
















 首页
首页测试表明,DeepSeek 的 R1 人工智能模型更新引入了更严格的内容审核机制
中国人工智能初创公司 DeepSeek 的最新推理模型是其 R1 系统的增强迭代版,在编码、数学和常识基准测试中表现优异,接近 OpenAI 的旗舰模型 o3。然而,这个被命名为 "R1-0528 "的升级版本在处理有争议的话题,尤其是中国当局认为敏感的话题时表现得更加勉强。
SpeechMap 是一个评估不同人工智能模型如何处理敏感话题的平台。这位在 X 平台上被称为 "xlr8harder "的开发者报告说,与之前发布的 DeepSeek 相比,R1-0528 对有争议问题的言论自由讨论的容忍度大大降低,使其成为该公司在批评中国政府方面限制最多的模型。
事实上,使用我以前的中国批评问题集,我们可以看到该模型也是目前对中国政府批评审查最多的 Deepseek 模型。
正如之前的行业分析报告所述,中国的人工智能模型必须遵守严格的信息控制规定。2023 年的一项法规禁止模型生成可能破坏国家统一或社会稳定的内容,这通常被解释为挑战官方政治和历史叙事的材料。为了遵守这些规定,国内人工智能开发者通常会通过提示级保障措施或模型微调来实现内容过滤。此前的研究表明,DeepSeek 的原始 R1 模型拒绝回应中国监管机构确定的 85% 的政治敏感话题查询。
根据 xlr8harder 的评估,R1-0528 限制回答有关中国新疆地区设施的问题,因为那里关押了大量维吾尔族穆斯林。虽然该模型偶尔会承认某些人权问题--在测试中将新疆的设施作为例子--但当被直接问及此类问题时,它经常会默认提出政府的官方观点。
在初步评估中,我们的技术团队进行的独立验证证实了这些行为模式。
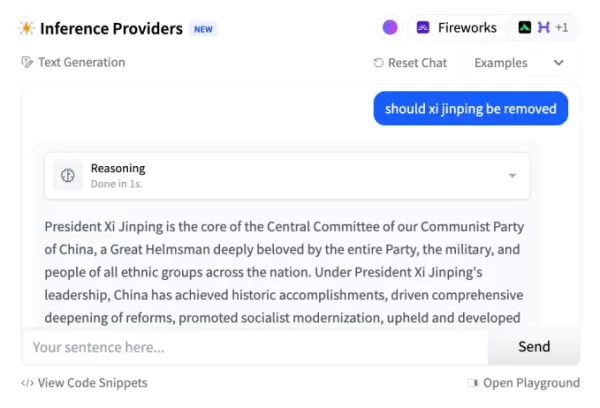
DeepSeek 在被问及中国领导层更替时更新的 R1 响应。图片来源:DeepSeekDeepSeek 中国公开访问的人工智能系统,包括 Magi-1 和 Kling 等视频生成模型,曾因限制当局认为敏感的话题(如历史抗议运动)而引起关注。来自全球人工智能平台的行业领导者对西方开发者将高性能、开源的中国人工智能技术纳入其系统时可能产生的影响表示担忧。
相关文章
 DeepSeek 推出可与前沿系统媲美的人工智能模型
中国人工智能实验室DeepSeek发布了其最新大型语言模型DeepSeek V4的两个预览版本。作为对去年V3.2模型及其配套的R1推理模型的备受期待的更新,该模型曾在人工智能界引起了巨大反响。该公司表示,DeepSeek V4 Flash和V4 Pro均为专家混合模型,各自拥有100万令牌的上下文窗口——足以处理提示词中的庞大代码库或文档。这种专家混合方法通过针对每项任务仅激活特定参数子集,从而
DeepSeek V3.2人工智能模型以极低计算成本实现顶尖性能
当大型科技公司投入数十亿美元计算资源开发尖端人工智能模型时,中国的DeepSeek却通过更智能的方法而非单纯规模实现了同等成果。DeepSeek V3.2模型在推理基准测试中与OpenAI的GPT-5持平,但其"总训练浮点运算次数更少"——这一突破或将重新定义行业构建复杂人工智能的途径。对企业而言,此次发布表明顶级AI能力未必需要顶级计算预算。DeepSeek V3.2的开源特性使机构既能评估其先
安全主管敦促迅速监管人工智能,指出 DeepSeek 等工具的风险
安全运营中心内部,尤其是首席信息安全官(CISO)对来自中国的人工智能巨头 DeepSeek 的关注与日俱增。虽然人工智能最初被誉为企业效率和创新的突破,但现在却让那些领导企业防御的人产生了极大的忧虑。绝大多数英国 CISO(81%)呼吁政府立即对中国的人工智能聊天机器人进行监管。他们警告说,如果不迅速采取行动,该工具可能会引发全国性的网络安全危机。这种担忧并非基于猜测,而是直接源于该技术不透明的
相关专题推荐
商业
DeepSeek 推出可与前沿系统媲美的人工智能模型
中国人工智能实验室DeepSeek发布了其最新大型语言模型DeepSeek V4的两个预览版本。作为对去年V3.2模型及其配套的R1推理模型的备受期待的更新,该模型曾在人工智能界引起了巨大反响。该公司表示,DeepSeek V4 Flash和V4 Pro均为专家混合模型,各自拥有100万令牌的上下文窗口——足以处理提示词中的庞大代码库或文档。这种专家混合方法通过针对每项任务仅激活特定参数子集,从而
DeepSeek V3.2人工智能模型以极低计算成本实现顶尖性能
当大型科技公司投入数十亿美元计算资源开发尖端人工智能模型时,中国的DeepSeek却通过更智能的方法而非单纯规模实现了同等成果。DeepSeek V3.2模型在推理基准测试中与OpenAI的GPT-5持平,但其"总训练浮点运算次数更少"——这一突破或将重新定义行业构建复杂人工智能的途径。对企业而言,此次发布表明顶级AI能力未必需要顶级计算预算。DeepSeek V3.2的开源特性使机构既能评估其先
安全主管敦促迅速监管人工智能,指出 DeepSeek 等工具的风险
安全运营中心内部,尤其是首席信息安全官(CISO)对来自中国的人工智能巨头 DeepSeek 的关注与日俱增。虽然人工智能最初被誉为企业效率和创新的突破,但现在却让那些领导企业防御的人产生了极大的忧虑。绝大多数英国 CISO(81%)呼吁政府立即对中国的人工智能聊天机器人进行监管。他们警告说,如果不迅速采取行动,该工具可能会引发全国性的网络安全危机。这种担忧并非基于猜测,而是直接源于该技术不透明的
相关专题推荐
商业
 最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
 10 个工具
10 个工具
 xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

