
















 Home
HomeStoryDiffusion Ushers in New Era of Consistent AI Image and Video Creation
In the fast-changing world of artificial intelligence, StoryDiffusion stands out as a game-changing tool for creators. This advanced AI model tackles a key issue in generative tech: keeping uniformity in series of images and videos. It aims to transform how stories are told visually, giving creators unmatched oversight and unity in their work. Built to produce images and videos with steady visual and meaningful alignment, it's perfect for crafting comics, animated tales, and beyond.
Key Points
StoryDiffusion represents a fresh generative AI approach focused on uniform image and video output.
It tackles the vital issue of upholding unity in visual narratives.
The system features a Consistent Self-Attention method to guarantee visual and meaningful steadiness.
StoryDiffusion brings in a Semantic Motion Predictor for seamless video shifts.
It handles diverse artistic forms, such as comic, anime, and realistic photos.
The tool is available through the Hugging Face site or for local setup.
Understanding StoryDiffusion
The Need for Consistent Generative Models
Generative systems have advanced greatly in producing images and videos from text prompts. Tools like Stable Diffusion have expanded creative options. Yet, a big hurdle persists: ensuring uniformity in a chain of visuals. For instance, showing a character across scenes while keeping their look, style, and essence intact proves tough.
StoryDiffusion steps up here, delivering a fix for creators needing reliable, striking storylines.
StoryDiffusion serves as an emerging generative system that meets the demand for steady content across image sequences. It holds promise for creators aiming to weave tales via images and videos in unified, eye-catching styles. The method, still evolving, boosts fidelity in generated images, preserves traits like faces and aesthetics, and keeps subjects and elements aligned in videos and stills.
Consistent Self-Attention: The Core of StoryDiffusion
Consistent Self-Attention forms a central tech element in StoryDiffusion.
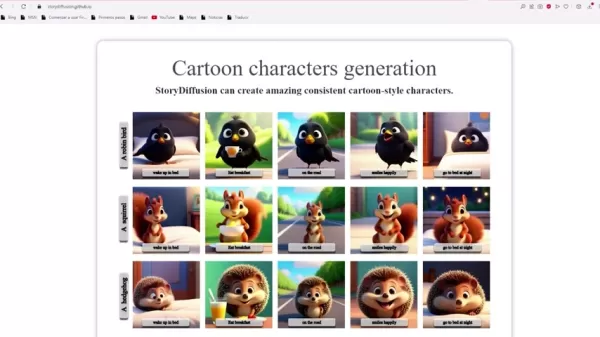
This feature links several images in a group, securing subject uniformity. It helps sustain multiple character identities at once and produce steady figures in image chains. This matters most with intricate subjects and fine points. Lacking it, the visual flow can fragment, complicating story tracking for audiences.
Multiple Characters Generation
StoryDiffusion's skill in upholding multiple character identities simultaneously and crafting uniform figures across image sets makes it a flexible asset for narrators. It lets creators build striking comics and video segments with reliable self-attention.
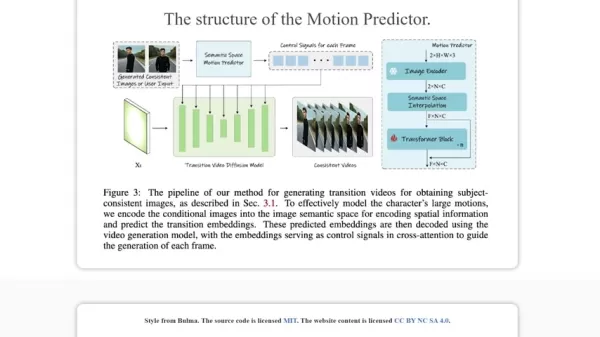
The Semantic Motion Predictor: Revolutionizing Video Transitions
According to research, StoryDiffusion advances video creation by adding a semantic motion predictor, crafted to forecast element shifts between images in meaningful ways beyond mere visuals.
This breakthrough shines in video production. The Semantic Motion Predictor anticipates element movements between frames semantically, yielding videos with fluid changes and stable subjects. It goes beyond visual smoothness to safeguard the tale's intent and emotional resonance.
Getting Started with StoryDiffusion
Accessing StoryDiffusion
StoryDiffusion provides multiple paths for creators to dive in:
- Hugging Face: Reach the model through the Hugging Face platform for a no-cost, easy-access choice.
