
















 家
家AIが人間の顧客サービス担当者への経路を効率化する
新たな研究により、オープンソースのChatGPT型AIシステムが自然言語を用いて、コールセンターで発信者を適切な担当者につなぐ可能性が明らかになった。これにより、意図的に障害を設けられているように感じられる、煩わしく頻繁に変更されるメニューシステムを操作する必要がなくなる。
生身のオペレーターに接続するのは苛立たしい試練となり得る。利用者は複数の選択肢をゆっくりと進めねばならず、どの選択肢が自身の具体的な問題に合致するか確信が持てない場合が多い。該当する選択肢がない場合、知識のあるユーザーはしばしば人間オペレーターに到達し「選択肢地獄」から脱出するための裏技や回避策を編み出す。多くの人にとって、この体験は敵対的でユーザーフレンドリーではないと感じられる。
コールセンターがAIによる強化や代替の主要な対象となっているのは驚くべきことではない。一部の専門家が慎重な対応を促しているにもかかわらず、コールセンターの自動化は依然として技術関連のニュースの見出しを飾る「低垂の果実」であり、異例の速さで投資回収を実現できるAI駆動型イノベーションの有望な分野である。
閉鎖的な世界
しかし、オープンソースの原則や公開データがこの分野で適用されることは稀であり、それには正当な理由がある。顧客対応システムを自動化する企業は、競争優位性の基盤となるデータ、手法、企業知的財産を共有するインセンティブがほとんどない。
こうした資源を共有すれば市場優位性が損なわれる。さらに深刻なのは、AIシステムが機密情報を漏洩する恐れがあるため、重大な法的リスクも伴う点だ。
このため、資金力のある複数の企業が独自にAI搭載コールセンターシステムを開発する動きが生まれ、必然的に重複した努力が生じている。同時に、AI駆動型カスタマーサービス機能への需要増大に対応しようとするB2Bスタートアップや既存企業の急増も促している。
PolyAIの音声アシスタントは、架空の企業「オーガスタ・ローンケア」の顧客サービスコールを開始し、既存のコールセンターインフラ内で応答を自動化するために、広範なトレーニング会話を活用している。出典
さらに、複雑なコールセンターメニューによる顧客の不満解消に向けた取り組みが研究を促進している。しかし、インタラクティブ音声応答(IVR)開発の典型的な非公開性を反映し、大半の研究成果はArxivなどの公開プラットフォームで発表されていない。
結果として、カスタマーサービスにおけるAI自動化に関連する研究、データ、ビジネスインテリジェンスは厳重に管理されている。法的に安全なデータでこうしたシステムを利用することが現実的な選択肢だとしても(それは疑わしいが)、オープンソースの代替案はほとんど存在しない。
ローカルコール
こうした背景の中、コロンビア発の新たな論文は、IVR開発を企業の金庫から少しだけ引き出す歓迎すべき試みである。 「Beyond IVR Touch-Tones: Customer Intent Routing using LLMs」と題されたこの簡潔な研究は、ボゴタのフランシスコ・ホセ・デ・カルダス市立大学の研究者によるものである。本研究は、大規模言語モデル(LLM)を用いてカスタマー・インテント・ルーティング(CIR)システムの実用的な設計図を作成した初の非専有プロジェクトであると主張している。
実際の通話データや独自メニュー構造を用いる代わりに、本プロジェクトでは3つのAIモデルを用いて全コンポーネントをゼロから生成している。1つは現実的なコールセンターメニューを設計し、もう1つは数百件の苦情通話をシミュレートし、3つ目はチャットボットとして機能し、これらの問い合わせを適切な宛先にルーティングする。
その結果、架空の通信会社と920件の異なるユーザー問い合わせを特徴とする、完全に合成されながらも説得力のあるテスト環境が構築された。この設定により、現行のAIが曖昧で構造化されていない発話をどの程度正確に解釈し、法的リスクを回避しつつ適切な対応先へ誘導できるかを検証できる。
テストでは、特に詳細な説明ではなく「簡略化された」メニューオプションが提供された場合、システムが自由形式の苦情を最大89.13%の精度で適切な宛先に正確にマッピングできることが示された。
また、AIは通話者がカジュアルな表現や多様な言葉遣いを使用した場合に誤りを増やすことも判明した。ただし、一部の誤りはAIの誤解ではなく、電話メニュー自体が混乱を招く構造であったことに起因していた。
