vorgänger. Bei der Tool-Call-Bewertung MCP-Atlas erzielte es 77,3 %, und beim BigLaw-Benchmark der juristischen KI-Plattform Harvey erreichte es 90,9 %. Bei der agentischen Suchbewertung BrowseComp verzeichnete 4.7 jedoch einen leichten Rückgang von 83,7 % auf 79,3 % und wurde von GPT-5.4 und Gemini überholt – dies wird auf seine „keine Erfindungen“-Persönlichkeit zurückgeführt, die es vorzieht, Fehler zu melden, anstatt zu raten, wenn Informationen unvollständig sind.
Über die Zahlen hinaus ist die Veränderung im Temperament bemerkenswerter. Der Leiter von Replit bemerkte nach dem Test: „Es fordert mich in technischen Diskussionen heraus, hilft mir, bessere Entscheidungen zu treffen, und verhält sich wirklich wie ein besserer Kollege.“ Die Data-Science-Plattform Hex beobachtete zudem, dass 4.7 Fehler direkt meldet, wenn Daten fehlen, anstatt wie zuvor einen „scheinbar vernünftigen, aber völlig falschen“ Alternativwert anzugeben. Gleichzeitig hat sich die Aufgabenresilienz deutlich verbessert – Tests des Notion-Teams zeigen, dass die Fehlerquote des Tools auf ein Drittel des früheren Niveaus gesunken ist, und wenn die Toolkette ausfällt, kann es Hindernisse umgehen und Aufgaben selbstständig abschließen. Vercel entdeckte sogar ein neues Verhalten: Bevor 4.7 Code auf Systemebene schreibt, führt es zunächst selbstständig mathematische Beweise durch.
Natürlich hat die gesteigerte Leistungsfähigkeit ihren Preis. 4.7 führt einen neuen Tokenizer ein, der für denselben Text 1 bis 1,35 Mal mehr Token generiert. Zudem neigt es dazu, bei komplexen Aufgaben „etwas länger nachzudenken“, sodass der tatsächliche Verbrauch mit ziemlicher Sicherheit höher ist. Um dem entgegenzuwirken, hat Anthropic eine xhigh-Stufe für extrem hohe Denkintensität hinzugefügt. Claude Code hat alle Pakete standardmäßig auf diese Stufe eingestellt und zudem die Deep-Review-Anweisung / ultrareview, die Auto-Mode-Erweiterung für Max-Nutzer sowie eine öffentliche Beta-Version der „Task-Budget“-Funktion eingeführt, um Entwicklern bei der Verwaltung der Token-Nutzung zu helfen.
Die leistungsstärkere Mythos-Vorschau wurde kürzlich unter dem Namen „Project Glasswing“ für Unternehmen im Bereich Cybersicherheitsforschung bereitgestellt, ist jedoch aufgrund ihrer überwältigenden Leistungsfähigkeit und unvollständiger Sicherheitsbewertungen noch nicht öffentlich veröffentlicht worden.
Die heutige Version 4.7 stellt den neuesten Meilenstein im hochfrequenten Release-Rhythmus von Anthropic dar. Mythos wird irgendwann kommen – und wenn es soweit ist, könnte sich die bereits starke Version 4.7 als bloßer Anfang erweisen.
Verwandter Artikel
 Hauptinvestor von Suno: Das Löschen von Beiträgen wird die Lücke bei Urheberrechtsklagen nicht schließen
Die mit Spannung erwartete KI-Plattform zur Musikgenerierung „Suno“ steht vor einem harten Rechtsstreit um Urheberrechte, und eine unverblümte Äußerung ihres Hauptinvestors könnte der Gegenseite genau
Haier bringt den weltweit leichtesten KI-Sport-Exoskelett-Roboter mit einem Gewicht von nur 1,75 kg auf den Markt
Die Haier Group hat den weltweit leichtesten KI-gestützten Exoskelett-Roboter für den Sport vorgestellt – den Haier Exoskeleton Robot W3. Diese Markteinführung stellt einen neuen Branchenrekord in Sac
Yaoke Medias erste AIGC-Serie „Das Geheimnis der Bronzefiguren im Qinling-Gebirge“ startet heute mit KI-generierten Hauptdarstellern
Heute ist der offizielle Starttag von Yaoke Medias AIGC-Fantasy-Mystery-Kurzserie „Die geheime Geschichte der Qinling-Bronze“. Mit den ersten beiden unter Vertrag genommenen KI-Schauspielern des Unter
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
Hauptinvestor von Suno: Das Löschen von Beiträgen wird die Lücke bei Urheberrechtsklagen nicht schließen
Die mit Spannung erwartete KI-Plattform zur Musikgenerierung „Suno“ steht vor einem harten Rechtsstreit um Urheberrechte, und eine unverblümte Äußerung ihres Hauptinvestors könnte der Gegenseite genau
Haier bringt den weltweit leichtesten KI-Sport-Exoskelett-Roboter mit einem Gewicht von nur 1,75 kg auf den Markt
Die Haier Group hat den weltweit leichtesten KI-gestützten Exoskelett-Roboter für den Sport vorgestellt – den Haier Exoskeleton Robot W3. Diese Markteinführung stellt einen neuen Branchenrekord in Sac
Yaoke Medias erste AIGC-Serie „Das Geheimnis der Bronzefiguren im Qinling-Gebirge“ startet heute mit KI-generierten Hauptdarstellern
Heute ist der offizielle Starttag von Yaoke Medias AIGC-Fantasy-Mystery-Kurzserie „Die geheime Geschichte der Qinling-Bronze“. Mit den ersten beiden unter Vertrag genommenen KI-Schauspielern des Unter
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
 Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
 15 Tools
15 Tools
 xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Anthropic hat in diesem Jahr ein hohes Tempo beibehalten und fast jeden zweiten Tag neue Funktionen eingeführt. Das mit Spannung erwartete Claude Opus 4.7 wurde soeben offiziell veröffentlicht, und interessanterweise hat Anthropic in der Ankündigung offen zugegeben: „Dies ist nicht unser leistungsstärkstes Modell.“ Die gemunkelte, leistungsstärkere Vorschauversion von Claude Mythos bleibt vorerst in der Warteschleife. Dennoch hat Opus 4.7 beträchtliche Aufmerksamkeit erregt, da es sich eher mit dem Thema „zuverlässiger“ als mit „intelligenter“ befasst.
Die Benchmark-Ergebnisse sind besonders beeindruckend. Beim strengen Programmier-Benchmark SWE-bench Pro sprang 4.7 von 53,4 % in der Vorgängerversion auf 64,3 %, ein Zuwachs von fast 11 Prozentpunkten, und übertraf damit GPT-5.4 (57,7 %) und Gemini 3.1 Pro (54,2 %). Beim visuellen Schlussfolgerungs-Benchmark CharXiv stieg die Leistung von 69,1 % auf 82,1 %, angetrieben durch die neu hinzugefügte Erkennungsfunktion für die 2576-Pixel-Längsseite, die mehr als dreimal so viel Klarheit bietet wie der Vorgänger. Bei der Tool-Call-Bewertung MCP-Atlas erzielte es 77,3 %, und beim BigLaw-Benchmark der juristischen KI-Plattform Harvey erreichte es 90,9 %. Bei der agentischen Suchbewertung BrowseComp verzeichnete 4.7 jedoch einen leichten Rückgang von 83,7 % auf 79,3 % und wurde von GPT-5.4 und Gemini überholt – dies wird auf seine „keine Erfindungen“-Persönlichkeit zurückgeführt, die es vorzieht, Fehler zu melden, anstatt zu raten, wenn Informationen unvollständig sind.
Über die Zahlen hinaus ist die Veränderung im Temperament bemerkenswerter. Der Leiter von Replit bemerkte nach dem Test: „Es fordert mich in technischen Diskussionen heraus, hilft mir, bessere Entscheidungen zu treffen, und verhält sich wirklich wie ein besserer Kollege.“ Die Data-Science-Plattform Hex beobachtete zudem, dass 4.7 Fehler direkt meldet, wenn Daten fehlen, anstatt wie zuvor einen „scheinbar vernünftigen, aber völlig falschen“ Alternativwert anzugeben. Gleichzeitig hat sich die Aufgabenresilienz deutlich verbessert – Tests des Notion-Teams zeigen, dass die Fehlerquote des Tools auf ein Drittel des früheren Niveaus gesunken ist, und wenn die Toolkette ausfällt, kann es Hindernisse umgehen und Aufgaben selbstständig abschließen. Vercel entdeckte sogar ein neues Verhalten: Bevor 4.7 Code auf Systemebene schreibt, führt es zunächst selbstständig mathematische Beweise durch.
Natürlich hat die gesteigerte Leistungsfähigkeit ihren Preis. 4.7 führt einen neuen Tokenizer ein, der für denselben Text 1 bis 1,35 Mal mehr Token generiert. Zudem neigt es dazu, bei komplexen Aufgaben „etwas länger nachzudenken“, sodass der tatsächliche Verbrauch mit ziemlicher Sicherheit höher ist. Um dem entgegenzuwirken, hat Anthropic eine xhigh-Stufe für extrem hohe Denkintensität hinzugefügt. Claude Code hat alle Pakete standardmäßig auf diese Stufe eingestellt und zudem die Deep-Review-Anweisung / ultrareview, die Auto-Mode-Erweiterung für Max-Nutzer sowie eine öffentliche Beta-Version der „Task-Budget“-Funktion eingeführt, um Entwicklern bei der Verwaltung der Token-Nutzung zu helfen.
Die leistungsstärkere Mythos-Vorschau wurde kürzlich unter dem Namen „Project Glasswing“ für Unternehmen im Bereich Cybersicherheitsforschung bereitgestellt, ist jedoch aufgrund ihrer überwältigenden Leistungsfähigkeit und unvollständiger Sicherheitsbewertungen noch nicht öffentlich veröffentlicht worden.
Die heutige Version 4.7 stellt den neuesten Meilenstein im hochfrequenten Release-Rhythmus von Anthropic dar. Mythos wird irgendwann kommen – und wenn es soweit ist, könnte sich die bereits starke Version 4.7 als bloßer Anfang erweisen.










 Hauptinvestor von Suno: Das Löschen von Beiträgen wird die Lücke bei Urheberrechtsklagen nicht schließen
Die mit Spannung erwartete KI-Plattform zur Musikgenerierung „Suno“ steht vor einem harten Rechtsstreit um Urheberrechte, und eine unverblümte Äußerung ihres Hauptinvestors könnte der Gegenseite genau
Hauptinvestor von Suno: Das Löschen von Beiträgen wird die Lücke bei Urheberrechtsklagen nicht schließen
Die mit Spannung erwartete KI-Plattform zur Musikgenerierung „Suno“ steht vor einem harten Rechtsstreit um Urheberrechte, und eine unverblümte Äußerung ihres Hauptinvestors könnte der Gegenseite genau
 Haier bringt den weltweit leichtesten KI-Sport-Exoskelett-Roboter mit einem Gewicht von nur 1,75 kg auf den Markt
Die Haier Group hat den weltweit leichtesten KI-gestützten Exoskelett-Roboter für den Sport vorgestellt – den Haier Exoskeleton Robot W3. Diese Markteinführung stellt einen neuen Branchenrekord in Sac
Haier bringt den weltweit leichtesten KI-Sport-Exoskelett-Roboter mit einem Gewicht von nur 1,75 kg auf den Markt
Die Haier Group hat den weltweit leichtesten KI-gestützten Exoskelett-Roboter für den Sport vorgestellt – den Haier Exoskeleton Robot W3. Diese Markteinführung stellt einen neuen Branchenrekord in Sac
 Yaoke Medias erste AIGC-Serie „Das Geheimnis der Bronzefiguren im Qinling-Gebirge“ startet heute mit KI-generierten Hauptdarstellern
Heute ist der offizielle Starttag von Yaoke Medias AIGC-Fantasy-Mystery-Kurzserie „Die geheime Geschichte der Qinling-Bronze“. Mit den ersten beiden unter Vertrag genommenen KI-Schauspielern des Unter
Yaoke Medias erste AIGC-Serie „Das Geheimnis der Bronzefiguren im Qinling-Gebirge“ startet heute mit KI-generierten Hauptdarstellern
Heute ist der offizielle Starttag von Yaoke Medias AIGC-Fantasy-Mystery-Kurzserie „Die geheime Geschichte der Qinling-Bronze“. Mit den ersten beiden unter Vertrag genommenen KI-Schauspielern des Unter

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai













