




StoryDiffusionが一貫性のあるAI画像とビデオ作成の新時代を切り開く
急速に変化する人工知能の世界で、StoryDiffusionはクリエイターにとって革新的なツールとして際立っています。この先進的なAIモデルは、生成技術の重要な課題である一連の画像とビデオの均一性を保つことに取り組んでいます。視覚的なストーリーテリングを変革し、クリエイターに比類のない監視と作品の一貫性を提供することを目指しています。視覚的および意味的に一貫した画像とビデオを生成するために構築されており、漫画、アニメーションストーリーなどに最適です。
主なポイント
StoryDiffusionは、均一な画像とビデオの出力に焦点を当てた新しい生成AIアプローチを表します。
視覚的な物語の一貫性を維持するという重要な課題に取り組んでいます。
このシステムは、視覚的および意味的な一貫性を保証する一貫性自己注意メカニズムを特徴としています。
StoryDiffusionは、シームレスなビデオ移行のためのセマンティックモーションプレディクターを導入しています。
漫画、アニメ、現実的な写真など、多様な芸術形式を扱います。
このツールは、Hugging Faceサイトを通じて、またはローカルセットアップで利用可能です。
StoryDiffusionの理解
一貫性のある生成モデルの必要性
生成システムは、テキストプロンプトから画像やビデオを生成する能力が大きく進化しました。Stable Diffusionのようなツールは創造的な選択肢を広げました。しかし、大きな障害が残っています:一連のビジュアルの均一性を確保すること。例えば、キャラクターの外見、スタイル、本質をシーン間で維持することは困難です。
StoryDiffusionはここで一歩踏み出し、信頼性が高く印象的なストーリーラインを必要とするクリエイターに解決策を提供します。
StoryDiffusionは、画像シーケンス全体で安定したコンテンツの需要に応える新興の生成システムです。統一された、目を引くスタイルで画像やビデオを通じて物語を紡ぐクリエイターに可能性を提供します。この方法はまだ進化中ですが、生成された画像の忠実度を高め、顔や美学などの特性を保持し、ビデオや静止画で被写体と要素を整列させます。
一貫性自己注意:StoryDiffusionの核心
一貫性自己注意は、StoryDiffusionの中心的な技術要素を形成します。
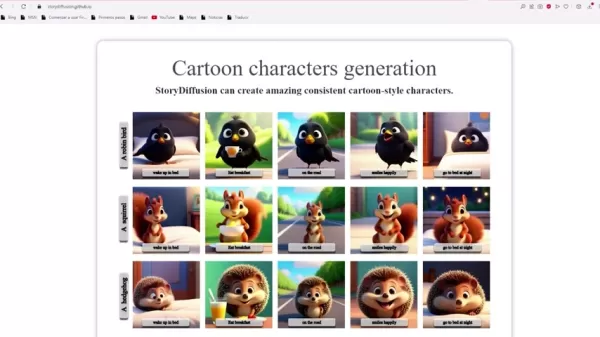
この機能は、グループ内の複数の画像をリンクし、被写体の一貫性を確保します。複数のキャラクターのアイデンティティを同時に維持し、画像チェーン内で安定したフィギュアを生成するのに役立ちます。これは複雑な被写体や細かい点で最も重要です。これがないと、視覚的な流れが断片化し、視聴者がストーリーを追うのが難しくなります。
複数キャラクターの生成
StoryDiffusionの、複数のキャラクターのアイデンティティを同時に維持し、画像セット全体で均一なフィギュアを作成するスキルは、ストーリーテラーにとって柔軟な資産となります。信頼性の高い自己注意で印象的な漫画やビデオセグメントを作成できます。
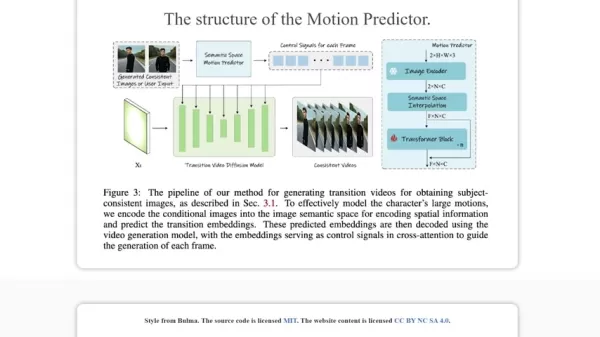
セマンティックモーションプレディクター:ビデオ移行の革命
研究によると、StoryDiffusionは、単なるビジュアルを超えた意味のある方法で画像間の要素の変化を予測するセマンティックモーションプレディクターを追加することで、ビデオ作成を進化させています。