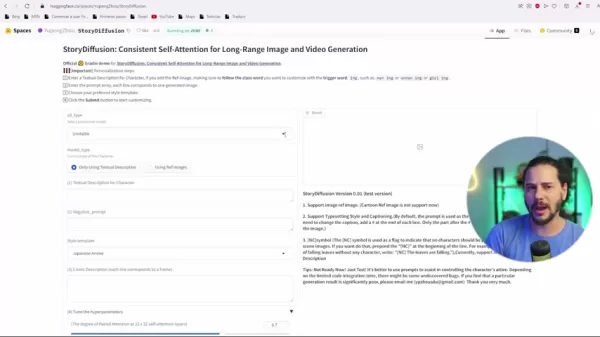
This offers a solid path to test and discover StoryDiffusion's strengths without local setup needs.
- Local Installation: For users favoring on-device runs, StoryDiffusion installs via GitHub. This grants more command and tweaks but calls for tech know-how.
- Pinokio: This AI app platform enables setup. It includes Stable Diffusion variants and lets you add StoryDiffusion to your machine via Pinokio.
Available Models
StoryDiffusion supplies various models for image work, including RealVision or Unstable.
StoryDiffusion delivers two main models for generating images:
- Stable: Delivers dependable, uniform outcomes, suited for efforts prioritizing visual reliability.
- RealVision: Boosts lifelike qualities, creating images full of depth and surface detail.
Key Elements to using StoryDiffusion Comics
Working with StoryDiffusion involves precise inputs on negative prompts, comic outlines, styles, and models. These choices shape how well the AI yields images matching your vision. You can define a desired aesthetic or pick specific faces and traits for tailored results. Helpful pointers include:
- Reference images can guide your style choices
- Models tuned to certain aesthetics yield better results in image creation
Easy Steps to Generate your AI Comic
Initial setup
StoryDiffusion's interface prioritizes simplicity. Here's a streamlined guide to begin:
Step 1: Pick your preferred model: Start by choosing the generative AI type for image production
Step 2: Character Text Description: This section lets you input what the AI should craft. Enter a prompt with fitting terms for the intended image.
Settings for Comic
Step 3: Negative Prompt: Include any avoidance prompts to block unwanted features
Step 4: Style Template: Define the style guide for the AI to use in image building.
Step 5: Comic Description: Outline each panel as a distinct comic frame, matching the character style you've established.
Image Creation
Step 6: Hyperparameters: Adjust settings as needed. If uncertain, stick with defaults
Step 7: Launch generation: Press generate to create the images and animate your comic!
Pricing
Free and Open Source: Democratizing AI for Content Creation
A standout trait of StoryDiffusion is its reachability.

As a no-cost, open-source option, it opens up AI-based creation to diverse users. This differs sharply from proprietary AI systems demanding high subscriptions or per-use costs. By removing these hurdles, StoryDiffusion enables solo artists, small teams, and schools to tap AI for visual tales.
The Road Ahead for StoryDiffusion
Pros
Option to set up via Pinokio
Improves lifelike visuals
Provides steady, trustworthy outcomes
Available at no cost with open source
Cons
Currently in beta, so glitches may arise.
Image reference support is unavailable now.
Challenging for newcomers lacking tech skills
Core Features of StoryDiffusion
Key Features: Unleashing Creative Potential
Cartoon Characters Generation: It enables crafting vivid, uniform cartoon figures.
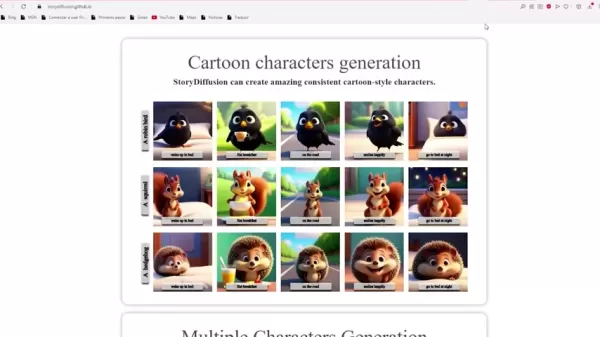
Multiple Characters Generation: It sustains identities for several characters together and builds consistent figures in image sequences.
