




歌うAIアバターの簡単な作り方:完全初心者ガイド
人工知能は、デジタルコンテンツ制作に革命をもたらしている。特に、AIを搭載した歌唱アバターは、驚くほどリアルなパフォーマンスを実現する。Hedra AIのような直感的なプラットフォームを使えば、専門知識は必要なく、誰でも正確なリップシンクを備えたカスタムデジタルパフォーマーを作ることができます。この包括的なチュートリアルでは、マーケティング、教育、エンターテイメントなど、魅力的なAIボーカルアバターを作成するためのすべてのステップを説明します。
キーポイント
アクセスしやすいアバター作成:最新のプラットフォームは、ユーザーフレンドリーなワークフローでデジタル・パフォーマー開発を民主化します。
プロンプト作成の要点:詳細なテキスト説明は、アバターの品質とリアリズムに大きな影響を与えます。
音声の最適化:高品質なボーカルトラックが、自然な口の動きと表情を実現します。
クリエイティブなカスタマイズ:アニメから写実的なキャラクターまで、多様なビジュアルスタイルを試すことができます。
マルチ・インダストリー・アプリケーション:これらのツールは、マーケティング、教育、カスタマーサービス、エンターテインメントの各分野のコンテンツ制作者に役立ちます。
AI歌唱アバターの紹介
デジタル・ヴォーカル・パフォーマーを理解する
AI歌唱アバターは、コンピュータ生成画像と高度な音声同期を組み合わせた合成メディアの画期的な進歩です。これらのデジタル・パフォーマーは、AIが視覚的表現に変換するテキストベースのキャラクター説明から始まります。音声トラック(録音されたものであれ、AIが生成したものであれ)と組み合わせると、洗練されたアルゴリズムがアバターの顔の特徴をアニメーション化し、説得力のある正確さでボーカル・パフォーマンスと一致させる。
この技術の多用途性は、多くのアプリケーションの扉を開く。マーケティング担当者はブランド化されたバーチャル・スポークスマンを開発し、教育者はアニメーション化されたインストラクターを作成し、エンターテイナーはバーチャル・バンドやデジタル・インフルエンサーを制作することができる。Hedra AIのようなプラットフォームは、アニメーションの専門知識を必要とせず、コンセプトから最終製品までユーザーを導く直感的なインターフェイスにより、このプロセスを簡素化します。
従来のアニメーションを超える利点
AIを活用したアバター制作は、従来のアニメーション技術と比較して明確な利点があります:
- 時間効率:制作期間を数週間から数時間に短縮
- 予算に優しい: 高額なアニメーション・スタジオのコストを削減できます。
- クリエイティブな自由:キャラクターデザインを迅速に反復
- アクセシビリティ:ユーザーフレンドリーなプラットフォームは専門的なトレーニングを必要としない
- 一貫性:複数のアバターで均一な品質を維持
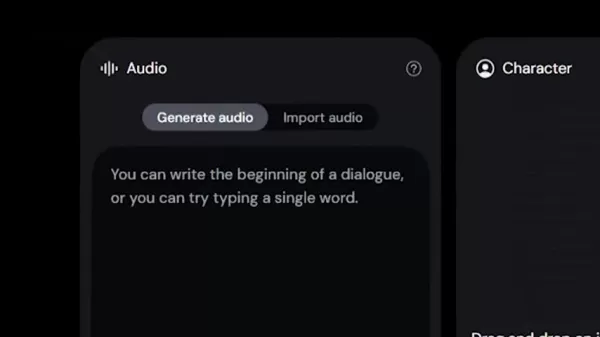
高品質のAIアバターを作る
テキストプロンプトをマスターする
優れたアバターの生成は、詳細な説明プロンプトから始まります。以下のベストプラクティスを参考にしてください:
- 視覚的な詳細を指定する(髪型、服装、顔の特徴)
- アーティスティックなスタイルの好み(アニメ、3D、写実的)を含める。
- 身体的属性を通して性格の特徴を説明する
- 照明条件や背景要素に言及する
- 比較表現を使う(「若いデヴィッド・ボウイに似ている)
改善例
基本:"女の子を作る"
強化:「レザージャケットにネオンのチョーカーをつけ、手から電気エネルギーを放ちながらロックホーンを投げる。
オーディオ入力の最適化
自然なリップシンクには、入念なオーディオの準備が必要です:
- 音響処理された空間で、プロ仕様のマイクを使って録音する。
- 録音全体の音量とピッチを一定に保つ
- フレーズとフレーズの間に自然なポーズを入れ、余裕を持たせる
- アバターの外見に合ったボーカルの特徴を考慮する