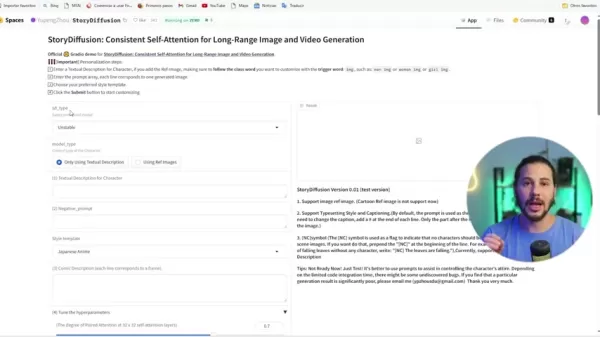
このブレークスルーはビデオ制作で輝きます。セマンティックモーションプレディクターは、フレーム間の要素の動きを意味的に予測し、流動的な変化と安定した被写体を持つビデオを生み出します。視覚的な滑らかさを超えて、物語の意図と感情的な響きを保護します。
StoryDiffusionの始め方
StoryDiffusionへのアクセス
StoryDiffusionはクリエイターが始めるための複数のパスを提供します:
- Hugging Face:Hugging Faceプラットフォームを通じてモデルにアクセスし、無料で簡単に利用できます。
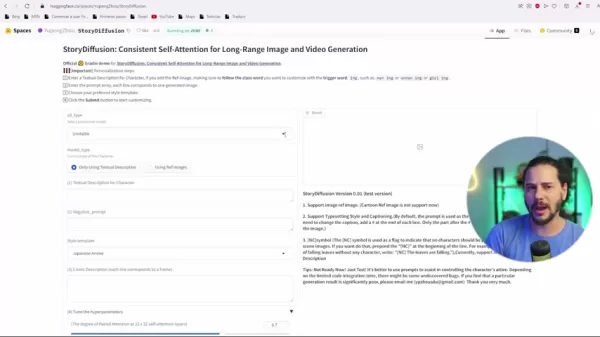
これは、ローカルセットアップの必要なく、StoryDiffusionの強みをテストし発見する確かな方法を提供します。
- ローカルインストール:デバイス上での実行を好むユーザーのために、StoryDiffusionはGitHubを介してインストールできます。これによりより多くの制御と調整が可能ですが、技術的な知識が必要です。
- Pinokio:このAIアプリプラットフォームはセットアップを可能にします。Stable Diffusionのバリエーションを含み、Pinokioを通じてStoryDiffusionをマシンに追加できます。
利用可能なモデル
StoryDiffusionは、RealVisionやUnstableなど、画像作業のためのさまざまなモデルを提供します。
StoryDiffusionは画像生成のための2つの主要なモデルを提供します:
- Stable:信頼性が高く均一な結果を提供し、視覚的な信頼性を優先する取り組みに適しています。
- RealVision:リアルな品質を高め、奥行きと表面の詳細に満ちた画像を作成します。
StoryDiffusionコミックを使用するための重要な要素
StoryDiffusionの操作には、ネガティブプロンプト、コミックの概要、スタイル、モデルに関する正確な入力が必要です。これらの選択は、AIがあなたのビジョンに合った画像をどの程度生成するかを形作ります。希望する美学を定義したり、特定の顔や特性を選んでカスタマイズされた結果を得ることができます。役立つヒントには以下が含まれます:
- 参照画像はスタイルの選択をガイドできます
- 特定の美学に調整されたモデルは、画像作成でより良い結果をもたらします
AIコミックを生成する簡単なステップ
初期設定
StoryDiffusionのインターフェースはシンプルさを優先します。始めるための簡潔なガイドは以下の通りです:
ステップ1:好みのモデルを選択:画像生成のための生成AIタイプを選ぶことから始めます
ステップ2:キャラクターのテキスト記述:このセクションでは、AIが作成すべき内容を入力します。意図した画像に適した用語でプロンプトを入力します。
コミックの設定
ステップ3:ネガティブプロンプト:望ましくない機能をブロックするために回避プロンプトを含めます
ステップ4:スタイルテンプレート:AIが画像構築に使用するスタイルガイドを定義します。
ステップ5:コミックの説明:設定したキャラクターのスタイルに合わせて、各パネルを個別のコミックフレームとして概要を説明します。
画像作成
ステップ6:ハイパーパラメータ:必要に応じて設定を調整します。不確かな場合はデフォルトを使用します
ステップ7:生成開始:生成ボタンを押して画像を作成し、コミックをアニメーション化します!