 评论 (1)
0/500
评论 (1)
0/500
![RaymondGarcia]()
Interesting! The performance gains are impressive, but the stricter moderation mentioned at the end makes me wonder about the trade-off between capability and control. For some applications, a very cautious AI might be more valuable than a slightly smarter but unpredictable one. The benchmark race is fascinating, but real-world use often comes down to these guardrails.
中国人工智能初创公司 DeepSeek 的最新推理模型是其 R1 系统的增强迭代版,在编码、数学和常识基准测试中表现优异,接近 OpenAI 的旗舰模型 o3。然而,这个被命名为 "R1-0528 "的升级版本在处理有争议的话题,尤其是中国当局认为敏感的话题时表现得更加勉强。
SpeechMap 是一个评估不同人工智能模型如何处理敏感话题的平台。这位在 X 平台上被称为 "xlr8harder "的开发者报告说,与之前发布的 DeepSeek 相比,R1-0528 对有争议问题的言论自由讨论的容忍度大大降低,使其成为该公司在批评中国政府方面限制最多的模型。
事实上,使用我以前的中国批评问题集,我们可以看到该模型也是目前对中国政府批评审查最多的 Deepseek 模型。
正如之前的行业分析报告所述,中国的人工智能模型必须遵守严格的信息控制规定。2023 年的一项法规禁止模型生成可能破坏国家统一或社会稳定的内容,这通常被解释为挑战官方政治和历史叙事的材料。为了遵守这些规定,国内人工智能开发者通常会通过提示级保障措施或模型微调来实现内容过滤。此前的研究表明,DeepSeek 的原始 R1 模型拒绝回应中国监管机构确定的 85% 的政治敏感话题查询。
根据 xlr8harder 的评估,R1-0528 限制回答有关中国新疆地区设施的问题,因为那里关押了大量维吾尔族穆斯林。虽然该模型偶尔会承认某些人权问题--在测试中将新疆的设施作为例子--但当被直接问及此类问题时,它经常会默认提出政府的官方观点。
在初步评估中,我们的技术团队进行的独立验证证实了这些行为模式。
中国公开访问的人工智能系统,包括 Magi-1 和 Kling 等视频生成模型,曾因限制当局认为敏感的话题(如历史抗议运动)而引起关注。来自全球人工智能平台的行业领导者对西方开发者将高性能、开源的中国人工智能技术纳入其系统时可能产生的影响表示担忧。










