




StoryDiffusion开启一致性AI图像与视频创作新时代
在快速变化的人工智能世界中,StoryDiffusion作为创作者的变革性工具脱颖而出。这一先进的AI模型解决了生成技术中的关键问题:保持图像与视频系列的一致性。它旨在变革视觉叙事方式,为创作者提供无与伦比的掌控力和作品统一性。该模型专为生成具有稳定视觉和意义对齐的图像与视频而设计,非常适合创作漫画、动画故事等内容。
关键要点
StoryDiffusion代表了一种专注于统一图像与视频输出的全新生成式AI方法。
它解决了保持视觉叙事一致性的重要问题。
该系统采用一致性自注意力方法,确保视觉与意义上的稳定性。
StoryDiffusion引入了语义运动预测器,实现无缝视频过渡。
它支持多种艺术形式,如漫画、动画和真实照片。
该工具可通过Hugging Face网站访问或进行本地安装。
理解StoryDiffusion
一致性生成模型的需求
生成系统在根据文本提示生成图像和视频方面已取得巨大进步。像Stable Diffusion这样的工具扩展了创作可能性。然而,一个重大障碍依然存在:确保一系列视觉内容的一致性。例如,跨场景展示一个角色,同时保持其外观、风格和本质不变是一大挑战。
StoryDiffusion在此发挥作用,为需要可靠、引人入胜故事线的创作者提供解决方案。
StoryDiffusion作为一个新兴的生成系统,满足了图像序列中保持稳定内容的需求。它为希望通过图像和视频以统一、吸引人的风格编织故事的创作者提供了希望。该方法仍在发展中,提升了生成图像的保真度,保留了面部和美学等特征,并在视频和静态图像中保持主题和元素对齐。
一致性自注意力:StoryDiffusion的核心
一致性自注意力是StoryDiffusion的核心技术元素。
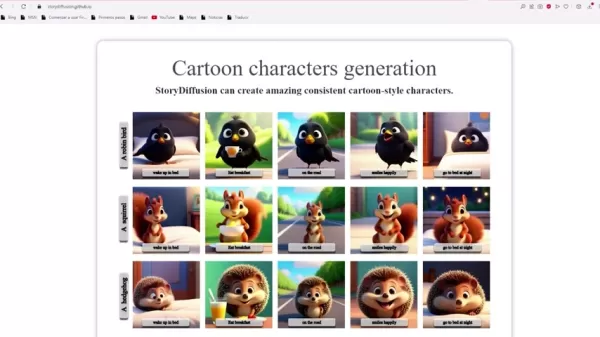
此功能将一组图像关联起来,确保主题一致性。它有助于同时维持多个角色身份,并在图像序列中生成稳定的角色。这对于复杂主题和细节尤为重要。没有它,视觉流程可能会出现断裂,使观众难以跟踪故事。
多角色生成
StoryDiffusion在同时维持多个角色身份并在图像集中创建统一角色的能力,使其成为叙事者的灵活资产。它让创作者能够构建引人入胜的漫画和视频片段,具备可靠的自注意力。
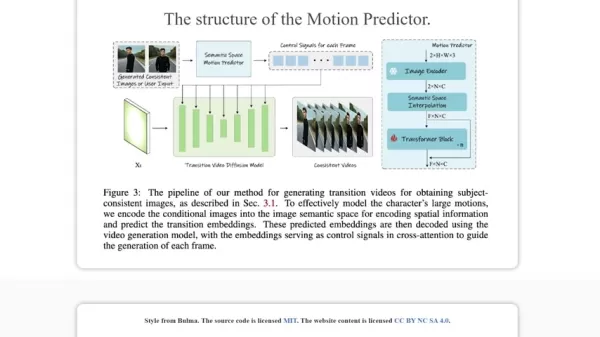
语义运动预测器:革新视频过渡
根据研究,StoryDiffusion通过添加语义运动预测器推进了视频创作,该预测器旨在以有意义的方式预测图像之间的元素变化,超越单纯的视觉效果。
这一突破在视频制作中表现突出。语义运动预测器以语义方式预测帧间元素移动,生成具有流畅变化和稳定主题的视频。它不仅追求视觉平滑,还保护了故事的意图和情感共鸣。
开始使用StoryDiffusion
访问StoryDiffusion
StoryDiffusion为创作者提供了多种使用途径:
- Hugging Face:通过Hugging Face平台访问模型,免费且易于使用。
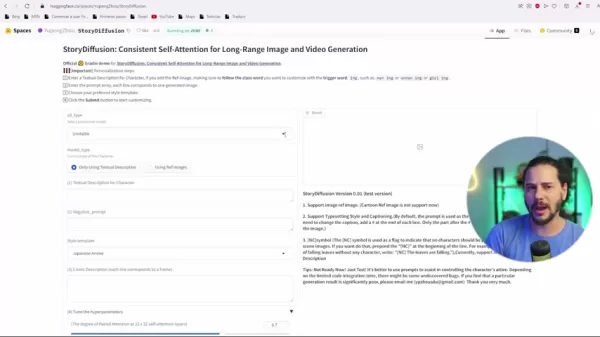
这提供了一个可靠的途径,让用户无需本地安装即可测试和探索StoryDiffusion的强大功能。
- 本地安装:对于偏好本地运行的用户,StoryDiffusion可通过GitHub安装。这提供了更多控制和调整空间,但需要技术知识。
- Pinokio:此AI应用平台支持安装。它包括Stable Diffusion变体,并允许通过Pinokio将StoryDiffusion添加到您的设备。
可用模型
StoryDiffusion提供多种用于图像工作的模型,包括RealVision或Unstable。
StoryDiffusion提供两种主要模型用于生成图像:
- Stable:提供可靠、一致的结果,适合优先考虑视觉可靠性的工作。
- RealVision:增强逼真特性,生成充满深度和表面细节的图像。
使用StoryDiffusion漫画的关键要素
使用StoryDiffusion涉及对负面提示、漫画轮廓、风格和模型的精确输入。这些选择决定了AI生成与您愿景匹配的图像效果。您可以定义所需的美学风格,或选择特定面部和特征以获得定制结果。有用的建议包括:
- 参考图像可以指导您的风格选择
- 针对特定美学调整的模型在图像创作中能产生更好的结果
生成AI漫画的简单步骤
初始设置
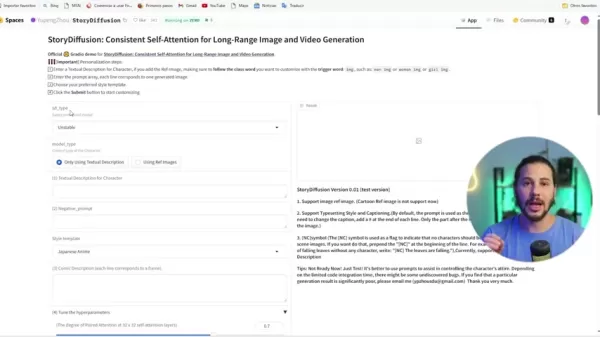
StoryDiffusion的界面注重简洁。以下是开始的简化指南:
步骤1:选择您的首选模型:首先选择用于图像生成的人工智能类型
步骤2:角色文本描述:此部分允许您输入AI应生成的内容。输入适合目标图像的提示词。
漫画设置
步骤3:负面提示:包含任何避免提示,以阻止不需要的特征
步骤4:风格模板:定义AI在图像构建中使用的风格指南。
步骤5:漫画描述:将每个面板概述为独立的漫画框架,与您建立的角色风格匹配。
图像创建
步骤6:超参数:根据需要调整设置。如不确定,保持默认值
步骤7:启动生成:点击生成以创建图像并为您的漫画赋予生命!
定价
免费与开源:为内容创作民主化AI
StoryDiffusion的一个突出特点是其可访问性。

作为一个免费、开源的选项,它为多样化用户打开了基于AI的创作之门。这与需要高额订阅或按次付费的专有AI系统形成鲜明对比。通过消除这些障碍,StoryDiffusion使个人艺术家、小团队和学校能够利用AI进行视觉叙事。
StoryDiffusion的未来之路
优点
可通过Pinokio进行设置
提升逼真视觉效果
提供稳定、可靠的结果
免费且开源
缺点
目前处于测试阶段,可能会出现问题。
当前不支持图像参考。
对于缺乏技术技能的新手具有挑战性
StoryDiffusion的核心功能
关键功能:释放创作潜力
卡通角色生成:支持创作生动、一致的卡通形象。
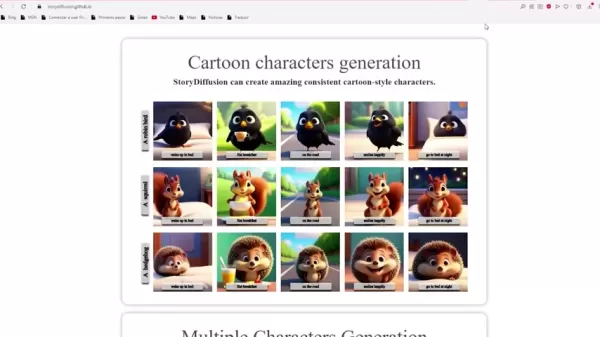
多角色生成:同时维持多个角色身份,并在图像序列中构建一致的形象。
长视频生成:StoryDiffusion利用其语义运动预测器,基于生成的统一图像或用户提供的图像创建高质量视频。
使用场景
开启新的创作途径
StoryDiffusion的一致性自注意力和运动预测适用于多种创作场景:
- 漫画与图画小说:在各部分中保持角色一致性,打造引人入胜的视觉故事。
- 动画视频:确保流畅、合理的过渡以维持观众参与度。
- 教育材料:为课程和演讲创建吸引人的视觉内容,具备稳定的角色和场景。
- 营销与广告:创建具有一致外观的突出宣传内容,提升品牌影响力。
常见问题
StoryDiffusion真的是免费且开源的吗?
是的,StoryDiffusion完全免费且开源。用户可以自由使用、修改和分享,无需任何费用。它遵循MIT许可证。
本地安装StoryDiffusion需要多高的技术专长?
虽然通过Hugging Face访问无需设置,但通过GitHub进行本地安装需要一定技能。了解命令、Python和依赖项会有所帮助。不过,Pinokio可以简化这一过程。
相关问题
StoryDiffusion与其他生成式AI模型相比如何?
StoryDiffusion在保持图像序列的视觉和意义统一性方面表现突出,这是其他模型常常不足的领域。其一致性自注意力促进了更具凝聚力的叙事,在角色创作和基于图像的故事中表现优异。语义运动预测器确保更流畅的视频流动,使其区别于专注于单一图像或视频的工具。虽然存在其他替代方案,但StoryDiffusion作为一个令人兴奋的进步值得关注。
相关文章
 AI音乐工具:承诺、挑战与真实说唱实验
人工智能正在变革创意产业,包括音乐。先进的AI平台使歌曲创作变得可触及,使没有深厚专业知识的人也能创作和完善曲目。本文探讨了AI驱动音乐的优势与不足,详细描述了一位创作者使用AI打造说唱曲目的历程,并评估了成果。内容涵盖了障碍、成功以及AI在声音制作中不断演变的角色。关键要点AI平台开启了音乐创作的新途径,但也带有明显的局限性。ChatGPT擅长起草歌词,但常缺乏个人情感和生活故事的细腻层次。当前
英伟达的收益:超越出口限制,聚焦新硬件需求
英伟达将于周三市场收盘后公布其2026财年第一季度财报,截至4月27日结束。虽然美国芯片出口管制引发了对英伟达全球芯片销售及未来前景的担忧,但一些专家认为,这并非公司即将发布财报的关键焦点。扎克斯投资研究公司高级股票策略师凯文·库克,拥有十年英伟达研究经验,他在接受TechCrunch采访时表示,英伟达自2月起开始发货的GB200 NVL72硬件——一款单机架百亿亿次计算计算机——更值得投资者关注
Chime AI智能录音机评测:提升现代专业人士的效率
在快速发展的现代环境中,创新型商业领袖和高管不断寻找能够提升效率和优化运营的设备。Chime AI智能录音机作为一款变革性解决方案脱颖而出,提供先进的AI驱动音频捕获和转录功能,设计精美且直观易用。探索这款尖端工具如何重塑您的录音和数据利用方式。关键要点Chime AI智能录音机面向创新型企业主和高管。它提供卓越的音频捕获和即时文本转换功能。AI工具包括概要、会议大纲、可视化图表和任务列表。此设备
评论 (0)
0/200
AI音乐工具:承诺、挑战与真实说唱实验
人工智能正在变革创意产业,包括音乐。先进的AI平台使歌曲创作变得可触及,使没有深厚专业知识的人也能创作和完善曲目。本文探讨了AI驱动音乐的优势与不足,详细描述了一位创作者使用AI打造说唱曲目的历程,并评估了成果。内容涵盖了障碍、成功以及AI在声音制作中不断演变的角色。关键要点AI平台开启了音乐创作的新途径,但也带有明显的局限性。ChatGPT擅长起草歌词,但常缺乏个人情感和生活故事的细腻层次。当前
英伟达的收益:超越出口限制,聚焦新硬件需求
英伟达将于周三市场收盘后公布其2026财年第一季度财报,截至4月27日结束。虽然美国芯片出口管制引发了对英伟达全球芯片销售及未来前景的担忧,但一些专家认为,这并非公司即将发布财报的关键焦点。扎克斯投资研究公司高级股票策略师凯文·库克,拥有十年英伟达研究经验,他在接受TechCrunch采访时表示,英伟达自2月起开始发货的GB200 NVL72硬件——一款单机架百亿亿次计算计算机——更值得投资者关注
Chime AI智能录音机评测:提升现代专业人士的效率
在快速发展的现代环境中,创新型商业领袖和高管不断寻找能够提升效率和优化运营的设备。Chime AI智能录音机作为一款变革性解决方案脱颖而出,提供先进的AI驱动音频捕获和转录功能,设计精美且直观易用。探索这款尖端工具如何重塑您的录音和数据利用方式。关键要点Chime AI智能录音机面向创新型企业主和高管。它提供卓越的音频捕获和即时文本转换功能。AI工具包括概要、会议大纲、可视化图表和任务列表。此设备
评论 (0)
0/200
在快速变化的人工智能世界中,StoryDiffusion作为创作者的变革性工具脱颖而出。这一先进的AI模型解决了生成技术中的关键问题:保持图像与视频系列的一致性。它旨在变革视觉叙事方式,为创作者提供无与伦比的掌控力和作品统一性。该模型专为生成具有稳定视觉和意义对齐的图像与视频而设计,非常适合创作漫画、动画故事等内容。
关键要点
StoryDiffusion代表了一种专注于统一图像与视频输出的全新生成式AI方法。
它解决了保持视觉叙事一致性的重要问题。
该系统采用一致性自注意力方法,确保视觉与意义上的稳定性。
StoryDiffusion引入了语义运动预测器,实现无缝视频过渡。
它支持多种艺术形式,如漫画、动画和真实照片。
该工具可通过Hugging Face网站访问或进行本地安装。
理解StoryDiffusion
一致性生成模型的需求
生成系统在根据文本提示生成图像和视频方面已取得巨大进步。像Stable Diffusion这样的工具扩展了创作可能性。然而,一个重大障碍依然存在:确保一系列视觉内容的一致性。例如,跨场景展示一个角色,同时保持其外观、风格和本质不变是一大挑战。
StoryDiffusion在此发挥作用,为需要可靠、引人入胜故事线的创作者提供解决方案。
StoryDiffusion作为一个新兴的生成系统,满足了图像序列中保持稳定内容的需求。它为希望通过图像和视频以统一、吸引人的风格编织故事的创作者提供了希望。该方法仍在发展中,提升了生成图像的保真度,保留了面部和美学等特征,并在视频和静态图像中保持主题和元素对齐。
一致性自注意力:StoryDiffusion的核心
一致性自注意力是StoryDiffusion的核心技术元素。
此功能将一组图像关联起来,确保主题一致性。它有助于同时维持多个角色身份,并在图像序列中生成稳定的角色。这对于复杂主题和细节尤为重要。没有它,视觉流程可能会出现断裂,使观众难以跟踪故事。
多角色生成
StoryDiffusion在同时维持多个角色身份并在图像集中创建统一角色的能力,使其成为叙事者的灵活资产。它让创作者能够构建引人入胜的漫画和视频片段,具备可靠的自注意力。
语义运动预测器:革新视频过渡
根据研究,StoryDiffusion通过添加语义运动预测器推进了视频创作,该预测器旨在以有意义的方式预测图像之间的元素变化,超越单纯的视觉效果。