価格
無料かつオープンソース:コンテンツ作成のためのAIの民主化
StoryDiffusionの際立った特徴はそのアクセシビリティです。

無料のオープンソースオプションとして、AIベースの創作を多様なユーザーに開放します。これは、高額なサブスクリプションや使用ごとのコストを要求する独自のAIシステムとは大きく異なります。これらの障壁を取り除くことで、StoryDiffusionは個人アーティスト、小規模チーム、学校が視覚的な物語にAIを活用できるようにします。
StoryDiffusionの今後の道
利点
Pinokioを介したセットアップのオプション
リアルなビジュアルを向上
安定した信頼性のある結果を提供
オープンソースで無料で利用可能
欠点
現在ベータ版のため、問題が発生する可能性があります。
画像参照のサポートは現在利用できません。
技術スキルがない初心者には難しい
StoryDiffusionの主要な機能
主要な機能:創造的可能性の解放
漫画キャラクターの生成:鮮やかで均一な漫画フィギュアを作成できます。
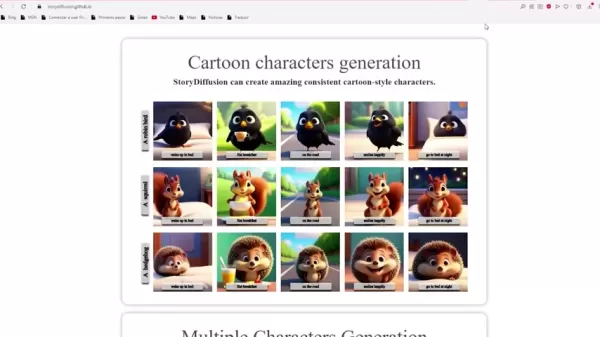
複数キャラクターの生成:複数のキャラクターのアイデンティティを同時に維持し、画像シーケンスで一貫したフィギュアを構築します。
長編ビデオ生成:セマンティックモーションプレディクターを使用して、生成された均一な画像またはユーザー提供の画像に基づいて高品質のビデオを作成します。
ユースケース
新しい創造的可能性の解放
StoryDiffusionの一貫性自己注意とモーション予測は、多くの創作コンテキストに適用されます:
- コミックとグラフィックノベル:セクション間でキャラクターの一貫性を維持し、魅力的な視覚的ストーリーを作成。
- アニメーション動画:視聴者の関心を維持するために流動的かつ意味のある移行を確保。
- 教育資料:授業や講演のための魅力的なビジュアルを一貫したキャラクターと設定で作成。
- マーケティングと広告:ブランドの存在感を高めるために、一貫した外観の目立つプロモーションコンテンツを構築。
FAQ
StoryDiffusionは本当に無料でオープンソースですか?
はい、StoryDiffusionは無料でオープンソースです。ユーザーは費用なしで自由に使用、変更、共有できます。MITライセンスの下にあります。
StoryDiffusionをローカルにインストールするために必要な技術的専門知識のレベルは?
