
















 Дом
ДомСамоучитель Langchain: Руководство по обобщению видеороликов YouTube
В нашем быстро меняющемся цифровом мире возможность быстро понять суть видеоролика невероятно ценна. Для исследователей, студентов и профессионалов создание кратких резюме длинных видеороликов на YouTube может стать серьезной экономией времени и повышением производительности. Это руководство предлагает четкий пошаговый метод использования Langchain, OpenAI и Whisper для автоматического создания резюме контента YouTube. Вы узнаете, как писать скрипты на Python в Google Colab для извлечения аудио, транскрибирования его в текст и последующего сжатия с помощью мощных моделей искусственного интеллекта.
Ключевые моменты
Узнайте, как использовать Langchain, OpenAI и Whisper для автоматического обобщения видео.
Напишем код на Python в Google Colab для загрузки и расшифровки аудиозаписей.
Применять методы разбиения и обобщения текста для создания кратких обзоров.
Реализуйте метод цепочки map reduce для эффективного обобщения больших документов.
Использовать API OpenAI для доступа к продвинутым моделям обобщения.
Используйте RecursiveCharacterTextSplitter для разделения текста на более мелкие и удобные фрагменты.
Настройка среды для обобщения видео
Начало работы с Google Colab
Прежде всего, убедитесь, что у вас есть аккаунт Google, чтобы получить доступ к Google Colab - бесплатной облачной платформе, идеально подходящей для выполнения кода на Python. Откройте Google Colab и создайте новый блокнот. Это будет ваше рабочее пространство для проекта по обобщению видео. Переименуйте блокнот во что-нибудь запоминающееся, например "YouTube_Summarizer", чтобы не запутаться.
Далее настройте конфигурацию времени выполнения.
Перейдите в меню 'Runtime' и выберите 'Change runtime type'. Из выпадающего списка выберите 'T4 GPU' в качестве аппаратного ускорителя. Этот выбор использует вычислительную мощность GPU для ускорения выполнения кода. Сохраните настройки, чтобы применить их к среде Colab. Теперь вы готовы к установке необходимых пакетов.
Установка основных пакетов Python
Перед написанием кода необходимо установить необходимые библиотеки Python. Эти пакеты предоставляют инструменты для извлечения, транскрипции и обобщения аудио. Выполните следующие команды в ячейке Colab с помощью pip install:
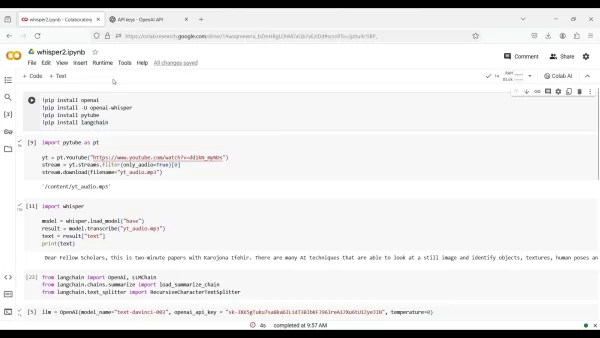
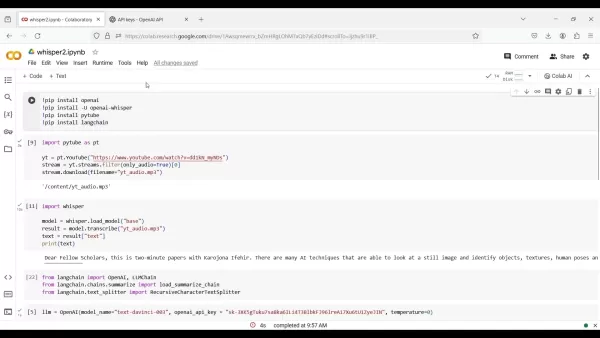
! pip install OpenAI!pip install -U openai-whisper!pip install pytube!pip install langchain
- OpenAI: Эта библиотека позволяет взаимодействовать с языковыми моделями OpenAI, которые очень важны для резюмирования текста.
- Whisper: Система автоматического распознавания речи (ASR) OpenAI, используемая для преобразования аудио в текст.
- Pytube: Библиотека для загрузки аудио непосредственно из видеороликов YouTube.
- Langchain: Мощный фреймворк, предоставляющий стандартный интерфейс для цепочек и других инструментов, упрощающий процесс создания приложений с языковыми моделями.