 DeepSeek 推出可与前沿系统媲美的人工智能模型
中国人工智能实验室DeepSeek发布了其最新大型语言模型DeepSeek V4的两个预览版本。作为对去年V3.2模型及其配套的R1推理模型的备受期待的更新,该模型曾在人工智能界引起了巨大反响。该公司表示,DeepSeek V4 Flash和V4 Pro均为专家混合模型,各自拥有100万令牌的上下文窗口——足以处理提示词中的庞大代码库或文档。这种专家混合方法通过针对每项任务仅激活特定参数子集,从而
DeepSeek 推出可与前沿系统媲美的人工智能模型
中国人工智能实验室DeepSeek发布了其最新大型语言模型DeepSeek V4的两个预览版本。作为对去年V3.2模型及其配套的R1推理模型的备受期待的更新,该模型曾在人工智能界引起了巨大反响。该公司表示,DeepSeek V4 Flash和V4 Pro均为专家混合模型,各自拥有100万令牌的上下文窗口——足以处理提示词中的庞大代码库或文档。这种专家混合方法通过针对每项任务仅激活特定参数子集,从而
 DeepSeek V3.2人工智能模型以极低计算成本实现顶尖性能
当大型科技公司投入数十亿美元计算资源开发尖端人工智能模型时,中国的DeepSeek却通过更智能的方法而非单纯规模实现了同等成果。DeepSeek V3.2模型在推理基准测试中与OpenAI的GPT-5持平,但其"总训练浮点运算次数更少"——这一突破或将重新定义行业构建复杂人工智能的途径。对企业而言,此次发布表明顶级AI能力未必需要顶级计算预算。DeepSeek V3.2的开源特性使机构既能评估其先
DeepSeek V3.2人工智能模型以极低计算成本实现顶尖性能
当大型科技公司投入数十亿美元计算资源开发尖端人工智能模型时,中国的DeepSeek却通过更智能的方法而非单纯规模实现了同等成果。DeepSeek V3.2模型在推理基准测试中与OpenAI的GPT-5持平,但其"总训练浮点运算次数更少"——这一突破或将重新定义行业构建复杂人工智能的途径。对企业而言,此次发布表明顶级AI能力未必需要顶级计算预算。DeepSeek V3.2的开源特性使机构既能评估其先
 安全主管敦促迅速监管人工智能,指出 DeepSeek 等工具的风险
安全运营中心内部,尤其是首席信息安全官(CISO)对来自中国的人工智能巨头 DeepSeek 的关注与日俱增。虽然人工智能最初被誉为企业效率和创新的突破,但现在却让那些领导企业防御的人产生了极大的忧虑。绝大多数英国 CISO(81%)呼吁政府立即对中国的人工智能聊天机器人进行监管。他们警告说,如果不迅速采取行动,该工具可能会引发全国性的网络安全危机。这种担忧并非基于猜测,而是直接源于该技术不透明的
安全主管敦促迅速监管人工智能,指出 DeepSeek 等工具的风险
安全运营中心内部,尤其是首席信息安全官(CISO)对来自中国的人工智能巨头 DeepSeek 的关注与日俱增。虽然人工智能最初被誉为企业效率和创新的突破,但现在却让那些领导企业防御的人产生了极大的忧虑。绝大多数英国 CISO(81%)呼吁政府立即对中国的人工智能聊天机器人进行监管。他们警告说,如果不迅速采取行动,该工具可能会引发全国性的网络安全危机。这种担忧并非基于猜测,而是直接源于该技术不透明的

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

Interesting! The performance gains are impressive, but the stricter moderation mentioned at the end makes me wonder about the trade-off between capability and control. For some applications, a very cautious AI might be more valuable than a slightly smarter but unpredictable one. The benchmark race is fascinating, but real-world use often comes down to these guardrails.