Hugging Faceアクセスはセットアップをスキップしますが、GitHubのローカルインストールにはある程度のスキルが必要です。コマンド、Python、依存関係の知識が役立ちます。それでも、Pinokioはこれを容易にします。
関連する質問
StoryDiffusionは他の生成AIモデルとどう比較されますか?
StoryDiffusionは、画像チェーン全体で視覚的および意味的な統一性を保つことに優れており、他のモデルがしばしば遅れる領域です。一貫性自己注意は、キャラクターの作業や画像ベースの物語で優れた一貫性のある物語を促進します。セマンティックモーションプレディクターは、よりスムーズなビデオフローを確保し、単一の画像やビデオに焦点を当てたツールとは一線を画します。代替案は存在しますが、StoryDiffusionは注目すべきエキサイティングな進歩として浮上しています。
関連記事
 AI音楽ツール:約束、課題、そして実際のラップ実験
人工知能は、音楽を含むクリエイティブ産業を変革しています。高度なAIプラットフォームは、深い専門知識がなくても誰でも曲作りを可能にし、トラックの作成と改良を容易にします。この記事では、AI主導の音楽の強みと弱みを検証し、あるクリエイターがAIを使ってラップトラックを作成する過程とその結果を詳しく紹介します。障害、成功、そして音響制作におけるAIの進化する役割についても扱います。 主なポイントAI
Nvidiaの収益:輸出規制を超えて新しいハードウェア需要へ
Nvidiaは、4月27日終了の2026会計年度第1四半期の収益を水曜日の市場閉場後に発表します。米国のチップ輸出規制がNvidiaのグローバルチップ販売と将来の見通しに関する懸念を引き起こしていますが、一部の専門家は、これが同社の今後の結果の主要な焦点ではないと主張しています。Zacks Investment Researchのシニアエクイティストラテジストで、Nvidiaに関する10年の専門知
Chime AIスマートレコーダーのレビュー:現代のプロフェッショナルの効率を高める
急速に変化する現代の環境において、革新的なビジネスリーダーや経営者は、効率を向上させ、業務を洗練させるデバイスを常に求めています。Chime AIスマートレコーダーは、洗練されたAI駆動の音声キャプチャと文字起こしを提供する、変革的なソリューションとして際立っています。この最先端のツールが、録音やデータ活用の方法をどのように変えるかをご覧ください。主なポイントChime AIスマートレコーダーは、
コメント (0)
0/200
AI音楽ツール:約束、課題、そして実際のラップ実験
人工知能は、音楽を含むクリエイティブ産業を変革しています。高度なAIプラットフォームは、深い専門知識がなくても誰でも曲作りを可能にし、トラックの作成と改良を容易にします。この記事では、AI主導の音楽の強みと弱みを検証し、あるクリエイターがAIを使ってラップトラックを作成する過程とその結果を詳しく紹介します。障害、成功、そして音響制作におけるAIの進化する役割についても扱います。 主なポイントAI
Nvidiaの収益:輸出規制を超えて新しいハードウェア需要へ
Nvidiaは、4月27日終了の2026会計年度第1四半期の収益を水曜日の市場閉場後に発表します。米国のチップ輸出規制がNvidiaのグローバルチップ販売と将来の見通しに関する懸念を引き起こしていますが、一部の専門家は、これが同社の今後の結果の主要な焦点ではないと主張しています。Zacks Investment Researchのシニアエクイティストラテジストで、Nvidiaに関する10年の専門知
Chime AIスマートレコーダーのレビュー:現代のプロフェッショナルの効率を高める
急速に変化する現代の環境において、革新的なビジネスリーダーや経営者は、効率を向上させ、業務を洗練させるデバイスを常に求めています。Chime AIスマートレコーダーは、洗練されたAI駆動の音声キャプチャと文字起こしを提供する、変革的なソリューションとして際立っています。この最先端のツールが、録音やデータ活用の方法をどのように変えるかをご覧ください。主なポイントChime AIスマートレコーダーは、
コメント (0)
0/200