这一突破在视频制作中表现突出。语义运动预测器以语义方式预测帧间元素移动,生成具有流畅变化和稳定主题的视频。它不仅追求视觉平滑,还保护了故事的意图和情感共鸣。
开始使用StoryDiffusion
访问StoryDiffusion
StoryDiffusion为创作者提供了多种使用途径:
- Hugging Face:通过Hugging Face平台访问模型,免费且易于使用。
这提供了一个可靠的途径,让用户无需本地安装即可测试和探索StoryDiffusion的强大功能。
- 本地安装:对于偏好本地运行的用户,StoryDiffusion可通过GitHub安装。这提供了更多控制和调整空间,但需要技术知识。
- Pinokio:此AI应用平台支持安装。它包括Stable Diffusion变体,并允许通过Pinokio将StoryDiffusion添加到您的设备。
可用模型
StoryDiffusion提供多种用于图像工作的模型,包括RealVision或Unstable。
StoryDiffusion提供两种主要模型用于生成图像:
- Stable:提供可靠、一致的结果,适合优先考虑视觉可靠性的工作。
- RealVision:增强逼真特性,生成充满深度和表面细节的图像。
使用StoryDiffusion漫画的关键要素
使用StoryDiffusion涉及对负面提示、漫画轮廓、风格和模型的精确输入。这些选择决定了AI生成与您愿景匹配的图像效果。您可以定义所需的美学风格,或选择特定面部和特征以获得定制结果。有用的建议包括:
- 参考图像可以指导您的风格选择
- 针对特定美学调整的模型在图像创作中能产生更好的结果
生成AI漫画的简单步骤
初始设置
StoryDiffusion的界面注重简洁。以下是开始的简化指南:
步骤1:选择您的首选模型:首先选择用于图像生成的人工智能类型
步骤2:角色文本描述:此部分允许您输入AI应生成的内容。输入适合目标图像的提示词。
漫画设置
步骤3:负面提示:包含任何避免提示,以阻止不需要的特征
步骤4:风格模板:定义AI在图像构建中使用的风格指南。
步骤5:漫画描述:将每个面板概述为独立的漫画框架,与您建立的角色风格匹配。
图像创建
步骤6:超参数:根据需要调整设置。如不确定,保持默认值
步骤7:启动生成:点击生成以创建图像并为您的漫画赋予生命!
定价
免费与开源:为内容创作民主化AI
StoryDiffusion的一个突出特点是其可访问性。
作为一个免费、开源的选项,它为多样化用户打开了基于AI的创作之门。这与需要高额订阅或按次付费的专有AI系统形成鲜明对比。通过消除这些障碍,StoryDiffusion使个人艺术家、小团队和学校能够利用AI进行视觉叙事。
StoryDiffusion的未来之路
优点
可通过Pinokio进行设置
提升逼真视觉效果
提供稳定、可靠的结果
免费且开源
缺点
目前处于测试阶段,可能会出现问题。
当前不支持图像参考。
对于缺乏技术技能的新手具有挑战性
StoryDiffusion的核心功能
关键功能:释放创作潜力
卡通角色生成:支持创作生动、一致的卡通形象。
多角色生成:同时维持多个角色身份,并在图像序列中构建一致的形象。
长视频生成:StoryDiffusion利用其语义运动预测器,基于生成的统一图像或用户提供的图像创建高质量视频。
使用场景
开启新的创作途径
StoryDiffusion的一致性自注意力和运动预测适用于多种创作场景:
- 漫画与图画小说:在各部分中保持角色一致性,打造引人入胜的视觉故事。
- 动画视频:确保流畅、合理的过渡以维持观众参与度。
- 教育材料:为课程和演讲创建吸引人的视觉内容,具备稳定的角色和场景。
- 营销与广告:创建具有一致外观的突出宣传内容,提升品牌影响力。
常见问题
StoryDiffusion真的是免费且开源的吗?
是的,StoryDiffusion完全免费且开源。用户可以自由使用、修改和分享,无需任何费用。它遵循MIT许可证。
本地安装StoryDiffusion需要多高的技术专长?
