
















 집
집StoryDiffusion, 일관된 AI 이미지 및 비디오 제작의 새 시대를 열다
빠르게 변화하는 인공지능 세계에서 StoryDiffusion은 창작자들에게 획기적인 도구로 두각을 나타냅니다. 이 고급 AI 모델은 생성 기술의 핵심 문제를 해결합니다: 이미지와 비디오 시리즈에서 일관성을 유지하는 것. 시각적으로 이야기를 전달하는 방식을 혁신하여 창작자들에게 작업의 통일성과 감독을 제공합니다. 일관된 시각적, 의미적 정렬로 이미지와 비디오를 생성하도록 설계된 이 도구는 만화, 애니메이션 이야기 등을 제작하는 데 완벽합니다.
주요 포인트
StoryDiffusion은 일관된 이미지 및 비디오 출력을 목표로 한 새로운 생성 AI 접근 방식입니다.
시각적 내러티브에서 통일성을 유지하는 중요한 문제를 해결합니다.
이 시스템은 시각적, 의미적 일관성을 보장하는 Consistent Self-Attention 방법을 특징으로 합니다.
StoryDiffusion은 부드러운 비디오 전환을 위해 Semantic Motion Predictor를 도입했습니다.
만화, 애니메이션, 사실적인 사진 등 다양한 예술적 형식을 처리합니다.
이 도구는 Hugging Face 사이트를 통해 이용하거나 로컬 설치가 가능합니다.
StoryDiffusion 이해하기
일관된 생성 모델의 필요성
생성 시스템은 텍스트 프롬프트에서 이미지와 비디오를 생성하는 데 크게 발전했습니다. Stable Diffusion 같은 도구는 창의적 옵션을 확장했습니다. 그러나 큰 장애물이 남아 있습니다: 시각적 연속성의 일관성을 보장하는 것. 예를 들어, 캐릭터의 외형, 스타일, 본질을 유지하면서 여러 장면에서 보여주는 것은 어렵습니다.
StoryDiffusion은 신뢰할 수 있고 인상적인 스토리라인을 필요로 하는 창작자들에게 해결책을 제공합니다.
StoryDiffusion은 이미지 시퀀스에서 일관된 콘텐츠를 요구하는 새로운 생성 시스템입니다. 통일되고 매력적인 스타일로 이미지와 비디오를 통해 이야기를 엮으려는 창작자들에게 가능성을 제공합니다. 아직 발전 중인 이 방법은 생성된 이미지의 충실도를 높이고, 얼굴과 미적 특성을 보존하며, 비디오와 스틸 이미지에서 주제와 요소를 정렬합니다.
Consistent Self-Attention: StoryDiffusion의 핵심
Consistent Self-Attention은 StoryDiffusion의 핵심 기술 요소입니다.
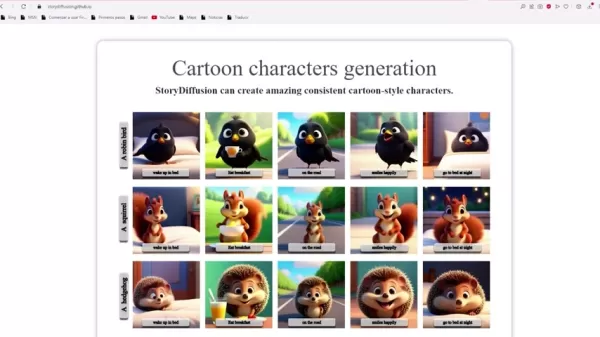
이 기능은 그룹 내 여러 이미지를 연결하여 주제의 일관성을 확보합니다. 여러 캐릭터의 정체성을 동시에 유지하고 이미지 체인에서 일관된 형상을 생성하는 데 도움을 줍니다. 이는 복잡한 주제와 세부 사항에서 가장 중요합니다. 이 기능이 없으면 시각적 흐름이 단절되어 관객이 이야기를 따라가기 어려워질 수 있습니다.