急速に変化する人工知能の世界で、StoryDiffusionはクリエイターにとって革新的なツールとして際立っています。この先進的なAIモデルは、生成技術の重要な課題である一連の画像とビデオの均一性を保つことに取り組んでいます。視覚的なストーリーテリングを変革し、クリエイターに比類のない監視と作品の一貫性を提供することを目指しています。視覚的および意味的に一貫した画像とビデオを生成するために構築されており、漫画、アニメーションストーリーなどに最適です。
主なポイント
StoryDiffusionは、均一な画像とビデオの出力に焦点を当てた新しい生成AIアプローチを表します。
視覚的な物語の一貫性を維持するという重要な課題に取り組んでいます。
このシステムは、視覚的および意味的な一貫性を保証する一貫性自己注意メカニズムを特徴としています。
StoryDiffusionは、シームレスなビデオ移行のためのセマンティックモーションプレディクターを導入しています。
漫画、アニメ、現実的な写真など、多様な芸術形式を扱います。
このツールは、Hugging Faceサイトを通じて、またはローカルセットアップで利用可能です。
StoryDiffusionの理解
一貫性のある生成モデルの必要性
生成システムは、テキストプロンプトから画像やビデオを生成する能力が大きく進化しました。Stable Diffusionのようなツールは創造的な選択肢を広げました。しかし、大きな障害が残っています:一連のビジュアルの均一性を確保すること。例えば、キャラクターの外見、スタイル、本質をシーン間で維持することは困難です。
StoryDiffusionはここで一歩踏み出し、信頼性が高く印象的なストーリーラインを必要とするクリエイターに解決策を提供します。
StoryDiffusionは、画像シーケンス全体で安定したコンテンツの需要に応える新興の生成システムです。統一された、目を引くスタイルで画像やビデオを通じて物語を紡ぐクリエイターに可能性を提供します。この方法はまだ進化中ですが、生成された画像の忠実度を高め、顔や美学などの特性を保持し、ビデオや静止画で被写体と要素を整列させます。
一貫性自己注意:StoryDiffusionの核心
一貫性自己注意は、StoryDiffusionの中心的な技術要素を形成します。
この機能は、グループ内の複数の画像をリンクし、被写体の一貫性を確保します。複数のキャラクターのアイデンティティを同時に維持し、画像チェーン内で安定したフィギュアを生成するのに役立ちます。これは複雑な被写体や細かい点で最も重要です。これがないと、視覚的な流れが断片化し、視聴者がストーリーを追うのが難しくなります。
複数キャラクターの生成
StoryDiffusionの、複数のキャラクターのアイデンティティを同時に維持し、画像セット全体で均一なフィギュアを作成するスキルは、ストーリーテラーにとって柔軟な資産となります。信頼性の高い自己注意で印象的な漫画やビデオセグメントを作成できます。
セマンティックモーションプレディクター:ビデオ移行の革命
研究によると、StoryDiffusionは、単なるビジュアルを超えた意味のある方法で画像間の要素の変化を予測するセマンティックモーションプレディクターを追加することで、ビデオ作成を進化させています。
このブレークスルーはビデオ制作で輝きます。セマンティックモーションプレディクターは、フレーム間の要素の動きを意味的に予測し、流動的な変化と安定した被写体を持つビデオを生み出します。視覚的な滑らかさを超えて、物語の意図と感情的な響きを保護します。
StoryDiffusionの始め方
StoryDiffusionへのアクセス
StoryDiffusionはクリエイターが始めるための複数のパスを提供します:
- Hugging Face:Hugging Faceプラットフォームを通じてモデルにアクセスし、無料で簡単に利用できます。
これは、ローカルセットアップの必要なく、StoryDiffusionの強みをテストし発見する確かな方法を提供します。
- ローカルインストール:デバイス上での実行を好むユーザーのために、StoryDiffusionはGitHubを介してインストールできます。これによりより多くの制御と調整が可能ですが、技術的な知識が必要です。
- Pinokio:このAIアプリプラットフォームはセットアップを可能にします。Stable Diffusionのバリエーションを含み、Pinokioを通じてStoryDiffusionをマシンに追加できます。
利用可能なモデル
StoryDiffusionは、RealVisionやUnstableなど、画像作業のためのさまざまなモデルを提供します。
