
















 家
家Langchainチュートリアル:YouTube動画要約ガイド
ペースの速いデジタル世界では、動画の核となるメッセージを素早く理解する能力は非常に貴重です。研究者、学生、専門家にとって、長いYouTube動画の簡潔な要約を作成することは、時間の節約と生産性の向上につながります。このガイドでは、Langchain、OpenAI、Whisperを使って、YouTubeコンテンツの要約を自動的に作成する方法を、明確なステップで説明します。Google ColabでPythonスクリプトを作成し、音声を抽出、テキストに書き起こし、強力なAIモデルを使って要約する方法を学びます。
キーポイント
動画の自動要約にLangchain、OpenAI、Whisperを使用する方法を学ぶ。
Google ColabでPythonコードを記述し、ビデオの音声をダウンロードして書き起こします。
テキスト分割と要約方法を適用し、簡潔な概要を作成する。
大きな文書を効率的に要約するためのマップリデューチェーン技術を実装する。
OpenAI APIを利用して、高度な要約モデルにアクセスする。
RecursiveCharacterTextSplitter を使用して、テキストを管理しやすい小さな断片に分割する。
動画要約のための環境設定
Google Colabを始める
まず、Pythonコードを実行するのに最適な無料のクラウドベースのプラットフォームであるGoogle Colabにアクセスするために、Googleアカウントを持っていることを確認してください。Google Colabを開き、新しいノートブックを作成します。これが動画要約プロジェクトのワークスペースになる。整理しやすいように、ノートブックの名前を'YouTube_Summarizer'のような覚えやすいものに変更する。
次に、ランタイムの設定を調整する。
Runtime'メニューに行き、'Change runtime type'を選択する。ドロップダウンから、ハードウェア・アクセラレーターとして「T4 GPU」を選択する。この選択により、GPUの処理能力を使用してコード実行を高速化します。設定を保存してColab環境に適用します。これで、必要なパッケージをインストールする準備ができました。
必須Pythonパッケージのインストール
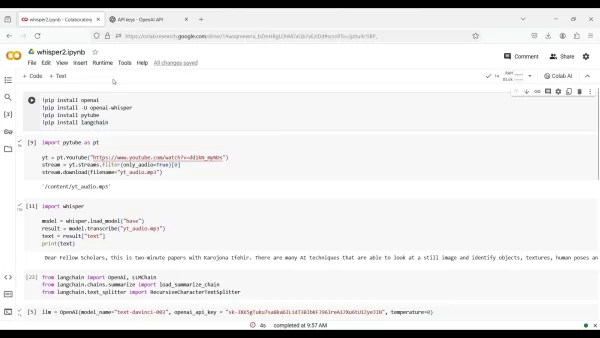
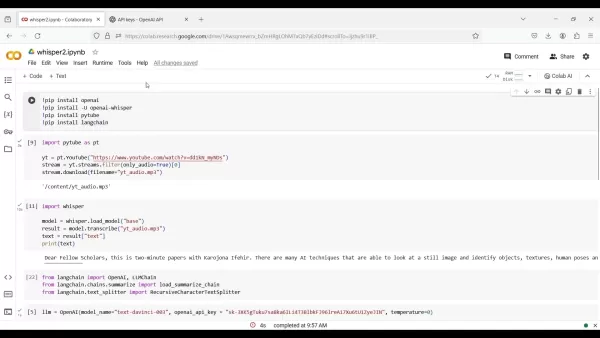
コードを書く前に、必要なPythonライブラリをインストールする必要があります。これらのパッケージは、音声抽出、文字起こし、要約のためのツールを提供します。Colabセルでpip installを使って以下のコマンドを実行する:
pip install OpenAI!pip install -U openai-whisper!pip install pytube!pip install langchain
- OpenAI: このライブラリはOpenAIの言語モデルとのインタラクションを可能にする。
- Whisper:OpenAIの自動音声認識(ASR)システムで、音声をテキストに変換するのに使われる。
- Pytube:YouTubeの動画から直接音声をダウンロードするためのライブラリ。
- Langchainチェーンやその他のツールの標準インターフェースを提供する強力なフレームワークで、言語モデルを使ったアプリケーションの構築プロセスを簡素化します。
これらのコマンドを実行すると、OpenAI、Whisper、Pytube、Langchainライブラリがインストールされ、次のステップに必要なツールがすべて揃う。インストールが完了したら、これらのパッケージをスクリプトにインポートできる。
YouTube動画から音声を抽出する
Pytubeのインポートと動画の読み込み
まず、YouTubeから音声をダウンロードできるpytubeライブラリをインポートします。インポートしたら、処理したいYouTube動画のURLを指定します。

次のコードはその方法を示しています:
import pytube as ptyt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
このコードでは、指定されたURLを使ってYouTubeオブジェクトを作成し、利用可能なストリームをフィルタリングして音声のみのオプションを選択し、yt_audio.mp3というMP3ファイルとしてダウンロードします。このファイルは次のステージで書き起こしに使われます。
Whisperで音声を書き起こす
音声ファイルをダウンロードしたら、次はOpenAIのWhisperモデルを使ってテキストに変換します。Whisperは音声からテキストに変換するための堅牢なツールで、先にインストールしたopenai-whisperライブラリから利用できます。以下は、音声を書き起こす方法です:
import whispermodel = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)

このコードはWhisperの基本モデルをロードし、yt_audio.mp3ファイルを書き起こし、結果のテキストを抽出します。書き起こされたテキストはコンソールに出力され、動画の音声コンテンツが文字で表示される。テキストの準備ができたので、Langchainを使ってテキストを要約します。
Langchainを使ってテキストを要約する
書き起こしたテキストを手に入れたら、Langchainを使って要約を作成します。LangchainはOpenAIの言語モデルを使ったテキスト要約のための柔軟なフレームワークを提供します。このプロセスでは、テキストをより小さなセグメントに分割し、それぞれを要約して最終的な簡潔な概要を作成します。
以下の手順に従って、Langchainで要約プロセスをセットアップしてください:
Langchainから必要なモジュールをインポートする:
これにはOpenAI統合、LLMチェーン、要約、テキスト分割のモジュールが含まれる。
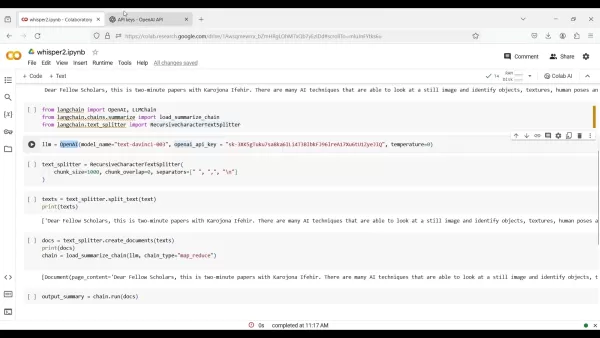
from langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitter
OpenAIの言語モデルを初期化する:
llm = OpenAI(model_name="text-davinci-003", openai_api_key="YOUR_API_KEY", temperature=0)
YOUR_API_KEYは、OpenAIプラットフォームから取得できる実際のOpenAI APIキーに置き換えてください。
書き起こされたテキストを管理しやすい塊に分割します:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=[", "", ".
", "", ". ", " ", ""])text = text_splitter.split_text(text)
このコードでは、テキストを1000文字ずつ、重ならないように分割している。4.**テキストチャンクからドキュメントオブジェクトを作成する**:``pythondocs = [Document(page_content=t) for t in texts].
要約チェーンをロードします:
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)
このコードは、map_reduceメソッドを使って要約チェーンを初期化します。この方法は、各チャンクを個別に要約し(mapステップ)、それらの要約を最終的な要約にまとめる(reduceステップ)ので、大きなドキュメントに対して効率的です。
要約チェーンを実行する:
output_summary = chain.run(docs)print(output_summary)。
これはドキュメントの塊に対して要約処理を実行し、最終的な要約を表示します。これで、元のYouTube動画の内容の簡潔な要約ができました。
以上の手順で、Langchain、OpenAI、Whisperを使ってYouTube動画を効率的に要約し、情報抽出を自動化して生産性を高めることができます。
ステップバイステップガイドコードでYouTube動画を要約する
ステップ1:Google Colabを開き、新しいノートブックを作成する
ウェブブラウザを開き、Google Colabのウェブサイトにアクセスする。Googleアカウントでログインします。ログインしたら、「新しいノートブック」をクリックして新しいノートブックを作成します。これで、プロジェクト用のクリーンなコーディング環境が開きます。

ステップ2:ランタイム設定の構成
最適なパフォーマンスを確保するために、特にAIモデルの場合は、GPUを使用するようにランタイムを設定します。メニューバーの'Runtime'をクリックし、'Change runtime type'を選択する。ハードウェアアクセラレータ」のドロップダウンから「GPU」を選択します。変更を保存します。これでセッションにGPUが割り当てられ、処理タスクが加速されます。
ステップ3:必要なライブラリのインストール
次に、pipを使用して必要なPythonライブラリをインストールします。openai、openai-whisper、pytube、langchainなどです。以下のコードをColabセルで実行する:
pip install openai!pip install -U openai-whisper!pip install pytube!pip install langchain
セルを実行してライブラリをインストールします。次に進む前に、インストールが正常に完了したことを確認してください。
ステップ 4: ライブラリのインポートと OpenAI API キーの設定
必要なライブラリをノートブックにインポートします。また、言語モデルへのアクセスを有効にするために、OpenAI APIキーを設定します。APIキーはOpenAIプラットフォームで生成できます。コード中のYOUR_API_KEYは実際のキーに置き換えてください。
import pytube as ptimport whisperfrom langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitteropenai_api_key = "YOUR_API_KEY"
ステップ5:YouTubeビデオの読み込みと音声の抽出
YouTubeビデオのURLを指定し、pytubeを使って音声を抽出します。以下のコードは、YouTubeオブジェクトを作成し、音声のみのストリームをフィルタリングし、音声をMP3ファイルとしてダウンロードします:
yt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
ステップ 6: Whisperを使って音声を書き起こす
ダウンロードした音声ファイルをWhisperモデルを使ってテキストに書き起こします。モデルをロードして、それを使って音声を書き起こします:
model = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
ステップ 7: Langchainを使ってテキストを要約する
Langchainを使って書き起こしたテキストを要約します。これは、テキストをチャンクに分割し、そこからドキュメントを作成し、要約チェーンを使って最終的な要約を生成する。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=[", "", ". ", ""])texts = text_splitter.split_text(text)from langchain.document_loaders import TextLoaderfrom langchain.docstore.document import Documentdocs = [Document(page_content=t) for t in texts]llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key, temperature=0)chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)output_summary = chain.run(docs)print(output_summary)
このコードは、テキストを分割し、ドキュメントを作成し、要約チェーンを初期化し、要約を作成するために実行する。
ステップ8: コードの実行とサマリーの取得
Colabノートブックのすべてのコードセルを実行する。これにより、音声のダウンロードから最終的な要約の生成まで、要約パイプライン全体が実行される。結果の要約はコンソールに表示されます。
Langchain、OpenAI、Whisperの価格に関する考察
コストを理解する
Langchain、OpenAI、Whisperを使用する場合、予算を効果的に管理するために、それぞれの価格モデルを理解することが重要です。
- OpenAI API:OpenAIはトークンの使用量に応じて課金されます。コストはモデル(例:text-davinci-003)と処理されるトークンの数によって異なります。価格は通常1,000トークンあたりなので、使用量を監視することがコストをコントロールする鍵になります。
- ウィスパーWhisperはOpenAIを通じてAPIとして利用することも、自分でホストすることもできる。OpenAI APIを使用する場合、トランスクリプションのコストは音声の長さに依存する。
- Langchain:オープンソースのフレームワークであるLangchain自体は無料です。しかし、Langchainを通して使用するOpenAI APIなど、統合されたサービスのコストを考慮する必要があります。
Langchainベースのビデオ要約の利点と欠点
長所
自動化により、手作業による要約に比べ、かなりの時間を節約できる。
動画の要点を捉えた簡潔な要約を生成。
カスタマイズ可能な設定により、ニーズに合わせて要約を調整できる。
強力なOpenAI言語モデルとのシームレスな統合。
オープンソースであるため、柔軟性とコミュニティ主導のサポートを提供する。
短所
セットアップと設定には基本的なプログラミング知識が必要。
要約の精度は、音声書き起こしの品質と言語モデルに依存する可能性がある。
OpenAI APIを使用するためのコストがかかる。
書き起こしや要約中にエラーや不正確さが発生する可能性がある。
元のビデオの微妙なニュアンスや文脈を全て把握できない可能性がある。
動画要約用Langchainの主な特徴
Langchainの機能の活用
Langchainは動画要約をより効率的にするいくつかの機能を提供します:
- チェーンの抽象化:チェインの抽象化:チェインを構築する標準的な方法を提供し、言語モデルやテキストスプリッターのような異なるコンポーネントを簡単に結合し、まとまりのあるワークフローを実現します。
- テキスト分割:段落や文などの指定された区切り文字に基づいてテキストを分割する
RecursiveCharacterTextSplitterなど、テキストを分割するためのさまざまなメソッドが含まれています。 - 要約チェーン:
load_summarize_chainのような、大規模なドキュメントを効率的に要約するためにmap_reduceのようなテクニックを使用するビルド済みのチェーンを提供します。
自動ビデオ要約の多様な使用例
さまざまな分野での応用
自動動画要約は、様々な分野で数多くの実用的な用途がある:
- 教育:学生や教師は講義ビデオを素早くレビューし、重要なアイデアを抽出し、学習ガイドを作成することができる。
- 研究:研究者はビデオコンテンツを効率的に分析し、関連データを抽出し、パターンを特定することができます。
- ビジネス:プロフェッショナルは、業界のトレンド情報を入手し、競合他社のコンテンツを分析し、サマリーレポートを作成できます。
- メディアモニタリング:ニュース放送を追跡し、世論を分析し、新たなストーリーを特定することができます。
よくある質問
Langchainとは何ですか?また、どのようにしてビデオの要約を容易にするのですか?
Langchainは、言語モデルを使ったアプリケーションの構築を簡素化するために設計されたフレームワークです。操作の連鎖を作るための標準インターフェースを提供します。ビデオ要約の場合、Langchainは、書き起こされたテキストの処理から最終的な要約の生成まで、プロセス全体の管理をサポートし、柔軟で強力なツールとなります。
OpenAIのAPIキーはどのように取得できますか?また、なぜ動画要約に必要なのですか?
OpenAI APIキーは、テキスト要約用のOpenAIの言語モデルを認証して使用するために必要です。APIキーは、OpenAIのプラットフォームにサインアップし、アカウント設定でキーを生成することで取得できます。このキーによって、あなたのスクリプトは要約を行うモデルにアクセスできるようになります。
Langchain、OpenAI、Whisperを使用する際のコスト管理上の注意点は何ですか?
コストを効果的に管理するために、OpenAI APIのトークン使用量に注意してください。適切なテキストチャンクサイズを使用してコードを最適化し、単純なタスクにはより安価なモデルを使用することを検討してください。Whisperについては、APIを使用する場合、コストはオーディオの長さに基づいているため、より短いクリップを処理するか、セルフホスティングバージョンを使用することで、費用をコントロールすることができます。
さらに詳しく関連する質問と高度なテクニック
Langchainを使った動画要約の精度を上げるにはどうすればいいですか?
要約の精度を上げるには、いくつかのパラメータやテクニックを調整する必要があります。以下の戦略を検討してください:様々なテキストスプリッターを試す:文字テキストスプリッター:再帰的文字テキスト分割:文字に基づいてテキストを分割します:トークン テキスト スプリッター:トークンに基づいてテキストを分割します:チャンクサイズとオーバーラップの調整:チャンクサイズ:テキストセグメントのサイズは、要約に影響します。チャンクの大きさ:テキストセグメントの大きさは、要約に影響します。チャンクが小さいと、より詳細な要約が得られ、チャンクが大きいと、より多くの文脈が得られます:チャンクの重なり:チャンク間の重なりは文脈の流れを維持するのに役立つ。最適なバランスを見つけるために、さまざまなサイズや重なりを試してみてください。より強力な言語モデルを選択:OpenAIは、以下のようなさまざまなモデルを提供しています。
関連記事
 Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
WordPress.comでは、AIエージェントによる投稿の作成や公開が可能になりました。その他にもさまざまな機能が追加されています。
人気のウェブホスティング・パブリッシングプラットフォームであるWordPress.comが、AIエージェントの導入に乗り出した。この動きは、ウェブのあり方を一変させる可能性がある。同社は金曜日、AIエージェントが顧客のウェブサイト上でコンテンツの下書き作成、編集、公開を行うほか、コメントの管理、メタデータの更新・修正、タグやカテゴリを用いたコンテンツの整理も可能になると発表した。これらすべての操作
関連特集おすすめ
仕事
Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
WordPress.comでは、AIエージェントによる投稿の作成や公開が可能になりました。その他にもさまざまな機能が追加されています。
人気のウェブホスティング・パブリッシングプラットフォームであるWordPress.comが、AIエージェントの導入に乗り出した。この動きは、ウェブのあり方を一変させる可能性がある。同社は金曜日、AIエージェントが顧客のウェブサイト上でコンテンツの下書き作成、編集、公開を行うほか、コメントの管理、メタデータの更新・修正、タグやカテゴリを用いたコンテンツの整理も可能になると発表した。これらすべての操作
関連特集おすすめ
仕事
 おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
 10 ツール
10 ツール
 xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![HenryLopez]()
這篇教學太實用了!我常常需要看很多英文教學影片,如果能自動生成摘要真的會省下超多時間。不過我有點擔心,如果AI摘要漏掉重要細節怎麼辦?大家會完全依賴這個功能嗎?🤔
ペースの速いデジタル世界では、動画の核となるメッセージを素早く理解する能力は非常に貴重です。研究者、学生、専門家にとって、長いYouTube動画の簡潔な要約を作成することは、時間の節約と生産性の向上につながります。このガイドでは、Langchain、OpenAI、Whisperを使って、YouTubeコンテンツの要約を自動的に作成する方法を、明確なステップで説明します。Google ColabでPythonスクリプトを作成し、音声を抽出、テキストに書き起こし、強力なAIモデルを使って要約する方法を学びます。
キーポイント
動画の自動要約にLangchain、OpenAI、Whisperを使用する方法を学ぶ。
Google ColabでPythonコードを記述し、ビデオの音声をダウンロードして書き起こします。
テキスト分割と要約方法を適用し、簡潔な概要を作成する。
大きな文書を効率的に要約するためのマップリデューチェーン技術を実装する。
OpenAI APIを利用して、高度な要約モデルにアクセスする。
RecursiveCharacterTextSplitter を使用して、テキストを管理しやすい小さな断片に分割する。
動画要約のための環境設定
Google Colabを始める
まず、Pythonコードを実行するのに最適な無料のクラウドベースのプラットフォームであるGoogle Colabにアクセスするために、Googleアカウントを持っていることを確認してください。Google Colabを開き、新しいノートブックを作成します。これが動画要約プロジェクトのワークスペースになる。整理しやすいように、ノートブックの名前を'YouTube_Summarizer'のような覚えやすいものに変更する。
次に、ランタイムの設定を調整する。
Runtime'メニューに行き、'Change runtime type'を選択する。ドロップダウンから、ハードウェア・アクセラレーターとして「T4 GPU」を選択する。この選択により、GPUの処理能力を使用してコード実行を高速化します。設定を保存してColab環境に適用します。これで、必要なパッケージをインストールする準備ができました。
必須Pythonパッケージのインストール
コードを書く前に、必要なPythonライブラリをインストールする必要があります。これらのパッケージは、音声抽出、文字起こし、要約のためのツールを提供します。Colabセルでpip installを使って以下のコマンドを実行する:
pip install OpenAI!pip install -U openai-whisper!pip install pytube!pip install langchain
- OpenAI: このライブラリはOpenAIの言語モデルとのインタラクションを可能にする。
- Whisper:OpenAIの自動音声認識(ASR)システムで、音声をテキストに変換するのに使われる。
- Pytube:YouTubeの動画から直接音声をダウンロードするためのライブラリ。
- Langchainチェーンやその他のツールの標準インターフェースを提供する強力なフレームワークで、言語モデルを使ったアプリケーションの構築プロセスを簡素化します。
これらのコマンドを実行すると、OpenAI、Whisper、Pytube、Langchainライブラリがインストールされ、次のステップに必要なツールがすべて揃う。インストールが完了したら、これらのパッケージをスクリプトにインポートできる。
YouTube動画から音声を抽出する
Pytubeのインポートと動画の読み込み
まず、YouTubeから音声をダウンロードできるpytubeライブラリをインポートします。インポートしたら、処理したいYouTube動画のURLを指定します。
次のコードはその方法を示しています:
import pytube as ptyt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
このコードでは、指定されたURLを使ってYouTubeオブジェクトを作成し、利用可能なストリームをフィルタリングして音声のみのオプションを選択し、yt_audio.mp3というMP3ファイルとしてダウンロードします。このファイルは次のステージで書き起こしに使われます。
Whisperで音声を書き起こす
音声ファイルをダウンロードしたら、次はOpenAIのWhisperモデルを使ってテキストに変換します。Whisperは音声からテキストに変換するための堅牢なツールで、先にインストールしたopenai-whisperライブラリから利用できます。以下は、音声を書き起こす方法です:
import whispermodel = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
このコードはWhisperの基本モデルをロードし、yt_audio.mp3ファイルを書き起こし、結果のテキストを抽出します。書き起こされたテキストはコンソールに出力され、動画の音声コンテンツが文字で表示される。テキストの準備ができたので、Langchainを使ってテキストを要約します。
Langchainを使ってテキストを要約する
書き起こしたテキストを手に入れたら、Langchainを使って要約を作成します。LangchainはOpenAIの言語モデルを使ったテキスト要約のための柔軟なフレームワークを提供します。このプロセスでは、テキストをより小さなセグメントに分割し、それぞれを要約して最終的な簡潔な概要を作成します。
以下の手順に従って、Langchainで要約プロセスをセットアップしてください:
Langchainから必要なモジュールをインポートする:
これにはOpenAI統合、LLMチェーン、要約、テキスト分割のモジュールが含まれる。
from langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitterOpenAIの言語モデルを初期化する:
llm = OpenAI(model_name="text-davinci-003", openai_api_key="YOUR_API_KEY", temperature=0)YOUR_API_KEYは、OpenAIプラットフォームから取得できる実際のOpenAI APIキーに置き換えてください。書き起こされたテキストを管理しやすい塊に分割します:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=[", "", ".
", "", ". ", " ", ""])text = text_splitter.split_text(text)
このコードでは、テキストを1000文字ずつ、重ならないように分割している。4.**テキストチャンクからドキュメントオブジェクトを作成する**:``pythondocs = [Document(page_content=t) for t in texts].
要約チェーンをロードします:
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)このコードは、
map_reduceメソッドを使って要約チェーンを初期化します。この方法は、各チャンクを個別に要約し(mapステップ)、それらの要約を最終的な要約にまとめる(reduceステップ)ので、大きなドキュメントに対して効率的です。要約チェーンを実行する:
output_summary = chain.run(docs)print(output_summary)。これはドキュメントの塊に対して要約処理を実行し、最終的な要約を表示します。これで、元のYouTube動画の内容の簡潔な要約ができました。
以上の手順で、Langchain、OpenAI、Whisperを使ってYouTube動画を効率的に要約し、情報抽出を自動化して生産性を高めることができます。
ステップバイステップガイドコードでYouTube動画を要約する
ステップ1:Google Colabを開き、新しいノートブックを作成する
ウェブブラウザを開き、Google Colabのウェブサイトにアクセスする。Googleアカウントでログインします。ログインしたら、「新しいノートブック」をクリックして新しいノートブックを作成します。これで、プロジェクト用のクリーンなコーディング環境が開きます。
ステップ2:ランタイム設定の構成
最適なパフォーマンスを確保するために、特にAIモデルの場合は、GPUを使用するようにランタイムを設定します。メニューバーの'Runtime'をクリックし、'Change runtime type'を選択する。ハードウェアアクセラレータ」のドロップダウンから「GPU」を選択します。変更を保存します。これでセッションにGPUが割り当てられ、処理タスクが加速されます。
ステップ3:必要なライブラリのインストール
次に、pipを使用して必要なPythonライブラリをインストールします。openai、openai-whisper、pytube、langchainなどです。以下のコードをColabセルで実行する:
pip install openai!pip install -U openai-whisper!pip install pytube!pip install langchain
セルを実行してライブラリをインストールします。次に進む前に、インストールが正常に完了したことを確認してください。
ステップ 4: ライブラリのインポートと OpenAI API キーの設定
必要なライブラリをノートブックにインポートします。また、言語モデルへのアクセスを有効にするために、OpenAI APIキーを設定します。APIキーはOpenAIプラットフォームで生成できます。コード中のYOUR_API_KEYは実際のキーに置き換えてください。
import pytube as ptimport whisperfrom langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitteropenai_api_key = "YOUR_API_KEY"
ステップ5:YouTubeビデオの読み込みと音声の抽出
YouTubeビデオのURLを指定し、pytubeを使って音声を抽出します。以下のコードは、YouTubeオブジェクトを作成し、音声のみのストリームをフィルタリングし、音声をMP3ファイルとしてダウンロードします:
yt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
ステップ 6: Whisperを使って音声を書き起こす
ダウンロードした音声ファイルをWhisperモデルを使ってテキストに書き起こします。モデルをロードして、それを使って音声を書き起こします:
model = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
ステップ 7: Langchainを使ってテキストを要約する
Langchainを使って書き起こしたテキストを要約します。これは、テキストをチャンクに分割し、そこからドキュメントを作成し、要約チェーンを使って最終的な要約を生成する。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=[", "", ". ", ""])texts = text_splitter.split_text(text)from langchain.document_loaders import TextLoaderfrom langchain.docstore.document import Documentdocs = [Document(page_content=t) for t in texts]llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key, temperature=0)chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)output_summary = chain.run(docs)print(output_summary)
このコードは、テキストを分割し、ドキュメントを作成し、要約チェーンを初期化し、要約を作成するために実行する。
ステップ8: コードの実行とサマリーの取得
Colabノートブックのすべてのコードセルを実行する。これにより、音声のダウンロードから最終的な要約の生成まで、要約パイプライン全体が実行される。結果の要約はコンソールに表示されます。
Langchain、OpenAI、Whisperの価格に関する考察
コストを理解する
Langchain、OpenAI、Whisperを使用する場合、予算を効果的に管理するために、それぞれの価格モデルを理解することが重要です。
- OpenAI API:OpenAIはトークンの使用量に応じて課金されます。コストはモデル(例:text-davinci-003)と処理されるトークンの数によって異なります。価格は通常1,000トークンあたりなので、使用量を監視することがコストをコントロールする鍵になります。
- ウィスパーWhisperはOpenAIを通じてAPIとして利用することも、自分でホストすることもできる。OpenAI APIを使用する場合、トランスクリプションのコストは音声の長さに依存する。
- Langchain:オープンソースのフレームワークであるLangchain自体は無料です。しかし、Langchainを通して使用するOpenAI APIなど、統合されたサービスのコストを考慮する必要があります。
Langchainベースのビデオ要約の利点と欠点
長所
自動化により、手作業による要約に比べ、かなりの時間を節約できる。
動画の要点を捉えた簡潔な要約を生成。
カスタマイズ可能な設定により、ニーズに合わせて要約を調整できる。
強力なOpenAI言語モデルとのシームレスな統合。
オープンソースであるため、柔軟性とコミュニティ主導のサポートを提供する。
短所
セットアップと設定には基本的なプログラミング知識が必要。
要約の精度は、音声書き起こしの品質と言語モデルに依存する可能性がある。
OpenAI APIを使用するためのコストがかかる。
書き起こしや要約中にエラーや不正確さが発生する可能性がある。
元のビデオの微妙なニュアンスや文脈を全て把握できない可能性がある。
動画要約用Langchainの主な特徴
Langchainの機能の活用
Langchainは動画要約をより効率的にするいくつかの機能を提供します:
- チェーンの抽象化:チェインの抽象化:チェインを構築する標準的な方法を提供し、言語モデルやテキストスプリッターのような異なるコンポーネントを簡単に結合し、まとまりのあるワークフローを実現します。
- テキスト分割:段落や文などの指定された区切り文字に基づいてテキストを分割する
RecursiveCharacterTextSplitterなど、テキストを分割するためのさまざまなメソッドが含まれています。 - 要約チェーン:
load_summarize_chainのような、大規模なドキュメントを効率的に要約するためにmap_reduceのようなテクニックを使用するビルド済みのチェーンを提供します。
自動ビデオ要約の多様な使用例
さまざまな分野での応用
自動動画要約は、様々な分野で数多くの実用的な用途がある:
- 教育:学生や教師は講義ビデオを素早くレビューし、重要なアイデアを抽出し、学習ガイドを作成することができる。
- 研究:研究者はビデオコンテンツを効率的に分析し、関連データを抽出し、パターンを特定することができます。
- ビジネス:プロフェッショナルは、業界のトレンド情報を入手し、競合他社のコンテンツを分析し、サマリーレポートを作成できます。
- メディアモニタリング:ニュース放送を追跡し、世論を分析し、新たなストーリーを特定することができます。
よくある質問
Langchainとは何ですか?また、どのようにしてビデオの要約を容易にするのですか?
Langchainは、言語モデルを使ったアプリケーションの構築を簡素化するために設計されたフレームワークです。操作の連鎖を作るための標準インターフェースを提供します。ビデオ要約の場合、Langchainは、書き起こされたテキストの処理から最終的な要約の生成まで、プロセス全体の管理をサポートし、柔軟で強力なツールとなります。
OpenAIのAPIキーはどのように取得できますか?また、なぜ動画要約に必要なのですか?
OpenAI APIキーは、テキスト要約用のOpenAIの言語モデルを認証して使用するために必要です。APIキーは、OpenAIのプラットフォームにサインアップし、アカウント設定でキーを生成することで取得できます。このキーによって、あなたのスクリプトは要約を行うモデルにアクセスできるようになります。
Langchain、OpenAI、Whisperを使用する際のコスト管理上の注意点は何ですか?
コストを効果的に管理するために、OpenAI APIのトークン使用量に注意してください。適切なテキストチャンクサイズを使用してコードを最適化し、単純なタスクにはより安価なモデルを使用することを検討してください。Whisperについては、APIを使用する場合、コストはオーディオの長さに基づいているため、より短いクリップを処理するか、セルフホスティングバージョンを使用することで、費用をコントロールすることができます。
さらに詳しく関連する質問と高度なテクニック
Langchainを使った動画要約の精度を上げるにはどうすればいいですか?
要約の精度を上げるには、いくつかのパラメータやテクニックを調整する必要があります。以下の戦略を検討してください:様々なテキストスプリッターを試す:文字テキストスプリッター:再帰的文字テキスト分割:文字に基づいてテキストを分割します:トークン テキスト スプリッター:トークンに基づいてテキストを分割します:チャンクサイズとオーバーラップの調整:チャンクサイズ:テキストセグメントのサイズは、要約に影響します。チャンクの大きさ:テキストセグメントの大きさは、要約に影響します。チャンクが小さいと、より詳細な要約が得られ、チャンクが大きいと、より多くの文脈が得られます:チャンクの重なり:チャンク間の重なりは文脈の流れを維持するのに役立つ。最適なバランスを見つけるために、さまざまなサイズや重なりを試してみてください。より強力な言語モデルを選択:OpenAIは、以下のようなさまざまなモデルを提供しています。










 Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
 WordPress.comでは、AIエージェントによる投稿の作成や公開が可能になりました。その他にもさまざまな機能が追加されています。
人気のウェブホスティング・パブリッシングプラットフォームであるWordPress.comが、AIエージェントの導入に乗り出した。この動きは、ウェブのあり方を一変させる可能性がある。同社は金曜日、AIエージェントが顧客のウェブサイト上でコンテンツの下書き作成、編集、公開を行うほか、コメントの管理、メタデータの更新・修正、タグやカテゴリを用いたコンテンツの整理も可能になると発表した。これらすべての操作
WordPress.comでは、AIエージェントによる投稿の作成や公開が可能になりました。その他にもさまざまな機能が追加されています。
人気のウェブホスティング・パブリッシングプラットフォームであるWordPress.comが、AIエージェントの導入に乗り出した。この動きは、ウェブのあり方を一変させる可能性がある。同社は金曜日、AIエージェントが顧客のウェブサイト上でコンテンツの下書き作成、編集、公開を行うほか、コメントの管理、メタデータの更新・修正、タグやカテゴリを用いたコンテンツの整理も可能になると発表した。これらすべての操作

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

這篇教學太實用了!我常常需要看很多英文教學影片,如果能自動生成摘要真的會省下超多時間。不過我有點擔心,如果AI摘要漏掉重要細節怎麼辦?大家會完全依賴這個功能嗎?🤔