다중 캐릭터 생성
StoryDiffusion은 여러 캐릭터의 정체성을 동시에 유지하고 이미지 세트에서 일관된 형상을 제작하는 능력으로, 이야기꾼들에게 유연한 자산이 됩니다. 신뢰할 수 있는 자가 주의(self-attention)로 인상적인 만화와 비디오 세그먼트를 제작할 수 있습니다.
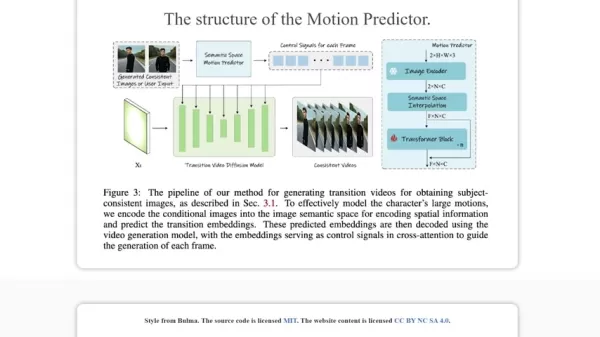
Semantic Motion Predictor: 비디오 전환 혁신
연구에 따르면, StoryDiffusion은 단순한 시각적 요소를 넘어 의미 있는 방식으로 이미지 간 요소 이동을 예측하도록 설계된 Semantic Motion Predictor를 추가하여 비디오 제작을 발전시킵니다.
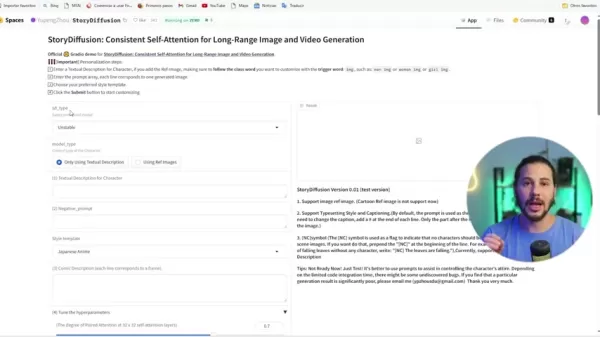
이 혁신은 비디오 제작에서 빛을 발합니다. Semantic Motion Predictor는 프레임 간 요소 이동을 의미적으로 예측하여 부드러운 변화와 안정된 주제를 가진 비디오를 생성합니다. 이는 시각적 부드러움을 넘어 이야기의 의도와 감정적 공명을 보호합니다.
StoryDiffusion 시작하기
StoryDiffusion 접근
StoryDiffusion은 창작자들이 시작할 수 있는 여러 경로를 제공합니다:
- Hugging Face: Hugging Face 플랫폼을 통해 무료로 쉽게 접근할 수 있습니다.
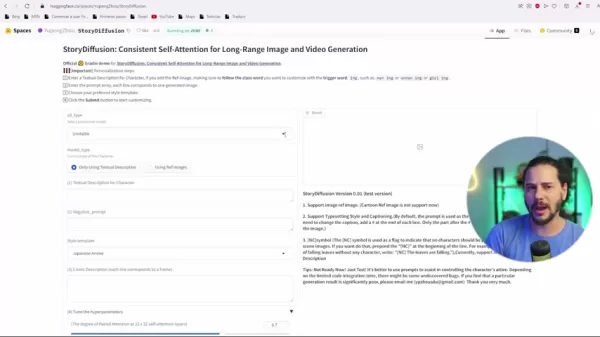
로컬 설치 없이 StoryDiffusion의 강점을 테스트하고 탐색할 수 있는 견고한 경로를 제공합니다.
- 로컬 설치: 디바이스에서 실행을 선호하는 사용자를 위해 StoryDiffusion은 GitHub를 통해 설치됩니다. 이는 더 많은 제어와 조정을 제공하지만 기술적 노하우가 필요합니다.