![新規プロジェクトの一環として共有された顧客とのやり取りの例。[出典] https://figshare.com/articles/dataset/Beyond_IVR_Touch-Tones_Customer_Intent_Routing_using_LLMs/30118690](https://img.xix.ai/uploads/61/69023b8fbf62b.webp)
新プロジェクトの一環として共有された顧客対応事例。出典
本プロジェクトのデータは公開されている。
手法
三段階のアプローチでは、まず架空の通信会社向け詳細電話メニューを生成するモデルを構築。次に、現実的な発話パターンをシミュレートするため、明快なものから言い換えられたもの、カジュアルなものまで多様な発信者メッセージを生成するモデルを運用。合計920例のメッセージを生成した。
第三のモデルは、メッセージとメニューのバージョンのみに基づいて、各発信者を適切な部門に接続する役割を担った。この枠組みにより、実際の通話データや顧客情報を公開することなく、実験を完全に再現可能にした。
![三つのシステムが三者アプローチのために選ばれた。[出典] https://arxiv.org/pdf/2510.21715](https://img.xix.ai/uploads/87/69023b91dcc46.webp)
三者アプローチに採用された3つのシステム。出典
使用モデルはそれぞれgpt-3.5-turbo、gpt-4o-mini、gpt-4.1-miniであった。
本物のカスタマーサービス環境をシミュレートするため、複雑な電話メニューを一から合成する必要があった。関連データセットが不足していたため、gpt-3.5-turboモデルに架空の通信事業者向け完全な多階層構造を生成するようプロンプトした。
各分岐は、請求、テクニカルサポート、アカウント管理、新サービスなどのサービス領域を表し、現実的なサブオプションと異なる階層深さを備えていた。テスト用に2種類のメニューバージョンを作成した:人間が読みやすい形式を模したプレーンテキスト階層と、対応するボタンシーケンス付きのエンドポイントリストである。
これにより、ルーティング問題の詳細版と簡略版の両方でのテストが可能となった:

AIには2種類の電話メニューが提供された:詳細なテキスト階層と、直接メニューオプションの簡略化されたリストである。これにより、各形式が発信者を適切な場所へルーティングする能力を比較検証した。
テスト通話者メッセージ生成のため、第二の言語モデルが各メニューエンドポイントごとに10件の固有例を含む苦情・要求文を生成。
その後、それぞれが実際の人が問題を表現する多様な方法を反映するために、長さの変化、トーン、さらには小さな誤りやフィラーワードまで取り入れ、いくつかのバリエーションに言い換えられました。
920件の初期メッセージは、システムの精度をテストし、自然な会話の予測不可能性をシミュレートするために作成されました。
第三段階では、2種類の異なるIVR提示形式を用いて、最終モデルが各メッセージを正しいメニュー先へマッピングする能力をテストした。
最初のバージョンでは、AIは電話ツリーの完全な記述的概要を受け取りました。2番目のバージョンでは、最終的な行き先とそのボタンシーケンスのリストのみが表示されました。
目的は、簡略化されたメニューがモデルの通話ルーティング効率向上に寄与するかを確認することでした。いずれの場合も、システムは1メッセージずつ処理し、自動採点のため余分なテキストなしで経路のみを返すよう指示されました。
分離
テスト結果の混同を防ぐため、各モデルは隔離された状態で運用された。最初のモデルが電話メニューの草案を作成したが、他のシステムが認識できないよう最終調整は手動で行われた。
発信者メッセージはgpt-4o-miniがメニュー構造にアクセスせずにエンドポイント名のみを使用して個別に生成した。最後に、ルーティングを実行したgpt-4.1-miniはメニューテキストと受信メッセージのみにアクセス可能で、それらを作成する役割は一切担わなかった。
評価指標
ルーティングシステムの性能は2つの標準指標で評価した:正確性(モデルが完全な正しい経路(例:1-2-3)を提供したケースの割合)と、誤り箇所を特定するための混同行列*。評価はpandasとscikit-learnライブラリを用いたPythonで実施。
結果
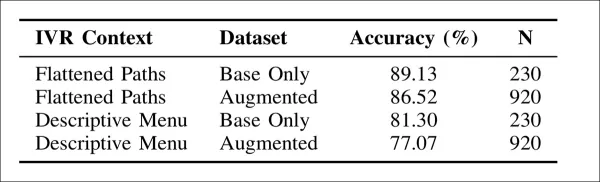
テストの結果、モデルの精度はメニューの提示方法に大きく依存することが明らかになった。メニューパスを平坦化したリストでは、より単純なデータセットで89.13%の精度を達成したのに対し、完全な記述的メニューでは81.30%であった。
3番目のモデル(LLM3)におけるルーティング精度は、プロンプト形式やデータセットの種類を問わず、平坦化されたメニューパスが一貫して階層的記述を上回り、言い換えや非公式な言語入力では精度がわずかに低下する傾向を示した。
この傾向は、より大規模で言語的に多様なデータセットでも継続し、平坦化されたバージョンが再び優れた性能を示し、86.52%のスコアを記録したのに対し、記述形式は77.07%であった。
本論文は、これらの結果が、長い階層的記述よりも、より単純なリストベースのプロンプトがモデルによるクエリのマッチング信頼性を高めることを示唆していると指摘している。
また、言い換えや非公式な発信者メッセージが導入された場合、精度がわずかに低下した。これは多様性の増加が現実感を高める一方で、分類を困難にしたことを示唆している。
論文は次のように結論づけている:
「当社の結果は、LLMが平坦化されたIVR経路(最大89.13%)を提供された場合、冗長なメニュー説明(最低77.07%)と比較して顧客の意図をより正確にルーティングすることを実証している。これは簡潔で構造化されたプロンプトがノイズを低減し、ルーティングタスクに適していることを示唆する。
これは、分類シナリオにおいて明瞭さと簡潔さがLLMの性能を向上させるという考えを支持するものである。
さらに、メニューを平坦化された経路に変換することは、実運用において単純化され自動化可能なプロセスである。」
結論
秘密主義と排他性が特徴的な分野でオープンな研究が展開されつつあることは心強い。重要な疑問が残る:将来のシステムはLLMを文脈化する「フレーミング」アーキテクチャを必要とするのか、それともモデルがローカルで利用可能なビジネスインテリジェンスに直接アクセスできるようになり、企業が第三者とデータを共有する必要がなくなるのか。
結局のところ、ここで探求した中核的な設計原則は、顧客サービスという特定のユースケース向けに特別に適応させる必要なく、将来のAIシステムによって自然に採用される可能性が高いと考えられる。
*詳細は原論文を参照のこと。
初出:2025年10月29日(水)
関連記事
 「Cursor Composer 2」対「Claude Opus 4.6」:ベンチマークテストがAIコーディングを巡る新たな議論を巻き起こす
3月19日、Cursorは自社開発のコーディングモデル「Composer 2」を正式にリリースした。 この発表は開発者コミュニティで即座に議論を巻き起こした。Cursorによると、Composer 2はTerminal-Bench 2.0で61.7%のスコアを記録し、同一のテスト条件下でClaude Opus 4.6の58.0%を大幅に上回ったという。Anthropicのフラッグシップモデルが、自
「StrictlyVC サンフランシスコ」に、TDKベンチャーズやReplitなどのリーダーが集結
今年最初のStrictlyVCイベントが、あっという間にサンフランシスコで開催されます。 4月30日にセントロ・フィリピーノ・カルチュラル・センターで開催される本イベントのチケットは、現在も販売中です。豪華なスピーカー陣が登壇するこのイベントでは、StrictlyVCならではのネットワーキングやコミュニティ交流に加え、資金調達に関する最新の知見を求めるAI分野のイノベーターや起業家の方々にとって、
Notionは、ワークスペースをAIエージェントのハブへと変革します
生産性向上ソフトウェア企業であるNotionが、「エージェント時代」に突入する。水曜日にライブ配信された製品発表会で、共同ノート作成アプリで知られるNotionは、カスタムAIエージェントの機能を拡張し、外部エージェントと連携し、あらゆるデータベースからデータを取得できる自動化された多段階ワークフローをチームが構築できるようにする新しい開発者向けプラットフォームを発表した。複数のツールやデータソー
関連特集おすすめ
書き込み
「Cursor Composer 2」対「Claude Opus 4.6」:ベンチマークテストがAIコーディングを巡る新たな議論を巻き起こす
3月19日、Cursorは自社開発のコーディングモデル「Composer 2」を正式にリリースした。 この発表は開発者コミュニティで即座に議論を巻き起こした。Cursorによると、Composer 2はTerminal-Bench 2.0で61.7%のスコアを記録し、同一のテスト条件下でClaude Opus 4.6の58.0%を大幅に上回ったという。Anthropicのフラッグシップモデルが、自
「StrictlyVC サンフランシスコ」に、TDKベンチャーズやReplitなどのリーダーが集結
今年最初のStrictlyVCイベントが、あっという間にサンフランシスコで開催されます。 4月30日にセントロ・フィリピーノ・カルチュラル・センターで開催される本イベントのチケットは、現在も販売中です。豪華なスピーカー陣が登壇するこのイベントでは、StrictlyVCならではのネットワーキングやコミュニティ交流に加え、資金調達に関する最新の知見を求めるAI分野のイノベーターや起業家の方々にとって、
Notionは、ワークスペースをAIエージェントのハブへと変革します
生産性向上ソフトウェア企業であるNotionが、「エージェント時代」に突入する。水曜日にライブ配信された製品発表会で、共同ノート作成アプリで知られるNotionは、カスタムAIエージェントの機能を拡張し、外部エージェントと連携し、あらゆるデータベースからデータを取得できる自動化された多段階ワークフローをチームが構築できるようにする新しい開発者向けプラットフォームを発表した。複数のツールやデータソー
関連特集おすすめ
書き込み
 ラジオおよびポッドキャスト用の最適なAIスクリプティングツール:魅力的なオーディオコマーシャルを作成する
ラジオおよびポッドキャスト用の最適なAIスクリプティングツール:魅力的なオーディオコマーシャルを作成する
XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
 10 ツール
10 ツール
 xix.ai
仕事
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
xix.ai
仕事
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai
アニメーション制作
東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai
漫画制作
漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
書き込み
AI小説プロファイル作成のトップクリエイター:一貫性のあるキャラクターの動機と致命的な欠点を生成する
深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai
仕事
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
新たな研究により、オープンソースのChatGPT型AIシステムが自然言語を用いて、コールセンターで発信者を適切な担当者につなぐ可能性が明らかになった。これにより、意図的に障害を設けられているように感じられる、煩わしく頻繁に変更されるメニューシステムを操作する必要がなくなる。
生身のオペレーターに接続するのは苛立たしい試練となり得る。利用者は複数の選択肢をゆっくりと進めねばならず、どの選択肢が自身の具体的な問題に合致するか確信が持てない場合が多い。該当する選択肢がない場合、知識のあるユーザーはしばしば人間オペレーターに到達し「選択肢地獄」から脱出するための裏技や回避策を編み出す。多くの人にとって、この体験は敵対的でユーザーフレンドリーではないと感じられる。
コールセンターがAIによる強化や代替の主要な対象となっているのは驚くべきことではない。一部の専門家が慎重な対応を促しているにもかかわらず、コールセンターの自動化は依然として技術関連のニュースの見出しを飾る「低垂の果実」であり、異例の速さで投資回収を実現できるAI駆動型イノベーションの有望な分野である。
閉鎖的な世界
しかし、オープンソースの原則や公開データがこの分野で適用されることは稀であり、それには正当な理由がある。顧客対応システムを自動化する企業は、競争優位性の基盤となるデータ、手法、企業知的財産を共有するインセンティブがほとんどない。
こうした資源を共有すれば市場優位性が損なわれる。さらに深刻なのは、AIシステムが機密情報を漏洩する恐れがあるため、重大な法的リスクも伴う点だ。
このため、資金力のある複数の企業が独自にAI搭載コールセンターシステムを開発する動きが生まれ、必然的に重複した努力が生じている。同時に、AI駆動型カスタマーサービス機能への需要増大に対応しようとするB2Bスタートアップや既存企業の急増も促している。

PolyAIの音声アシスタントは、架空の企業「オーガスタ・ローンケア」の顧客サービスコールを開始し、既存のコールセンターインフラ内で応答を自動化するために、広範なトレーニング会話を活用している。出典
さらに、複雑なコールセンターメニューによる顧客の不満解消に向けた取り組みが研究を促進している。しかし、インタラクティブ音声応答(IVR)開発の典型的な非公開性を反映し、大半の研究成果はArxivなどの公開プラットフォームで発表されていない。
結果として、カスタマーサービスにおけるAI自動化に関連する研究、データ、ビジネスインテリジェンスは厳重に管理されている。法的に安全なデータでこうしたシステムを利用することが現実的な選択肢だとしても(それは疑わしいが)、オープンソースの代替案はほとんど存在しない。
ローカルコール
こうした背景の中、コロンビア発の新たな論文は、IVR開発を企業の金庫から少しだけ引き出す歓迎すべき試みである。 「Beyond IVR Touch-Tones: Customer Intent Routing using LLMs」と題されたこの簡潔な研究は、ボゴタのフランシスコ・ホセ・デ・カルダス市立大学の研究者によるものである。本研究は、大規模言語モデル(LLM)を用いてカスタマー・インテント・ルーティング(CIR)システムの実用的な設計図を作成した初の非専有プロジェクトであると主張している。
実際の通話データや独自メニュー構造を用いる代わりに、本プロジェクトでは3つのAIモデルを用いて全コンポーネントをゼロから生成している。1つは現実的なコールセンターメニューを設計し、もう1つは数百件の苦情通話をシミュレートし、3つ目はチャットボットとして機能し、これらの問い合わせを適切な宛先にルーティングする。
その結果、架空の通信会社と920件の異なるユーザー問い合わせを特徴とする、完全に合成されながらも説得力のあるテスト環境が構築された。この設定により、現行のAIが曖昧で構造化されていない発話をどの程度正確に解釈し、法的リスクを回避しつつ適切な対応先へ誘導できるかを検証できる。
テストでは、特に詳細な説明ではなく「簡略化された」メニューオプションが提供された場合、システムが自由形式の苦情を最大89.13%の精度で適切な宛先に正確にマッピングできることが示された。
また、AIは通話者がカジュアルな表現や多様な言葉遣いを使用した場合に誤りを増やすことも判明した。ただし、一部の誤りはAIの誤解ではなく、電話メニュー自体が混乱を招く構造であったことに起因していた。
![新規プロジェクトの一環として共有された顧客とのやり取りの例。[出典] https://figshare.com/articles/dataset/Beyond_IVR_Touch-Tones_Customer_Intent_Routing_using_LLMs/30118690](https://img.xix.ai/uploads/61/69023b8fbf62b.webp.webp)
新プロジェクトの一環として共有された顧客対応事例。出典
本プロジェクトのデータは公開されている。
手法
三段階のアプローチでは、まず架空の通信会社向け詳細電話メニューを生成するモデルを構築。次に、現実的な発話パターンをシミュレートするため、明快なものから言い換えられたもの、カジュアルなものまで多様な発信者メッセージを生成するモデルを運用。合計920例のメッセージを生成した。
第三のモデルは、メッセージとメニューのバージョンのみに基づいて、各発信者を適切な部門に接続する役割を担った。この枠組みにより、実際の通話データや顧客情報を公開することなく、実験を完全に再現可能にした。
![三つのシステムが三者アプローチのために選ばれた。[出典] https://arxiv.org/pdf/2510.21715](https://img.xix.ai/uploads/87/69023b91dcc46.webp.webp)
三者アプローチに採用された3つのシステム。出典
使用モデルはそれぞれgpt-3.5-turbo、gpt-4o-mini、gpt-4.1-miniであった。
本物のカスタマーサービス環境をシミュレートするため、複雑な電話メニューを一から合成する必要があった。関連データセットが不足していたため、gpt-3.5-turboモデルに架空の通信事業者向け完全な多階層構造を生成するようプロンプトした。
各分岐は、請求、テクニカルサポート、アカウント管理、新サービスなどのサービス領域を表し、現実的なサブオプションと異なる階層深さを備えていた。テスト用に2種類のメニューバージョンを作成した:人間が読みやすい形式を模したプレーンテキスト階層と、対応するボタンシーケンス付きのエンドポイントリストである。
これにより、ルーティング問題の詳細版と簡略版の両方でのテストが可能となった:

AIには2種類の電話メニューが提供された:詳細なテキスト階層と、直接メニューオプションの簡略化されたリストである。これにより、各形式が発信者を適切な場所へルーティングする能力を比較検証した。
テスト通話者メッセージ生成のため、第二の言語モデルが各メニューエンドポイントごとに10件の固有例を含む苦情・要求文を生成。
その後、それぞれが実際の人が問題を表現する多様な方法を反映するために、長さの変化、トーン、さらには小さな誤りやフィラーワードまで取り入れ、いくつかのバリエーションに言い換えられました。
920件の初期メッセージは、システムの精度をテストし、自然な会話の予測不可能性をシミュレートするために作成されました。
第三段階では、2種類の異なるIVR提示形式を用いて、最終モデルが各メッセージを正しいメニュー先へマッピングする能力をテストした。
最初のバージョンでは、AIは電話ツリーの完全な記述的概要を受け取りました。2番目のバージョンでは、最終的な行き先とそのボタンシーケンスのリストのみが表示されました。
目的は、簡略化されたメニューがモデルの通話ルーティング効率向上に寄与するかを確認することでした。いずれの場合も、システムは1メッセージずつ処理し、自動採点のため余分なテキストなしで経路のみを返すよう指示されました。
分離
テスト結果の混同を防ぐため、各モデルは隔離された状態で運用された。最初のモデルが電話メニューの草案を作成したが、他のシステムが認識できないよう最終調整は手動で行われた。
発信者メッセージはgpt-4o-miniがメニュー構造にアクセスせずにエンドポイント名のみを使用して個別に生成した。最後に、ルーティングを実行したgpt-4.1-miniはメニューテキストと受信メッセージのみにアクセス可能で、それらを作成する役割は一切担わなかった。
評価指標
ルーティングシステムの性能は2つの標準指標で評価した:正確性(モデルが完全な正しい経路(例:1-2-3)を提供したケースの割合)と、誤り箇所を特定するための混同行列*。評価はpandasとscikit-learnライブラリを用いたPythonで実施。
結果
テストの結果、モデルの精度はメニューの提示方法に大きく依存することが明らかになった。メニューパスを平坦化したリストでは、より単純なデータセットで89.13%の精度を達成したのに対し、完全な記述的メニューでは81.30%であった。

3番目のモデル(LLM3)におけるルーティング精度は、プロンプト形式やデータセットの種類を問わず、平坦化されたメニューパスが一貫して階層的記述を上回り、言い換えや非公式な言語入力では精度がわずかに低下する傾向を示した。
この傾向は、より大規模で言語的に多様なデータセットでも継続し、平坦化されたバージョンが再び優れた性能を示し、86.52%のスコアを記録したのに対し、記述形式は77.07%であった。
本論文は、これらの結果が、長い階層的記述よりも、より単純なリストベースのプロンプトがモデルによるクエリのマッチング信頼性を高めることを示唆していると指摘している。
また、言い換えや非公式な発信者メッセージが導入された場合、精度がわずかに低下した。これは多様性の増加が現実感を高める一方で、分類を困難にしたことを示唆している。
論文は次のように結論づけている:
「当社の結果は、LLMが平坦化されたIVR経路(最大89.13%)を提供された場合、冗長なメニュー説明(最低77.07%)と比較して顧客の意図をより正確にルーティングすることを実証している。これは簡潔で構造化されたプロンプトがノイズを低減し、ルーティングタスクに適していることを示唆する。
これは、分類シナリオにおいて明瞭さと簡潔さがLLMの性能を向上させるという考えを支持するものである。
さらに、メニューを平坦化された経路に変換することは、実運用において単純化され自動化可能なプロセスである。」
結論
秘密主義と排他性が特徴的な分野でオープンな研究が展開されつつあることは心強い。重要な疑問が残る:将来のシステムはLLMを文脈化する「フレーミング」アーキテクチャを必要とするのか、それともモデルがローカルで利用可能なビジネスインテリジェンスに直接アクセスできるようになり、企業が第三者とデータを共有する必要がなくなるのか。
結局のところ、ここで探求した中核的な設計原則は、顧客サービスという特定のユースケース向けに特別に適応させる必要なく、将来のAIシステムによって自然に採用される可能性が高いと考えられる。
*詳細は原論文を参照のこと。
初出:2025年10月29日(水)










 「Cursor Composer 2」対「Claude Opus 4.6」:ベンチマークテストがAIコーディングを巡る新たな議論を巻き起こす
3月19日、Cursorは自社開発のコーディングモデル「Composer 2」を正式にリリースした。 この発表は開発者コミュニティで即座に議論を巻き起こした。Cursorによると、Composer 2はTerminal-Bench 2.0で61.7%のスコアを記録し、同一のテスト条件下でClaude Opus 4.6の58.0%を大幅に上回ったという。Anthropicのフラッグシップモデルが、自
「Cursor Composer 2」対「Claude Opus 4.6」:ベンチマークテストがAIコーディングを巡る新たな議論を巻き起こす
3月19日、Cursorは自社開発のコーディングモデル「Composer 2」を正式にリリースした。 この発表は開発者コミュニティで即座に議論を巻き起こした。Cursorによると、Composer 2はTerminal-Bench 2.0で61.7%のスコアを記録し、同一のテスト条件下でClaude Opus 4.6の58.0%を大幅に上回ったという。Anthropicのフラッグシップモデルが、自
 「StrictlyVC サンフランシスコ」に、TDKベンチャーズやReplitなどのリーダーが集結
今年最初のStrictlyVCイベントが、あっという間にサンフランシスコで開催されます。 4月30日にセントロ・フィリピーノ・カルチュラル・センターで開催される本イベントのチケットは、現在も販売中です。豪華なスピーカー陣が登壇するこのイベントでは、StrictlyVCならではのネットワーキングやコミュニティ交流に加え、資金調達に関する最新の知見を求めるAI分野のイノベーターや起業家の方々にとって、
「StrictlyVC サンフランシスコ」に、TDKベンチャーズやReplitなどのリーダーが集結
今年最初のStrictlyVCイベントが、あっという間にサンフランシスコで開催されます。 4月30日にセントロ・フィリピーノ・カルチュラル・センターで開催される本イベントのチケットは、現在も販売中です。豪華なスピーカー陣が登壇するこのイベントでは、StrictlyVCならではのネットワーキングやコミュニティ交流に加え、資金調達に関する最新の知見を求めるAI分野のイノベーターや起業家の方々にとって、
 Notionは、ワークスペースをAIエージェントのハブへと変革します
生産性向上ソフトウェア企業であるNotionが、「エージェント時代」に突入する。水曜日にライブ配信された製品発表会で、共同ノート作成アプリで知られるNotionは、カスタムAIエージェントの機能を拡張し、外部エージェントと連携し、あらゆるデータベースからデータを取得できる自動化された多段階ワークフローをチームが構築できるようにする新しい開発者向けプラットフォームを発表した。複数のツールやデータソー
Notionは、ワークスペースをAIエージェントのハブへと変革します
生産性向上ソフトウェア企業であるNotionが、「エージェント時代」に突入する。水曜日にライブ配信された製品発表会で、共同ノート作成アプリで知られるNotionは、カスタムAIエージェントの機能を拡張し、外部エージェントと連携し、あらゆるデータベースからデータを取得できる自動化された多段階ワークフローをチームが構築できるようにする新しい開発者向けプラットフォームを発表した。複数のツールやデータソー

XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
10 ツール
xix.ai

XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai

2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai

XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai













