
















 首頁
首頁Langchain 教程:總結 YouTube 影片指南
在我們這個快節奏的數位世界中,能夠快速瞭解影片的核心訊息是非常有價值的。對於研究人員、學生和專業人士來說,為冗長的 YouTube 影片製作簡潔的摘要,可以大大節省時間,提高工作效率。本指南提供了一個清晰、循序漸進的方法,讓您可以使用 Langchain、OpenAI 和 Whisper 自動建立 YouTube 內容的摘要。您將學會如何在 Google Colab 中撰寫 Python 腳本來擷取音訊、將音訊轉錄成文字,然後再使用強大的 AI 模型進行濃縮。
重點
學習使用 Langchain、OpenAI 和 Whisper 進行自動視訊摘要。
在 Google Colab 中編寫 Python 程式碼來下載和轉錄視訊音訊。
應用文字分割與摘要方法,建立簡潔的概述。
實作 map reduce chain 技術,以有效率地總結大文件。
利用 OpenAI API 存取進階摘要模型。
使用 RecursiveCharacterTextSplitter 將文字分割成較小的、可管理的片段。
設定視訊摘要的環境
開始使用 Google Colab
首先,請確定您有 Google 帳戶以存取 Google Colab,這是一個免費的雲端平台,非常適合執行 Python 程式碼。開啟 Google Colab 並建立一個新的筆記本。這將會是您視訊摘要專案的工作區。將筆記本重新命名為易記的名稱,例如「YouTube_Summarizer」,以協助您保持井井有條。
接下來,調整執行時設定。
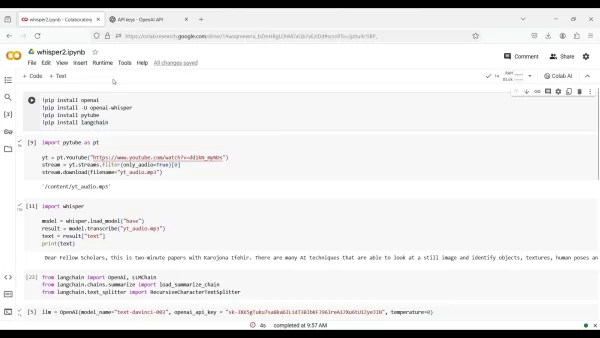
進入「Runtime」功能表,選擇「Change runtime type」。從下拉式選單中,選擇「T4 GPU」作為硬體加速器。此選擇會使用 GPU 的處理能力來加速您的程式碼執行。儲存設定以套用至 Colab 環境。現在,您已準備好安裝必要的套件。
安裝必要的 Python 套件
在撰寫程式碼之前,您必須先安裝所需的 Python 函式庫。這些套件提供了音訊擷取、轉錄和摘要的工具。在 Colab 單元中使用pip install 執行下列指令:
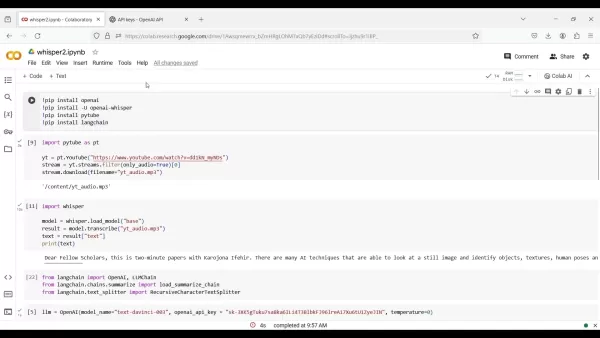
!pip install OpenAI!pip install -U openai-whisper!pip install pytube!pip install langchain
- OpenAI:此函式庫可與 OpenAI 的語言模型互動,這對於文字摘要非常重要。
- Whisper:OpenAI 的自動語音辨識 (ASR) 系統,用來將音訊轉換成文字。
- Pytube:直接從 YouTube 影片下載音訊的函式庫。
- Langchain:一個功能強大的框架,提供鏈和其他工具的標準介面,簡化使用語言模型建立應用程式的流程。
這些指令將安裝 OpenAI、Whisper、Pytube 和 Langchain 函式庫,為您提供下一步所需的所有工具。安裝完成後,您就可以將這些套件匯入腳本中。
從 YouTube 影片擷取音訊
匯入 Pytube 並載入影片
首先匯入pytube函式庫,它可以讓您從 YouTube 下載音訊。匯入後,指定您要處理的 YouTube 影片的 URL。

以下程式碼顯示如何執行:
import pytube as ptyt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
此程式碼使用所提供的 URL 建立 YouTube 物件,過濾可用的串流以選擇只有音訊的選項,並下載為 MP3 檔案,檔案名稱為yt_audio.mp3。此檔案將用於下一階段的轉錄。
使用 Whisper 謄寫音訊
下載音訊檔案後,下一步就是使用 OpenAI 的 Whisper 模型將它轉換成文字。Whisper 是一個強大的語音轉換工具,可透過您先前安裝的openai-whisper函式庫取得。以下是轉錄音訊的方法:
import whispermodel = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)

此程式碼載入 Whisper 的基本模型,轉錄yt_audio.mp3檔案,並擷取結果文字。轉錄的文字會列印到控制台,為您提供視訊音訊內容的書面版本。準備好文字後,您就可以使用 Langchain 歸納文字了。
使用 Langchain 摘要轉錄的文字
現在您有了轉錄的文字,可以使用 Langchain 建立摘要。Langchain 提供了一個靈活的框架,可使用 OpenAI 的語言模型進行文字摘要。這個過程包括將文字分割成較小的片段,然後歸納每個片段,最後產生簡潔的概述。
請依照下列步驟使用 Langchain 設定摘要處理程序:
從 Langchain 匯入所需的模組:
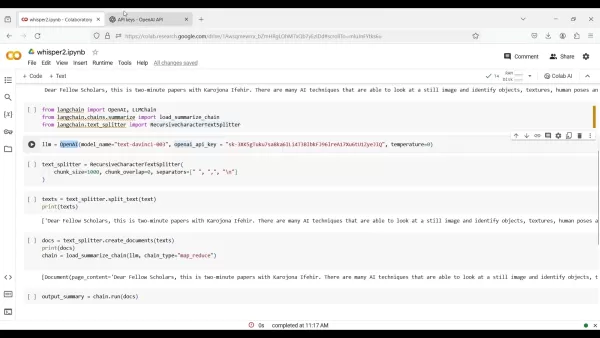
這包括 OpenAI 整合、LLM 鏈、摘要和文字分割的模組。
from langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitter
初始化 OpenAI 語言模型:
llm = OpenAI(model_name="text-davinci-003", openai_api_key="YOUR_API_KEY", temperature=0)
將YOUR_API_KEY改為您實際的 OpenAI API 金鑰,您可以從 OpenAI 平台取得此金鑰。
將轉錄的文字分割成容易處理的區塊:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=["
", "", ". ", " ", ""])texts = text_splitter.split_text(text)
此程式碼將文字分割為每段 1000 個字元的區段,且不重疊。參數 `separators` 確保文字在段落和句子等自然分隔處被分割。4.**從文字區塊建立文件物件**:```pythondocs = [Document(page_content=t) for t in texts]
載入摘要鏈:
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)
此程式碼使用map_reduce方法初始化摘要鏈。這種方法對於大型文件非常有效率,因為它會先個別總結每個分塊 (map 步驟),然後將這些總結合併為最後的總結 (reduce 步驟)。
執行摘要鏈:
output_summary = chain.run(docs)print(output_summary)
這會在文件塊上執行摘要程序,並列印最終摘要。現在您有了原始 YouTube 影片內容的簡明摘要。
只要遵循這些步驟,您就可以使用 Langchain、OpenAI 和 Whisper 有效率地摘要 YouTube 影片,自動化資訊擷取並提昇工作效率。
逐步指南:使用程式碼摘要 YouTube 影片
步驟 1:開啟 Google Colab 並建立新筆記本
開啟您的網頁瀏覽器,並前往 Google Colab 網站。使用您的 Google 帳戶登入。登入後,按一下「New Notebook」建立新筆記。這會為您的專案開啟一個乾淨的編碼環境。

步驟 2:設定運行時設定
為了確保最佳效能,尤其是 AI 模型,請設定運行時間使用 GPU。點選功能表列的「Runtime」,然後選擇「Change runtime type」。從「硬體加速器」下拉選項中,選擇「GPU」。儲存您的變更。這會為您的會話分配 GPU,加速處理任務。
步驟 3:安裝所需的程式庫
接下來,使用pip 安裝必要的 Python 函式庫。這些函式庫包括openai、openai-whisper、pytube 和langchain。在 Colab 單元中執行下列程式碼:
!pip install openai!pip install -U openai-whisper!pip install pytube!pip install langchain
執行單元以安裝函式庫。在繼續之前,請確認安裝成功完成。
步驟 4:匯入程式庫並設定 OpenAI API 金鑰
匯入必要的函式庫到您的筆記型電腦。此外,請設定 OpenAI API 金鑰,以便存取語言模型。您可以在 OpenAI 平台上產生 API 金鑰。在程式碼中用您的實際金鑰取代YOUR_API_KEY。
import pytube as ptimport whisperfrom langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitteropenai_api_key = "YOUR_API_KEY"
步驟 5:載入 YouTube 影片並擷取音訊
指定 YouTube 視訊 URL 並使用pytube擷取音訊。下面的程式碼會建立一個YouTube物件,過濾只包含音訊的串流,並將音訊下載為 MP3 檔案:
yt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
步驟 6:使用 Whisper 謄寫音訊
使用 Whisper 模型將下載的音訊檔案轉錄為文字。載入模型並使用它來轉錄音訊:
model = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
步驟 7:使用 Langchain 總結文字
使用 Langchain 歸納轉錄的文字。這包括將文字分割成區塊、從區塊中建立文件,並使用摘要鏈產生最終摘要。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=["", "", ". ", " ", ""])texts = text_splitter.split_text(text)from langchain.document_loaders import TextLoaderfrom langchain.docstore.TextLoader.text = text_splitter.split_text(text)document import Documentdocs = [Document(page_content=t) for t in texts]llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key, temperature=0)chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)output_summary = chain.run(docs)print(output_summary)
此程式碼會分割文字、建立文件、初始化摘要鏈,並執行它以產生摘要。
步驟 8:執行程式碼並取得摘要
執行 Colab 記事本中的所有程式碼單元格。這將運行整個摘要管道,從音訊下載到最終摘要產生。生成的摘要將顯示在控制台中。
Langchain、OpenAI 和 Whisper 的定價考慮因素
瞭解成本
使用 Langchain、OpenAI 和 Whisper 時,瞭解它們各自的定價模式對有效管理預算非常重要。
- OpenAI API:OpenAI 根據代用幣使用量收費。成本依據模型(例如 text-davinci-003)和處理的代幣數量而有所不同。定價通常以每 1,000 個代用幣計算,因此監控使用量是控制成本的關鍵。
- Whisper:您可以透過 OpenAI 將 Whisper 作為 API 使用,也可以自行託管。如果使用 OpenAI API,轉錄成本取決於音訊時間長短。
- Langchain:作為一個開放原始碼架構,Langchain 本身是免費的。但是,您必須計算整合服務的成本,例如您透過它使用的 OpenAI API。
基於 Langchain 的視訊摘要的優缺點
優點
相較於手動摘要,自動化可節省大量時間。
可產生簡明的摘要,捕捉視訊的重點。
可客製化設定可依您的需求調整摘要。
與強大的 OpenAI 語言模型無縫整合。
由於是開放原始碼,它提供了彈性和社群驅動的支援。
缺點
需要基本的程式設計知識來設定和配置。
摘要的準確度可能取決於語音轉錄和語言模型的品質。
使用 OpenAI API 會產生成本。
在轉錄和摘要過程中可能會出錯或不準確。
可能無法捕捉原始視訊中所有微妙的細節與情境。
Langchain 用於視訊摘要的主要功能
利用 Langchain 的功能
Langchain 提供多項功能,讓視訊摘要更有效率:
- 鏈抽象:提供建立鏈的標準化方式,可輕鬆將語言模型和文字分割器等不同元件結合為一個具凝聚力的工作流程。
- 文字分割:包含各種分割文字的方法,例如
RecursiveCharacterTextSplitter,可根據指定的分隔符 (例如段落和句子) 來分割文字。 - 總結鏈:提供預先建立的鏈,例如
load_summarize_chain,使用map_reduce等技術有效地總結大文件。
自動化視訊摘要的多樣化使用案例
跨領域的應用
自動視訊摘要在不同領域有許多實際應用:
- 教育:學生和教師可以快速檢視講座視訊、擷取關鍵意念,並建立學習指南。
- 研究:研究人員可以有效率地分析視訊內容、擷取相關資料並識別模式。
- 商業:專業人士可以隨時瞭解產業趨勢、分析競爭對手的內容,並建立摘要報告。
- 媒體監控:機構可追蹤新聞廣播、分析輿論,並找出新興新聞。
常見問題
什麼是 Langchain,它如何促進視訊摘要?
Langchain 是一個專為簡化使用語言模型建立應用程式而設計的框架。它提供了一個標準介面來建立操作鏈。對於視訊摘要,Langchain 可協助管理從處理轉錄文字到產生最終摘要的整個流程,使其成為一個靈活且功能強大的工具。
如何取得 OpenAI API 金鑰?
驗證和使用 OpenAI 語言模型進行文字摘要需要 OpenAI API 金鑰。您可以在 OpenAI 平台上註冊並在帳號設定中產生一個金鑰,以獲得 API 金鑰。此金鑰可讓您的腳本存取提供摘要功能的模型。
使用 Langchain、OpenAI 和 Whisper 時,管理成本的主要考量為何?
為了有效管理成本,請密切注意 OpenAI API 的令牌使用量,因為計費是根據消耗量來計算的。使用適當的文字區塊大小來優化您的程式碼,並考慮使用較便宜的模型來執行較簡單的任務。對 Whisper 而言,如果使用 API,費用是根據音訊長度來計算,因此處理較短的片段或使用自託管版本有助於控制支出。
進一步探索:相關問題與進階技術
如何使用 Langchain 提高視訊摘要的精確度?
提高摘要精確度涉及調整多項參數和技術。請考慮以下策略:嘗試使用不同的文字分割器:字元文字分割器:根據字元來分割文字,這有助於維持句子結構:使用分隔符清單遞迴分割文字,可進行更智慧型的分割:測試不同的分割器,看看哪個最適合您的特定視訊內容。Adjust the Chunk Size and Overlap:Chunk Size:文字片段的大小會影響摘要。較小的區塊可能會產生更詳細的摘要,而較大的區塊則會提供更多的上下文:片段間的重疊有助於維持上下文的流暢。選擇更強大的語言模型:OpenAI 提供多種模型,可滿足不同的需求。
相關文章
 貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
AI 搜尋強制政策引發用戶出走潮,DuckDuckGo 用戶數激增
繼 Google 在 2026 年 I/O 大會上宣布將對其搜尋引擎進行全面的人工智慧改造後,由於缺乏簡單的「一鍵停用」功能來關閉 AI 功能,許多使用者開始尋找更具掌控力的替代方案。 以隱私保護為核心的搜尋平台DuckDuckGo近期明顯感受到流量轉移,已成為對 Google 強勢推動 AI 感到不滿用戶的熱門避風港。1. 用戶用腳投票:安裝量激增根據 DuckDuckGo 分享的數據,隨著用戶
小紅書組織重整:柯南出任總裁,成立 AI 主業務部門 Dots 及海外事業部 Rednote
4月30日,小紅書向全體員工發佈內部通告,宣布啟動新一輪組織架構調整。此次變革的核心在於將社群、電商和商業化三大業務線,與公司的技術系統全面整合。 公司新設了名為「Dots」的「AI優先」部門,此舉標誌著小紅書已正式將人工智慧提升為最高戰略優先事項,旨在使其從工具型功能轉型為核心生產力。在人事任命方面,南(丁玲)獲任命為小紅書總裁,負責公司核心業務營運,並直接向執行長邢宇匯報。 各業務領域的負責人
相關專題推薦
文字轉語音
貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
AI 搜尋強制政策引發用戶出走潮,DuckDuckGo 用戶數激增
繼 Google 在 2026 年 I/O 大會上宣布將對其搜尋引擎進行全面的人工智慧改造後,由於缺乏簡單的「一鍵停用」功能來關閉 AI 功能,許多使用者開始尋找更具掌控力的替代方案。 以隱私保護為核心的搜尋平台DuckDuckGo近期明顯感受到流量轉移,已成為對 Google 強勢推動 AI 感到不滿用戶的熱門避風港。1. 用戶用腳投票:安裝量激增根據 DuckDuckGo 分享的數據,隨著用戶
小紅書組織重整:柯南出任總裁,成立 AI 主業務部門 Dots 及海外事業部 Rednote
4月30日,小紅書向全體員工發佈內部通告,宣布啟動新一輪組織架構調整。此次變革的核心在於將社群、電商和商業化三大業務線,與公司的技術系統全面整合。 公司新設了名為「Dots」的「AI優先」部門,此舉標誌著小紅書已正式將人工智慧提升為最高戰略優先事項,旨在使其從工具型功能轉型為核心生產力。在人事任命方面,南(丁玲)獲任命為小紅書總裁,負責公司核心業務營運,並直接向執行長邢宇匯報。 各業務領域的負責人
相關專題推薦
文字轉語音
 專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
 10 個工具
10 個工具
 xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![HenryLopez]()
這篇教學太實用了!我常常需要看很多英文教學影片,如果能自動生成摘要真的會省下超多時間。不過我有點擔心,如果AI摘要漏掉重要細節怎麼辦?大家會完全依賴這個功能嗎?🤔
在我們這個快節奏的數位世界中,能夠快速瞭解影片的核心訊息是非常有價值的。對於研究人員、學生和專業人士來說,為冗長的 YouTube 影片製作簡潔的摘要,可以大大節省時間,提高工作效率。本指南提供了一個清晰、循序漸進的方法,讓您可以使用 Langchain、OpenAI 和 Whisper 自動建立 YouTube 內容的摘要。您將學會如何在 Google Colab 中撰寫 Python 腳本來擷取音訊、將音訊轉錄成文字,然後再使用強大的 AI 模型進行濃縮。
重點
學習使用 Langchain、OpenAI 和 Whisper 進行自動視訊摘要。
在 Google Colab 中編寫 Python 程式碼來下載和轉錄視訊音訊。
應用文字分割與摘要方法,建立簡潔的概述。
實作 map reduce chain 技術,以有效率地總結大文件。
利用 OpenAI API 存取進階摘要模型。
使用 RecursiveCharacterTextSplitter 將文字分割成較小的、可管理的片段。
設定視訊摘要的環境
開始使用 Google Colab
首先,請確定您有 Google 帳戶以存取 Google Colab,這是一個免費的雲端平台,非常適合執行 Python 程式碼。開啟 Google Colab 並建立一個新的筆記本。這將會是您視訊摘要專案的工作區。將筆記本重新命名為易記的名稱,例如「YouTube_Summarizer」,以協助您保持井井有條。
接下來,調整執行時設定。
進入「Runtime」功能表,選擇「Change runtime type」。從下拉式選單中,選擇「T4 GPU」作為硬體加速器。此選擇會使用 GPU 的處理能力來加速您的程式碼執行。儲存設定以套用至 Colab 環境。現在,您已準備好安裝必要的套件。
安裝必要的 Python 套件
在撰寫程式碼之前,您必須先安裝所需的 Python 函式庫。這些套件提供了音訊擷取、轉錄和摘要的工具。在 Colab 單元中使用pip install 執行下列指令:
!pip install OpenAI!pip install -U openai-whisper!pip install pytube!pip install langchain
- OpenAI:此函式庫可與 OpenAI 的語言模型互動,這對於文字摘要非常重要。
- Whisper:OpenAI 的自動語音辨識 (ASR) 系統,用來將音訊轉換成文字。
- Pytube:直接從 YouTube 影片下載音訊的函式庫。
- Langchain:一個功能強大的框架,提供鏈和其他工具的標準介面,簡化使用語言模型建立應用程式的流程。
這些指令將安裝 OpenAI、Whisper、Pytube 和 Langchain 函式庫,為您提供下一步所需的所有工具。安裝完成後,您就可以將這些套件匯入腳本中。
從 YouTube 影片擷取音訊
匯入 Pytube 並載入影片
首先匯入pytube函式庫,它可以讓您從 YouTube 下載音訊。匯入後,指定您要處理的 YouTube 影片的 URL。
以下程式碼顯示如何執行:
import pytube as ptyt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
此程式碼使用所提供的 URL 建立 YouTube 物件,過濾可用的串流以選擇只有音訊的選項,並下載為 MP3 檔案,檔案名稱為yt_audio.mp3。此檔案將用於下一階段的轉錄。
使用 Whisper 謄寫音訊
下載音訊檔案後,下一步就是使用 OpenAI 的 Whisper 模型將它轉換成文字。Whisper 是一個強大的語音轉換工具,可透過您先前安裝的openai-whisper函式庫取得。以下是轉錄音訊的方法:
import whispermodel = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
此程式碼載入 Whisper 的基本模型,轉錄yt_audio.mp3檔案,並擷取結果文字。轉錄的文字會列印到控制台,為您提供視訊音訊內容的書面版本。準備好文字後,您就可以使用 Langchain 歸納文字了。
使用 Langchain 摘要轉錄的文字
現在您有了轉錄的文字,可以使用 Langchain 建立摘要。Langchain 提供了一個靈活的框架,可使用 OpenAI 的語言模型進行文字摘要。這個過程包括將文字分割成較小的片段,然後歸納每個片段,最後產生簡潔的概述。
請依照下列步驟使用 Langchain 設定摘要處理程序:
從 Langchain 匯入所需的模組:
這包括 OpenAI 整合、LLM 鏈、摘要和文字分割的模組。
from langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitter初始化 OpenAI 語言模型:
llm = OpenAI(model_name="text-davinci-003", openai_api_key="YOUR_API_KEY", temperature=0)將
YOUR_API_KEY改為您實際的 OpenAI API 金鑰,您可以從 OpenAI 平台取得此金鑰。將轉錄的文字分割成容易處理的區塊:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=["
", "", ". ", " ", ""])texts = text_splitter.split_text(text)
此程式碼將文字分割為每段 1000 個字元的區段,且不重疊。參數 `separators` 確保文字在段落和句子等自然分隔處被分割。4.**從文字區塊建立文件物件**:```pythondocs = [Document(page_content=t) for t in texts]
載入摘要鏈:
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)此程式碼使用
map_reduce方法初始化摘要鏈。這種方法對於大型文件非常有效率,因為它會先個別總結每個分塊 (map 步驟),然後將這些總結合併為最後的總結 (reduce 步驟)。執行摘要鏈:
output_summary = chain.run(docs)print(output_summary)這會在文件塊上執行摘要程序,並列印最終摘要。現在您有了原始 YouTube 影片內容的簡明摘要。
只要遵循這些步驟,您就可以使用 Langchain、OpenAI 和 Whisper 有效率地摘要 YouTube 影片,自動化資訊擷取並提昇工作效率。
逐步指南:使用程式碼摘要 YouTube 影片
步驟 1:開啟 Google Colab 並建立新筆記本
開啟您的網頁瀏覽器,並前往 Google Colab 網站。使用您的 Google 帳戶登入。登入後,按一下「New Notebook」建立新筆記。這會為您的專案開啟一個乾淨的編碼環境。
步驟 2:設定運行時設定
為了確保最佳效能,尤其是 AI 模型,請設定運行時間使用 GPU。點選功能表列的「Runtime」,然後選擇「Change runtime type」。從「硬體加速器」下拉選項中,選擇「GPU」。儲存您的變更。這會為您的會話分配 GPU,加速處理任務。
步驟 3:安裝所需的程式庫
接下來,使用pip 安裝必要的 Python 函式庫。這些函式庫包括openai、openai-whisper、pytube 和langchain。在 Colab 單元中執行下列程式碼:
!pip install openai!pip install -U openai-whisper!pip install pytube!pip install langchain
執行單元以安裝函式庫。在繼續之前,請確認安裝成功完成。
步驟 4:匯入程式庫並設定 OpenAI API 金鑰
匯入必要的函式庫到您的筆記型電腦。此外,請設定 OpenAI API 金鑰,以便存取語言模型。您可以在 OpenAI 平台上產生 API 金鑰。在程式碼中用您的實際金鑰取代YOUR_API_KEY。
import pytube as ptimport whisperfrom langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitteropenai_api_key = "YOUR_API_KEY"
步驟 5:載入 YouTube 影片並擷取音訊
指定 YouTube 視訊 URL 並使用pytube擷取音訊。下面的程式碼會建立一個YouTube物件,過濾只包含音訊的串流,並將音訊下載為 MP3 檔案:
yt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
步驟 6:使用 Whisper 謄寫音訊
使用 Whisper 模型將下載的音訊檔案轉錄為文字。載入模型並使用它來轉錄音訊:
model = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
步驟 7:使用 Langchain 總結文字
使用 Langchain 歸納轉錄的文字。這包括將文字分割成區塊、從區塊中建立文件,並使用摘要鏈產生最終摘要。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=["", "", ". ", " ", ""])texts = text_splitter.split_text(text)from langchain.document_loaders import TextLoaderfrom langchain.docstore.TextLoader.text = text_splitter.split_text(text)document import Documentdocs = [Document(page_content=t) for t in texts]llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key, temperature=0)chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)output_summary = chain.run(docs)print(output_summary)
此程式碼會分割文字、建立文件、初始化摘要鏈,並執行它以產生摘要。
步驟 8:執行程式碼並取得摘要
執行 Colab 記事本中的所有程式碼單元格。這將運行整個摘要管道,從音訊下載到最終摘要產生。生成的摘要將顯示在控制台中。
Langchain、OpenAI 和 Whisper 的定價考慮因素
瞭解成本
使用 Langchain、OpenAI 和 Whisper 時,瞭解它們各自的定價模式對有效管理預算非常重要。
- OpenAI API:OpenAI 根據代用幣使用量收費。成本依據模型(例如 text-davinci-003)和處理的代幣數量而有所不同。定價通常以每 1,000 個代用幣計算,因此監控使用量是控制成本的關鍵。
- Whisper:您可以透過 OpenAI 將 Whisper 作為 API 使用,也可以自行託管。如果使用 OpenAI API,轉錄成本取決於音訊時間長短。
- Langchain:作為一個開放原始碼架構,Langchain 本身是免費的。但是,您必須計算整合服務的成本,例如您透過它使用的 OpenAI API。
基於 Langchain 的視訊摘要的優缺點
優點
相較於手動摘要,自動化可節省大量時間。
可產生簡明的摘要,捕捉視訊的重點。
可客製化設定可依您的需求調整摘要。
與強大的 OpenAI 語言模型無縫整合。
由於是開放原始碼,它提供了彈性和社群驅動的支援。
缺點
需要基本的程式設計知識來設定和配置。
摘要的準確度可能取決於語音轉錄和語言模型的品質。
使用 OpenAI API 會產生成本。
在轉錄和摘要過程中可能會出錯或不準確。
可能無法捕捉原始視訊中所有微妙的細節與情境。
Langchain 用於視訊摘要的主要功能
利用 Langchain 的功能
Langchain 提供多項功能,讓視訊摘要更有效率:
- 鏈抽象:提供建立鏈的標準化方式,可輕鬆將語言模型和文字分割器等不同元件結合為一個具凝聚力的工作流程。
- 文字分割:包含各種分割文字的方法,例如
RecursiveCharacterTextSplitter,可根據指定的分隔符 (例如段落和句子) 來分割文字。 - 總結鏈:提供預先建立的鏈,例如
load_summarize_chain,使用map_reduce等技術有效地總結大文件。
自動化視訊摘要的多樣化使用案例
跨領域的應用
自動視訊摘要在不同領域有許多實際應用:
- 教育:學生和教師可以快速檢視講座視訊、擷取關鍵意念,並建立學習指南。
- 研究:研究人員可以有效率地分析視訊內容、擷取相關資料並識別模式。
- 商業:專業人士可以隨時瞭解產業趨勢、分析競爭對手的內容,並建立摘要報告。
- 媒體監控:機構可追蹤新聞廣播、分析輿論,並找出新興新聞。
常見問題
什麼是 Langchain,它如何促進視訊摘要?
Langchain 是一個專為簡化使用語言模型建立應用程式而設計的框架。它提供了一個標準介面來建立操作鏈。對於視訊摘要,Langchain 可協助管理從處理轉錄文字到產生最終摘要的整個流程,使其成為一個靈活且功能強大的工具。
如何取得 OpenAI API 金鑰?
驗證和使用 OpenAI 語言模型進行文字摘要需要 OpenAI API 金鑰。您可以在 OpenAI 平台上註冊並在帳號設定中產生一個金鑰,以獲得 API 金鑰。此金鑰可讓您的腳本存取提供摘要功能的模型。
使用 Langchain、OpenAI 和 Whisper 時,管理成本的主要考量為何?
為了有效管理成本,請密切注意 OpenAI API 的令牌使用量,因為計費是根據消耗量來計算的。使用適當的文字區塊大小來優化您的程式碼,並考慮使用較便宜的模型來執行較簡單的任務。對 Whisper 而言,如果使用 API,費用是根據音訊長度來計算,因此處理較短的片段或使用自託管版本有助於控制支出。
進一步探索:相關問題與進階技術
如何使用 Langchain 提高視訊摘要的精確度?
提高摘要精確度涉及調整多項參數和技術。請考慮以下策略:嘗試使用不同的文字分割器:字元文字分割器:根據字元來分割文字,這有助於維持句子結構:使用分隔符清單遞迴分割文字,可進行更智慧型的分割:測試不同的分割器,看看哪個最適合您的特定視訊內容。Adjust the Chunk Size and Overlap:Chunk Size:文字片段的大小會影響摘要。較小的區塊可能會產生更詳細的摘要,而較大的區塊則會提供更多的上下文:片段間的重疊有助於維持上下文的流暢。選擇更強大的語言模型:OpenAI 提供多種模型,可滿足不同的需求。









 貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
 AI 搜尋強制政策引發用戶出走潮,DuckDuckGo 用戶數激增
繼 Google 在 2026 年 I/O 大會上宣布將對其搜尋引擎進行全面的人工智慧改造後,由於缺乏簡單的「一鍵停用」功能來關閉 AI 功能,許多使用者開始尋找更具掌控力的替代方案。 以隱私保護為核心的搜尋平台DuckDuckGo近期明顯感受到流量轉移,已成為對 Google 強勢推動 AI 感到不滿用戶的熱門避風港。1. 用戶用腳投票:安裝量激增根據 DuckDuckGo 分享的數據,隨著用戶
AI 搜尋強制政策引發用戶出走潮,DuckDuckGo 用戶數激增
繼 Google 在 2026 年 I/O 大會上宣布將對其搜尋引擎進行全面的人工智慧改造後,由於缺乏簡單的「一鍵停用」功能來關閉 AI 功能,許多使用者開始尋找更具掌控力的替代方案。 以隱私保護為核心的搜尋平台DuckDuckGo近期明顯感受到流量轉移,已成為對 Google 強勢推動 AI 感到不滿用戶的熱門避風港。1. 用戶用腳投票:安裝量激增根據 DuckDuckGo 分享的數據,隨著用戶
 小紅書組織重整:柯南出任總裁,成立 AI 主業務部門 Dots 及海外事業部 Rednote
4月30日,小紅書向全體員工發佈內部通告,宣布啟動新一輪組織架構調整。此次變革的核心在於將社群、電商和商業化三大業務線,與公司的技術系統全面整合。 公司新設了名為「Dots」的「AI優先」部門,此舉標誌著小紅書已正式將人工智慧提升為最高戰略優先事項,旨在使其從工具型功能轉型為核心生產力。在人事任命方面,南(丁玲)獲任命為小紅書總裁,負責公司核心業務營運,並直接向執行長邢宇匯報。 各業務領域的負責人
小紅書組織重整:柯南出任總裁,成立 AI 主業務部門 Dots 及海外事業部 Rednote
4月30日,小紅書向全體員工發佈內部通告,宣布啟動新一輪組織架構調整。此次變革的核心在於將社群、電商和商業化三大業務線,與公司的技術系統全面整合。 公司新設了名為「Dots」的「AI優先」部門,此舉標誌著小紅書已正式將人工智慧提升為最高戰略優先事項,旨在使其從工具型功能轉型為核心生產力。在人事任命方面,南(丁玲)獲任命為小紅書總裁,負責公司核心業務營運,並直接向執行長邢宇匯報。 各業務領域的負責人

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

這篇教學太實用了!我常常需要看很多英文教學影片,如果能自動生成摘要真的會省下超多時間。不過我有點擔心,如果AI摘要漏掉重要細節怎麼辦?大家會完全依賴這個功能嗎?🤔