Эти команды установят библиотеки OpenAI, Whisper, Pytube и Langchain, предоставив вам все инструменты, необходимые для выполнения следующих шагов. После завершения установки вы сможете импортировать эти пакеты в свой скрипт.
Извлечение звука из видеороликов YouTube
Импорт Pytube и загрузка видео
Начните с импорта библиотеки pytube, которая позволяет загружать аудио с YouTube. После импорта укажите URL-адрес видеоролика YouTube, который вы хотите обработать.

Следующий код показывает, как это сделать:
import pytube as ptyt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
Этот код создает объект YouTube по указанному URL-адресу, фильтрует доступные потоки, выбирая вариант только аудио, и загружает его в виде MP3-файла с именем yt_audio.mp3. Этот файл будет использован для транскрипции на следующем этапе.
Транскрибация аудио с помощью Whisper
Когда аудиофайл загружен, следующим шагом будет преобразование его в текст с помощью модели Whisper от OpenAI. Whisper - это надежный инструмент для преобразования речи в текст, доступный через библиотеку openai-whisper, которую вы установили ранее. Вот как расшифровать аудиозапись:
import whispermodel = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)

Этот код загружает базовую модель Whisper, транскрибирует файл yt_audio.mp3 и извлекает полученный текст. Транскрибированный текст выводится в консоль, предоставляя вам письменную версию аудиоконтента видео. Теперь, когда текст готов, можно приступить к его резюмированию с помощью Langchain.
Резюмирование расшифрованного текста с помощью Langchain
Теперь, когда у вас есть расшифрованный текст, вы можете использовать Langchain для создания резюме. Langchain предоставляет гибкую основу для резюмирования текста с помощью языковых моделей OpenAI. Этот процесс включает в себя разбиение текста на более мелкие сегменты и резюмирование каждого из них для получения окончательного, краткого обзора.
Выполните следующие шаги, чтобы настроить процесс обобщения с помощью Langchain:
Импортируйте необходимые модули из Langchain:
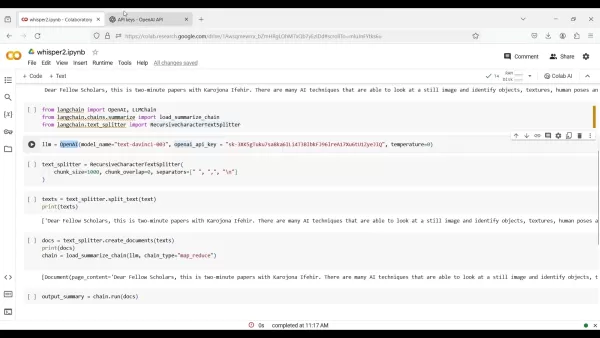
Сюда входят модули для интеграции OpenAI, LLM-цепочек, резюмирования и разбиения текста.
from langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitter
Инициализируйте языковую модель OpenAI:
llm = OpenAI(model_name="text-davinci-003", openai_api_key="YOUR_API_KEY", temperature=0)
Замените YOUR_API_KEY на ваш реальный API-ключ OpenAI, который вы можете получить на платформе OpenAI.
Разделите транскрибированный текст на удобные куски:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=["
", "", ". ", " ", ""])texts = text_splitter.split_text(text)
Этот код делит текст на сегменты по 1000 символов каждый, без перекрытия. Параметр `separators` обеспечивает разбиение текста на естественные разрывы, такие как абзацы и предложения.4.**Создание объектов документов из фрагментов текста**:``pythondocs = [Document(page_content=t) for t in texts]
Загрузите цепочку резюмирования:
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)
Этот код инициализирует цепочку обобщения с помощью метода map_reduce. Этот подход эффективен для больших документов, поскольку он обобщает каждый фрагмент по отдельности (шаг map), а затем объединяет эти обобщения в итоговое резюме (шаг reduce).
Выполните цепочку суммирования:
output_summary = chain.run(docs)print(output_summary)
Это запустит процесс обобщения на фрагментах документов и выведет итоговое резюме. Теперь у вас есть краткое изложение содержания оригинального видео на YouTube.
Выполнив эти шаги, вы сможете эффективно обобщать видеоролики YouTube с помощью Langchain, OpenAI и Whisper, автоматизируя извлечение информации и повышая свою производительность.
