
















 Home
HomeProcedural Memory Slashes AI Agent Costs and Complexity
A new technique developed by Zhejiang University and Alibaba Group equips large language model (LLM) agents with dynamic memory, boosting their efficiency and effectiveness in handling complex tasks. Named Memp, this approach provides agents with a "procedural memory" that updates continuously as they accumulate experience, mirroring the way humans learn through repeated practice.
Memp establishes a lifelong learning system where agents no longer need to begin from zero for each new task. As they face new scenarios in real-world environments, they steadily improve and become more efficient, a critical feature for dependable enterprise automation.
The importance of procedural memory in AI agents
LLM agents show great potential for automating intricate, multi-step business operations. However, in practice, these extended tasks can be prone to failure. The researchers highlight that unexpected issues—such as network interruptions, user interface updates, or changing data formats—can disrupt the entire workflow. Currently, this often forces agents to restart from the beginning each time, leading to delays and higher costs.
At the same time, many complex tasks, while appearing different on the surface, share underlying structural similarities. Rather than relearning these patterns every time, an agent should be capable of drawing from and reusing its past experiences—both successes and failures—as the researchers emphasize. This calls for a specialized "procedural memory," similar to human long-term memory for skills like typing or cycling, which become second nature with repetition.
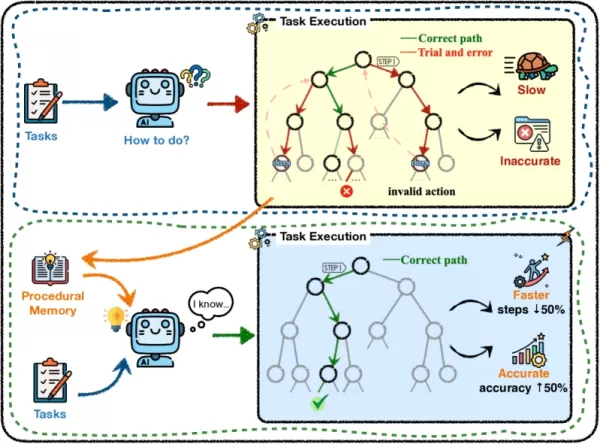
Starting from scratch (top) vs using procedural memory (bottom) (source: arXiv) Most current agent systems lack this functionality. Their procedural knowledge is usually manually programmed by developers, stored in inflexible prompt templates, or embedded in the model’s parameters, which are costly and slow to modify. Even existing frameworks with memory enhancements offer only broad abstractions and fail to properly address how skills should be developed, indexed, refined, and managed throughout an agent's lifecycle.
As the researchers state in their paper, "there is no principled way to quantify how efficiently an agent evolves its procedural repertoire or to guarantee that new experiences improve rather than erode performance."
How Memp works
Memp is a task-agnostic framework that treats procedural memory as a fundamental, optimizable component. It operates through three core stages that form a continuous cycle: building, retrieving, and updating memory.
Memories are constructed from an agent’s past experiences, or "trajectories." The team investigated storing these memories in two forms: either as exact, step-by-step actions, or by summarizing those actions into higher-level, script-like abstractions. For retrieval, when presented with a new task, the agent searches its memory for the most relevant prior experience. The researchers tested various methods, including vector search, to align the new task’s description with past queries, or extracting keywords to find the closest match.
The update mechanism is the most vital element. Memp incorporates several strategies to ensure the agent’s memory evolves. As an agent finishes more tasks, its memory can be updated by adding the new experience, filtering for only successful outcomes, or—most effectively—by analyzing failures to correct and improve the original memory.