虽然通过Hugging Face访问无需设置,但通过GitHub进行本地安装需要一定技能。了解命令、Python和依赖项会有所帮助。不过,Pinokio可以简化这一过程。
相关问题
StoryDiffusion与其他生成式AI模型相比如何?
StoryDiffusion在保持图像序列的视觉和意义统一性方面表现突出,这是其他模型常常不足的领域。其一致性自注意力促进了更具凝聚力的叙事,在角色创作和基于图像的故事中表现优异。语义运动预测器确保更流畅的视频流动,使其区别于专注于单一图像或视频的工具。虽然存在其他替代方案,但StoryDiffusion作为一个令人兴奋的进步值得关注。










 AI音乐工具:承诺、挑战与真实说唱实验
人工智能正在变革创意产业,包括音乐。先进的AI平台使歌曲创作变得可触及,使没有深厚专业知识的人也能创作和完善曲目。本文探讨了AI驱动音乐的优势与不足,详细描述了一位创作者使用AI打造说唱曲目的历程,并评估了成果。内容涵盖了障碍、成功以及AI在声音制作中不断演变的角色。关键要点AI平台开启了音乐创作的新途径,但也带有明显的局限性。ChatGPT擅长起草歌词,但常缺乏个人情感和生活故事的细腻层次。当前
AI音乐工具:承诺、挑战与真实说唱实验
人工智能正在变革创意产业,包括音乐。先进的AI平台使歌曲创作变得可触及,使没有深厚专业知识的人也能创作和完善曲目。本文探讨了AI驱动音乐的优势与不足,详细描述了一位创作者使用AI打造说唱曲目的历程,并评估了成果。内容涵盖了障碍、成功以及AI在声音制作中不断演变的角色。关键要点AI平台开启了音乐创作的新途径,但也带有明显的局限性。ChatGPT擅长起草歌词,但常缺乏个人情感和生活故事的细腻层次。当前
 英伟达的收益:超越出口限制,聚焦新硬件需求
英伟达将于周三市场收盘后公布其2026财年第一季度财报,截至4月27日结束。虽然美国芯片出口管制引发了对英伟达全球芯片销售及未来前景的担忧,但一些专家认为,这并非公司即将发布财报的关键焦点。扎克斯投资研究公司高级股票策略师凯文·库克,拥有十年英伟达研究经验,他在接受TechCrunch采访时表示,英伟达自2月起开始发货的GB200 NVL72硬件——一款单机架百亿亿次计算计算机——更值得投资者关注
英伟达的收益:超越出口限制,聚焦新硬件需求
英伟达将于周三市场收盘后公布其2026财年第一季度财报,截至4月27日结束。虽然美国芯片出口管制引发了对英伟达全球芯片销售及未来前景的担忧,但一些专家认为,这并非公司即将发布财报的关键焦点。扎克斯投资研究公司高级股票策略师凯文·库克,拥有十年英伟达研究经验,他在接受TechCrunch采访时表示,英伟达自2月起开始发货的GB200 NVL72硬件——一款单机架百亿亿次计算计算机——更值得投资者关注
 Chime AI智能录音机评测:提升现代专业人士的效率
在快速发展的现代环境中,创新型商业领袖和高管不断寻找能够提升效率和优化运营的设备。Chime AI智能录音机作为一款变革性解决方案脱颖而出,提供先进的AI驱动音频捕获和转录功能,设计精美且直观易用。探索这款尖端工具如何重塑您的录音和数据利用方式。关键要点Chime AI智能录音机面向创新型企业主和高管。它提供卓越的音频捕获和即时文本转换功能。AI工具包括概要、会议大纲、可视化图表和任务列表。此设备
Chime AI智能录音机评测:提升现代专业人士的效率
在快速发展的现代环境中,创新型商业领袖和高管不断寻找能够提升效率和优化运营的设备。Chime AI智能录音机作为一款变革性解决方案脱颖而出,提供先进的AI驱动音频捕获和转录功能,设计精美且直观易用。探索这款尖端工具如何重塑您的录音和数据利用方式。关键要点Chime AI智能录音机面向创新型企业主和高管。它提供卓越的音频捕获和即时文本转换功能。AI工具包括概要、会议大纲、可视化图表和任务列表。此设备