Пошаговое руководство: Резюмирование видеороликов YouTube с помощью кода
Шаг 1: Откройте Google Colab и создайте новый блокнот
Откройте веб-браузер и перейдите на сайт Google Colab. Войдите в систему, используя свою учетную запись Google. Войдя в систему, создайте новый блокнот, нажав кнопку "Новый блокнот". Это откроет чистую среду кодирования для вашего проекта.

Шаг 2: Настройте параметры времени выполнения
Чтобы обеспечить оптимальную производительность, особенно для моделей искусственного интеллекта, настройте время выполнения на использование GPU. Нажмите на "Время выполнения" в строке меню, затем выберите "Изменить тип времени выполнения". В раскрывающемся списке "Аппаратный ускоритель" выберите "GPU". Сохраните изменения. Это выделит GPU для вашей сессии, ускорив выполнение задач обработки.
Шаг 3: Установка необходимых библиотек
Далее установите необходимые библиотеки Python с помощью pip. К ним относятся openai, openai-whisper, pytube и langchain. Выполните следующий код в ячейке Colab:
!pip install openai!pip install -U openai-whisper!pip install pytube!pip install langchain
Выполните ячейку для установки библиотек. Убедитесь в успешном завершении установки, прежде чем двигаться дальше.
Шаг 4: Импорт библиотек и настройка API-ключа OpenAI
Импортируйте необходимые библиотеки в ноутбук. Также установите ключ OpenAI API, чтобы получить доступ к языковым моделям. Вы можете сгенерировать API-ключ на платформе OpenAI. Замените в коде YOUR_API_KEY на ваш реальный ключ.
import pytube as ptimport whisperfrom langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitteropenai_api_key = "YOUR_API_KEY"
Шаг 5: Загрузка видео с YouTube и извлечение аудио
Укажите URL-адрес видео на YouTube и используйте pytube для извлечения аудио. Приведенный ниже код создает объект YouTube, фильтрует потоки, предназначенные только для аудио, и загружает аудио в виде MP3-файла:
yt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
Шаг 6: Транскрибируйте аудио с помощью Whisper
Расшифруйте загруженный аудиофайл в текст с помощью модели Whisper. Загрузите модель и используйте ее для транскрибирования аудио:
model = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
Шаг 7: Обобщение текста с помощью Langchain
Обобщите транскрибированный текст с помощью Langchain. Это включает в себя разбиение текста на фрагменты, создание документов из них и использование цепочки обобщения для создания окончательного резюме.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=["", "", ". ", "", ""])texts = text_splitter.split_text(text)from langchain.document_loaders import TextLoaderfrom langchain.docstore.document import Documentdocs = [Document(page_content=t) for t in texts]llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key, temperature=0)chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)output_summary = chain.run(docs)print(output_summary)
Этот код разбивает текст, создает документы, инициализирует цепочку обобщения и запускает ее для получения сводки.
Шаг 8: Выполните код и получите сводку
Выполните все ячейки кода в блокноте Colab. В результате будет запущен весь цикл обобщения, от загрузки аудио до создания итогового резюме. Полученная сводка будет отображена в консоли.
Ценообразование для Langchain, OpenAI и Whisper
Понимание затрат
При использовании Langchain, OpenAI и Whisper важно понимать их соответствующие ценовые модели, чтобы эффективно управлять бюджетом.
- API OpenAI: OpenAI взимает плату за использование токенов. Стоимость варьируется в зависимости от модели (например, text-davinci-003) и количества обрабатываемых токенов. Обычно цены устанавливаются за 1 000 токенов, поэтому мониторинг использования является ключевым фактором для контроля расходов.
- Whisper: Вы можете использовать Whisper в качестве API через OpenAI или разместить его самостоятельно. При использовании API OpenAI стоимость транскрипции зависит от продолжительности аудио.
- Langchain: Будучи фреймворком с открытым исходным кодом, Langchain сам по себе бесплатен. Однако вы должны учитывать стоимость интегрированных сервисов, таких как API OpenAI, которые вы используете через него.
Преимущества и недостатки обобщения видео на основе Langchain
Плюсы
Автоматизация позволяет сэкономить значительное количество времени по сравнению с ручным подведением итогов.
Генерируются краткие резюме, отражающие основные моменты видео.
Настраиваемые параметры позволяют адаптировать резюме к вашим потребностям.
Бесшовная интеграция с мощными языковыми моделями OpenAI.
Открытый исходный код обеспечивает гибкость и поддержку со стороны сообщества.
Минусы
Требуются базовые знания программирования для установки и настройки.