- Pinokio: 이 AI 앱 플랫폼은 설치를 가능하게 합니다. Stable Diffusion 변형을 포함하며 Pinokio를 통해 StoryDiffusion을 기기에 추가할 수 있습니다.
사용 가능한 모델
StoryDiffusion은 RealVision 또는 Unstable을 포함한 이미지 작업을 위한 다양한 모델을 제공합니다.
StoryDiffusion은 이미지를 생성하기 위해 두 가지 주요 모델을 제공합니다:
- Stable: 시각적 신뢰성을 우선시하는 작업에 적합한 안정적이고 일관된 결과를 제공합니다.
- RealVision: 사실적인 품질을 강화하여 깊이와 표면 디테일이 가득한 이미지를 생성합니다.
StoryDiffusion 만화 사용의 핵심 요소
StoryDiffusion 작업은 부정 프롬프트, 만화 개요, 스타일, 모델에 대한 정확한 입력을 포함합니다. 이러한 선택은 AI가 사용자의 비전에 맞는 이미지를 생성하는 데 영향을 미칩니다. 원하는 미학을 정의하거나 특정 얼굴과 특성을 선택하여 맞춤형 결과를 얻을 수 있습니다. 유용한 팁은 다음과 같습니다:
- 참조 이미지는 스타일 선택을 안내할 수 있습니다.
- 특정 미학에 맞춘 모델은 이미지 생성에서 더 나은 결과를 제공합니다.
AI 만화 생성을 위한 쉬운 단계
초기 설정
StoryDiffusion의 인터페이스는 단순함을 우선시합니다. 시작을 위한 간소화된 가이드는 다음과 같습니다:
1단계: 선호 모델 선택: 이미지 제작을 위한 생성 AI 유형을 선택하여 시작합니다.
2단계: 캐릭터 텍스트 설명: 이 섹션에서는 AI가 제작할 내용을 입력할 수 있습니다. 의도된 이미지에 적합한 용어로 프롬프트를 입력하세요.
만화 설정
3단계: 부정 프롬프트: 원치 않는 기능을 차단하기 위해 회피 프롬프트를 포함합니다.
4단계: 스타일 템플릿: 이미지 제작에 사용할 AI의 스타일 가이드를 정의합니다.
5단계: 만화 설명: 설정한 캐릭터 스타일에 맞춰 각 패널을 별개의 만화 프레임으로 개요를 작성합니다.
이미지 생성
6단계: 하이퍼파라미터: 필요에 따라 설정을 조정합니다. 확실하지 않다면 기본값을 유지하세요.
7단계: 생성 시작: 생성 버튼을 눌러 이미지를 만들고 만화를 애니메이션화하세요!
가격
무료 및 오픈 소스: 콘텐츠 제작을 위한 AI 민주화
StoryDiffusion의 두드러진 특징은 접근성입니다.

무료 오픈 소스 옵션으로, 다양한 사용자에게 AI 기반 창작을 개방합니다. 이는 높은 구독료나 사용당 비용을 요구하는 독점 AI 시스템과 크게 다릅니다. 이러한 장벽을 제거함으로써 StoryDiffusion은 개인 아티스트, 소규모 팀, 학교가 시각적 이야기를 위해 AI를 활용할 수 있도록 합니다.
StoryDiffusion의 앞으로의 길
장점
Pinokio를 통한 설정 옵션
사실적인 시각 개선
안정적이고 신뢰할 수 있는 결과 제공
무료 및 오픈 소스로 제공
단점
현재 베타 상태로, 오류가 발생할 수 있음.
이미지 참조 지원은 현재 불가능.
기술적 기술이 부족한 초보자에게는 도전적임.
StoryDiffusion의 핵심 기능
주요 기능: 창의적 잠재력 발휘
만화 캐릭터 생성: 생생하고 일관된 만화 캐릭터를 제작할 수 있습니다.
