
















 Home
HomeCohere Unveils Top-Rated Aya Vision AI Model
Cohere's nonprofit research lab just dropped a new multimodal AI model called Aya Vision, and they're calling it the best in its class. This model is pretty slick—it can whip up image captions, answer questions about pictures, translate text, and even summarize stuff in 23 major languages. Plus, Cohere's making Aya Vision available for free on WhatsApp, saying it's a big move towards getting these tech breakthroughs into the hands of researchers everywhere.
In their blog post, Cohere pointed out that while AI's been making strides, there's still a huge gap in how well models handle different languages, especially when you throw in both text and images. That's where Aya Vision steps in, aiming to bridge that gap.
Aya Vision comes in two versions: the beefier Aya Vision 32B and the lighter Aya Vision 8B. The 32B version, according to Cohere, is setting a "new frontier," outdoing models twice its size, like Meta's Llama-3.2 90B Vision, in some visual understanding tests. And the 8B version? It's holding its own against models that are 10 times bigger.
You can grab both models from Hugging Face under a Creative Commons 4.0 license, but there's a catch—they're not for commercial use.
Cohere trained Aya Vision using a mix of English datasets, which they translated and turned into synthetic annotations. These annotations, or tags, help the model make sense of the data during training. For instance, if you're training an image recognition model, you might use annotations to mark objects or add captions about what's in the picture.
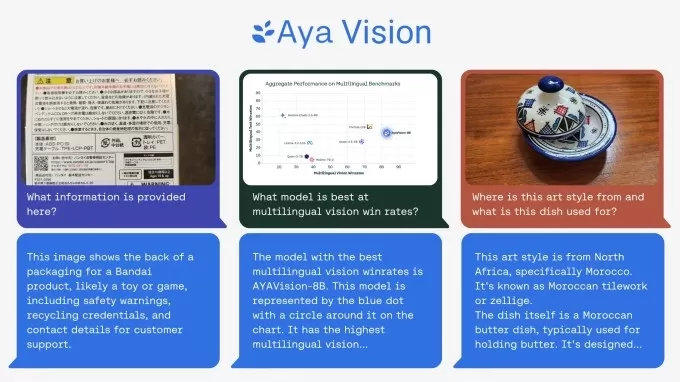
Cohere’s Aya Vision model can perform a range of visual understanding tasks.Image Credits:Cohere Using synthetic annotations is all the rage right now, even if it has its drawbacks. Big players like OpenAI are jumping on the synthetic data bandwagon as real-world data gets harder to come by. Gartner reckons that last year, 60% of the data used for AI and analytics projects was synthetic.
Cohere says that training Aya Vision on synthetic annotations let them use fewer resources while still getting top-notch results. It's all about efficiency and doing more with less, they say, which is great news for researchers who don't always have access to big compute resources.
Alongside Aya Vision, Cohere released a new benchmark suite called AyaVisionBench. It's designed to test a model's skills in tasks like spotting differences between images and turning screenshots into code.
The AI world's been struggling with what some folks call an "evaluation crisis." The usual benchmarks give you an overall score that doesn't really reflect how well a model does on the tasks that matter to most users. Cohere thinks AyaVisionBench can help fix that, offering a tough and broad way to check a model's cross-lingual and multimodal chops.
Here's hoping they're right. Cohere's researchers say the dataset is a solid benchmark for testing vision-language models in multilingual and real-world scenarios. They've made it available to the research community to help push forward multilingual multimodal evaluations.
Related article
 Cohere Unveils Open-Source Multilingual AI Model Family
Enterprise AI firm Cohere has unveiled a new family of multilingual models, named Tiny Aya, during the ongoing India AI Summit. These open-weight models—meaning their core code is publicly accessible for use and modification—support over 70 languages
Cohere and Aleph Alpha Announce Merger
Canadian AI startup Cohere is acquiring Germany's Aleph Alpha with backing from the Schwarz Group, the parent company of grocery chain Lidl. With government support, the companies aim to provide a sovereign alternative for enterprises within an AI se
Cohere Launches Secure Enterprise AI Platform North
AI agent tools hold the potential to reduce repetitive tasks in daily workflows, yet many organizations remain cautious about adoption. A primary concern is data security. Large enterprises with proprietary secrets, firms in heavily regulated sectors
Related Special Topic Recommendations
code
Cohere Unveils Open-Source Multilingual AI Model Family
Enterprise AI firm Cohere has unveiled a new family of multilingual models, named Tiny Aya, during the ongoing India AI Summit. These open-weight models—meaning their core code is publicly accessible for use and modification—support over 70 languages
Cohere and Aleph Alpha Announce Merger
Canadian AI startup Cohere is acquiring Germany's Aleph Alpha with backing from the Schwarz Group, the parent company of grocery chain Lidl. With government support, the companies aim to provide a sovereign alternative for enterprises within an AI se
Cohere Launches Secure Enterprise AI Platform North
AI agent tools hold the potential to reduce repetitive tasks in daily workflows, yet many organizations remain cautious about adoption. A primary concern is data security. Large enterprises with proprietary secrets, firms in heavily regulated sectors
Related Special Topic Recommendations
code
 Best AI Code Reviewers: Automate Clean Code Compliance & Refactor Legacy Repo Files
Best AI Code Reviewers: Automate Clean Code Compliance & Refactor Legacy Repo Files
Discover the 2026 best AI code reviewers on XIX.AI. Our curated list features top-rated, game-changing tools for automating clean code compliance and refactoring legacy repo files. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI edge today.
 10 tools
10 tools
 xix.ai
Text-to-speech
Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
xix.ai
Text-to-speech
Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

 Comments (46)
0/500
Comments (46)
0/500
![EricJohnson]()
このモデルは23言語に対応しているって、すごいね!でも、実際に使ってみないと本当の性能はわからないかも。Cohereは競合他社と比べてどうなんだろう?🤔
![JasonAnderson]()
Aya Vision klingt beeindruckend! Besonders die 23 Sprachen sind praktisch. Hoffentlich bleibt die Übersetzungsqualität auch bei komplexen Themen konsistent. 🤔 Würde mich interessieren, wie es sich im Alltag gegen GPT-4 behauptet.
![JoseAdams]()
Incroyable modèle de Cohere ! Mais est-ce que cette IA 'top-rated' tiendra ses promesses face à GPT-4 ? 🤔 Les fonctionnalités multilingues sont impressionnantes, mais j'aimerais voir plus de démos concrètes.
![MarkRoberts]()
¡Interesante! Aya Vision parece ser un modelo bastante completo con esas capacidades multilingües. Me pregunto qué tan bien funcionará en idiomas menos comunes, sobre todo porque menciona '23 grandes idiomas'. ¿Habrá algún soporte para lenguas indígenas o regionales en el futuro? 🌎
![KennethMartin]()
This Aya Vision model sounds like a game-changer! Captioning images and translating in 23 languages? That’s some next-level tech. Can’t wait to see how it stacks up against the big players like OpenAI. 😎
![PaulKing]()
This Aya Vision model sounds like a game-changer! Being able to handle images and 23 languages is wild—imagine using it to instantly caption my travel photos or summarize foreign articles. Curious how it stacks up against other AI models in real-world tasks. 😎
Cohere's nonprofit research lab just dropped a new multimodal AI model called Aya Vision, and they're calling it the best in its class. This model is pretty slick—it can whip up image captions, answer questions about pictures, translate text, and even summarize stuff in 23 major languages. Plus, Cohere's making Aya Vision available for free on WhatsApp, saying it's a big move towards getting these tech breakthroughs into the hands of researchers everywhere.
In their blog post, Cohere pointed out that while AI's been making strides, there's still a huge gap in how well models handle different languages, especially when you throw in both text and images. That's where Aya Vision steps in, aiming to bridge that gap.
Aya Vision comes in two versions: the beefier Aya Vision 32B and the lighter Aya Vision 8B. The 32B version, according to Cohere, is setting a "new frontier," outdoing models twice its size, like Meta's Llama-3.2 90B Vision, in some visual understanding tests. And the 8B version? It's holding its own against models that are 10 times bigger.
You can grab both models from Hugging Face under a Creative Commons 4.0 license, but there's a catch—they're not for commercial use.
Cohere trained Aya Vision using a mix of English datasets, which they translated and turned into synthetic annotations. These annotations, or tags, help the model make sense of the data during training. For instance, if you're training an image recognition model, you might use annotations to mark objects or add captions about what's in the picture.
Cohere says that training Aya Vision on synthetic annotations let them use fewer resources while still getting top-notch results. It's all about efficiency and doing more with less, they say, which is great news for researchers who don't always have access to big compute resources.
Alongside Aya Vision, Cohere released a new benchmark suite called AyaVisionBench. It's designed to test a model's skills in tasks like spotting differences between images and turning screenshots into code.
The AI world's been struggling with what some folks call an "evaluation crisis." The usual benchmarks give you an overall score that doesn't really reflect how well a model does on the tasks that matter to most users. Cohere thinks AyaVisionBench can help fix that, offering a tough and broad way to check a model's cross-lingual and multimodal chops.
Here's hoping they're right. Cohere's researchers say the dataset is a solid benchmark for testing vision-language models in multilingual and real-world scenarios. They've made it available to the research community to help push forward multilingual multimodal evaluations.










 Cohere Unveils Open-Source Multilingual AI Model Family
Enterprise AI firm Cohere has unveiled a new family of multilingual models, named Tiny Aya, during the ongoing India AI Summit. These open-weight models—meaning their core code is publicly accessible for use and modification—support over 70 languages
Cohere Unveils Open-Source Multilingual AI Model Family
Enterprise AI firm Cohere has unveiled a new family of multilingual models, named Tiny Aya, during the ongoing India AI Summit. These open-weight models—meaning their core code is publicly accessible for use and modification—support over 70 languages
 Cohere and Aleph Alpha Announce Merger
Canadian AI startup Cohere is acquiring Germany's Aleph Alpha with backing from the Schwarz Group, the parent company of grocery chain Lidl. With government support, the companies aim to provide a sovereign alternative for enterprises within an AI se
Cohere and Aleph Alpha Announce Merger
Canadian AI startup Cohere is acquiring Germany's Aleph Alpha with backing from the Schwarz Group, the parent company of grocery chain Lidl. With government support, the companies aim to provide a sovereign alternative for enterprises within an AI se
 Cohere Launches Secure Enterprise AI Platform North
AI agent tools hold the potential to reduce repetitive tasks in daily workflows, yet many organizations remain cautious about adoption. A primary concern is data security. Large enterprises with proprietary secrets, firms in heavily regulated sectors
Cohere Launches Secure Enterprise AI Platform North
AI agent tools hold the potential to reduce repetitive tasks in daily workflows, yet many organizations remain cautious about adoption. A primary concern is data security. Large enterprises with proprietary secrets, firms in heavily regulated sectors

Discover the 2026 best AI code reviewers on XIX.AI. Our curated list features top-rated, game-changing tools for automating clean code compliance and refactoring legacy repo files. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

このモデルは23言語に対応しているって、すごいね!でも、実際に使ってみないと本当の性能はわからないかも。Cohereは競合他社と比べてどうなんだろう?🤔
Aya Vision klingt beeindruckend! Besonders die 23 Sprachen sind praktisch. Hoffentlich bleibt die Übersetzungsqualität auch bei komplexen Themen konsistent. 🤔 Würde mich interessieren, wie es sich im Alltag gegen GPT-4 behauptet.
Incroyable modèle de Cohere ! Mais est-ce que cette IA 'top-rated' tiendra ses promesses face à GPT-4 ? 🤔 Les fonctionnalités multilingues sont impressionnantes, mais j'aimerais voir plus de démos concrètes.
¡Interesante! Aya Vision parece ser un modelo bastante completo con esas capacidades multilingües. Me pregunto qué tan bien funcionará en idiomas menos comunes, sobre todo porque menciona '23 grandes idiomas'. ¿Habrá algún soporte para lenguas indígenas o regionales en el futuro? 🌎
This Aya Vision model sounds like a game-changer! Captioning images and translating in 23 languages? That’s some next-level tech. Can’t wait to see how it stacks up against the big players like OpenAI. 😎
This Aya Vision model sounds like a game-changer! Being able to handle images and 23 languages is wild—imagine using it to instantly caption my travel photos or summarize foreign articles. Curious how it stacks up against other AI models in real-world tasks. 😎