Точность резюме может зависеть от качества транскрипции аудио и языковой модели.
Использование API OpenAI связано с расходами.
Возможны ошибки и неточности при транскрибировании и составлении резюме.
Может не передать все тонкие нюансы и контекст исходного видео.
Ключевые особенности Langchain для обобщения видео
Использование возможностей Langchain
Langchain предлагает несколько функций, которые делают обобщение видео более эффективным:
- Абстракция цепочек: Обеспечивает стандартизированный способ построения цепочек, позволяя легко объединять различные компоненты, такие как языковые модели и устройства разделения текста, в единый рабочий процесс.
- Разделение текста: Включает различные методы разделения текста, такие как
RecursiveCharacterTextSplitter, который разделяет текст на основе заданных разделителей, таких как абзацы и предложения. - Цепочки суммирования: Предлагает готовые цепочки, например
load_summarize_chain, которые используют такие методы, как map_reduce, для эффективного обобщения больших документов.
Разнообразные сценарии использования автоматизированного суммирования видео
Применение в различных областях
Автоматизированное обобщение видео имеет множество практических применений в различных областях:
- Образование: Студенты и преподаватели могут быстро просматривать видеозаписи лекций, извлекать ключевые идеи и создавать учебные пособия.
- Исследования: Исследователи могут эффективно анализировать видеоконтент, извлекать необходимые данные и выявлять закономерности.
- Бизнес: Профессионалы могут быть в курсе отраслевых тенденций, анализировать контент конкурентов и создавать сводные отчеты.
- Мониторинг СМИ: Агентства могут отслеживать новостные выпуски, анализировать общественное мнение и выявлять новые сюжеты.
Часто задаваемые вопросы
Что такое Langchain и как он помогает обобщать видео?
Langchain - это фреймворк, предназначенный для упрощения создания приложений с языковыми моделями. Он предоставляет стандартный интерфейс для создания цепочек операций. При резюмировании видео Langchain помогает управлять всем процессом - от обработки транскрибированного текста до создания итогового резюме, что делает его гибким и мощным инструментом.
Как получить ключ API OpenAI и почему он необходим для обобщения видео?
Ключ API OpenAI необходим для аутентификации и использования языковых моделей OpenAI для обобщения текста. Вы можете получить API-ключ, зарегистрировавшись на платформе OpenAI и сгенерировав ключ в настройках аккаунта. Этот ключ позволяет вашему скрипту получить доступ к моделям, которые обеспечивают обобщение.
Каковы ключевые соображения по управлению расходами при использовании Langchain, OpenAI и Whisper?
Чтобы эффективно управлять расходами, следите за использованием токена для API OpenAI, поскольку биллинг основан на потреблении. Оптимизируйте свой код, используя соответствующие размеры текстовых чанков, и рассмотрите возможность использования менее дорогих моделей для более простых задач. Для Whisper, если используется API, стоимость зависит от длины аудио, поэтому обработка коротких клипов или использование самостоятельной версии может помочь контролировать расходы.
Смотрите далее: Похожие вопросы и Дополнительные методы
Как повысить точность обобщения видео с помощью Langchain?
Повышение точности обобщения предполагает настройку нескольких параметров и методов. Рассмотрим эти стратегии:Экспериментируйте с различными разделителями текста:Разделитель текста по символам: Разделяет текст на основе символов, что помогает сохранить структуру предложения.Recursive Character Text Splitter: Рекурсивно разделяет текст, используя список разделителей, что позволяет выполнить более интеллектуальное разделение.Token Text Splitter: Разделяет текст на основе лексем, что позволяет сохранить смысл.Протестируйте различные разделители, чтобы понять, какой из них лучше всего подходит для вашего конкретного видеоконтента.Настройте размер фрагмента и перекрытие:Размер фрагмента: Размер сегментов текста влияет на итоговый результат. Маленькие фрагменты могут дать более подробное резюме, а большие фрагменты - больше контекста.Перекрытие фрагментов: Перекрытие между фрагментами может помочь сохранить контекстный поток. Экспериментируйте с различными размерами и перекрытиями, чтобы найти оптимальный баланс.Выберите более мощную языковую модель:OpenAI предлагает различные модели с
Связанная статья
 Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Сегодня стартует первый сериал Yaoke Media, созданный с помощью технологий AIGC, — «Тайна бронзы в Циньлине» с главными героями, нарисованными искусственным интеллектом
Сегодня состоялся официальный запуск короткометражного фэнтезийного детективного сериала «Тайная история бронзы Циньлин» от Yaoke Media. В главных ролях — первые два подписанных компанией ИИ-актера, Ц
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
Рекомендации по связанным специальным темам
Бизнес
Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Сегодня стартует первый сериал Yaoke Media, созданный с помощью технологий AIGC, — «Тайна бронзы в Циньлине» с главными героями, нарисованными искусственным интеллектом
Сегодня состоялся официальный запуск короткометражного фэнтезийного детективного сериала «Тайная история бронзы Циньлин» от Yaoke Media. В главных ролях — первые два подписанных компанией ИИ-актера, Ц
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
Рекомендации по связанным специальным темам
Бизнес
 Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
 10 инструментов
10 инструментов
 xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие тренажеры по флирту и общению на базе ИИ: повышайте свою харизму и уверенность в себе в режиме реального времени
Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

 Комментарии (1)
Комментарии (1)
![HenryLopez]()
這篇教學太實用了!我常常需要看很多英文教學影片,如果能自動生成摘要真的會省下超多時間。不過我有點擔心,如果AI摘要漏掉重要細節怎麼辦?大家會完全依賴這個功能嗎?🤔
В нашем быстро меняющемся цифровом мире возможность быстро понять суть видеоролика невероятно ценна. Для исследователей, студентов и профессионалов создание кратких резюме длинных видеороликов на YouTube может стать серьезной экономией времени и повышением производительности. Это руководство предлагает четкий пошаговый метод использования Langchain, OpenAI и Whisper для автоматического создания резюме контента YouTube. Вы узнаете, как писать скрипты на Python в Google Colab для извлечения аудио, транскрибирования его в текст и последующего сжатия с помощью мощных моделей искусственного интеллекта.
Ключевые моменты
Узнайте, как использовать Langchain, OpenAI и Whisper для автоматического обобщения видео.
Напишем код на Python в Google Colab для загрузки и расшифровки аудиозаписей.
Применять методы разбиения и обобщения текста для создания кратких обзоров.
Реализуйте метод цепочки map reduce для эффективного обобщения больших документов.
Использовать API OpenAI для доступа к продвинутым моделям обобщения.
Используйте RecursiveCharacterTextSplitter для разделения текста на более мелкие и удобные фрагменты.
Настройка среды для обобщения видео
Начало работы с Google Colab
Прежде всего, убедитесь, что у вас есть аккаунт Google, чтобы получить доступ к Google Colab - бесплатной облачной платформе, идеально подходящей для выполнения кода на Python. Откройте Google Colab и создайте новый блокнот. Это будет ваше рабочее пространство для проекта по обобщению видео. Переименуйте блокнот во что-нибудь запоминающееся, например "YouTube_Summarizer", чтобы не запутаться.
Далее настройте конфигурацию времени выполнения.
Перейдите в меню 'Runtime' и выберите 'Change runtime type'. Из выпадающего списка выберите 'T4 GPU' в качестве аппаратного ускорителя. Этот выбор использует вычислительную мощность GPU для ускорения выполнения кода. Сохраните настройки, чтобы применить их к среде Colab. Теперь вы готовы к установке необходимых пакетов.
Установка основных пакетов Python
Перед написанием кода необходимо установить необходимые библиотеки Python. Эти пакеты предоставляют инструменты для извлечения, транскрипции и обобщения аудио. Выполните следующие команды в ячейке Colab с помощью pip install:
! pip install OpenAI!pip install -U openai-whisper!pip install pytube!pip install langchain
- OpenAI: Эта библиотека позволяет взаимодействовать с языковыми моделями OpenAI, которые очень важны для резюмирования текста.
- Whisper: Система автоматического распознавания речи (ASR) OpenAI, используемая для преобразования аудио в текст.
- Pytube: Библиотека для загрузки аудио непосредственно из видеороликов YouTube.
- Langchain: Мощный фреймворк, предоставляющий стандартный интерфейс для цепочек и других инструментов, упрощающий процесс создания приложений с языковыми моделями.
Эти команды установят библиотеки OpenAI, Whisper, Pytube и Langchain, предоставив вам все инструменты, необходимые для выполнения следующих шагов. После завершения установки вы сможете импортировать эти пакеты в свой скрипт.
Извлечение звука из видеороликов YouTube
Импорт Pytube и загрузка видео
Начните с импорта библиотеки pytube, которая позволяет загружать аудио с YouTube. После импорта укажите URL-адрес видеоролика YouTube, который вы хотите обработать.
Следующий код показывает, как это сделать:
import pytube as ptyt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
Этот код создает объект YouTube по указанному URL-адресу, фильтрует доступные потоки, выбирая вариант только аудио, и загружает его в виде MP3-файла с именем yt_audio.mp3. Этот файл будет использован для транскрипции на следующем этапе.
Транскрибация аудио с помощью Whisper
Когда аудиофайл загружен, следующим шагом будет преобразование его в текст с помощью модели Whisper от OpenAI. Whisper - это надежный инструмент для преобразования речи в текст, доступный через библиотеку openai-whisper, которую вы установили ранее. Вот как расшифровать аудиозапись:
import whispermodel = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
Этот код загружает базовую модель Whisper, транскрибирует файл yt_audio.mp3 и извлекает полученный текст. Транскрибированный текст выводится в консоль, предоставляя вам письменную версию аудиоконтента видео. Теперь, когда текст готов, можно приступить к его резюмированию с помощью Langchain.
Резюмирование расшифрованного текста с помощью Langchain
Теперь, когда у вас есть расшифрованный текст, вы можете использовать Langchain для создания резюме. Langchain предоставляет гибкую основу для резюмирования текста с помощью языковых моделей OpenAI. Этот процесс включает в себя разбиение текста на более мелкие сегменты и резюмирование каждого из них для получения окончательного, краткого обзора.
Выполните следующие шаги, чтобы настроить процесс обобщения с помощью Langchain:
Импортируйте необходимые модули из Langchain:
Сюда входят модули для интеграции OpenAI, LLM-цепочек, резюмирования и разбиения текста.
from langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitterИнициализируйте языковую модель OpenAI:
llm = OpenAI(model_name="text-davinci-003", openai_api_key="YOUR_API_KEY", temperature=0)Замените
YOUR_API_KEYна ваш реальный API-ключ OpenAI, который вы можете получить на платформе OpenAI.Разделите транскрибированный текст на удобные куски:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=["
", "", ". ", " ", ""])texts = text_splitter.split_text(text)
Этот код делит текст на сегменты по 1000 символов каждый, без перекрытия. Параметр `separators` обеспечивает разбиение текста на естественные разрывы, такие как абзацы и предложения.4.**Создание объектов документов из фрагментов текста**:``pythondocs = [Document(page_content=t) for t in texts]
Загрузите цепочку резюмирования:
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)Этот код инициализирует цепочку обобщения с помощью метода
map_reduce. Этот подход эффективен для больших документов, поскольку он обобщает каждый фрагмент по отдельности (шаг map), а затем объединяет эти обобщения в итоговое резюме (шаг reduce).Выполните цепочку суммирования:
output_summary = chain.run(docs)print(output_summary)Это запустит процесс обобщения на фрагментах документов и выведет итоговое резюме. Теперь у вас есть краткое изложение содержания оригинального видео на YouTube.
Выполнив эти шаги, вы сможете эффективно обобщать видеоролики YouTube с помощью Langchain, OpenAI и Whisper, автоматизируя извлечение информации и повышая свою производительность.
Пошаговое руководство: Резюмирование видеороликов YouTube с помощью кода
Шаг 1: Откройте Google Colab и создайте новый блокнот
Откройте веб-браузер и перейдите на сайт Google Colab. Войдите в систему, используя свою учетную запись Google. Войдя в систему, создайте новый блокнот, нажав кнопку "Новый блокнот". Это откроет чистую среду кодирования для вашего проекта.
Шаг 2: Настройте параметры времени выполнения
Чтобы обеспечить оптимальную производительность, особенно для моделей искусственного интеллекта, настройте время выполнения на использование GPU. Нажмите на "Время выполнения" в строке меню, затем выберите "Изменить тип времени выполнения". В раскрывающемся списке "Аппаратный ускоритель" выберите "GPU". Сохраните изменения. Это выделит GPU для вашей сессии, ускорив выполнение задач обработки.
Шаг 3: Установка необходимых библиотек
Далее установите необходимые библиотеки Python с помощью pip. К ним относятся openai, openai-whisper, pytube и langchain. Выполните следующий код в ячейке Colab:
!pip install openai!pip install -U openai-whisper!pip install pytube!pip install langchain
Выполните ячейку для установки библиотек. Убедитесь в успешном завершении установки, прежде чем двигаться дальше.