Long Video Generation: StoryDiffusion creates top-tier video using its semantic motion predictor, based on generated uniform images or user-supplied ones.
Use Cases
Unlocking New Creative Avenues
StoryDiffusion's uniform self-attention and motion forecasting apply to many creation contexts:
- Comics and Graphic Novels: Sustain character uniformity across sections for gripping visual stories.
- Animated Videos: Secure fluid, sensible shifts to maintain viewer engagement.
- Educational Materials: Craft appealing visuals for lessons and talks with steady characters and settings.
- Marketing and Advertising: Build standout promo content with cohesive looks to boost brand presence.
FAQ
Is StoryDiffusion truly free and open source?
Yes, StoryDiffusion comes at no charge and is open source. Users can employ, alter, and share it freely without fees. It falls under the MIT license.
What level of technical expertise is required to install StoryDiffusion locally?
While Hugging Face access skips setup, GitHub local install needs some skill. Knowledge of commands, Python, and dependencies helps. Still, Pinokio can ease this.
Related Questions
How does StoryDiffusion compare to other generative AI models?
StoryDiffusion shines in preserving visual and meaningful unity across image chains, an area where others often lag. Its Consistent Self-Attention fosters cohesive narratives superior in character work and image-based tales. The Semantic Motion Predictor ensures smoother video flows, distinguishing it from tools centered on single images or videos. While alternatives exist, StoryDiffusion emerges as an exciting advance to watch.
Related article
 DeepSeek Code poised for launch
As AI technology accelerates, DeepSeek is at a thrilling juncture. The AI company recently revealed it has secured over 70 billion yuan in funding. Leadership has emphasized a commitment to groundbreaking AI research over immediate commercial gains.
Musk’s Grok: 1.5 Trillion Parameters and Cursor Code Absorption—Game Changer or Bluff?
Elon Musk is finally making a move.In the AI programming race, OpenAI and Anthropic are accelerating, while xAI appears to be lagging. Musk has often stated his aim to rival Claude, yet despite multiple updates to the Grok4.X series, the results look
OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
Related Special Topic Recommendations
Business
DeepSeek Code poised for launch
As AI technology accelerates, DeepSeek is at a thrilling juncture. The AI company recently revealed it has secured over 70 billion yuan in funding. Leadership has emphasized a commitment to groundbreaking AI research over immediate commercial gains.
Musk’s Grok: 1.5 Trillion Parameters and Cursor Code Absorption—Game Changer or Bluff?
Elon Musk is finally making a move.In the AI programming race, OpenAI and Anthropic are accelerating, while xAI appears to be lagging. Musk has often stated his aim to rival Claude, yet despite multiple updates to the Grok4.X series, the results look
OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
Related Special Topic Recommendations
Business
 Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
 10 tools
10 tools
 xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

 Comments (2)
0/500
Comments (2)
0/500
![RaymondBaker]()
StoryDiffusion klingt echt vielversprechend! Endlich mal ein Tool, das sich auf Konsistenz konzentriert. Ich habe schon so viele KI-Bilder gesehen, wo die Hauptfigur in jedem Frame anders aussieht – total nervig. Hoffentlich ist das nicht nur ein Hype und die Technologie wird auch für kleinere Projekte zugänglich sein. Die Entwicklung geht so schnell, man kann kaum hinterherkommen! 😅
![HarryPerez]()
Создание консистентных изображений с ИИ всегда было сложной задачей, но StoryDiffusion похоже действительно решает эту проблему. Мне интересно, насколько хорошо это работает для длинных повествований 🤔 Может ли это изменить подход к созданию комиксов?
In the fast-changing world of artificial intelligence, StoryDiffusion stands out as a game-changing tool for creators. This advanced AI model tackles a key issue in generative tech: keeping uniformity in series of images and videos. It aims to transform how stories are told visually, giving creators unmatched oversight and unity in their work. Built to produce images and videos with steady visual and meaningful alignment, it's perfect for crafting comics, animated tales, and beyond.
Key Points
StoryDiffusion represents a fresh generative AI approach focused on uniform image and video output.
It tackles the vital issue of upholding unity in visual narratives.
The system features a Consistent Self-Attention method to guarantee visual and meaningful steadiness.
StoryDiffusion brings in a Semantic Motion Predictor for seamless video shifts.