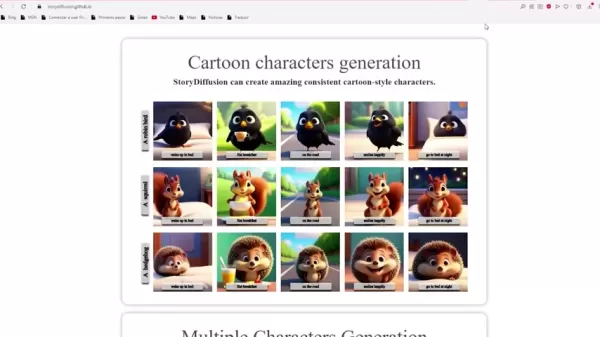
다중 캐릭터 생성: 여러 캐릭터의 정체성을 함께 유지하고 이미지 시퀀스에서 일관된 형상을 구축합니다.
긴 비디오 생성: StoryDiffusion은 생성된 일관된 이미지 또는 사용자 제공 이미지를 기반으로 Semantic Motion Predictor를 사용해 최고 수준의 비디오를 생성합니다.
사용 사례
새로운 창의적 길 개척
StoryDiffusion의 일관된 자가 주의와 모션 예측은 다양한 창작 맥락에 적용됩니다:
- 만화 및 그래픽 노블: 매력적인 시각적 이야기를 위해 섹션 간 캐릭터 일관성을 유지합니다.
- 애니메이션 비디오: 관객의 몰입을 유지하기 위해 부드럽고 의미 있는 전환을 보장합니다.
- 교육 자료: 수업과 강의용으로 매력적인 시각 자료를 안정된 캐릭터와 설정으로 제작합니다.
- 마케팅 및 광고: 일관된 룩으로 두드러지는 프로모션 콘텐츠를 만들어 브랜드 존재감을 높입니다.
FAQ
StoryDiffusion은 정말 무료이고 오픈 소스인가요?
네, StoryDiffusion은 무료이며 오픈 소스입니다. 사용자는 비용 없이 자유롭게 사용, 수정, 공유할 수 있습니다. MIT 라이선스에 따릅니다.
StoryDiffusion을 로컬로 설치하려면 어느 정도의 기술적 전문성이 필요한가요?
Hugging Face 접근은 설치를 생략하지만, GitHub 로컬 설치는 약간의 기술이 필요합니다. 명령어, Python, 종속성에 대한 지식이 도움이 됩니다. 그래도 Pinokio는 이를 쉽게 할 수 있습니다.
관련 질문
StoryDiffusion은 다른 생성 AI 모델과 어떻게 비교되나요?
StoryDiffusion은 이미지 체인에서 시각적, 의미적 통일성을 유지하는 데 탁월하며, 다른 모델이 종종 뒤처지는 영역입니다. Consistent Self-Attention은 캐릭터 작업과 이미지 기반 이야기에서 우수한 응집력 있는 내러티브를 촉진합니다. Semantic Motion Predictor는 더 부드러운 비디오 흐름을 보장하여 단일 이미지나 비디오 중심의 도구들과 구별됩니다. 대안이 존재하지만, StoryDiffusion은 주목할 만한 흥미로운 발전으로 나타납니다.
관련 기사
 야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
관련 특별 주제 추천
사업
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
관련 특별 주제 추천
사업
 최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
 10 도구
10 도구
 xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai
챗봇
최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

 의견 (2)
0/500
의견 (2)
0/500
![RaymondBaker]()
StoryDiffusion klingt echt vielversprechend! Endlich mal ein Tool, das sich auf Konsistenz konzentriert. Ich habe schon so viele KI-Bilder gesehen, wo die Hauptfigur in jedem Frame anders aussieht – total nervig. Hoffentlich ist das nicht nur ein Hype und die Technologie wird auch für kleinere Projekte zugänglich sein. Die Entwicklung geht so schnell, man kann kaum hinterherkommen! 😅
![HarryPerez]()
Создание консистентных изображений с ИИ всегда было сложной задачей, но StoryDiffusion похоже действительно решает эту проблему. Мне интересно, насколько хорошо это работает для длинных повествований 🤔 Может ли это изменить подход к созданию комиксов?
빠르게 변화하는 인공지능 세계에서 StoryDiffusion은 창작자들에게 획기적인 도구로 두각을 나타냅니다. 이 고급 AI 모델은 생성 기술의 핵심 문제를 해결합니다: 이미지와 비디오 시리즈에서 일관성을 유지하는 것. 시각적으로 이야기를 전달하는 방식을 혁신하여 창작자들에게 작업의 통일성과 감독을 제공합니다. 일관된 시각적, 의미적 정렬로 이미지와 비디오를 생성하도록 설계된 이 도구는 만화, 애니메이션 이야기 등을 제작하는 데 완벽합니다.
주요 포인트
StoryDiffusion은 일관된 이미지 및 비디오 출력을 목표로 한 새로운 생성 AI 접근 방식입니다.
시각적 내러티브에서 통일성을 유지하는 중요한 문제를 해결합니다.
이 시스템은 시각적, 의미적 일관성을 보장하는 Consistent Self-Attention 방법을 특징으로 합니다.
StoryDiffusion은 부드러운 비디오 전환을 위해 Semantic Motion Predictor를 도입했습니다.
만화, 애니메이션, 사실적인 사진 등 다양한 예술적 형식을 처리합니다.
이 도구는 Hugging Face 사이트를 통해 이용하거나 로컬 설치가 가능합니다.
StoryDiffusion 이해하기
일관된 생성 모델의 필요성
생성 시스템은 텍스트 프롬프트에서 이미지와 비디오를 생성하는 데 크게 발전했습니다. Stable Diffusion 같은 도구는 창의적 옵션을 확장했습니다. 그러나 큰 장애물이 남아 있습니다: 시각적 연속성의 일관성을 보장하는 것. 예를 들어, 캐릭터의 외형, 스타일, 본질을 유지하면서 여러 장면에서 보여주는 것은 어렵습니다.
StoryDiffusion은 신뢰할 수 있고 인상적인 스토리라인을 필요로 하는 창작자들에게 해결책을 제공합니다.
StoryDiffusion은 이미지 시퀀스에서 일관된 콘텐츠를 요구하는 새로운 생성 시스템입니다. 통일되고 매력적인 스타일로 이미지와 비디오를 통해 이야기를 엮으려는 창작자들에게 가능성을 제공합니다. 아직 발전 중인 이 방법은 생성된 이미지의 충실도를 높이고, 얼굴과 미적 특성을 보존하며, 비디오와 스틸 이미지에서 주제와 요소를 정렬합니다.
Consistent Self-Attention: StoryDiffusion의 핵심
Consistent Self-Attention은 StoryDiffusion의 핵심 기술 요소입니다.
이 기능은 그룹 내 여러 이미지를 연결하여 주제의 일관성을 확보합니다. 여러 캐릭터의 정체성을 동시에 유지하고 이미지 체인에서 일관된 형상을 생성하는 데 도움을 줍니다. 이는 복잡한 주제와 세부 사항에서 가장 중요합니다. 이 기능이 없으면 시각적 흐름이 단절되어 관객이 이야기를 따라가기 어려워질 수 있습니다.
다중 캐릭터 생성
StoryDiffusion은 여러 캐릭터의 정체성을 동시에 유지하고 이미지 세트에서 일관된 형상을 제작하는 능력으로, 이야기꾼들에게 유연한 자산이 됩니다. 신뢰할 수 있는 자가 주의(self-attention)로 인상적인 만화와 비디오 세그먼트를 제작할 수 있습니다.
Semantic Motion Predictor: 비디오 전환 혁신
연구에 따르면, StoryDiffusion은 단순한 시각적 요소를 넘어 의미 있는 방식으로 이미지 간 요소 이동을 예측하도록 설계된 Semantic Motion Predictor를 추가하여 비디오 제작을 발전시킵니다.
이 혁신은 비디오 제작에서 빛을 발합니다. Semantic Motion Predictor는 프레임 간 요소 이동을 의미적으로 예측하여 부드러운 변화와 안정된 주제를 가진 비디오를 생성합니다. 이는 시각적 부드러움을 넘어 이야기의 의도와 감정적 공명을 보호합니다.
StoryDiffusion 시작하기
StoryDiffusion 접근
StoryDiffusion은 창작자들이 시작할 수 있는 여러 경로를 제공합니다:
- Hugging Face: Hugging Face 플랫폼을 통해 무료로 쉽게 접근할 수 있습니다.
로컬 설치 없이 StoryDiffusion의 강점을 테스트하고 탐색할 수 있는 견고한 경로를 제공합니다.
- 로컬 설치: 디바이스에서 실행을 선호하는 사용자를 위해 StoryDiffusion은 GitHub를 통해 설치됩니다. 이는 더 많은 제어와 조정을 제공하지만 기술적 노하우가 필요합니다.
- Pinokio: 이 AI 앱 플랫폼은 설치를 가능하게 합니다. Stable Diffusion 변형을 포함하며 Pinokio를 통해 StoryDiffusion을 기기에 추가할 수 있습니다.
사용 가능한 모델
StoryDiffusion은 RealVision 또는 Unstable을 포함한 이미지 작업을 위한 다양한 모델을 제공합니다.
StoryDiffusion은 이미지를 생성하기 위해 두 가지 주요 모델을 제공합니다:
- Stable: 시각적 신뢰성을 우선시하는 작업에 적합한 안정적이고 일관된 결과를 제공합니다.
- RealVision: 사실적인 품질을 강화하여 깊이와 표면 디테일이 가득한 이미지를 생성합니다.
StoryDiffusion 만화 사용의 핵심 요소
StoryDiffusion 작업은 부정 프롬프트, 만화 개요, 스타일, 모델에 대한 정확한 입력을 포함합니다. 이러한 선택은 AI가 사용자의 비전에 맞는 이미지를 생성하는 데 영향을 미칩니다. 원하는 미학을 정의하거나 특정 얼굴과 특성을 선택하여 맞춤형 결과를 얻을 수 있습니다. 유용한 팁은 다음과 같습니다:
- 참조 이미지는 스타일 선택을 안내할 수 있습니다.
- 특정 미학에 맞춘 모델은 이미지 생성에서 더 나은 결과를 제공합니다.
AI 만화 생성을 위한 쉬운 단계
초기 설정
StoryDiffusion의 인터페이스는 단순함을 우선시합니다. 시작을 위한 간소화된 가이드는 다음과 같습니다:
1단계: 선호 모델 선택: 이미지 제작을 위한 생성 AI 유형을 선택하여 시작합니다.
2단계: 캐릭터 텍스트 설명: 이 섹션에서는 AI가 제작할 내용을 입력할 수 있습니다. 의도된 이미지에 적합한 용어로 프롬프트를 입력하세요.
만화 설정
3단계: 부정 프롬프트: 원치 않는 기능을 차단하기 위해 회피 프롬프트를 포함합니다.
4단계: 스타일 템플릿: 이미지 제작에 사용할 AI의 스타일 가이드를 정의합니다.
5단계: 만화 설명: 설정한 캐릭터 스타일에 맞춰 각 패널을 별개의 만화 프레임으로 개요를 작성합니다.
이미지 생성
6단계: 하이퍼파라미터: 필요에 따라 설정을 조정합니다. 확실하지 않다면 기본값을 유지하세요.
7단계: 생성 시작: 생성 버튼을 눌러 이미지를 만들고 만화를 애니메이션화하세요!
가격
무료 및 오픈 소스: 콘텐츠 제작을 위한 AI 민주화
StoryDiffusion의 두드러진 특징은 접근성입니다.
무료 오픈 소스 옵션으로, 다양한 사용자에게 AI 기반 창작을 개방합니다. 이는 높은 구독료나 사용당 비용을 요구하는 독점 AI 시스템과 크게 다릅니다. 이러한 장벽을 제거함으로써 StoryDiffusion은 개인 아티스트, 소규모 팀, 학교가 시각적 이야기를 위해 AI를 활용할 수 있도록 합니다.
