
















 首頁
首頁如何輕鬆製作會唱歌的 AI 虛擬人偶:完整的新手指南
人工智慧正在徹底改變數位內容的創作,特別是透過人工智慧驅動的歌唱虛擬人偶,提供非常逼真的表演。透過 Hedra AI 等直覺式平台,任何人現在都可以製作客製化的數位表演者,並提供精準的口型同步 - 不需要專業技術。這套全面的教學將引導您完成製作引人入勝的 AI 聲音虛擬人偶的每個步驟,適用於行銷、教育、娛樂等領域。
重點
無障礙的虛擬人偶製作:現代平台透過友善的工作流程將數位表演者的開發民主化。
迅速的製作要點:詳細的文字描述可顯著影響虛擬人像的品質與逼真度。
音訊最佳化:高品質的聲音音軌可確保自然的嘴部動作與表情。
創意自訂:從動畫到逼真的角色,您可以嘗試各種不同的視覺風格。
多產業應用:這些工具可為行銷、教育、客戶服務和娛樂領域的內容創作者提供服務。
AI 歌唱虛擬人偶簡介
了解數位聲樂表演者
AI 歌唱虛擬人偶是合成媒體的一項突破,結合了電腦產生的影像與先進的語音同步技術。這些數位表演者一開始是以文字為基礎的角色描述,然後由 AI 轉換成可視化的表現。當搭配音軌 (無論是錄音或 AI 產生的) 時,精密的演算法會將虛擬人偶的臉部特徵製成動畫,以令人信服的精確度來搭配聲樂表演。
這項技術的多樣性為眾多應用打開了大門。行銷人員可以開發品牌虛擬代言人、教育工作者可以創造動畫導師、藝人可以製作虛擬樂團或數位影響力。Hedra AI 等平台可透過直覺式介面簡化製作過程,從概念到最終產品都能引導使用者,無須動畫專業知識。
超越傳統動畫的優勢
與傳統動畫技術相比,AI 驅動的虛擬人像創作提供了明顯的優勢:
- 時間效率:將製作時間從數週縮短至數小時
- 預算輕鬆:省去昂貴的動畫工作室成本
- 創意自由:快速迭代角色設計
- 無障礙:使用者友善的平台,無需專業訓練
- 一致性:在多個虛擬人偶中維持一致的品質
製作高品質的 AI 頭像
掌握文字提示
出色的虛擬人偶生成始於詳細的描述性提示。考慮這些最佳做法:
- 指定視覺細節(髮型、衣服、臉部特徵)
- 包含藝術風格偏好(動畫、3D、逼真)
- 透過身體屬性描述個性特徵
- 參考光線條件和背景元素
- 使用比較性語言 (「像年輕的 David Bowie」)
改善範例:
基本:「創造一個女孩
增強型:「產生一個生氣勃勃的動漫角色,她扎著彩虹般的辮子,穿著皮夾克和霓虹吊飾,投擲岩石角,手上散發著電一般的能量」
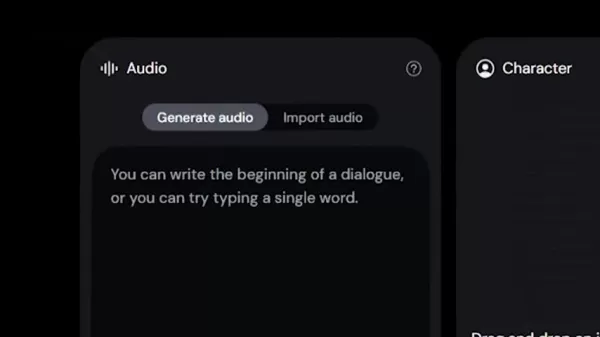
優化音訊輸入
自然的唇語同步需要仔細的音訊準備:
- 在經過聲學處理的空間中使用專業麥克風錄音
- 在整個錄音過程中保持一致的音量和音調
- 在短語之間加入自然的停頓,以提供呼吸空間
- 考慮與化身外觀相符的聲音特徵
- 使用降噪工具消除背景雜訊
使用 Hedra AI 分步創作
平台導覽
- 透過 Hedra AI 官方網站存取
- 使用您偏好的憑證註冊
- 探索測試版儀表板介面
三個核心工作流程面板
- 音訊模組:上傳錄音或產生合成人聲
- 角色生成器:透過文字提示或圖片上傳設計頭像
- 視訊產生器:結合元素並呈現最終輸出
音訊整合流程
- 選擇音訊來源 (檔案上傳/錄音/TTS 轉換)
- 針對 TTS:輸入文字(300 字元限制)並選擇語音設定檔
- 用於上傳:使用以 44.1kHz 或更高頻率錄製的 MP3/WAV 檔案
- 調整時序標記以獲得精確的同步點
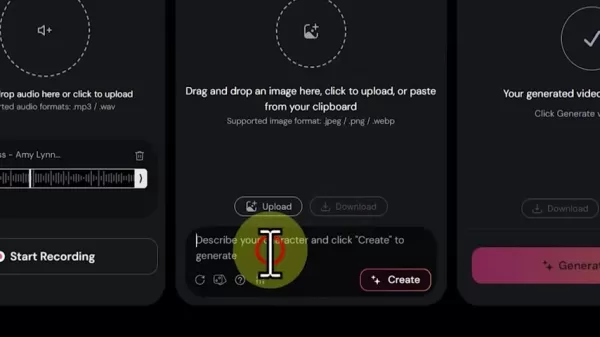
視覺設計階段
- 選擇圖片上傳或 AI 產生
- 針對 AI 創作:輸入詳細的角色描述
- 利用種子隨機化進行變體探索
- 調整生成參數以完善風格
最終渲染
- 預覽同步精確度
- 必要時調整時間偏移
- 以最佳解析度渲染專案
- 下載完成的視訊檔案
Hedra AI 功能細分
核心功能
- 先進的文字轉圖像角色生成
- 畫面精準的唇部同步技術
- 具備情緒調變功能的多語言文字轉語音
- 基於雲端處理的硬體獨立性
實際應用
行銷實作
- 虛擬產品示範
- 個人化視訊訊息
- 互動式數位代言人
教育用途
- 動畫演講
- 語言學習助手
- 歷史人物重現
娛樂概念
- 虛擬音樂表演者
- 動畫播客主持人
- 互動故事敘述員
常見問題
音訊長度指引
為了達到最佳的處理效率和同步精確度,請將連續的音訊片段限制在 3 分鐘以下。可考慮將較長的內容分割成章節,並分別渲染。
圖片規格
上傳高解析度圖片 (最小寬度 1024px),且臉部特徵清晰可見。避免使用受版權保護的素材或未經適當授權的肖像。
相關文章
 Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
相關專題推薦
商業
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
相關專題推薦
商業
 最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
 10 個工具
10 個工具
 xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai
代碼
最適合自動化單元測試的最佳AI工具:一鍵生成Jest、PyTest和JUnit測試用例
探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

 評論 (3)
0/500
評論 (3)
0/500
![BenGarcía]()
This guide is super helpful for beginners! I've been wanting to create a virtual singer for my music covers, and Hedra AI seems like the perfect starting point. The idea of AI making performances more 'lifelike' is both exciting and a bit scary for future human artists, though. 😅 Can't wait to try it this weekend!
![GeorgeJones]()
이 가이드 진짜 도움 많이 되네요 👍 헤드라 AI 같은 플랫폼 덕분에 초보자도 AI 가상 가수를 만들 수 있다니… 기술 발전 속도가 놀라워요. 혹시 창작한 아바타로 콘서트나 라이브 스트리밍도 가능할까요? 앞으로 가상 아이돌 시장이 어떻게 변할지 궁금해요 🎤
![WalterWalker]()
AIで歌うアバターを作るなんて、SFの世界みたい!でも技術の進歩は本当にすごいね。個人的には、VTuberやバーチャルアイドルに使えそうで楽しみだけど、著作権や声の権利問題は大丈夫かな?ちょっと心配…😅
人工智慧正在徹底改變數位內容的創作,特別是透過人工智慧驅動的歌唱虛擬人偶,提供非常逼真的表演。透過 Hedra AI 等直覺式平台,任何人現在都可以製作客製化的數位表演者,並提供精準的口型同步 - 不需要專業技術。這套全面的教學將引導您完成製作引人入勝的 AI 聲音虛擬人偶的每個步驟,適用於行銷、教育、娛樂等領域。
重點
無障礙的虛擬人偶製作:現代平台透過友善的工作流程將數位表演者的開發民主化。
迅速的製作要點:詳細的文字描述可顯著影響虛擬人像的品質與逼真度。
音訊最佳化:高品質的聲音音軌可確保自然的嘴部動作與表情。
創意自訂:從動畫到逼真的角色,您可以嘗試各種不同的視覺風格。
多產業應用:這些工具可為行銷、教育、客戶服務和娛樂領域的內容創作者提供服務。
AI 歌唱虛擬人偶簡介
了解數位聲樂表演者
AI 歌唱虛擬人偶是合成媒體的一項突破,結合了電腦產生的影像與先進的語音同步技術。這些數位表演者一開始是以文字為基礎的角色描述,然後由 AI 轉換成可視化的表現。當搭配音軌 (無論是錄音或 AI 產生的) 時,精密的演算法會將虛擬人偶的臉部特徵製成動畫,以令人信服的精確度來搭配聲樂表演。
這項技術的多樣性為眾多應用打開了大門。行銷人員可以開發品牌虛擬代言人、教育工作者可以創造動畫導師、藝人可以製作虛擬樂團或數位影響力。Hedra AI 等平台可透過直覺式介面簡化製作過程,從概念到最終產品都能引導使用者,無須動畫專業知識。
超越傳統動畫的優勢
與傳統動畫技術相比,AI 驅動的虛擬人像創作提供了明顯的優勢:
- 時間效率:將製作時間從數週縮短至數小時
- 預算輕鬆:省去昂貴的動畫工作室成本
- 創意自由:快速迭代角色設計
- 無障礙:使用者友善的平台,無需專業訓練
- 一致性:在多個虛擬人偶中維持一致的品質
製作高品質的 AI 頭像
掌握文字提示
出色的虛擬人偶生成始於詳細的描述性提示。考慮這些最佳做法:
- 指定視覺細節(髮型、衣服、臉部特徵)
- 包含藝術風格偏好(動畫、3D、逼真)
- 透過身體屬性描述個性特徵
- 參考光線條件和背景元素
- 使用比較性語言 (「像年輕的 David Bowie」)
改善範例:
基本:「創造一個女孩
增強型:「產生一個生氣勃勃的動漫角色,她扎著彩虹般的辮子,穿著皮夾克和霓虹吊飾,投擲岩石角,手上散發著電一般的能量」
優化音訊輸入
自然的唇語同步需要仔細的音訊準備:
- 在經過聲學處理的空間中使用專業麥克風錄音
- 在整個錄音過程中保持一致的音量和音調
- 在短語之間加入自然的停頓,以提供呼吸空間
- 考慮與化身外觀相符的聲音特徵
- 使用降噪工具消除背景雜訊
使用 Hedra AI 分步創作
平台導覽
- 透過 Hedra AI 官方網站存取
- 使用您偏好的憑證註冊
- 探索測試版儀表板介面
三個核心工作流程面板
- 音訊模組:上傳錄音或產生合成人聲
- 角色生成器:透過文字提示或圖片上傳設計頭像
- 視訊產生器:結合元素並呈現最終輸出
音訊整合流程
- 選擇音訊來源 (檔案上傳/錄音/TTS 轉換)
- 針對 TTS:輸入文字(300 字元限制)並選擇語音設定檔
- 用於上傳:使用以 44.1kHz 或更高頻率錄製的 MP3/WAV 檔案
- 調整時序標記以獲得精確的同步點
視覺設計階段
- 選擇圖片上傳或 AI 產生
- 針對 AI 創作:輸入詳細的角色描述
- 利用種子隨機化進行變體探索
- 調整生成參數以完善風格
最終渲染
- 預覽同步精確度
- 必要時調整時間偏移
- 以最佳解析度渲染專案
- 下載完成的視訊檔案
Hedra AI 功能細分
核心功能
- 先進的文字轉圖像角色生成
- 畫面精準的唇部同步技術
- 具備情緒調變功能的多語言文字轉語音
- 基於雲端處理的硬體獨立性
實際應用
行銷實作
- 虛擬產品示範
- 個人化視訊訊息
- 互動式數位代言人
教育用途
- 動畫演講
- 語言學習助手
- 歷史人物重現
娛樂概念
- 虛擬音樂表演者
- 動畫播客主持人
- 互動故事敘述員
常見問題
音訊長度指引
為了達到最佳的處理效率和同步精確度,請將連續的音訊片段限制在 3 分鐘以下。可考慮將較長的內容分割成章節,並分別渲染。
圖片規格
上傳高解析度圖片 (最小寬度 1024px),且臉部特徵清晰可見。避免使用受版權保護的素材或未經適當授權的肖像。










 Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
 DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
 馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

This guide is super helpful for beginners! I've been wanting to create a virtual singer for my music covers, and Hedra AI seems like the perfect starting point. The idea of AI making performances more 'lifelike' is both exciting and a bit scary for future human artists, though. 😅 Can't wait to try it this weekend!
이 가이드 진짜 도움 많이 되네요 👍 헤드라 AI 같은 플랫폼 덕분에 초보자도 AI 가상 가수를 만들 수 있다니… 기술 발전 속도가 놀라워요. 혹시 창작한 아바타로 콘서트나 라이브 스트리밍도 가능할까요? 앞으로 가상 아이돌 시장이 어떻게 변할지 궁금해요 🎤
AIで歌うアバターを作るなんて、SFの世界みたい!でも技術の進歩は本当にすごいね。個人的には、VTuberやバーチャルアイドルに使えそうで楽しみだけど、著作権や声の権利問題は大丈夫かな?ちょっと心配…😅













