
















 首頁
首頁人工智慧簡化通往人工客服專員的途徑
最新研究顯示,開源的ChatGPT式人工智慧系統有望運用自然語言,在客服中心將來電者直接轉接至適當人員,從而避開那些令人沮喪且頻繁變動的選單系統——這些系統往往給人刻意設置障礙之感。
聯繫真人客服人員往往是令人沮喪的折磨,來電者必須緩慢地從多選項中逐一嘗試,卻常不確定哪個選項能解決其具體問題。當所有選項皆不適用時,精明的用戶常會發展出技巧與變通方法,以期聯繫到真人客服並逃離「選項地獄」。對許多人而言,這種體驗充滿對抗性且極不友善。
客服中心成為人工智慧強化或取代的首要目標,實屬意料之中。儘管部分專家呼籲謹慎行事,自動化客服中心仍是科技新聞的低垂果實,更是人工智慧驅動創新的潛力領域——此領域能帶來異常快速的投資回報。
封閉體系
然而,開源原則與公開數據在此領域鮮少被採用,箇中緣由不言而喻。企業在自動化客戶回應系統時,極少願意分享支撐其競爭優勢的數據、方法論或企業智慧財產。
共享資源將削弱市場優勢。更關鍵的是,人工智慧系統可能洩漏敏感資訊,此舉亦伴隨重大法律風險。
這導致多家資金雄厚企業各自獨立開發AI客服中心系統,難免造成資源重複投入。同時也催生大量B2B新創與傳統企業,競相滿足日益增長的AI客服需求。
PolyAI語音助理為虛構企業「奧古斯塔草坪護理」啟動客服通話,運用大量訓練對話在現有呼叫中心架構中實現自動化回應。來源
此外,消除複雜客服選單帶來的挫折感亦推動相關研究。然而多數成果未發表於Arxiv等開放平台,反映互動式語音應答(IVR)開發通常具有專有性質。
因此,與客服人工智慧自動化相關的研究、數據及商業智慧皆被嚴密保護。即便在法律上安全無虞的數據環境下使用此類系統是可行的選擇——這點尚存疑慮——現存的開源替代方案仍寥寥可數。
本地通話
在此背景下,哥倫比亞的新研究論文可謂一抹亮色,試圖將IVR開發稍稍從企業金庫中釋放出來。 這篇題為《超越IVR按鍵音:運用大型語言模型實現客戶意圖路由》的簡明研究,出自波哥大卡爾達斯大學研究員之手。該研究宣稱是首個採用大型語言模型(LLMs)建立客戶意圖路由(CIR)系統功能架構的非專有專案。
該專案捨棄真實通話數據與專有選單架構,轉而運用三種AI模型從零建構所有元件:其一設計逼真的呼叫中心選單,其二模擬數百則用戶投訴,其三則作為聊天機器人,將查詢導向正確目的地。
最終建構出一個完全合成卻極具說服力的測試環境,包含虛構電信公司及920種獨特用戶查詢。此架構使實驗得以探索現行AI如何解讀模糊非結構化語音並精準導向來電者,同時完全避開法律風險。
測試顯示,該系統能以高達89.13%的準確度將自由形式的投訴精準對應至正確處理管道,尤其當提供「扁平化」選單選項而非詳細描述時表現更佳。
研究同時發現,當來電者使用口語化或多變的表達時,AI的錯誤率會上升。但部分失誤並非源於AI理解錯誤,而是電話選單本身存在混淆性。
![客戶互動範例,作為新專案的一部分分享。[來源] https://figshare.com/articles/dataset/Beyond_IVR_Touch-Tones_Customer_Intent_Routing_using_LLMs/30118690](https://img.xix.ai/uploads/61/69023b8fbf62b.webp)
新專案分享的客戶互動實例。來源
該專案數據已公開釋出。
方法
三階段方法首先由模型為虛構電信公司建立詳盡電話選單。第二個模型生成獨特的來電者訊息——包含直白表述、改寫版本及口語化表達——以模擬真實語音模式,共產生920個範例。
第三模型則專責依據通話者訊息及菜單版本,將其轉接至正確部門。此架構使實驗完全可重現,無需使用真實通話數據或暴露客戶資訊。
![為三方合作模式所選定的三套系統。[來源] https://arxiv.org/pdf/2510.21715](https://img.xix.ai/uploads/87/69023b91dcc46.webp)
採用三方協作模式的三大系統。來源
所用模型分別為 gpt-3.5-turbo、gpt-4o-mini 及 gpt-4.1-mini。
為模擬真實客服情境,需從零合成複雜電話選單。因缺乏相關資料集,故以gpt-3.5-turbo模型生成虛構電信供應商的完整多分支結構。
每個分支代表計費、技術支援、帳戶管理及 新服務等服務領域,並具備真實的子選項與不同層級深度。為測試目的,共創建兩種選單版本:模擬人類可讀格式的純文字層級結構,以及附對應按鍵序列的端點清單。
此設計使我們能同時測試路由問題的精細版與簡化版:

向AI提供兩種電話選單版本:詳盡的文字層級結構與簡化的直達選項清單,藉此比較兩種格式引導來電者至正確服務據點的成效。
為生成測試來電訊息,第二語言模型針對每個選單終端點生成十組獨特投訴或請求範例。
每則訊息隨後被改寫成多種變體,以反映真實使用者表達問題的多樣性,包含長度變化、語氣調整,甚至加入輕微錯誤或填充詞。
這920則初始訊息旨在測試系統準確性,並模擬自然對話的不可預測性。
第三階段採用兩種不同的互動式語音應答呈現格式,測試最終模型將訊息對應至正確選單目的地的能力。
第一種版本中,AI 獲得完整的電話樹描述性綱要;第二種版本僅提供最終目的地清單及其按鍵序列。
此舉旨在驗證簡化選單能否提升模型路由通話的效能。兩種情境下,系統皆採逐則訊息處理模式,並被要求僅回傳路徑(不含額外文字),以利自動化評分機制運作。
隔離機制
為避免測試結果交叉污染,各模型均採隔離運作。首個模型負責草擬電話選單,但最終版本經人工修訂以確保其他系統無法預先知曉。
來電訊息由 gpt-4o-mini 獨立生成,僅使用終端點名稱且無法接觸選單結構。最後,負責路由的 gpt-4.1-mini 僅能存取選單文字與來電訊息,不參與任何內容創作。
指標
採用兩項標準指標評估路由系統效能:準確度(定義為模型提供完全正確路徑之案例百分比,例如1-2-3)。同時生成混淆矩陣*以精準定位錯誤源頭。評估過程透過 Python 執行,使用 pandas 與 scikit-learn 函式庫。
結果
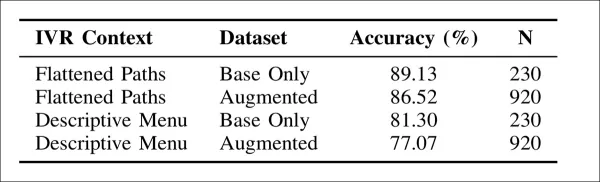
測試顯示模型準確度顯著受選單呈現形式影響:採用扁平化選單路徑清單時,系統在簡易資料集上達到89.13%準確度;而使用完整描述性選單時準確度則降至81.30%。
第三個模型(LLM3)在不同提示格式與資料集類型下的路徑準確度顯示:扁平化路徑始終優於層級式描述,而使用轉述或非正式語言輸入時準確度略有下降。
此趨勢在規模更大、語言多樣性更高的數據集中持續顯現:扁平化版本再次表現更優,準確率達86.52%,而描述性格式僅為77.07%。
論文指出,這些結果表明相較於冗長的層級描述,更簡潔的清單式提示能幫助模型更可靠地匹配查詢。
當引入改寫或非正式的來電者訊息時,準確度亦略有下滑,顯示雖然增加多樣性可提升真實感,卻也使分類更為困難。
論文結論指出:
「研究結果顯示,相較於冗長菜單描述(最低僅77.07%),當大型語言模型接收扁平化IVR路徑時(最高達89.13%),能更精準地轉接客戶意圖。這表明簡潔結構化的提示能減少干擾,更適合路由任務。
此結果支持『清晰簡潔能提升大型語言模型在分類情境中表現』的觀點。
「此外,將選單轉換為扁平化路徑是可直接自動化部署的實用流程。」
結論
在通常以保密與排他性為特徵的領域中,開放式研究的興起令人振奮。關鍵問題在於:未來系統是否仍需依賴「框架」架構為大型語言模型提供語境,抑或模型僅需存取本地商業智慧資料,從而免除企業與第三方共享數據的必要性。
最終,本文探討的核心設計原則很可能被未來人工智慧系統自然採用——其應用範圍甚至將超越客服領域,無需針對此特定用例進行特殊調整。
*詳情請參閱原始論文。
初版發佈於2025年10月29日(星期三)
相關文章
 iOS 27 將推出具備聊天機器人介面的獨立版 Siri 應用程式
距離蘋果 2026 年全球開發者大會(WWDC)開辦不到一個月,知名科技記者馬克·古爾曼(Mark Gurman)分享了關於 iOS 27 的最新消息。 在代號為「Rave」的即將推出的系統中,Siri 將以獨立應用程式的形式強勢回歸——這標誌著睽違 15 年後,Siri 再次擁有專屬的入口。更新後的Siri將作為一款常駐的智能助理,具備類似聊天機器人的介面,支援對話記錄、檔案上傳及內容釘選功能。
AI 專家進駐:大型模型進駐工廠,工業製造邁入新紀元
在生物發酵、建築設計,甚至廢水處理等領域的前線,一種新型的「員工」正悄然重塑傳統製造業。他們並非滿身大汗的工人,而是被稱為「AI大師」的工業時間序列控制大型模型,其名稱為ManuDrive。上海交通大學人工智慧與微結構實驗室(AIMS Lab)近期的一項突破性成果,已引起業界的矚目。由李金金教授創立的這家科技公司,正將人工智慧的應用範圍從文字生成與影像處理,拓展至充滿噪音與油漬的工廠現場。 與常見
Google 相片運用人工智慧,讓《窈窕淑女》中那座標誌性的衣櫥栩栩如生
Google Photos 於週三宣布了一項由人工智慧驅動的新功能,這項功能將很快能將您衣物的照片轉化為數位衣櫥,讓您能創造嶄新的穿搭組合,甚至進行虛擬試穿。這個概念顯然是受到電影《窈窕淑女》中 Cher 那座標誌性的虛擬衣櫥啟發,她在片中可以瀏覽眾多服裝組合,同時決定該穿什麼。Google表示,這項功能將運用AI技術,根據您Google相簿圖庫中的衣物,自動建立您的衣櫥數位副本。在應用程式內,您
相關專題推薦
生產率
iOS 27 將推出具備聊天機器人介面的獨立版 Siri 應用程式
距離蘋果 2026 年全球開發者大會(WWDC)開辦不到一個月,知名科技記者馬克·古爾曼(Mark Gurman)分享了關於 iOS 27 的最新消息。 在代號為「Rave」的即將推出的系統中,Siri 將以獨立應用程式的形式強勢回歸——這標誌著睽違 15 年後,Siri 再次擁有專屬的入口。更新後的Siri將作為一款常駐的智能助理,具備類似聊天機器人的介面,支援對話記錄、檔案上傳及內容釘選功能。
AI 專家進駐:大型模型進駐工廠,工業製造邁入新紀元
在生物發酵、建築設計,甚至廢水處理等領域的前線,一種新型的「員工」正悄然重塑傳統製造業。他們並非滿身大汗的工人,而是被稱為「AI大師」的工業時間序列控制大型模型,其名稱為ManuDrive。上海交通大學人工智慧與微結構實驗室(AIMS Lab)近期的一項突破性成果,已引起業界的矚目。由李金金教授創立的這家科技公司,正將人工智慧的應用範圍從文字生成與影像處理,拓展至充滿噪音與油漬的工廠現場。 與常見
Google 相片運用人工智慧,讓《窈窕淑女》中那座標誌性的衣櫥栩栩如生
Google Photos 於週三宣布了一項由人工智慧驅動的新功能,這項功能將很快能將您衣物的照片轉化為數位衣櫥,讓您能創造嶄新的穿搭組合,甚至進行虛擬試穿。這個概念顯然是受到電影《窈窕淑女》中 Cher 那座標誌性的虛擬衣櫥啟發,她在片中可以瀏覽眾多服裝組合,同時決定該穿什麼。Google表示,這項功能將運用AI技術,根據您Google相簿圖庫中的衣物,自動建立您的衣櫥數位副本。在應用程式內,您
相關專題推薦
生產率
 AI 架構設計師:運用自然語言建構可擴展的系統架構
AI 架構設計師:運用自然語言建構可擴展的系統架構
立即在 XIX.AI 探索 2026 年最佳 AI 架構設計工具。我們精心挑選並廣受好評的清單,匯集了強大且具革命性的解決方案,讓您能透過自然語言建構可擴展的系統架構。透過實務見解,比較免費與付費選項的差異。立即釋放您的 AI 優勢,並簡化開發流程。
 10 個工具
10 個工具
 xix.ai
漫畫創作
AI角色建立工具:為漫畫主角生成詳細的背景故事及視覺參考資料
xix.ai
漫畫創作
AI角色建立工具:為漫畫主角生成詳細的背景故事及視覺參考資料
2026年最新最佳AI角色建立工具:發現那些備受好評的工具,它們能夠幫助你為漫畫角色生成詳細的背景故事和視覺素材。我們精心整理的這份每週更新的列表會根據實際測試結果,對比免費與付費選項的優劣。找到這些強大且能改變創作流程的工具,幫助你塑造引人入勝的角色,提升創作效率。立即訪問XIX.AI檢視排名,找到最適合你的故事創作助手吧。
10 個工具
xix.ai
健康與養生
AI 孕期輔助系統:生成安全且按孕期分階段的運動與營養計畫
探索 2026 年最佳 AI 孕期輔助工具,為您量身打造安全且針對各孕期的運動與營養計畫。獲取精選的高評分推薦,包含免費與付費方案的比較,以及實用經驗分享。透過 XIX.AI 的專家指南,開啟您最健康的孕期旅程。立即探索。
10 個工具
xix.ai
寫作
最佳免費且無法被偵測的 AI 寫手:將機械化的草稿轉化為自然、類人化的散文
立即前往 XIX.AI,探索 2026 年最頂尖的免費且難以被察覺的 AI 寫手。我們精心篩選的頂級清單,能協助您將生硬的草稿轉化為自然流暢、宛如人類撰寫的文字。透過實際測試與每週更新的排行榜,比較免費與付費選項的優劣。立即解鎖您的 AI 寫作優勢。
10 個工具
xix.ai
圖像編輯
用於短劇故事板的AI藝術生成工具:幻想與都市浪漫題材的角色設計
2026最新推薦:探索最適合用於短劇故事板製作的AI藝術生成工具。我們精心挑選了眾多頂級工具,幫助您創作出引人入勝的幻想角色和都市浪漫角色。您可以對比免費與付費選項,檢視實際測試結果,從而找到最適合自己的創意工具。XIX.AI還會每週更新排名並提供專家分析,讓您立即開始將故事視覺化呈現吧!
10 個工具
xix.ai
寫作
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
最新研究顯示,開源的ChatGPT式人工智慧系統有望運用自然語言,在客服中心將來電者直接轉接至適當人員,從而避開那些令人沮喪且頻繁變動的選單系統——這些系統往往給人刻意設置障礙之感。
聯繫真人客服人員往往是令人沮喪的折磨,來電者必須緩慢地從多選項中逐一嘗試,卻常不確定哪個選項能解決其具體問題。當所有選項皆不適用時,精明的用戶常會發展出技巧與變通方法,以期聯繫到真人客服並逃離「選項地獄」。對許多人而言,這種體驗充滿對抗性且極不友善。
客服中心成為人工智慧強化或取代的首要目標,實屬意料之中。儘管部分專家呼籲謹慎行事,自動化客服中心仍是科技新聞的低垂果實,更是人工智慧驅動創新的潛力領域——此領域能帶來異常快速的投資回報。
封閉體系
然而,開源原則與公開數據在此領域鮮少被採用,箇中緣由不言而喻。企業在自動化客戶回應系統時,極少願意分享支撐其競爭優勢的數據、方法論或企業智慧財產。
共享資源將削弱市場優勢。更關鍵的是,人工智慧系統可能洩漏敏感資訊,此舉亦伴隨重大法律風險。
這導致多家資金雄厚企業各自獨立開發AI客服中心系統,難免造成資源重複投入。同時也催生大量B2B新創與傳統企業,競相滿足日益增長的AI客服需求。

PolyAI語音助理為虛構企業「奧古斯塔草坪護理」啟動客服通話,運用大量訓練對話在現有呼叫中心架構中實現自動化回應。來源
此外,消除複雜客服選單帶來的挫折感亦推動相關研究。然而多數成果未發表於Arxiv等開放平台,反映互動式語音應答(IVR)開發通常具有專有性質。
