Новые исследования показывают, что системы искусственного интеллекта с открытым исходным кодом, подобные ChatGPT, могут потенциально использовать естественный язык для соединения звонящих с нужным человеком в колл-центре, минуя необходимость проходить через сложные и часто меняющиеся системы меню, которые зачастую кажутся намеренно затруднительными.
Дозвониться до живого оператора может быть утомительным испытанием, поскольку звонящие должны медленно проходить через несколько вариантов выбора, часто не зная, какой из них подходит для их конкретной проблемы. Когда ни один из них не подходит, опытные пользователи часто придумывают хитрости и обходные пути, чтобы дозвониться до живого оператора и избежать «ада вариантов». Для многих этот опыт кажется враждебным и недружелюбным по отношению к пользователю.
Неудивительно, что колл-центры являются основной целью для расширения или замены искусственного интеллекта. Несмотря на то, что некоторые эксперты призывают к осторожности, автоматизация колл-центров остается легкой добычей для технологических заголовков и многообещающей областью для инноваций на основе искусственного интеллекта, которые могут обеспечить необычайно быструю окупаемость инвестиций.
Закрытый магазин
Однако принципы открытого исходного кода и общедоступные данные редко применяются в этой области, и на то есть веские причины. Компании, автоматизирующие свои системы реагирования на запросы клиентов, не имеют стимула делиться данными, методологиями или корпоративной интеллектуальной собственностью, которые лежат в основе их конкурентного преимущества.
Обмен такими ресурсами подорвал бы их рыночное преимущество. Что еще более важно, поскольку системы ИИ могут быть подвержены утечке конфиденциальной информации, это также несет значительные правовые риски.
Это привело к тому, что несколько хорошо финансируемых компаний независимо друг от друга разработали системы колл-центров на базе ИИ, что неизбежно привело к дублированию некоторых усилий. Это также способствовало росту числа стартапов в сфере B2B и устоявшихся игроков, стремящихся удовлетворить растущий спрос на возможности обслуживания клиентов на базе ИИ.
Голосовой помощник PolyAI инициирует звонок в службу поддержки клиентов вымышленной компании «Augusta Lawn Care», используя обширные тренировочные диалоги для автоматизации ответов в рамках существующей инфраструктуры колл-центра. Источник
Кроме того, стремление устранить неудобства, связанные со сложными меню колл-центров, стимулировало исследовательские усилия. Однако большинство результатов не публикуется на Arxiv или других открытых платформах, что отражает типичный закрытый характер разработки интерактивного голосового ответа (IVR).
В результате исследования, данные и бизнес-аналитика, связанные с автоматизацией обслуживания клиентов с помощью ИИ, тщательно охраняются. Существует очень мало альтернатив с открытым исходным кодом, даже если использование таких систем с юридически защищенными данными было бы жизнеспособным вариантом, что сомнительно.
Местный звонок
На этом фоне новая статья из Колумбии является долгожданной попыткой вывести разработку IVR из корпоративного хранилища. Краткое исследование под названием «Beyond IVR Touch-Tones: Customer Intent Routing using LLMs»(За пределами IVR Touch-Tones: маршрутизация намерений клиентов с использованием LLM) было проведено исследователем из Университета Дистриталь Франсиско Хосе де Кальдас в Боготе. Оно утверждает, что является первым непатентованным проектом, использующим большие языковые модели (LLM) для создания функциональной схемы системы маршрутизации намерений клиентов (CIR).
Вместо использования реальных данных о звонках или проприетарных структур меню, проект генерирует все компоненты с нуля, используя три модели ИИ: одну для проектирования реалистичного меню call-центра, другую для моделирования сотен жалоб звонящих и третью для работы в качестве чат-бота, направляющего эти запросы по правильному адресу.
Результатом является полностью синтетическая, но убедительная тестовая среда с вымышленной телекоммуникационной компанией и 920 различными запросами пользователей. Такая настройка позволяет эксперименту исследовать, насколько хорошо современный ИИ интерпретирует неясную, неструктурированную речь и направляет звонящих соответствующим образом, при этом избегая юридических рисков.
Тесты показывают, что система может точно сопоставить жалобы звонящих в свободной форме с правильным адресатом с точностью до 89,13%, особенно когда ей предоставляются «упрощенные» варианты меню вместо подробных описаний.
Исследование также показало, что ИИ делал больше ошибок, когда звонящие использовали неформальный или разнообразный язык. Однако некоторые ошибки происходили не из-за того, что ИИ неправильно понял, а из-за того, что само телефонное меню было запутанным.
Примеры взаимодействия с клиентами, представленные в рамках нового проекта. Источник
Данные проекта были обнародованы.
Метод
Трехсторонний подход начался с модели, создавшей подробное телефонное меню для вымышленной телекоммуникационной компании. Вторая модель генерировала уникальные сообщения звонящих — некоторые прямые, другие перефразированные или более разговорные — для имитации реалистичных речевых моделей. Всего было сгенерировано 920 примеров.
Третья модель была предназначена для соединения каждого звонящего с нужным отделом исключительно на основе сообщения и версии меню. Эта структура сделала эксперимент полностью воспроизводимым без необходимости использования реальных данных о звонках или раскрытия информации о клиентах.
Три системы, выбранные для трехстороннего подхода. Источник
Использовались модели gpt-3.5-turbo, gpt-4o-mini и gpt-4.1-mini соответственно.
Чтобы имитировать реальную ситуацию обслуживания клиентов, необходимо было с нуля синтезировать сложное телефонное меню. Из-за отсутствия соответствующих наборов данных модель gpt-3.5-turbo была запрограммирована на генерацию полной многоуровневой структуры для вымышленного телекоммуникационного провайдера.
Каждая ветвь представляла области обслуживания, такие как биллинговая служба, техническая поддержка, управление учетными записями и новые услуги, с реалистичными подпунктами и различной глубиной. Для тестирования были созданы две версии меню: иерархия в виде простого текста, имитирующая формат, понятный человеку, и список конечных точек с соответствующими последовательностями кнопок.
Это позволило протестировать как подробную, так и упрощенную версию задачи маршрутизации:
ИИ были предоставлены две версии телефонного меню: подробная текстовая иерархия и упрощенный список прямых опций меню, чтобы сравнить, насколько хорошо каждый формат поддерживает маршрутизацию звонящих в нужное место.
Для генерации тестовых сообщений звонящих вторая языковая модель создала набор оригинальных жалоб или запросов, по десять уникальных примеров на каждую конечную точку меню.
Затем каждое из них было перефразировано в нескольких вариантах, чтобы отразить разнообразные способы, которыми реальные люди выражают свои проблемы, включая изменения в длине, тоне и даже незначительные ошибки или слова-заполнители.
920 исходных сообщений были созданы для тестирования точности системы и моделирования непредсказуемости естественного разговора.
На третьем этапе способность окончательной модели сопоставить каждое сообщение с правильным пунктом назначения меню была протестирована с использованием двух различных форматов представления IVR.
Для первой версии ИИ получил полное описательное изложение телефонного дерева. Для второй он видел только список конечных пунктов назначения с последовательностью кнопок.
Цель состояла в том, чтобы определить, поможет ли упрощенное меню модели более эффективно маршрутизировать вызовы. В обоих случаях система обрабатывала по одному сообщению за раз и получала инструкцию возвращать только путь без дополнительного текста, чтобы обеспечить автоматическую оценку.
Изоляция
Чтобы предотвратить загрязнение результатов тестирования, каждая модель была изолирована. Первая модель составила черновой вариант телефонного меню, но он был доработан вручную, чтобы остаться незнакомым для других систем.
Сообщения вызывающего абонента генерировались отдельно с помощью gpt-4o-mini, используя только названия конечных точек без доступа к структуре меню. Наконец, gpt-4.1-mini, который выполнял маршрутизацию, имел доступ только к тексту меню и входящим сообщениям, не участвуя в их создании.
Показатели
Две стандартные метрики оценивали производительность системы маршрутизации: точность, определяемая как процент случаев, когда модель предоставляла точно правильный путь (например, 1-2-3). Также были сгенерированы матрицы путаницы*, чтобы точно определить места ошибок. Оценки проводились в Python с использованием библиотек pandas и scikit-learn.
Результаты
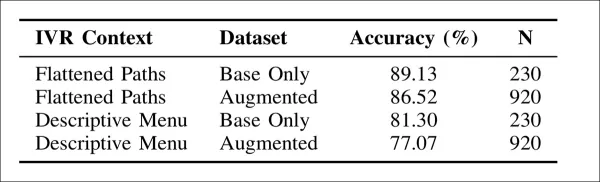
Тестирование показало, что точность модели в значительной степени зависела от представления меню. С упрощенным списком путей меню система достигла точности 89,13 % на более простом наборе данных по сравнению с 81,30 % с полным описательным меню.
Точность маршрутизации для третьей модели (LLM3) при различных форматах запросов и типах наборов данных показала, что упрощенные пути меню стабильно превосходили иерархические описания, а точность немного снижалась при использовании перефразированных или неформальных языковых вводов.
Эта тенденция сохранилась и при использовании более крупного и лингвистически разнообразного набора данных, где упрощенная версия снова показала лучшие результаты, набрав 86,52% против 77,07% для описательного формата.
В статье отмечается, что эти результаты свидетельствуют о том, что более простые подсказки на основе списков помогали модели более надежно сопоставлять запросы, чем длинные иерархические описания.
Точность также немного снизилась при введении перефразированных и неформальных сообщений вызывающих абонентов, что указывает на то, что хотя увеличение разнообразия повысило реалистичность, оно также затруднило классификацию.
В статье делается следующий вывод:
«Наши результаты показывают, что LLM более точно направляют намерения клиентов, когда им предоставляются упрощенные пути IVR (до 89,13%), по сравнению с подробными описаниями меню (всего 77,07%). Это говорит о том, что лаконичные, структурированные подсказки уменьшают шум и лучше подходят для задач маршрутизации.
Это подтверждает идею о том, что ясность и краткость улучшают производительность LLM в сценариях классификации.
Кроме того, преобразование меню в упрощенные пути является простым и автоматизируемым процессом для внедрения в реальных условиях».
Заключение
Отрадно видеть появление открытых исследований в области, которая обычно характеризуется секретностью и эксклюзивностью. Остается ключевой вопрос: потребуют ли будущие системы «фрейминг»-архитектуры для контекстуализации LLM, или модели просто потребуют доступа к локально доступной бизнес-аналитике, устраняя необходимость для компаний делиться данными с третьими сторонами.
В конечном итоге, основные принципы проектирования, рассмотренные здесь, вероятно, будут естественным образом приняты будущими системами ИИ, даже за пределами обслуживания клиентов, без необходимости специальной адаптации для этого случая использования.
2026 Год: Откройте для себя лучшие генераторы искусства на основе ИИ для создания сценариев к коротким драмам. Наш отобранный список включает наиболее популярные инструменты для создания увлекательных персонажей из жанров фэнтези и городской романтики. Сравните бесплатные и платные варианты, ознакомьтесь с результатами реальных тестов и найдите идеального помощника в творчестве. Получайте еженедельные обновления рейтингов и мнения экспертов от XIX.AI. Начните визуализировать свою историю прямо сегодня!
Откройте для себя лучшие инструменты для создания скриптов на основе искусственного интеллекта в 2026 году, предназначенные для радио- и подкастинга, на сайте XIX.AI. Наш тщательно отобранный список включает мощные решения, способные значительно ускорить процесс создания привлекательных аудиореклам. Сравните бесплатные и платные варианты на основе реальных тестов и еженедельно обновляемых рейтингов. Раскройте свой творческий потенциал уже сегодня!
Откройте для себя лучшее программное обеспечение 2026 года для анализа договоров с помощью ИИ на сайте XIX.AI. В нашем тщательно отобранном списке лидеров представлены мощные инструменты, которые мгновенно выявляют юридические лазейки и риски несоответствия нормативным требованиям. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Найдите решение, которое кардинально изменит ваш подход к безопасному и эффективному анализу договоров. Ознакомьтесь с исчерпывающим руководством прямо сейчас.
Откройте для себя лучшие генераторы аниме на основе искусственного интеллекта 2026 года для создания донхуа. Наш список, составленный специально для вас, включает мощные инструменты, позволяющие создавать потрясающих персонажей для веб-новелл и комиксов. Сравните бесплатные и платные варианты на основе реальных тестов. Найдите идеального помощника в творчестве и превратите свои истории в жизнь сегодня на сайте XIX.AI.
Откройте для себя лучшие инструменты для автоматической раскраски манги с помощью ИИ в 2026 году на сайте XIX.AI. В нашем тщательно составленном списке представлены самые популярные и революционные решения, которые наносят плоские цвета без единой ошибки в цветовом соответствии, что значительно повышает вашу продуктивность. Изучите сравнения бесплатных и платных версий, результаты реальных тестов и еженедельно обновляемые рейтинги, чтобы найти идеальный вариант для себя. Воспользуйтесь преимуществами ИИ уже сегодня.
Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
При нажатии на «Принять все файлы cookie» вы соглашаетесь на хранение файлов cookie на вашем устройстве для улучшения навигации по сайту, анализа использования сайта и поддержки наших маркетинговых усилий.Политика конфиденциальности Уведомление
При посещении любого веб-сайта он может хранить или получать информацию в вашем браузере, главным образом в виде файлов cookie. Эта информация может относиться к вам, вашим предпочтениям или вашему устройству и в основном используется для того, чтобы сайт работал так, как вы ожидаете. Эта информация обычно не идентифицирует вас напрямую, но может предоставить вам более персонализированный веб-опыт. Поскольку мы уважаем ваше право на конфиденциальность, вы можете отказаться от разрешения определенных типов файлов cookie. Нажмите на разные заголовки категорий, чтобы узнать больше и изменить наши параметры по умолчанию. Однако блокировка некоторых типов файлов cookie может повлиять на ваше восприятие сайта и предоставляемые нами услуги. Политика конфиденциальностиЗаявление
Управление предпочтениями
Строго необходимые файлы cookie
Всегда активен
Эти файлы cookie необходимы для работы веб-сайта и не могут быть отключены в наших системах. Обычно они устанавливаются только в ответ на ваши действия, которые являются запросом на предоставление услуг, например, настройка предпочтений конфиденциальности, вход в систему или заполнение форм. Вы можете настроить браузер на блокировку этих файлов cookie или оповещение о них, но тогда некоторые части сайта не будут работать. Эти файлы cookie не хранят никакой персональной информации, позволяющей идентифицировать вас.

















 Дом
Дом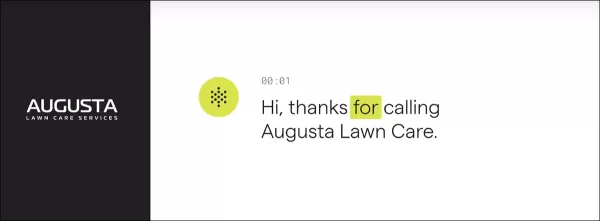
![Примеры взаимодействия с клиентами, представленные в рамках нового проекта. [Источник] https://figshare.com/articles/dataset/Beyond_IVR_Touch-Tones_Customer_Intent_Routing_using_LLMs/30118690](https://img.xix.ai/uploads/61/69023b8fbf62b.webp)
![Три системы, выбранные для трехстороннего подхода. [Источник] https://arxiv.org/pdf/2510.21715](https://img.xix.ai/uploads/87/69023b91dcc46.webp)

 BuzzFeed открывает дочернюю компанию по разработке бесполезных приложений на базе ИИ
На фоне серьезного кризиса в сфере бизнеса бывший гигант цифровых медиа BuzzFeed запускает амбициозный эксперимент по самоспасению с использованием искусственного интеллекта. На недавней конференции S
BuzzFeed открывает дочернюю компанию по разработке бесполезных приложений на базе ИИ
На фоне серьезного кризиса в сфере бизнеса бывший гигант цифровых медиа BuzzFeed запускает амбициозный эксперимент по самоспасению с использованием искусственного интеллекта. На недавней конференции S
 Генераторы искусства на основе ИИ для сценариев коротких драм: персонажи в жанрах фэнтези и городской романтики
Генераторы искусства на основе ИИ для сценариев коротких драм: персонажи в жанрах фэнтези и городской романтики
 10 инструментов
10 инструментов
 xix.ai
письмо
xix.ai
письмо

 Комментарии (0)
Комментарии (0)

![Примеры взаимодействия с клиентами, представленные в рамках нового проекта. [Источник] https://figshare.com/articles/dataset/Beyond_IVR_Touch-Tones_Customer_Intent_Routing_using_LLMs/30118690](https://img.xix.ai/uploads/61/69023b8fbf62b.webp.webp)
![Три системы, выбранные для трехстороннего подхода. [Источник] https://arxiv.org/pdf/2510.21715](https://img.xix.ai/uploads/87/69023b91dcc46.webp.webp)












 BuzzFeed открывает дочернюю компанию по разработке бесполезных приложений на базе ИИ
На фоне серьезного кризиса в сфере бизнеса бывший гигант цифровых медиа BuzzFeed запускает амбициозный эксперимент по самоспасению с использованием искусственного интеллекта. На недавней конференции S
BuzzFeed открывает дочернюю компанию по разработке бесполезных приложений на базе ИИ
На фоне серьезного кризиса в сфере бизнеса бывший гигант цифровых медиа BuzzFeed запускает амбициозный эксперимент по самоспасению с использованием искусственного интеллекта. На недавней конференции S
 Режим для взрослых в ChatGPT снова отложен; Ультрамен: в первую очередь — интеллект
OpenAI вновь откладывает запуск спорной функции, сосредоточившись на персонализации и проактивном взаимодействииВопрос о том, должен ли «неуместный контент» быть частью продуктивного инструмента ИИ, у
Режим для взрослых в ChatGPT снова отложен; Ультрамен: в первую очередь — интеллект
OpenAI вновь откладывает запуск спорной функции, сосредоточившись на персонализации и проактивном взаимодействииВопрос о том, должен ли «неуместный контент» быть частью продуктивного инструмента ИИ, у
 Компания Baidu Health в ближайшее время проведет внутреннее тестирование AI-помощника врача DoctorClaw для поиска научной информации и оказания помощи в офисной работе
По имеющимся данным, компания Baidu Health приступила к внутреннему тестированию профессионального интеллектуального помощника на базе искусственного интеллекта, предназначенного для врачей. Этот прод
Компания Baidu Health в ближайшее время проведет внутреннее тестирование AI-помощника врача DoctorClaw для поиска научной информации и оказания помощи в офисной работе
По имеющимся данным, компания Baidu Health приступила к внутреннему тестированию профессионального интеллектуального помощника на базе искусственного интеллекта, предназначенного для врачей. Этот прод



