Шаг 4: Импорт библиотек и настройка API-ключа OpenAI
Импортируйте необходимые библиотеки в ноутбук. Также установите ключ OpenAI API, чтобы получить доступ к языковым моделям. Вы можете сгенерировать API-ключ на платформе OpenAI. Замените в коде YOUR_API_KEY на ваш реальный ключ.
import pytube as ptimport whisperfrom langchain import OpenAI, LLMChainfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitteropenai_api_key = "YOUR_API_KEY"
Шаг 5: Загрузка видео с YouTube и извлечение аудио
Укажите URL-адрес видео на YouTube и используйте pytube для извлечения аудио. Приведенный ниже код создает объект YouTube, фильтрует потоки, предназначенные только для аудио, и загружает аудио в виде MP3-файла:
yt = pt.YouTube("https://www.youtube.com/watch?v=dd1kN_myNDs")stream = yt.streams.filter(only_audio=True)[0]stream.download(filename='yt_audio.mp3')
Шаг 6: Транскрибируйте аудио с помощью Whisper
Расшифруйте загруженный аудиофайл в текст с помощью модели Whisper. Загрузите модель и используйте ее для транскрибирования аудио:
model = whisper.load_model("base")result = model.transcribe("yt_audio.mp3")text = result["text"]print(text)
Шаг 7: Обобщение текста с помощью Langchain
Обобщите транскрибированный текст с помощью Langchain. Это включает в себя разбиение текста на фрагменты, создание документов из них и использование цепочки обобщения для создания окончательного резюме.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=["", "", ". ", "", ""])texts = text_splitter.split_text(text)from langchain.document_loaders import TextLoaderfrom langchain.docstore.document import Documentdocs = [Document(page_content=t) for t in texts]llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key, temperature=0)chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)output_summary = chain.run(docs)print(output_summary)
Этот код разбивает текст, создает документы, инициализирует цепочку обобщения и запускает ее для получения сводки.
Шаг 8: Выполните код и получите сводку
Выполните все ячейки кода в блокноте Colab. В результате будет запущен весь цикл обобщения, от загрузки аудио до создания итогового резюме. Полученная сводка будет отображена в консоли.
Ценообразование для Langchain, OpenAI и Whisper
Понимание затрат
При использовании Langchain, OpenAI и Whisper важно понимать их соответствующие ценовые модели, чтобы эффективно управлять бюджетом.
- API OpenAI: OpenAI взимает плату за использование токенов. Стоимость варьируется в зависимости от модели (например, text-davinci-003) и количества обрабатываемых токенов. Обычно цены устанавливаются за 1 000 токенов, поэтому мониторинг использования является ключевым фактором для контроля расходов.
- Whisper: Вы можете использовать Whisper в качестве API через OpenAI или разместить его самостоятельно. При использовании API OpenAI стоимость транскрипции зависит от продолжительности аудио.
- Langchain: Будучи фреймворком с открытым исходным кодом, Langchain сам по себе бесплатен. Однако вы должны учитывать стоимость интегрированных сервисов, таких как API OpenAI, которые вы используете через него.
Преимущества и недостатки обобщения видео на основе Langchain
Плюсы
Автоматизация позволяет сэкономить значительное количество времени по сравнению с ручным подведением итогов.
Генерируются краткие резюме, отражающие основные моменты видео.
Настраиваемые параметры позволяют адаптировать резюме к вашим потребностям.
Бесшовная интеграция с мощными языковыми моделями OpenAI.
Открытый исходный код обеспечивает гибкость и поддержку со стороны сообщества.
Минусы
Требуются базовые знания программирования для установки и настройки.
Точность резюме может зависеть от качества транскрипции аудио и языковой модели.
Использование API OpenAI связано с расходами.
Возможны ошибки и неточности при транскрибировании и составлении резюме.
Может не передать все тонкие нюансы и контекст исходного видео.
Ключевые особенности Langchain для обобщения видео
Использование возможностей Langchain
Langchain предлагает несколько функций, которые делают обобщение видео более эффективным:
- Абстракция цепочек: Обеспечивает стандартизированный способ построения цепочек, позволяя легко объединять различные компоненты, такие как языковые модели и устройства разделения текста, в единый рабочий процесс.
- Разделение текста: Включает различные методы разделения текста, такие как
RecursiveCharacterTextSplitter, который разделяет текст на основе заданных разделителей, таких как абзацы и предложения. - Цепочки суммирования: Предлагает готовые цепочки, например
load_summarize_chain, которые используют такие методы, какmap_reduce, для эффективного обобщения больших документов.
Разнообразные сценарии использования автоматизированного суммирования видео
Применение в различных областях
Автоматизированное обобщение видео имеет множество практических применений в различных областях:
- Образование: Студенты и преподаватели могут быстро просматривать видеозаписи лекций, извлекать ключевые идеи и создавать учебные пособия.
- Исследования: Исследователи могут эффективно анализировать видеоконтент, извлекать необходимые данные и выявлять закономерности.
- Бизнес: Профессионалы могут быть в курсе отраслевых тенденций, анализировать контент конкурентов и создавать сводные отчеты.
- Мониторинг СМИ: Агентства могут отслеживать новостные выпуски, анализировать общественное мнение и выявлять новые сюжеты.
Часто задаваемые вопросы
Что такое Langchain и как он помогает обобщать видео?
Langchain - это фреймворк, предназначенный для упрощения создания приложений с языковыми моделями. Он предоставляет стандартный интерфейс для создания цепочек операций. При резюмировании видео Langchain помогает управлять всем процессом - от обработки транскрибированного текста до создания итогового резюме, что делает его гибким и мощным инструментом.
Как получить ключ API OpenAI и почему он необходим для обобщения видео?
Ключ API OpenAI необходим для аутентификации и использования языковых моделей OpenAI для обобщения текста. Вы можете получить API-ключ, зарегистрировавшись на платформе OpenAI и сгенерировав ключ в настройках аккаунта. Этот ключ позволяет вашему скрипту получить доступ к моделям, которые обеспечивают обобщение.
Каковы ключевые соображения по управлению расходами при использовании Langchain, OpenAI и Whisper?
Чтобы эффективно управлять расходами, следите за использованием токена для API OpenAI, поскольку биллинг основан на потреблении. Оптимизируйте свой код, используя соответствующие размеры текстовых чанков, и рассмотрите возможность использования менее дорогих моделей для более простых задач. Для Whisper, если используется API, стоимость зависит от длины аудио, поэтому обработка коротких клипов или использование самостоятельной версии может помочь контролировать расходы.
Смотрите далее: Похожие вопросы и Дополнительные методы
Как повысить точность обобщения видео с помощью Langchain?
Повышение точности обобщения предполагает настройку нескольких параметров и методов. Рассмотрим эти стратегии:Экспериментируйте с различными разделителями текста:Разделитель текста по символам: Разделяет текст на основе символов, что помогает сохранить структуру предложения.Recursive Character Text Splitter: Рекурсивно разделяет текст, используя список разделителей, что позволяет выполнить более интеллектуальное разделение.Token Text Splitter: Разделяет текст на основе лексем, что позволяет сохранить смысл.Протестируйте различные разделители, чтобы понять, какой из них лучше всего подходит для вашего конкретного видеоконтента.Настройте размер фрагмента и перекрытие:Размер фрагмента: Размер сегментов текста влияет на итоговый результат. Маленькие фрагменты могут дать более подробное резюме, а большие фрагменты - больше контекста.Перекрытие фрагментов: Перекрытие между фрагментами может помочь сохранить контекстный поток. Экспериментируйте с различными размерами и перекрытиями, чтобы найти оптимальный баланс.Выберите более мощную языковую модель:OpenAI предлагает различные модели с










 Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
 Сегодня стартует первый сериал Yaoke Media, созданный с помощью технологий AIGC, — «Тайна бронзы в Циньлине» с главными героями, нарисованными искусственным интеллектом
Сегодня состоялся официальный запуск короткометражного фэнтезийного детективного сериала «Тайная история бронзы Циньлин» от Yaoke Media. В главных ролях — первые два подписанных компанией ИИ-актера, Ц
Сегодня стартует первый сериал Yaoke Media, созданный с помощью технологий AIGC, — «Тайна бронзы в Циньлине» с главными героями, нарисованными искусственным интеллектом
Сегодня состоялся официальный запуск короткометражного фэнтезийного детективного сериала «Тайная история бронзы Циньлин» от Yaoke Media. В главных ролях — первые два подписанных компанией ИИ-актера, Ц
 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

這篇教學太實用了!我常常需要看很多英文教學影片,如果能自動生成摘要真的會省下超多時間。不過我有點擔心,如果AI摘要漏掉重要細節怎麼辦?大家會完全依賴這個功能嗎?🤔