因此,與客服人工智慧自動化相關的研究、數據及商業智慧皆被嚴密保護。即便在法律上安全無虞的數據環境下使用此類系統是可行的選擇——這點尚存疑慮——現存的開源替代方案仍寥寥可數。
本地通話
在此背景下,哥倫比亞的新研究論文可謂一抹亮色,試圖將IVR開發稍稍從企業金庫中釋放出來。 這篇題為《超越IVR按鍵音:運用大型語言模型實現客戶意圖路由》的簡明研究,出自波哥大卡爾達斯大學研究員之手。該研究宣稱是首個採用大型語言模型(LLMs)建立客戶意圖路由(CIR)系統功能架構的非專有專案。
該專案捨棄真實通話數據與專有選單架構,轉而運用三種AI模型從零建構所有元件:其一設計逼真的呼叫中心選單,其二模擬數百則用戶投訴,其三則作為聊天機器人,將查詢導向正確目的地。
最終建構出一個完全合成卻極具說服力的測試環境,包含虛構電信公司及920種獨特用戶查詢。此架構使實驗得以探索現行AI如何解讀模糊非結構化語音並精準導向來電者,同時完全避開法律風險。
測試顯示,該系統能以高達89.13%的準確度將自由形式的投訴精準對應至正確處理管道,尤其當提供「扁平化」選單選項而非詳細描述時表現更佳。
研究同時發現,當來電者使用口語化或多變的表達時,AI的錯誤率會上升。但部分失誤並非源於AI理解錯誤,而是電話選單本身存在混淆性。
![客戶互動範例,作為新專案的一部分分享。[來源] https://figshare.com/articles/dataset/Beyond_IVR_Touch-Tones_Customer_Intent_Routing_using_LLMs/30118690](https://img.xix.ai/uploads/61/69023b8fbf62b.webp.webp)
新專案分享的客戶互動實例。來源
該專案數據已公開釋出。
方法
三階段方法首先由模型為虛構電信公司建立詳盡電話選單。第二個模型生成獨特的來電者訊息——包含直白表述、改寫版本及口語化表達——以模擬真實語音模式,共產生920個範例。
第三模型則專責依據通話者訊息及菜單版本,將其轉接至正確部門。此架構使實驗完全可重現,無需使用真實通話數據或暴露客戶資訊。
![為三方合作模式所選定的三套系統。[來源] https://arxiv.org/pdf/2510.21715](https://img.xix.ai/uploads/87/69023b91dcc46.webp.webp)
採用三方協作模式的三大系統。來源
所用模型分別為 gpt-3.5-turbo、gpt-4o-mini 及 gpt-4.1-mini。
為模擬真實客服情境,需從零合成複雜電話選單。因缺乏相關資料集,故以gpt-3.5-turbo模型生成虛構電信供應商的完整多分支結構。
每個分支代表計費、技術支援、帳戶管理及 新服務等服務領域,並具備真實的子選項與不同層級深度。為測試目的,共創建兩種選單版本:模擬人類可讀格式的純文字層級結構,以及附對應按鍵序列的端點清單。
此設計使我們能同時測試路由問題的精細版與簡化版:

向AI提供兩種電話選單版本:詳盡的文字層級結構與簡化的直達選項清單,藉此比較兩種格式引導來電者至正確服務據點的成效。
為生成測試來電訊息,第二語言模型針對每個選單終端點生成十組獨特投訴或請求範例。
每則訊息隨後被改寫成多種變體,以反映真實使用者表達問題的多樣性,包含長度變化、語氣調整,甚至加入輕微錯誤或填充詞。
這920則初始訊息旨在測試系統準確性,並模擬自然對話的不可預測性。
第三階段採用兩種不同的互動式語音應答呈現格式,測試最終模型將訊息對應至正確選單目的地的能力。
第一種版本中,AI 獲得完整的電話樹描述性綱要;第二種版本僅提供最終目的地清單及其按鍵序列。
此舉旨在驗證簡化選單能否提升模型路由通話的效能。兩種情境下,系統皆採逐則訊息處理模式,並被要求僅回傳路徑(不含額外文字),以利自動化評分機制運作。
隔離機制
為避免測試結果交叉污染,各模型均採隔離運作。首個模型負責草擬電話選單,但最終版本經人工修訂以確保其他系統無法預先知曉。
來電訊息由 gpt-4o-mini 獨立生成,僅使用終端點名稱且無法接觸選單結構。最後,負責路由的 gpt-4.1-mini 僅能存取選單文字與來電訊息,不參與任何內容創作。
指標
採用兩項標準指標評估路由系統效能:準確度(定義為模型提供完全正確路徑之案例百分比,例如1-2-3)。同時生成混淆矩陣*以精準定位錯誤源頭。評估過程透過 Python 執行,使用 pandas 與 scikit-learn 函式庫。
結果
測試顯示模型準確度顯著受選單呈現形式影響:採用扁平化選單路徑清單時,系統在簡易資料集上達到89.13%準確度;而使用完整描述性選單時準確度則降至81.30%。

第三個模型(LLM3)在不同提示格式與資料集類型下的路徑準確度顯示:扁平化路徑始終優於層級式描述,而使用轉述或非正式語言輸入時準確度略有下降。
此趨勢在規模更大、語言多樣性更高的數據集中持續顯現:扁平化版本再次表現更優,準確率達86.52%,而描述性格式僅為77.07%。
論文指出,這些結果表明相較於冗長的層級描述,更簡潔的清單式提示能幫助模型更可靠地匹配查詢。
當引入改寫或非正式的來電者訊息時,準確度亦略有下滑,顯示雖然增加多樣性可提升真實感,卻也使分類更為困難。
論文結論指出:
「研究結果顯示,相較於冗長菜單描述(最低僅77.07%),當大型語言模型接收扁平化IVR路徑時(最高達89.13%),能更精準地轉接客戶意圖。這表明簡潔結構化的提示能減少干擾,更適合路由任務。
此結果支持『清晰簡潔能提升大型語言模型在分類情境中表現』的觀點。
「此外,將選單轉換為扁平化路徑是可直接自動化部署的實用流程。」
結論
在通常以保密與排他性為特徵的領域中,開放式研究的興起令人振奮。關鍵問題在於:未來系統是否仍需依賴「框架」架構為大型語言模型提供語境,抑或模型僅需存取本地商業智慧資料,從而免除企業與第三方共享數據的必要性。
最終,本文探討的核心設計原則很可能被未來人工智慧系統自然採用——其應用範圍甚至將超越客服領域,無需針對此特定用例進行特殊調整。
*詳情請參閱原始論文。
初版發佈於2025年10月29日(星期三)










 iOS 27 將推出具備聊天機器人介面的獨立版 Siri 應用程式
距離蘋果 2026 年全球開發者大會(WWDC)開辦不到一個月,知名科技記者馬克·古爾曼(Mark Gurman)分享了關於 iOS 27 的最新消息。 在代號為「Rave」的即將推出的系統中,Siri 將以獨立應用程式的形式強勢回歸——這標誌著睽違 15 年後,Siri 再次擁有專屬的入口。更新後的Siri將作為一款常駐的智能助理,具備類似聊天機器人的介面,支援對話記錄、檔案上傳及內容釘選功能。
iOS 27 將推出具備聊天機器人介面的獨立版 Siri 應用程式
距離蘋果 2026 年全球開發者大會(WWDC)開辦不到一個月,知名科技記者馬克·古爾曼(Mark Gurman)分享了關於 iOS 27 的最新消息。 在代號為「Rave」的即將推出的系統中,Siri 將以獨立應用程式的形式強勢回歸——這標誌著睽違 15 年後,Siri 再次擁有專屬的入口。更新後的Siri將作為一款常駐的智能助理,具備類似聊天機器人的介面,支援對話記錄、檔案上傳及內容釘選功能。
 AI 專家進駐:大型模型進駐工廠,工業製造邁入新紀元
在生物發酵、建築設計,甚至廢水處理等領域的前線,一種新型的「員工」正悄然重塑傳統製造業。他們並非滿身大汗的工人,而是被稱為「AI大師」的工業時間序列控制大型模型,其名稱為ManuDrive。上海交通大學人工智慧與微結構實驗室(AIMS Lab)近期的一項突破性成果,已引起業界的矚目。由李金金教授創立的這家科技公司,正將人工智慧的應用範圍從文字生成與影像處理,拓展至充滿噪音與油漬的工廠現場。 與常見
AI 專家進駐:大型模型進駐工廠,工業製造邁入新紀元
在生物發酵、建築設計,甚至廢水處理等領域的前線,一種新型的「員工」正悄然重塑傳統製造業。他們並非滿身大汗的工人,而是被稱為「AI大師」的工業時間序列控制大型模型,其名稱為ManuDrive。上海交通大學人工智慧與微結構實驗室(AIMS Lab)近期的一項突破性成果,已引起業界的矚目。由李金金教授創立的這家科技公司,正將人工智慧的應用範圍從文字生成與影像處理,拓展至充滿噪音與油漬的工廠現場。 與常見
 Google 相片運用人工智慧,讓《窈窕淑女》中那座標誌性的衣櫥栩栩如生
Google Photos 於週三宣布了一項由人工智慧驅動的新功能,這項功能將很快能將您衣物的照片轉化為數位衣櫥,讓您能創造嶄新的穿搭組合,甚至進行虛擬試穿。這個概念顯然是受到電影《窈窕淑女》中 Cher 那座標誌性的虛擬衣櫥啟發,她在片中可以瀏覽眾多服裝組合,同時決定該穿什麼。Google表示,這項功能將運用AI技術,根據您Google相簿圖庫中的衣物,自動建立您的衣櫥數位副本。在應用程式內,您
Google 相片運用人工智慧,讓《窈窕淑女》中那座標誌性的衣櫥栩栩如生
Google Photos 於週三宣布了一項由人工智慧驅動的新功能,這項功能將很快能將您衣物的照片轉化為數位衣櫥,讓您能創造嶄新的穿搭組合,甚至進行虛擬試穿。這個概念顯然是受到電影《窈窕淑女》中 Cher 那座標誌性的虛擬衣櫥啟發,她在片中可以瀏覽眾多服裝組合,同時決定該穿什麼。Google表示,這項功能將運用AI技術,根據您Google相簿圖庫中的衣物,自動建立您的衣櫥數位副本。在應用程式內,您

立即在 XIX.AI 探索 2026 年最佳 AI 架構設計工具。我們精心挑選並廣受好評的清單,匯集了強大且具革命性的解決方案,讓您能透過自然語言建構可擴展的系統架構。透過實務見解,比較免費與付費選項的差異。立即釋放您的 AI 優勢,並簡化開發流程。
10 個工具
xix.ai

2026年最新最佳AI角色建立工具:發現那些備受好評的工具,它們能夠幫助你為漫畫角色生成詳細的背景故事和視覺素材。我們精心整理的這份每週更新的列表會根據實際測試結果,對比免費與付費選項的優劣。找到這些強大且能改變創作流程的工具,幫助你塑造引人入勝的角色,提升創作效率。立即訪問XIX.AI檢視排名,找到最適合你的故事創作助手吧。
10 個工具
xix.ai

探索 2026 年最佳 AI 孕期輔助工具,為您量身打造安全且針對各孕期的運動與營養計畫。獲取精選的高評分推薦,包含免費與付費方案的比較,以及實用經驗分享。透過 XIX.AI 的專家指南,開啟您最健康的孕期旅程。立即探索。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最頂尖的免費且難以被察覺的 AI 寫手。我們精心篩選的頂級清單,能協助您將生硬的草稿轉化為自然流暢、宛如人類撰寫的文字。透過實際測試與每週更新的排行榜,比較免費與付費選項的優劣。立即解鎖您的 AI 寫作優勢。
10 個工具
xix.ai

2026最新推薦:探索最適合用於短劇故事板製作的AI藝術生成工具。我們精心挑選了眾多頂級工具,幫助您創作出引人入勝的幻想角色和都市浪漫角色。您可以對比免費與付費選項,檢視實際測試結果,從而找到最適合自己的創意工具。XIX.AI還會每週更新排名並提供專家分析,讓您立即開始將故事視覺化呈現吧!
10 個工具
xix.ai

在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai













