
















 首页
首页如何轻松制作人工智能歌唱头像:完全新手指南
人工智能正在彻底改变数字内容的创作,特别是通过人工智能驱动的歌唱化身,提供栩栩如生的表演。借助 Hedra AI 等直观的平台,现在任何人都可以制作出具有精确唇语同步功能的定制数字表演者,而无需专业技术知识。本综合教程将指导您完成为营销、教育、娱乐等领域创建引人入胜的人工智能歌唱头像的每一个步骤。
要点
可访问的头像创建:现代平台通过用户友好的工作流程实现了数字表演者开发的民主化。
提示制作要点:详细的文字说明会极大地影响头像的质量和逼真度。
音频优化:高质量的声轨可确保嘴部动作和表情自然逼真。
创意定制:尝试从动漫到逼真角色的各种视觉风格。
多行业应用:这些工具可为营销、教育、客户服务和娱乐领域的内容创作者提供服务。
人工智能歌唱头像简介
了解数字声乐表演者
人工智能歌唱头像是合成媒体领域的一项突破,它将计算机生成的图像与先进的语音同步技术相结合。这些数字表演者一开始是基于文本的角色描述,人工智能将其转化为视觉表现。当与音轨(无论是录制的还是人工智能生成的)配对时,复杂的算法会将化身的面部特征制作成动画,以令人信服的准确度匹配声音表演。
这项技术的多功能性为众多应用打开了大门。市场营销人员可以开发品牌虚拟代言人,教育工作者可以创建动画讲师,艺人可以制作虚拟乐队或数字影响者。Hedra AI 等平台通过直观的界面简化了这一过程,引导用户从概念到最终产品,而无需动画专业知识。
与传统动画相比的优势
与传统动画技术相比,人工智能驱动的化身创建具有明显的优势:
- 时间效率:将制作时间从数周缩短至数小时
- 节省预算:省去昂贵的动画工作室费用
- 创作自由:快速迭代角色设计
- 无障碍:用户友好型平台,无需专业培训
- 一致性:在多个头像中保持统一的质量
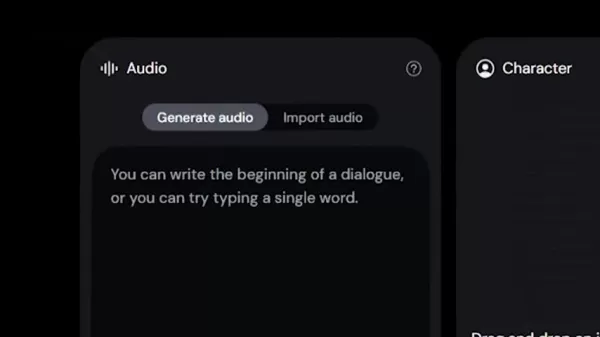
制作高质量的人工智能头像
掌握文本提示
出色的头像生成始于详细的描述性提示。请考虑以下最佳实践:
- 指定视觉细节(发型、服装、面部特征)
- 包括艺术风格偏好(动漫、3D、逼真)
- 通过物理属性描述个性特征
- 参考照明条件和背景元素
- 使用比较性语言("像年轻时的大卫-鲍伊)
改进示例:
基础:"创造一个女孩"
增强型:"生成一个充满活力的动漫人物,她扎着彩虹般的小辫子,身穿皮夹克,头戴霓虹吊饰,双手挥舞着散发着电能的摇滚号角。
优化音频输入
自然的唇音同步需要精心的音频准备:
- 在经过声学处理的空间中使用专业麦克风录音
- 在整个录音过程中保持一致的音量和音调
- 在短语之间添加自然停顿,以留出呼吸空间
- 考虑与头像外观相匹配的声音特征
- 使用降噪工具消除背景伪音
使用 Hedra AI 一步步进行创作
平台导航
- 通过其官方网站访问 Hedra AI
- 使用您喜欢的证书注册
- 探索测试版仪表板界面
三个核心工作流程面板
- 音频模块:上传录音或生成合成人声
- 角色生成器:通过文本提示或图片上传设计头像
- 视频生成器组合元素并渲染最终输出
音频集成流程
- 选择音频源(文件上传/录音/TTS 转换)
- 对于 TTS:输入文本(300 个字符限制)并选择语音配置文件
- 对于上传:使用以 44.1kHz 或更高频率录制的 MP3/WAV 文件
- 调整定时标记以获得精确的同步点
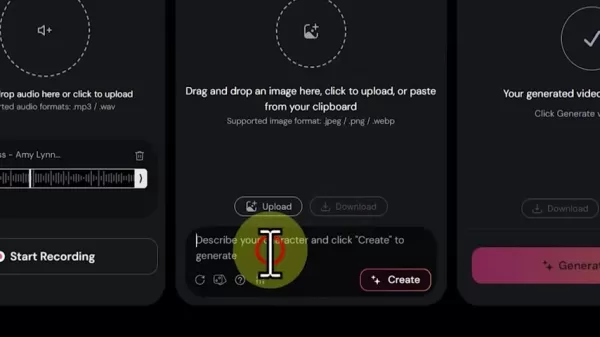
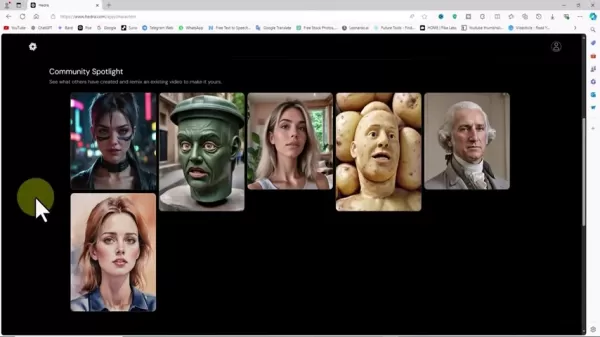
视觉设计阶段
- 选择图片上传或 AI 生成
- 创建 AI输入详细的角色描述
- 利用种子随机化进行变体探索
- 调整生成参数以完善风格
最终渲染
- 预览同步精度
- 必要时调整时间偏移
- 以最佳分辨率渲染项目
- 下载完成的视频文件
Hedra AI 功能细分
核心功能
- 先进的文本到图像字符生成技术
- 帧精确唇语同步技术
- 具有情感调节功能的多语言文本到语音技术
- 基于云的处理,实现硬件独立性
实际应用
营销实施
- 虚拟产品演示
- 个性化视频信息
- 交互式数字发言人模型
教育用途
- 动画讲座演示
- 语言学习助手
- 历史人物再现
娱乐概念
- 虚拟音乐表演者
- 动画播客主持人
- 互动故事讲述者
常见问题
音频时长指南
为达到最佳处理效率和同步精度,请将连续音频片段限制在 3 分钟以内。可考虑将较长的内容分成章节,分别渲染。
图片规格
上传面部特征清晰可见的高分辨率图片(最小宽度为 1024px)。避免使用受版权保护的材料或未经适当授权的肖像。
相关文章
 Anthropic公司的实验性人工智能Claude在电子商务测试中完成了谈判和交易
随着人工智能的飞速发展,Anthropic上周五悄然启动了一项名为“Project Deal”的内部实验,展示了人工智能在电子商务领域的潜力。该实验让其人工智能模型Claude在封闭的市场环境中自主处理买卖及价格谈判,并涉及真实的金融交易。实验的核心是一个基于Slack构建的内部市场,Claude在其中同时担任买卖双方的谈判代表。它首先对69名员工进行了访谈,收集了他们的买卖意向及个性化指示,随后
DeepSeek Code 即将发布
随着人工智能技术的加速发展,DeepSeek正处于一个激动人心的关键时刻。这家人工智能公司近日透露,已获得超过700亿元的融资。公司管理层强调,将致力于开创性的人工智能研究,而非追求眼前的商业利益。这一战略转型表明,DeepSeek将全力投入新产品的开发,尤其是备受期待的DeepSeek Code。DeepSeek Code的规划已初具雏形,公司招聘页面上已发布多个相关职位,例如“Agent Ha
马斯克的Grok:1.5万亿参数与光标代码吸收——颠覆性突破还是虚张声势?
埃隆·马斯克终于开始行动了。在人工智能编程竞赛中,OpenAI和Anthropic正加速前进,而xAI似乎有些落后。马斯克曾多次表示要与Claude一较高下,尽管Grok4.X系列已多次更新,但其成果在理论上看似不错,实际应用中却未能达到预期,双方的差距几乎未见缩小。不过,这次他手中握有一张新牌。马斯克在X平台确认,Grok的新版本即将问世。 这款基础模型第九版的内部代号已确定,参数规模高达1.5
相关专题推荐
商业
Anthropic公司的实验性人工智能Claude在电子商务测试中完成了谈判和交易
随着人工智能的飞速发展,Anthropic上周五悄然启动了一项名为“Project Deal”的内部实验,展示了人工智能在电子商务领域的潜力。该实验让其人工智能模型Claude在封闭的市场环境中自主处理买卖及价格谈判,并涉及真实的金融交易。实验的核心是一个基于Slack构建的内部市场,Claude在其中同时担任买卖双方的谈判代表。它首先对69名员工进行了访谈,收集了他们的买卖意向及个性化指示,随后
DeepSeek Code 即将发布
随着人工智能技术的加速发展,DeepSeek正处于一个激动人心的关键时刻。这家人工智能公司近日透露,已获得超过700亿元的融资。公司管理层强调,将致力于开创性的人工智能研究,而非追求眼前的商业利益。这一战略转型表明,DeepSeek将全力投入新产品的开发,尤其是备受期待的DeepSeek Code。DeepSeek Code的规划已初具雏形,公司招聘页面上已发布多个相关职位,例如“Agent Ha
马斯克的Grok:1.5万亿参数与光标代码吸收——颠覆性突破还是虚张声势?
埃隆·马斯克终于开始行动了。在人工智能编程竞赛中,OpenAI和Anthropic正加速前进,而xAI似乎有些落后。马斯克曾多次表示要与Claude一较高下,尽管Grok4.X系列已多次更新,但其成果在理论上看似不错,实际应用中却未能达到预期,双方的差距几乎未见缩小。不过,这次他手中握有一张新牌。马斯克在X平台确认,Grok的新版本即将问世。 这款基础模型第九版的内部代号已确定,参数规模高达1.5
相关专题推荐
商业
 最佳人工智能招聘工具:筛选简历并自动安排候选人面试
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
 10 个工具
10 个工具
 xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai
代码
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

 评论 (3)
0/500
评论 (3)
0/500
![BenGarcía]()
This guide is super helpful for beginners! I've been wanting to create a virtual singer for my music covers, and Hedra AI seems like the perfect starting point. The idea of AI making performances more 'lifelike' is both exciting and a bit scary for future human artists, though. 😅 Can't wait to try it this weekend!
![GeorgeJones]()
이 가이드 진짜 도움 많이 되네요 👍 헤드라 AI 같은 플랫폼 덕분에 초보자도 AI 가상 가수를 만들 수 있다니… 기술 발전 속도가 놀라워요. 혹시 창작한 아바타로 콘서트나 라이브 스트리밍도 가능할까요? 앞으로 가상 아이돌 시장이 어떻게 변할지 궁금해요 🎤
![WalterWalker]()
AIで歌うアバターを作るなんて、SFの世界みたい!でも技術の進歩は本当にすごいね。個人的には、VTuberやバーチャルアイドルに使えそうで楽しみだけど、著作権や声の権利問題は大丈夫かな?ちょっと心配…😅
人工智能正在彻底改变数字内容的创作,特别是通过人工智能驱动的歌唱化身,提供栩栩如生的表演。借助 Hedra AI 等直观的平台,现在任何人都可以制作出具有精确唇语同步功能的定制数字表演者,而无需专业技术知识。本综合教程将指导您完成为营销、教育、娱乐等领域创建引人入胜的人工智能歌唱头像的每一个步骤。
要点
可访问的头像创建:现代平台通过用户友好的工作流程实现了数字表演者开发的民主化。
提示制作要点:详细的文字说明会极大地影响头像的质量和逼真度。
音频优化:高质量的声轨可确保嘴部动作和表情自然逼真。
创意定制:尝试从动漫到逼真角色的各种视觉风格。
多行业应用:这些工具可为营销、教育、客户服务和娱乐领域的内容创作者提供服务。
人工智能歌唱头像简介
了解数字声乐表演者
人工智能歌唱头像是合成媒体领域的一项突破,它将计算机生成的图像与先进的语音同步技术相结合。这些数字表演者一开始是基于文本的角色描述,人工智能将其转化为视觉表现。当与音轨(无论是录制的还是人工智能生成的)配对时,复杂的算法会将化身的面部特征制作成动画,以令人信服的准确度匹配声音表演。
这项技术的多功能性为众多应用打开了大门。市场营销人员可以开发品牌虚拟代言人,教育工作者可以创建动画讲师,艺人可以制作虚拟乐队或数字影响者。Hedra AI 等平台通过直观的界面简化了这一过程,引导用户从概念到最终产品,而无需动画专业知识。
与传统动画相比的优势
与传统动画技术相比,人工智能驱动的化身创建具有明显的优势:
- 时间效率:将制作时间从数周缩短至数小时
- 节省预算:省去昂贵的动画工作室费用
- 创作自由:快速迭代角色设计
- 无障碍:用户友好型平台,无需专业培训
- 一致性:在多个头像中保持统一的质量
制作高质量的人工智能头像
掌握文本提示
出色的头像生成始于详细的描述性提示。请考虑以下最佳实践:
- 指定视觉细节(发型、服装、面部特征)
- 包括艺术风格偏好(动漫、3D、逼真)
- 通过物理属性描述个性特征
- 参考照明条件和背景元素
- 使用比较性语言("像年轻时的大卫-鲍伊)
改进示例:
基础:"创造一个女孩"
增强型:"生成一个充满活力的动漫人物,她扎着彩虹般的小辫子,身穿皮夹克,头戴霓虹吊饰,双手挥舞着散发着电能的摇滚号角。
优化音频输入
自然的唇音同步需要精心的音频准备:
- 在经过声学处理的空间中使用专业麦克风录音
- 在整个录音过程中保持一致的音量和音调
- 在短语之间添加自然停顿,以留出呼吸空间
- 考虑与头像外观相匹配的声音特征
- 使用降噪工具消除背景伪音
使用 Hedra AI 一步步进行创作
平台导航
- 通过其官方网站访问 Hedra AI
- 使用您喜欢的证书注册
- 探索测试版仪表板界面
三个核心工作流程面板
- 音频模块:上传录音或生成合成人声
- 角色生成器:通过文本提示或图片上传设计头像
- 视频生成器组合元素并渲染最终输出
音频集成流程
- 选择音频源(文件上传/录音/TTS 转换)
- 对于 TTS:输入文本(300 个字符限制)并选择语音配置文件
- 对于上传:使用以 44.1kHz 或更高频率录制的 MP3/WAV 文件
- 调整定时标记以获得精确的同步点
视觉设计阶段
- 选择图片上传或 AI 生成
- 创建 AI输入详细的角色描述
- 利用种子随机化进行变体探索
- 调整生成参数以完善风格
最终渲染
- 预览同步精度
- 必要时调整时间偏移
- 以最佳分辨率渲染项目
- 下载完成的视频文件
Hedra AI 功能细分
核心功能
- 先进的文本到图像字符生成技术
- 帧精确唇语同步技术
- 具有情感调节功能的多语言文本到语音技术
- 基于云的处理,实现硬件独立性
实际应用
营销实施
- 虚拟产品演示
- 个性化视频信息
- 交互式数字发言人模型
教育用途
- 动画讲座演示
- 语言学习助手
- 历史人物再现
娱乐概念
- 虚拟音乐表演者
- 动画播客主持人
- 互动故事讲述者
常见问题
音频时长指南
为达到最佳处理效率和同步精度,请将连续音频片段限制在 3 分钟以内。可考虑将较长的内容分成章节,分别渲染。
图片规格
上传面部特征清晰可见的高分辨率图片(最小宽度为 1024px)。避免使用受版权保护的材料或未经适当授权的肖像。










 Anthropic公司的实验性人工智能Claude在电子商务测试中完成了谈判和交易
随着人工智能的飞速发展,Anthropic上周五悄然启动了一项名为“Project Deal”的内部实验,展示了人工智能在电子商务领域的潜力。该实验让其人工智能模型Claude在封闭的市场环境中自主处理买卖及价格谈判,并涉及真实的金融交易。实验的核心是一个基于Slack构建的内部市场,Claude在其中同时担任买卖双方的谈判代表。它首先对69名员工进行了访谈,收集了他们的买卖意向及个性化指示,随后
Anthropic公司的实验性人工智能Claude在电子商务测试中完成了谈判和交易
随着人工智能的飞速发展,Anthropic上周五悄然启动了一项名为“Project Deal”的内部实验,展示了人工智能在电子商务领域的潜力。该实验让其人工智能模型Claude在封闭的市场环境中自主处理买卖及价格谈判,并涉及真实的金融交易。实验的核心是一个基于Slack构建的内部市场,Claude在其中同时担任买卖双方的谈判代表。它首先对69名员工进行了访谈,收集了他们的买卖意向及个性化指示,随后
 DeepSeek Code 即将发布
随着人工智能技术的加速发展,DeepSeek正处于一个激动人心的关键时刻。这家人工智能公司近日透露,已获得超过700亿元的融资。公司管理层强调,将致力于开创性的人工智能研究,而非追求眼前的商业利益。这一战略转型表明,DeepSeek将全力投入新产品的开发,尤其是备受期待的DeepSeek Code。DeepSeek Code的规划已初具雏形,公司招聘页面上已发布多个相关职位,例如“Agent Ha
DeepSeek Code 即将发布
随着人工智能技术的加速发展,DeepSeek正处于一个激动人心的关键时刻。这家人工智能公司近日透露,已获得超过700亿元的融资。公司管理层强调,将致力于开创性的人工智能研究,而非追求眼前的商业利益。这一战略转型表明,DeepSeek将全力投入新产品的开发,尤其是备受期待的DeepSeek Code。DeepSeek Code的规划已初具雏形,公司招聘页面上已发布多个相关职位,例如“Agent Ha
 马斯克的Grok:1.5万亿参数与光标代码吸收——颠覆性突破还是虚张声势?
埃隆·马斯克终于开始行动了。在人工智能编程竞赛中,OpenAI和Anthropic正加速前进,而xAI似乎有些落后。马斯克曾多次表示要与Claude一较高下,尽管Grok4.X系列已多次更新,但其成果在理论上看似不错,实际应用中却未能达到预期,双方的差距几乎未见缩小。不过,这次他手中握有一张新牌。马斯克在X平台确认,Grok的新版本即将问世。 这款基础模型第九版的内部代号已确定,参数规模高达1.5
马斯克的Grok:1.5万亿参数与光标代码吸收——颠覆性突破还是虚张声势?
埃隆·马斯克终于开始行动了。在人工智能编程竞赛中,OpenAI和Anthropic正加速前进,而xAI似乎有些落后。马斯克曾多次表示要与Claude一较高下,尽管Grok4.X系列已多次更新,但其成果在理论上看似不错,实际应用中却未能达到预期,双方的差距几乎未见缩小。不过,这次他手中握有一张新牌。马斯克在X平台确认,Grok的新版本即将问世。 这款基础模型第九版的内部代号已确定,参数规模高达1.5

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

This guide is super helpful for beginners! I've been wanting to create a virtual singer for my music covers, and Hedra AI seems like the perfect starting point. The idea of AI making performances more 'lifelike' is both exciting and a bit scary for future human artists, though. 😅 Can't wait to try it this weekend!
이 가이드 진짜 도움 많이 되네요 👍 헤드라 AI 같은 플랫폼 덕분에 초보자도 AI 가상 가수를 만들 수 있다니… 기술 발전 속도가 놀라워요. 혹시 창작한 아바타로 콘서트나 라이브 스트리밍도 가능할까요? 앞으로 가상 아이돌 시장이 어떻게 변할지 궁금해요 🎤
AIで歌うアバターを作るなんて、SFの世界みたい!でも技術の進歩は本当にすごいね。個人的には、VTuberやバーチャルアイドルに使えそうで楽しみだけど、著作権や声の権利問題は大丈夫かな?ちょっと心配…😅