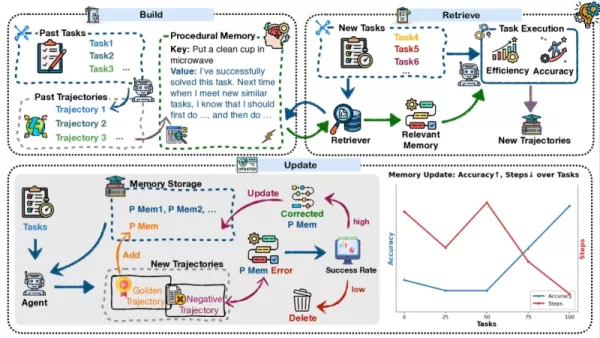
Memp framework (source: arXiv) This emphasis on dynamic, adaptable memory situates Memp within a growing research area focused on enhancing the reliability of AI agents for long-term assignments. The project aligns with other initiatives, such as Mem0, which extracts essential information from lengthy conversations and organizes it into structured facts and knowledge graphs to maintain consistency. Similarly, A-MEM allows agents to autonomously generate and connect "memory notes" from their interactions, building a sophisticated knowledge network over time.
Yet, co-author Runnan Fang points out a crucial difference between Memp and similar frameworks.
"Mem0 and A-MEM are excellent works… but they focus on remembering salient content within a single trajectory or conversation," Fang explained to VentureBeat. Essentially, they help an agent recall "what" occurred. "Memp, by contrast, targets cross-trajectory procedural memory." It concentrates on "how-to" knowledge that can be applied across comparable tasks, eliminating the need for the agent to repeatedly start from square one.
"By distilling past successful workflows into reusable procedural priors, Memp raises success rates and shortens steps," Fang continued. "Crucially, we also introduce an update mechanism so that this procedural memory keeps improving— after all, practice makes perfect for agents too."
Overcoming the cold-start challenge
While learning from past experiences is a powerful concept, it poses a practical challenge: How does an agent develop its initial memory when no flawless examples are available? The research team tackles this "cold-start" issue with a practical solution.
Fang described how developers can begin by defining a robust evaluation metric instead of needing a perfect "gold" trajectory from the start. This metric, which may be rule-based or powered by another LLM, rates the quality of an agent's performance. "Once that metric is in place, we let state-of-the-art models explore within the agent workflow and retain the trajectories that achieve the highest scores," Fang said. This method quickly assembles an initial collection of valuable memories, enabling a new agent to become proficient without extensive manual coding.
Memp in action
To evaluate the framework, the team integrated Memp with leading LLMs like GPT-4o, Claude 3.5 Sonnet, and Qwen2.5, testing them on demanding tasks such as household chores in the ALFWorld benchmark and information gathering in TravelPlanner. The outcomes revealed that by building and accessing procedural memory, an agent could effectively summarize and reuse its previous experience.
In testing, agents using Memp not only reached higher success rates but also operated far more efficiently. They cut out unproductive exploration and guesswork, significantly lowering both the number of steps and the token usage needed to finish a task.

Using procedural memory (right) enables agents to complete tasks with fewer steps and reduced token usage (source: arXiv) A particularly notable discovery for business use is that procedural memory can be transferred. In one test, procedural memory created by the high-powered GPT-4o was provided to a much smaller model, Qwen2.5-14B. The smaller model’s performance improved markedly, increasing its success rate and cutting down the steps required to accomplish tasks.
According to Fang, this is possible because smaller models typically handle straightforward, single-step actions competently but struggle with long-term planning and reasoning. The procedural memory from the larger model effectively bridges this gap. This implies that knowledge can be gathered using a top-tier model and then applied to smaller, more budget-friendly models without sacrificing the advantages of that learned experience.
Advancing toward fully autonomous agents
By integrating memory-update functions, the Memp framework enables agents to continually develop and polish their procedural knowledge as they work in live settings. The researchers observed that this gave the agent a "continual, almost linear mastery of the task."
Still, achieving complete autonomy faces another obstacle: numerous real-world tasks, like generating a research report, don't have a clear-cut success indicator. To keep improving, an agent must know whether its performance was satisfactory. Fang believes the solution lies ahead in employing LLMs as evaluators.
"Today we often combine powerful models with hand-crafted rules to compute completion scores," he observes. "This works, but hand-written rules are inflexible and difficult to generalize."
An LLM acting as a judge could offer the detailed, supervisory feedback necessary for an agent to self-correct on intricate, subjective assignments. This would make the overall learning process more scalable and resilient, representing a vital move toward creating the durable, flexible, and genuinely autonomous AI workers essential for advanced enterprise automation.
Related article
 Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
Related Special Topic Recommendations
Productivity
Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
Related Special Topic Recommendations
Productivity
 AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
 10 tools
10 tools
 xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai
Data Analysis
Best AI Data Visualization Tools: Auto-Generate Interactive BI Dashboards from Raw Files
Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

 Comments (2)
0/500
Comments (2)
0/500
![DonaldLee]()
Interesting approach! Giving LLMs a memory system could be a game-changer for automating complex workflows. I wonder how the cost savings compare to other optimization methods out there. The collaboration between academia and industry on this is promising. 🧠
![HarperJones]()
이 기술이 LLM 에이전트의 처리 효율을 높여줘서 정말 흥미롭네요! 하지만 실제 서비스에서 이렇게 동적 메모리가 잘 작동할까요? 복잡한 작업에서 성능이 안정적으로 유지되는지 궁금해요. 🤔 AI 비용 절감이 중요한 만큼 더 많은 연구가 필요해 보입니다.
A new technique developed by Zhejiang University and Alibaba Group equips large language model (LLM) agents with dynamic memory, boosting their efficiency and effectiveness in handling complex tasks. Named Memp, this approach provides agents with a "procedural memory" that updates continuously as they accumulate experience, mirroring the way humans learn through repeated practice.
Memp establishes a lifelong learning system where agents no longer need to begin from zero for each new task. As they face new scenarios in real-world environments, they steadily improve and become more efficient, a critical feature for dependable enterprise automation.
The importance of procedural memory in AI agents
LLM agents show great potential for automating intricate, multi-step business operations. However, in practice, these extended tasks can be prone to failure. The researchers highlight that unexpected issues—such as network interruptions, user interface updates, or changing data formats—can disrupt the entire workflow. Currently, this often forces agents to restart from the beginning each time, leading to delays and higher costs.
At the same time, many complex tasks, while appearing different on the surface, share underlying structural similarities. Rather than relearning these patterns every time, an agent should be capable of drawing from and reusing its past experiences—both successes and failures—as the researchers emphasize. This calls for a specialized "procedural memory," similar to human long-term memory for skills like typing or cycling, which become second nature with repetition.
Most current agent systems lack this functionality. Their procedural knowledge is usually manually programmed by developers, stored in inflexible prompt templates, or embedded in the model’s parameters, which are costly and slow to modify. Even existing frameworks with memory enhancements offer only broad abstractions and fail to properly address how skills should be developed, indexed, refined, and managed throughout an agent's lifecycle.
As the researchers state in their paper, "there is no principled way to quantify how efficiently an agent evolves its procedural repertoire or to guarantee that new experiences improve rather than erode performance."
How Memp works
Memp is a task-agnostic framework that treats procedural memory as a fundamental, optimizable component. It operates through three core stages that form a continuous cycle: building, retrieving, and updating memory.
Memories are constructed from an agent’s past experiences, or "trajectories." The team investigated storing these memories in two forms: either as exact, step-by-step actions, or by summarizing those actions into higher-level, script-like abstractions. For retrieval, when presented with a new task, the agent searches its memory for the most relevant prior experience. The researchers tested various methods, including vector search, to align the new task’s description with past queries, or extracting keywords to find the closest match.
The update mechanism is the most vital element. Memp incorporates several strategies to ensure the agent’s memory evolves. As an agent finishes more tasks, its memory can be updated by adding the new experience, filtering for only successful outcomes, or—most effectively—by analyzing failures to correct and improve the original memory.
This emphasis on dynamic, adaptable memory situates Memp within a growing research area focused on enhancing the reliability of AI agents for long-term assignments. The project aligns with other initiatives, such as Mem0, which extracts essential information from lengthy conversations and organizes it into structured facts and knowledge graphs to maintain consistency. Similarly, A-MEM allows agents to autonomously generate and connect "memory notes" from their interactions, building a sophisticated knowledge network over time.
Yet, co-author Runnan Fang points out a crucial difference between Memp and similar frameworks.
"Mem0 and A-MEM are excellent works… but they focus on remembering salient content within a single trajectory or conversation," Fang explained to VentureBeat. Essentially, they help an agent recall "what" occurred. "Memp, by contrast, targets cross-trajectory procedural memory." It concentrates on "how-to" knowledge that can be applied across comparable tasks, eliminating the need for the agent to repeatedly start from square one.
"By distilling past successful workflows into reusable procedural priors, Memp raises success rates and shortens steps," Fang continued. "Crucially, we also introduce an update mechanism so that this procedural memory keeps improving— after all, practice makes perfect for agents too."
Overcoming the cold-start challenge
While learning from past experiences is a powerful concept, it poses a practical challenge: How does an agent develop its initial memory when no flawless examples are available? The research team tackles this "cold-start" issue with a practical solution.
Fang described how developers can begin by defining a robust evaluation metric instead of needing a perfect "gold" trajectory from the start. This metric, which may be rule-based or powered by another LLM, rates the quality of an agent's performance. "Once that metric is in place, we let state-of-the-art models explore within the agent workflow and retain the trajectories that achieve the highest scores," Fang said. This method quickly assembles an initial collection of valuable memories, enabling a new agent to become proficient without extensive manual coding.
Memp in action
To evaluate the framework, the team integrated Memp with leading LLMs like GPT-4o, Claude 3.5 Sonnet, and Qwen2.5, testing them on demanding tasks such as household chores in the ALFWorld benchmark and information gathering in TravelPlanner. The outcomes revealed that by building and accessing procedural memory, an agent could effectively summarize and reuse its previous experience.
In testing, agents using Memp not only reached higher success rates but also operated far more efficiently. They cut out unproductive exploration and guesswork, significantly lowering both the number of steps and the token usage needed to finish a task.
A particularly notable discovery for business use is that procedural memory can be transferred. In one test, procedural memory created by the high-powered GPT-4o was provided to a much smaller model, Qwen2.5-14B. The smaller model’s performance improved markedly, increasing its success rate and cutting down the steps required to accomplish tasks.
According to Fang, this is possible because smaller models typically handle straightforward, single-step actions competently but struggle with long-term planning and reasoning. The procedural memory from the larger model effectively bridges this gap. This implies that knowledge can be gathered using a top-tier model and then applied to smaller, more budget-friendly models without sacrificing the advantages of that learned experience.
Advancing toward fully autonomous agents
By integrating memory-update functions, the Memp framework enables agents to continually develop and polish their procedural knowledge as they work in live settings. The researchers observed that this gave the agent a "continual, almost linear mastery of the task."
Still, achieving complete autonomy faces another obstacle: numerous real-world tasks, like generating a research report, don't have a clear-cut success indicator. To keep improving, an agent must know whether its performance was satisfactory. Fang believes the solution lies ahead in employing LLMs as evaluators.
"Today we often combine powerful models with hand-crafted rules to compute completion scores," he observes. "This works, but hand-written rules are inflexible and difficult to generalize."
An LLM acting as a judge could offer the detailed, supervisory feedback necessary for an agent to self-correct on intricate, subjective assignments. This would make the overall learning process more scalable and resilient, representing a vital move toward creating the durable, flexible, and genuinely autonomous AI workers essential for advanced enterprise automation.










 Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
 Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
 AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

Interesting approach! Giving LLMs a memory system could be a game-changer for automating complex workflows. I wonder how the cost savings compare to other optimization methods out there. The collaboration between academia and industry on this is promising. 🧠
이 기술이 LLM 에이전트의 처리 효율을 높여줘서 정말 흥미롭네요! 하지만 실제 서비스에서 이렇게 동적 메모리가 잘 작동할까요? 복잡한 작업에서 성능이 안정적으로 유지되는지 궁금해요. 🤔 AI 비용 절감이 중요한 만큼 더 많은 연구가 필요해 보입니다.