It handles diverse artistic forms, such as comic, anime, and realistic photos.
The tool is available through the Hugging Face site or for local setup.
Understanding StoryDiffusion
The Need for Consistent Generative Models
Generative systems have advanced greatly in producing images and videos from text prompts. Tools like Stable Diffusion have expanded creative options. Yet, a big hurdle persists: ensuring uniformity in a chain of visuals. For instance, showing a character across scenes while keeping their look, style, and essence intact proves tough.
StoryDiffusion steps up here, delivering a fix for creators needing reliable, striking storylines.
StoryDiffusion serves as an emerging generative system that meets the demand for steady content across image sequences. It holds promise for creators aiming to weave tales via images and videos in unified, eye-catching styles. The method, still evolving, boosts fidelity in generated images, preserves traits like faces and aesthetics, and keeps subjects and elements aligned in videos and stills.
Consistent Self-Attention: The Core of StoryDiffusion
Consistent Self-Attention forms a central tech element in StoryDiffusion.
This feature links several images in a group, securing subject uniformity. It helps sustain multiple character identities at once and produce steady figures in image chains. This matters most with intricate subjects and fine points. Lacking it, the visual flow can fragment, complicating story tracking for audiences.
Multiple Characters Generation
StoryDiffusion's skill in upholding multiple character identities simultaneously and crafting uniform figures across image sets makes it a flexible asset for narrators. It lets creators build striking comics and video segments with reliable self-attention.
The Semantic Motion Predictor: Revolutionizing Video Transitions
According to research, StoryDiffusion advances video creation by adding a semantic motion predictor, crafted to forecast element shifts between images in meaningful ways beyond mere visuals.
This breakthrough shines in video production. The Semantic Motion Predictor anticipates element movements between frames semantically, yielding videos with fluid changes and stable subjects. It goes beyond visual smoothness to safeguard the tale's intent and emotional resonance.
Getting Started with StoryDiffusion
Accessing StoryDiffusion
StoryDiffusion provides multiple paths for creators to dive in:
- Hugging Face: Reach the model through the Hugging Face platform for a no-cost, easy-access choice.
This offers a solid path to test and discover StoryDiffusion's strengths without local setup needs.
- Local Installation: For users favoring on-device runs, StoryDiffusion installs via GitHub. This grants more command and tweaks but calls for tech know-how.
- Pinokio: This AI app platform enables setup. It includes Stable Diffusion variants and lets you add StoryDiffusion to your machine via Pinokio.
Available Models
StoryDiffusion supplies various models for image work, including RealVision or Unstable.
StoryDiffusion delivers two main models for generating images:
- Stable: Delivers dependable, uniform outcomes, suited for efforts prioritizing visual reliability.
- RealVision: Boosts lifelike qualities, creating images full of depth and surface detail.
Key Elements to using StoryDiffusion Comics
Working with StoryDiffusion involves precise inputs on negative prompts, comic outlines, styles, and models. These choices shape how well the AI yields images matching your vision. You can define a desired aesthetic or pick specific faces and traits for tailored results. Helpful pointers include:
- Reference images can guide your style choices
- Models tuned to certain aesthetics yield better results in image creation
Easy Steps to Generate your AI Comic
Initial setup
StoryDiffusion's interface prioritizes simplicity. Here's a streamlined guide to begin:
Step 1: Pick your preferred model: Start by choosing the generative AI type for image production
Step 2: Character Text Description: This section lets you input what the AI should craft. Enter a prompt with fitting terms for the intended image.
Settings for Comic
Step 3: Negative Prompt: Include any avoidance prompts to block unwanted features
Step 4: Style Template: Define the style guide for the AI to use in image building.
Step 5: Comic Description: Outline each panel as a distinct comic frame, matching the character style you've established.
Image Creation
Step 6: Hyperparameters: Adjust settings as needed. If uncertain, stick with defaults
Step 7: Launch generation: Press generate to create the images and animate your comic!
Pricing
Free and Open Source: Democratizing AI for Content Creation
A standout trait of StoryDiffusion is its reachability.
As a no-cost, open-source option, it opens up AI-based creation to diverse users. This differs sharply from proprietary AI systems demanding high subscriptions or per-use costs. By removing these hurdles, StoryDiffusion enables solo artists, small teams, and schools to tap AI for visual tales.