StoryDiffusionは画像生成のための2つの主要なモデルを提供します:
- Stable:信頼性が高く均一な結果を提供し、視覚的な信頼性を優先する取り組みに適しています。
- RealVision:リアルな品質を高め、奥行きと表面の詳細に満ちた画像を作成します。
StoryDiffusionコミックを使用するための重要な要素
StoryDiffusionの操作には、ネガティブプロンプト、コミックの概要、スタイル、モデルに関する正確な入力が必要です。これらの選択は、AIがあなたのビジョンに合った画像をどの程度生成するかを形作ります。希望する美学を定義したり、特定の顔や特性を選んでカスタマイズされた結果を得ることができます。役立つヒントには以下が含まれます:
- 参照画像はスタイルの選択をガイドできます
- 特定の美学に調整されたモデルは、画像作成でより良い結果をもたらします
AIコミックを生成する簡単なステップ
初期設定
StoryDiffusionのインターフェースはシンプルさを優先します。始めるための簡潔なガイドは以下の通りです:
ステップ1:好みのモデルを選択:画像生成のための生成AIタイプを選ぶことから始めます
ステップ2:キャラクターのテキスト記述:このセクションでは、AIが作成すべき内容を入力します。意図した画像に適した用語でプロンプトを入力します。
コミックの設定
ステップ3:ネガティブプロンプト:望ましくない機能をブロックするために回避プロンプトを含めます
ステップ4:スタイルテンプレート:AIが画像構築に使用するスタイルガイドを定義します。
ステップ5:コミックの説明:設定したキャラクターのスタイルに合わせて、各パネルを個別のコミックフレームとして概要を説明します。
画像作成
ステップ6:ハイパーパラメータ:必要に応じて設定を調整します。不確かな場合はデフォルトを使用します
ステップ7:生成開始:生成ボタンを押して画像を作成し、コミックをアニメーション化します!
価格
無料かつオープンソース:コンテンツ作成のためのAIの民主化
StoryDiffusionの際立った特徴はそのアクセシビリティです。
無料のオープンソースオプションとして、AIベースの創作を多様なユーザーに開放します。これは、高額なサブスクリプションや使用ごとのコストを要求する独自のAIシステムとは大きく異なります。これらの障壁を取り除くことで、StoryDiffusionは個人アーティスト、小規模チーム、学校が視覚的な物語にAIを活用できるようにします。
StoryDiffusionの今後の道
利点
Pinokioを介したセットアップのオプション
リアルなビジュアルを向上
安定した信頼性のある結果を提供
オープンソースで無料で利用可能
欠点
現在ベータ版のため、問題が発生する可能性があります。
画像参照のサポートは現在利用できません。
技術スキルがない初心者には難しい
StoryDiffusionの主要な機能
主要な機能:創造的可能性の解放
漫画キャラクターの生成:鮮やかで均一な漫画フィギュアを作成できます。
複数キャラクターの生成:複数のキャラクターのアイデンティティを同時に維持し、画像シーケンスで一貫したフィギュアを構築します。
長編ビデオ生成:セマンティックモーションプレディクターを使用して、生成された均一な画像またはユーザー提供の画像に基づいて高品質のビデオを作成します。
ユースケース
新しい創造的可能性の解放
StoryDiffusionの一貫性自己注意とモーション予測は、多くの創作コンテキストに適用されます:
- コミックとグラフィックノベル:セクション間でキャラクターの一貫性を維持し、魅力的な視覚的ストーリーを作成。
- アニメーション動画:視聴者の関心を維持するために流動的かつ意味のある移行を確保。
- 教育資料:授業や講演のための魅力的なビジュアルを一貫したキャラクターと設定で作成。
- マーケティングと広告:ブランドの存在感を高めるために、一貫した外観の目立つプロモーションコンテンツを構築。
FAQ
StoryDiffusionは本当に無料でオープンソースですか?
はい、StoryDiffusionは無料でオープンソースです。ユーザーは費用なしで自由に使用、変更、共有できます。MITライセンスの下にあります。
StoryDiffusionをローカルにインストールするために必要な技術的専門知識のレベルは?
Hugging Faceアクセスはセットアップをスキップしますが、GitHubのローカルインストールにはある程度のスキルが必要です。コマンド、Python、依存関係の知識が役立ちます。それでも、Pinokioはこれを容易にします。
関連する質問
StoryDiffusionは他の生成AIモデルとどう比較されますか?
StoryDiffusionは、画像チェーン全体で視覚的および意味的な統一性を保つことに優れており、他のモデルがしばしば遅れる領域です。一貫性自己注意は、キャラクターの作業や画像ベースの物語で優れた一貫性のある物語を促進します。セマンティックモーションプレディクターは、よりスムーズなビデオフローを確保し、単一の画像やビデオに焦点を当てたツールとは一線を画します。代替案は存在しますが、StoryDiffusionは注目すべきエキサイティングな進歩として浮上しています。










 AI音楽ツール:約束、課題、そして実際のラップ実験
人工知能は、音楽を含むクリエイティブ産業を変革しています。高度なAIプラットフォームは、深い専門知識がなくても誰でも曲作りを可能にし、トラックの作成と改良を容易にします。この記事では、AI主導の音楽の強みと弱みを検証し、あるクリエイターがAIを使ってラップトラックを作成する過程とその結果を詳しく紹介します。障害、成功、そして音響制作におけるAIの進化する役割についても扱います。 主なポイントAI
AI音楽ツール:約束、課題、そして実際のラップ実験
人工知能は、音楽を含むクリエイティブ産業を変革しています。高度なAIプラットフォームは、深い専門知識がなくても誰でも曲作りを可能にし、トラックの作成と改良を容易にします。この記事では、AI主導の音楽の強みと弱みを検証し、あるクリエイターがAIを使ってラップトラックを作成する過程とその結果を詳しく紹介します。障害、成功、そして音響制作におけるAIの進化する役割についても扱います。 主なポイントAI
 Nvidiaの収益:輸出規制を超えて新しいハードウェア需要へ
Nvidiaは、4月27日終了の2026会計年度第1四半期の収益を水曜日の市場閉場後に発表します。米国のチップ輸出規制がNvidiaのグローバルチップ販売と将来の見通しに関する懸念を引き起こしていますが、一部の専門家は、これが同社の今後の結果の主要な焦点ではないと主張しています。Zacks Investment Researchのシニアエクイティストラテジストで、Nvidiaに関する10年の専門知
Nvidiaの収益:輸出規制を超えて新しいハードウェア需要へ
Nvidiaは、4月27日終了の2026会計年度第1四半期の収益を水曜日の市場閉場後に発表します。米国のチップ輸出規制がNvidiaのグローバルチップ販売と将来の見通しに関する懸念を引き起こしていますが、一部の専門家は、これが同社の今後の結果の主要な焦点ではないと主張しています。Zacks Investment Researchのシニアエクイティストラテジストで、Nvidiaに関する10年の専門知
 Chime AIスマートレコーダーのレビュー:現代のプロフェッショナルの効率を高める
急速に変化する現代の環境において、革新的なビジネスリーダーや経営者は、効率を向上させ、業務を洗練させるデバイスを常に求めています。Chime AIスマートレコーダーは、洗練されたAI駆動の音声キャプチャと文字起こしを提供する、変革的なソリューションとして際立っています。この最先端のツールが、録音やデータ活用の方法をどのように変えるかをご覧ください。主なポイントChime AIスマートレコーダーは、
Chime AIスマートレコーダーのレビュー:現代のプロフェッショナルの効率を高める
急速に変化する現代の環境において、革新的なビジネスリーダーや経営者は、効率を向上させ、業務を洗練させるデバイスを常に求めています。Chime AIスマートレコーダーは、洗練されたAI駆動の音声キャプチャと文字起こしを提供する、変革的なソリューションとして際立っています。この最先端のツールが、録音やデータ活用の方法をどのように変えるかをご覧ください。主なポイントChime AIスマートレコーダーは、