StoryDiffusion의 앞으로의 길
장점
Pinokio를 통한 설정 옵션
사실적인 시각 개선
안정적이고 신뢰할 수 있는 결과 제공
무료 및 오픈 소스로 제공
단점
현재 베타 상태로, 오류가 발생할 수 있음.
이미지 참조 지원은 현재 불가능.
기술적 기술이 부족한 초보자에게는 도전적임.
StoryDiffusion의 핵심 기능
주요 기능: 창의적 잠재력 발휘
만화 캐릭터 생성: 생생하고 일관된 만화 캐릭터를 제작할 수 있습니다.
다중 캐릭터 생성: 여러 캐릭터의 정체성을 함께 유지하고 이미지 시퀀스에서 일관된 형상을 구축합니다.
긴 비디오 생성: StoryDiffusion은 생성된 일관된 이미지 또는 사용자 제공 이미지를 기반으로 Semantic Motion Predictor를 사용해 최고 수준의 비디오를 생성합니다.
사용 사례
새로운 창의적 길 개척
StoryDiffusion의 일관된 자가 주의와 모션 예측은 다양한 창작 맥락에 적용됩니다:
- 만화 및 그래픽 노블: 매력적인 시각적 이야기를 위해 섹션 간 캐릭터 일관성을 유지합니다.
- 애니메이션 비디오: 관객의 몰입을 유지하기 위해 부드럽고 의미 있는 전환을 보장합니다.
- 교육 자료: 수업과 강의용으로 매력적인 시각 자료를 안정된 캐릭터와 설정으로 제작합니다.
- 마케팅 및 광고: 일관된 룩으로 두드러지는 프로모션 콘텐츠를 만들어 브랜드 존재감을 높입니다.
FAQ
StoryDiffusion은 정말 무료이고 오픈 소스인가요?
네, StoryDiffusion은 무료이며 오픈 소스입니다. 사용자는 비용 없이 자유롭게 사용, 수정, 공유할 수 있습니다. MIT 라이선스에 따릅니다.
StoryDiffusion을 로컬로 설치하려면 어느 정도의 기술적 전문성이 필요한가요?
Hugging Face 접근은 설치를 생략하지만, GitHub 로컬 설치는 약간의 기술이 필요합니다. 명령어, Python, 종속성에 대한 지식이 도움이 됩니다. 그래도 Pinokio는 이를 쉽게 할 수 있습니다.
관련 질문
StoryDiffusion은 다른 생성 AI 모델과 어떻게 비교되나요?
StoryDiffusion은 이미지 체인에서 시각적, 의미적 통일성을 유지하는 데 탁월하며, 다른 모델이 종종 뒤처지는 영역입니다. Consistent Self-Attention은 캐릭터 작업과 이미지 기반 이야기에서 우수한 응집력 있는 내러티브를 촉진합니다. Semantic Motion Predictor는 더 부드러운 비디오 흐름을 보장하여 단일 이미지나 비디오 중심의 도구들과 구별됩니다. 대안이 존재하지만, StoryDiffusion은 주목할 만한 흥미로운 발전으로 나타납니다.










 야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
 WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

StoryDiffusion klingt echt vielversprechend! Endlich mal ein Tool, das sich auf Konsistenz konzentriert. Ich habe schon so viele KI-Bilder gesehen, wo die Hauptfigur in jedem Frame anders aussieht – total nervig. Hoffentlich ist das nicht nur ein Hype und die Technologie wird auch für kleinere Projekte zugänglich sein. Die Entwicklung geht so schnell, man kann kaum hinterherkommen! 😅
Создание консистентных изображений с ИИ всегда было сложной задачей, но StoryDiffusion похоже действительно решает эту проблему. Мне интересно, насколько хорошо это работает для длинных повествований 🤔 Может ли это изменить подход к созданию комиксов?