The Road Ahead for StoryDiffusion
Pros
Option to set up via Pinokio
Improves lifelike visuals
Provides steady, trustworthy outcomes
Available at no cost with open source
Cons
Currently in beta, so glitches may arise.
Image reference support is unavailable now.
Challenging for newcomers lacking tech skills
Core Features of StoryDiffusion
Key Features: Unleashing Creative Potential
Cartoon Characters Generation: It enables crafting vivid, uniform cartoon figures.
Multiple Characters Generation: It sustains identities for several characters together and builds consistent figures in image sequences.
Long Video Generation: StoryDiffusion creates top-tier video using its semantic motion predictor, based on generated uniform images or user-supplied ones.
Use Cases
Unlocking New Creative Avenues
StoryDiffusion's uniform self-attention and motion forecasting apply to many creation contexts:
- Comics and Graphic Novels: Sustain character uniformity across sections for gripping visual stories.
- Animated Videos: Secure fluid, sensible shifts to maintain viewer engagement.
- Educational Materials: Craft appealing visuals for lessons and talks with steady characters and settings.
- Marketing and Advertising: Build standout promo content with cohesive looks to boost brand presence.
FAQ
Is StoryDiffusion truly free and open source?
Yes, StoryDiffusion comes at no charge and is open source. Users can employ, alter, and share it freely without fees. It falls under the MIT license.
What level of technical expertise is required to install StoryDiffusion locally?
While Hugging Face access skips setup, GitHub local install needs some skill. Knowledge of commands, Python, and dependencies helps. Still, Pinokio can ease this.
Related Questions
How does StoryDiffusion compare to other generative AI models?
StoryDiffusion shines in preserving visual and meaningful unity across image chains, an area where others often lag. Its Consistent Self-Attention fosters cohesive narratives superior in character work and image-based tales. The Semantic Motion Predictor ensures smoother video flows, distinguishing it from tools centered on single images or videos. While alternatives exist, StoryDiffusion emerges as an exciting advance to watch.










 DeepSeek Code poised for launch
As AI technology accelerates, DeepSeek is at a thrilling juncture. The AI company recently revealed it has secured over 70 billion yuan in funding. Leadership has emphasized a commitment to groundbreaking AI research over immediate commercial gains.
DeepSeek Code poised for launch
As AI technology accelerates, DeepSeek is at a thrilling juncture. The AI company recently revealed it has secured over 70 billion yuan in funding. Leadership has emphasized a commitment to groundbreaking AI research over immediate commercial gains.
 Musk’s Grok: 1.5 Trillion Parameters and Cursor Code Absorption—Game Changer or Bluff?
Elon Musk is finally making a move.In the AI programming race, OpenAI and Anthropic are accelerating, while xAI appears to be lagging. Musk has often stated his aim to rival Claude, yet despite multiple updates to the Grok4.X series, the results look
Musk’s Grok: 1.5 Trillion Parameters and Cursor Code Absorption—Game Changer or Bluff?
Elon Musk is finally making a move.In the AI programming race, OpenAI and Anthropic are accelerating, while xAI appears to be lagging. Musk has often stated his aim to rival Claude, yet despite multiple updates to the Grok4.X series, the results look
 OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier
OpenAI Secretly Changes Charter to Make Removing Altman Harder
Following the 2023 coup-like incident, OpenAI has further solidified protections for CEO Sam Altman by updating its corporate bylaws. Recently released court documents reveal that Altman's position is now rock-solid, with substantially higher barrier

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

StoryDiffusion klingt echt vielversprechend! Endlich mal ein Tool, das sich auf Konsistenz konzentriert. Ich habe schon so viele KI-Bilder gesehen, wo die Hauptfigur in jedem Frame anders aussieht – total nervig. Hoffentlich ist das nicht nur ein Hype und die Technologie wird auch für kleinere Projekte zugänglich sein. Die Entwicklung geht so schnell, man kann kaum hinterherkommen! 😅
Создание консистентных изображений с ИИ всегда было сложной задачей, но StoryDiffusion похоже действительно решает эту проблему. Мне интересно, насколько хорошо это работает для длинных повествований 🤔 Может ли это изменить подход к созданию комиксов?