- ノイズ除去ツールを使って背景のアーチファクトを除去する。
Hedra AIを使ったステップバイステップの作成
プラットフォームナビゲーション
- 公式ウェブサイトからHedra AIにアクセス
- お好みの認証情報を使って登録する
- ベータ版ダッシュボードのインターフェイスを見る
3つのコアワークフローパネル
- オーディオモジュール:レコーディングのアップロードまたは合成ボーカルの生成
- キャラクタービルダー:テキストプロンプトまたは画像のアップロードによるアバターのデザイン
- ビデオジェネレータ:要素を組み合わせて最終出力をレンダリング
音声統合プロセス
- オーディオソースの選択(ファイルアップロード/録音/TTS変換)
- TTSの場合: テキストを入力し(300文字制限)、音声プロファイルを選択します。
- アップロードの場合44.1kHz以上で録音されたMP3/WAVファイルを使用
- 正確な同期ポイントのためにタイミングマーカーを調整する
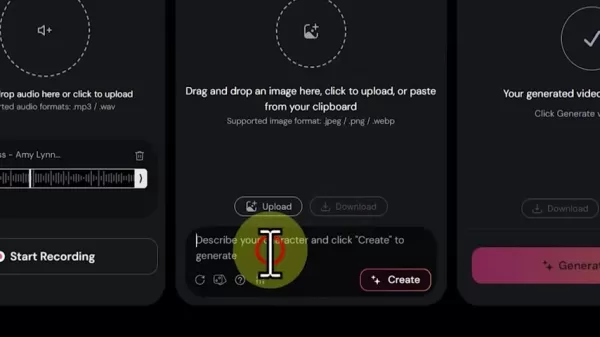
ビジュアルデザインフェーズ
- 画像アップロードかAI生成のどちらかを選択
- AI作成の場合キャラクターの詳細な説明を入力
- シードのランダム化を利用してバリアントを探索
- スタイル改良のための生成パラメータ調整
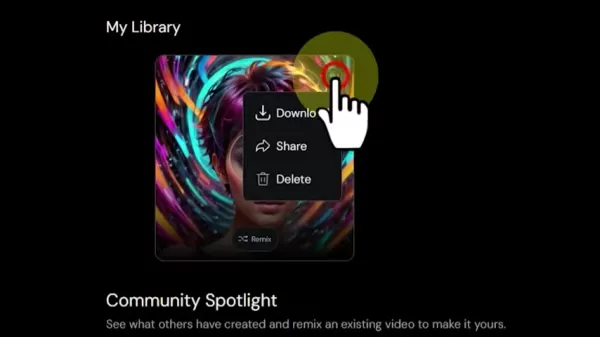
最終レンダリング
- 同期精度のプレビュー
- 必要に応じてタイミングオフセットを調整
- 最適な解像度でプロジェクトをレンダリング
- 完成した動画ファイルをダウンロード
ヘドラAIの機能内訳
コア機能
- 高度なテキストから画像への文字生成
- フレーム精度のリップシンクロ技術
- 感情変調による多言語音声合成
- ハードウェアに依存しないクラウドベース処理
実用的なアプリケーション
マーケティング実装
- バーチャル製品デモ
- パーソナライズされたビデオメッセージング
- インタラクティブなデジタル・スポークモデル
教育用途
- アニメーション講義プレゼンテーション
- 語学学習アシスタント
- 歴史上の人物の再現
エンターテイメント
- バーチャル音楽パフォーマー
- アニメーションポッドキャストホスト
- インタラクティブなストーリーナレーター
よくある質問
音声時間のガイドライン
処理効率と同期の精度を最適化するため、連続したオーディオセグメントは3分以内に制限してください。長いコンテンツは、チャプターに分割して別々にレンダリングすることを検討してください。
画像の仕様
顔の特徴がはっきりとわかる高解像度の画像(最小幅1024px)をアップロードしてください。著作権で保護された素材や、適切な許可のない肖像は避けてください。
関連記事
 AIブックカバーデザイン:革新的なアプリケーションと専門家のヒント
人工知能が著者やデザイナーにとって不可欠なクリエイティブ・パートナーになるにつれ、ブックカバーデザインの領域は変革期を迎えている。これらの最先端のツールは、ワークフローを合理化すると同時に、これまでにないクリエイティブな可能性を引き出し、注目を集める視覚的に印象的なカバーアートの開発を可能にします。特にこれらのツールの芸術的応用に焦点を当てながら、革新的なプロフェッショナルがどのようにAI技術を活
TikTok、テキストプロンプトで写真を動画に変換するAI機能を導入
TikTokの画期的な「AI Alive」機能は、シンプルなテキストプロンプトで静止画をアニメーション化する革新的な方法を紹介します。従来のAIビデオツールとは異なり、このプラットフォームは高度なAI技術をStory Cameraのインターフェースに直接統合することで、アニメーションプロセスを簡素化している。同社は、技術的なスキルに関係なく、すべてのユーザーがダイナミックな動きとクリエイティブなエ
最後のチャンス:TechCrunch Disrupt 2025 パス1,130ドル割引 - 間もなく終了
最終カウントダウン:TechCrunch Disrupt 2025のチケットが最大1,130ドル割引時間が迫っています!TechCrunch Disrupt 2025の割引パスが1,130ドルもお得に手に入る可能性があります。個人パスとグループ・バンドル(最大30%オフ)は、2月28日午後11時59分(PT)まで最安値でお求めいただけます。画期的な技術革新の20年を祝う今年のカンファレンス(10月
コメント (0)
0/200
AIブックカバーデザイン:革新的なアプリケーションと専門家のヒント
人工知能が著者やデザイナーにとって不可欠なクリエイティブ・パートナーになるにつれ、ブックカバーデザインの領域は変革期を迎えている。これらの最先端のツールは、ワークフローを合理化すると同時に、これまでにないクリエイティブな可能性を引き出し、注目を集める視覚的に印象的なカバーアートの開発を可能にします。特にこれらのツールの芸術的応用に焦点を当てながら、革新的なプロフェッショナルがどのようにAI技術を活
TikTok、テキストプロンプトで写真を動画に変換するAI機能を導入
TikTokの画期的な「AI Alive」機能は、シンプルなテキストプロンプトで静止画をアニメーション化する革新的な方法を紹介します。従来のAIビデオツールとは異なり、このプラットフォームは高度なAI技術をStory Cameraのインターフェースに直接統合することで、アニメーションプロセスを簡素化している。同社は、技術的なスキルに関係なく、すべてのユーザーがダイナミックな動きとクリエイティブなエ
最後のチャンス:TechCrunch Disrupt 2025 パス1,130ドル割引 - 間もなく終了
最終カウントダウン:TechCrunch Disrupt 2025のチケットが最大1,130ドル割引時間が迫っています!TechCrunch Disrupt 2025の割引パスが1,130ドルもお得に手に入る可能性があります。個人パスとグループ・バンドル(最大30%オフ)は、2月28日午後11時59分(PT)まで最安値でお求めいただけます。画期的な技術革新の20年を祝う今年のカンファレンス(10月
コメント (0)
0/200
人工知能は、デジタルコンテンツ制作に革命をもたらしている。特に、AIを搭載した歌唱アバターは、驚くほどリアルなパフォーマンスを実現する。Hedra AIのような直感的なプラットフォームを使えば、専門知識は必要なく、誰でも正確なリップシンクを備えたカスタムデジタルパフォーマーを作ることができます。この包括的なチュートリアルでは、マーケティング、教育、エンターテイメントなど、魅力的なAIボーカルアバターを作成するためのすべてのステップを説明します。
キーポイント
アクセスしやすいアバター作成:最新のプラットフォームは、ユーザーフレンドリーなワークフローでデジタル・パフォーマー開発を民主化します。
プロンプト作成の要点:詳細なテキスト説明は、アバターの品質とリアリズムに大きな影響を与えます。
音声の最適化:高品質なボーカルトラックが、自然な口の動きと表情を実現します。
クリエイティブなカスタマイズ:アニメから写実的なキャラクターまで、多様なビジュアルスタイルを試すことができます。
マルチ・インダストリー・アプリケーション:これらのツールは、マーケティング、教育、カスタマーサービス、エンターテインメントの各分野のコンテンツ制作者に役立ちます。
AI歌唱アバターの紹介
デジタル・ヴォーカル・パフォーマーを理解する
AI歌唱アバターは、コンピュータ生成画像と高度な音声同期を組み合わせた合成メディアの画期的な進歩です。これらのデジタル・パフォーマーは、AIが視覚的表現に変換するテキストベースのキャラクター説明から始まります。音声トラック(録音されたものであれ、AIが生成したものであれ)と組み合わせると、洗練されたアルゴリズムがアバターの顔の特徴をアニメーション化し、説得力のある正確さでボーカル・パフォーマンスと一致させる。
この技術の多用途性は、多くのアプリケーションの扉を開く。マーケティング担当者はブランド化されたバーチャル・スポークスマンを開発し、教育者はアニメーション化されたインストラクターを作成し、エンターテイナーはバーチャル・バンドやデジタル・インフルエンサーを制作することができる。Hedra AIのようなプラットフォームは、アニメーションの専門知識を必要とせず、コンセプトから最終製品までユーザーを導く直感的なインターフェイスにより、このプロセスを簡素化します。
従来のアニメーションを超える利点
AIを活用したアバター制作は、従来のアニメーション技術と比較して明確な利点があります:
- 時間効率:制作期間を数週間から数時間に短縮
- 予算に優しい: 高額なアニメーション・スタジオのコストを削減できます。
- クリエイティブな自由:キャラクターデザインを迅速に反復
- アクセシビリティ:ユーザーフレンドリーなプラットフォームは専門的なトレーニングを必要としない
- 一貫性:複数のアバターで均一な品質を維持
高品質のAIアバターを作る
テキストプロンプトをマスターする
優れたアバターの生成は、詳細な説明プロンプトから始まります。以下のベストプラクティスを参考にしてください:
- 視覚的な詳細を指定する(髪型、服装、顔の特徴)
- アーティスティックなスタイルの好み(アニメ、3D、写実的)を含める。
- 身体的属性を通して性格の特徴を説明する
- 照明条件や背景要素に言及する
- 比較表現を使う(「若いデヴィッド・ボウイに似ている)
改善例
基本:"女の子を作る"
強化:「レザージャケットにネオンのチョーカーをつけ、手から電気エネルギーを放ちながらロックホーンを投げる。
オーディオ入力の最適化
自然なリップシンクには、入念なオーディオの準備が必要です:
- 音響処理された空間で、プロ仕様のマイクを使って録音する。
- 録音全体の音量とピッチを一定に保つ
- フレーズとフレーズの間に自然なポーズを入れ、余裕を持たせる
- アバターの外見に合ったボーカルの特徴を考慮する
- ノイズ除去ツールを使って背景のアーチファクトを除去する。
Hedra AIを使ったステップバイステップの作成
プラットフォームナビゲーション
- 公式ウェブサイトからHedra AIにアクセス
- お好みの認証情報を使って登録する
- ベータ版ダッシュボードのインターフェイスを見る
3つのコアワークフローパネル
- オーディオモジュール:レコーディングのアップロードまたは合成ボーカルの生成
- キャラクタービルダー:テキストプロンプトまたは画像のアップロードによるアバターのデザイン
- ビデオジェネレータ:要素を組み合わせて最終出力をレンダリング
音声統合プロセス
- オーディオソースの選択(ファイルアップロード/録音/TTS変換)
- TTSの場合: テキストを入力し(300文字制限)、音声プロファイルを選択します。
- アップロードの場合44.1kHz以上で録音されたMP3/WAVファイルを使用
- 正確な同期ポイントのためにタイミングマーカーを調整する
ビジュアルデザインフェーズ
- 画像アップロードかAI生成のどちらかを選択
- AI作成の場合キャラクターの詳細な説明を入力
- シードのランダム化を利用してバリアントを探索
- スタイル改良のための生成パラメータ調整
最終レンダリング
- 同期精度のプレビュー
- 必要に応じてタイミングオフセットを調整
- 最適な解像度でプロジェクトをレンダリング
- 完成した動画ファイルをダウンロード
ヘドラAIの機能内訳
コア機能
- 高度なテキストから画像への文字生成
- フレーム精度のリップシンクロ技術
- 感情変調による多言語音声合成
- ハードウェアに依存しないクラウドベース処理
実用的なアプリケーション
マーケティング実装
- バーチャル製品デモ
- パーソナライズされたビデオメッセージング
- インタラクティブなデジタル・スポークモデル
教育用途
- アニメーション講義プレゼンテーション
- 語学学習アシスタント
- 歴史上の人物の再現
エンターテイメント
- バーチャル音楽パフォーマー
- アニメーションポッドキャストホスト
- インタラクティブなストーリーナレーター
よくある質問
音声時間のガイドライン
処理効率と同期の精度を最適化するため、連続したオーディオセグメントは3分以内に制限してください。長いコンテンツは、チャプターに分割して別々にレンダリングすることを検討してください。
画像の仕様
顔の特徴がはっきりとわかる高解像度の画像(最小幅1024px)をアップロードしてください。著作権で保護された素材や、適切な許可のない肖像は避けてください。










 AIブックカバーデザイン:革新的なアプリケーションと専門家のヒント
人工知能が著者やデザイナーにとって不可欠なクリエイティブ・パートナーになるにつれ、ブックカバーデザインの領域は変革期を迎えている。これらの最先端のツールは、ワークフローを合理化すると同時に、これまでにないクリエイティブな可能性を引き出し、注目を集める視覚的に印象的なカバーアートの開発を可能にします。特にこれらのツールの芸術的応用に焦点を当てながら、革新的なプロフェッショナルがどのようにAI技術を活
AIブックカバーデザイン:革新的なアプリケーションと専門家のヒント
人工知能が著者やデザイナーにとって不可欠なクリエイティブ・パートナーになるにつれ、ブックカバーデザインの領域は変革期を迎えている。これらの最先端のツールは、ワークフローを合理化すると同時に、これまでにないクリエイティブな可能性を引き出し、注目を集める視覚的に印象的なカバーアートの開発を可能にします。特にこれらのツールの芸術的応用に焦点を当てながら、革新的なプロフェッショナルがどのようにAI技術を活
 TikTok、テキストプロンプトで写真を動画に変換するAI機能を導入
TikTokの画期的な「AI Alive」機能は、シンプルなテキストプロンプトで静止画をアニメーション化する革新的な方法を紹介します。従来のAIビデオツールとは異なり、このプラットフォームは高度なAI技術をStory Cameraのインターフェースに直接統合することで、アニメーションプロセスを簡素化している。同社は、技術的なスキルに関係なく、すべてのユーザーがダイナミックな動きとクリエイティブなエ
TikTok、テキストプロンプトで写真を動画に変換するAI機能を導入
TikTokの画期的な「AI Alive」機能は、シンプルなテキストプロンプトで静止画をアニメーション化する革新的な方法を紹介します。従来のAIビデオツールとは異なり、このプラットフォームは高度なAI技術をStory Cameraのインターフェースに直接統合することで、アニメーションプロセスを簡素化している。同社は、技術的なスキルに関係なく、すべてのユーザーがダイナミックな動きとクリエイティブなエ
 最後のチャンス:TechCrunch Disrupt 2025 パス1,130ドル割引 - 間もなく終了
最終カウントダウン:TechCrunch Disrupt 2025のチケットが最大1,130ドル割引時間が迫っています!TechCrunch Disrupt 2025の割引パスが1,130ドルもお得に手に入る可能性があります。個人パスとグループ・バンドル(最大30%オフ)は、2月28日午後11時59分(PT)まで最安値でお求めいただけます。画期的な技術革新の20年を祝う今年のカンファレンス(10月
最後のチャンス:TechCrunch Disrupt 2025 パス1,130ドル割引 - 間もなく終了
最終カウントダウン:TechCrunch Disrupt 2025のチケットが最大1,130ドル割引時間が迫っています!TechCrunch Disrupt 2025の割引パスが1,130ドルもお得に手に入る可能性があります。個人パスとグループ・バンドル(最大30%オフ)は、2月28日午後11時59分(PT)まで最安値でお求めいただけます。画期的な技術革新の20年を祝う今年のカンファレンス(10月













