
















 首頁
首頁隨著 OpenAI、Google 和 Anthropic 相繼推出新產品,AI 健康科技戰局持續升溫
本月,OpenAI、Google 和 Anthropic 相隔僅數日便相繼揭露了各自專門的醫療 AI 功能。這波密集的公告顯示出競爭壓力,而非單純的巧合。然而,儘管行銷話術強調將徹底改變醫療保健,但這些產品均未獲准作為醫療器材、未獲准用於臨床,也無法直接用於患者診斷。
1月7日,OpenAI推出ChatGPT Health,透過與b.well、Apple Health、Function及MyFitnessPal的合作,讓美國用戶能串接醫療紀錄。Google則於1月13日發布MedGemma 1.5,將其開源醫療AI模型擴展至可解讀3D電腦斷層掃描(CT)與磁振造影(MRI)影像,以及全切片組織病理學影像。
Anthropic 隨後於 1 月 11 日推出「Claude for Healthcare」,提供符合 HIPAA 規範的連接器,可串接至 CMS 保險給付資料庫、ICD-10 編碼系統以及國家醫療服務提供者識別碼登記處。
這三家公司皆瞄準相同的行政痛點——事前授權審查、理賠處理及臨床文件記錄——雖採用相似的技術方法,但市場推廣策略各異。
開發者平台,而非診斷產品
其架構上的相似性令人驚嘆。每個系統皆採用針對醫學文獻與臨床資料集進行微調的多模態大型語言模型。各系統均強調隱私保護與法規免責聲明,並將自身定位為輔助而非取代臨床判斷。
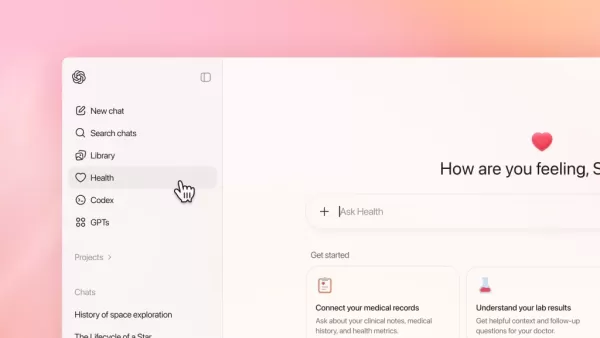
差異在於部署與存取模式。OpenAI 的 ChatGPT Health 作為面向消費者的服務運作,針對歐洲經濟區(EEA)、瑞士及英國以外地區的 ChatGPT Free、Plus 和 Pro 訂閱用戶設有候補名單。Google 的 MedGemma 1.5 則透過其「健康 AI 開發者基礎計畫」以開放模型形式發布,使用者可透過 Hugging Face 下載,或透過 Google Cloud 的 Vertex AI 進行部署。
Anthropic 的 Claude for Healthcare 則透過 Claude for Enterprise 整合至現有企業工作流程,目標客群為機構買家而非個人消費者。這三者均持一致的監管立場。
OpenAI 明確聲明 Health「不適用於診斷或治療」。Google 將 MedGemma 定位為「開發者評估並適應其醫療應用場景的起點」。Anthropic 則強調其輸出結果「不應直接用於臨床診斷、病患管理決策、治療建議,或任何其他直接的臨床實踐應用」。
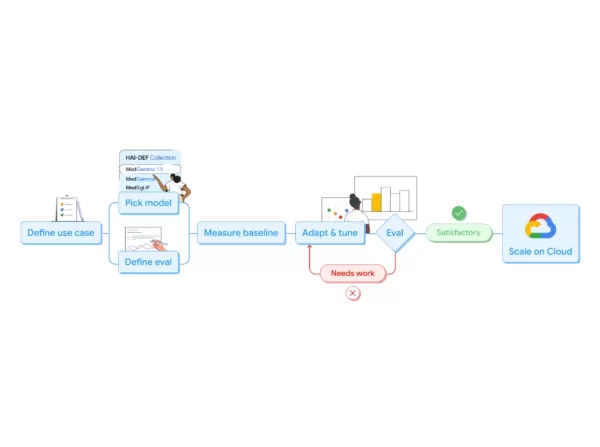
基準測試表現與臨床驗證
這三款產品在醫療 AI 基準測試中的表現均有顯著提升,但測試表現與實際臨床部署之間的差距依然龐大。Google 報告指出,MedGemma 1.5 在斯坦福大學的 MedAgentBench(醫療代理完成度基準測試)上達到了 92.3% 的準確度,而之前的 Sonnet 3.5 基準版本僅為 69.6%。
在內部測試中,該模型在 MRI 疾病分類上的表現提升了 14 個百分點,在 CT 檢查結果判讀上則提升了 3 個百分點。Anthropic 的 Claude Opus 4.5 在啟用 Python 程式碼執行功能的 MedCalc 醫療計算準確度測試中獲得 61.3% 的成績,而在 MedAgentBench 測試中則達到 92.3%。
該公司還聲稱在針對事實性幻覺的「誠實度評估」方面有所改善,但未公開具體指標。
OpenAI 並未針對 ChatGPT Health 發布具體的基準比較,而是根據對現有使用情況的去識別化分析指出,「全球每週有超過 2.3 億人透過 ChatGPT 提出健康與保健相關的問題」。
這些基準測試衡量的是在精選測試資料集上的表現,而非臨床結果。由於醫療錯誤可能導致危及生命的後果,將基準準確度轉化為實際臨床實用性,遠比其他 AI 領域複雜得多。
監管路徑仍不明朗
這些醫療 AI 工具的監管環境仍不明朗。在美國,FDA 的監管取決於產品的使用目的。任何「協助或向醫療專業人員提供關於預防、診斷或治療建議」的軟體,可能需作為醫療器材接受上市前審查。目前已公布的工具均未獲得 FDA 核准。
責任歸屬問題同樣懸而未決。當班納健康(Banner Health)的技術長麥克·雷金(Mike Reagin)表示該系統是「被 Anthropic 對 AI 安全的重視所吸引」時,這僅涉及技術選擇,而非法律責任框架。
若臨床醫師依賴 Claude 的預先授權分析,而患者因延誤治療而遭受傷害,現行判例法對責任歸屬幾乎沒有提供任何指引。
各區域的監管方針差異顯著。雖然美國食品藥物管理局(FDA)與歐洲《醫療器材法規》針對作為醫療器材的軟體提供了既定框架,但許多亞太地區監管機構尚未針對生成式人工智慧診斷工具發布具體指引。
這種不確定性影響了各市場的採用時程——在醫療基礎設施尚有缺口的市場中,這本可能加速技術導入,卻反而造成臨床需求與監管謹慎之間的張力。
行政工作流程,而非臨床決策
實際部署範圍仍相當有限。諾和諾德(Novo Nordisk)內容數位化總監 Louise Lind Skov 描述了將 Claude 用於「藥品開發中的文件與內容自動化」,重點在於法規申報而非患者診斷。
台灣健保署採用 MedGemma 從 30,000 份病理報告中提取數據進行政策分析,而非用於治療決策。
此模式顯示,機構採用AI的重點集中在行政工作流程上——例如帳務處理、文件記錄及試驗方案起草等,這些環節的錯誤通常不會立即造成危險;而非直接的臨床決策支援,儘管AI在後者領域對患者預後的影響可能最為顯著。
醫療 AI 的發展速度,已超越機構處理監管、法律責任及工作流程整合等複雜問題的能力。這項技術已然存在,只需支付月費,即可使用先進的醫療推理工具。
這是否能轉化為醫療服務的變革,取決於這些協調發布的聲明尚未解決的關鍵問題。
另請參閱:阿斯特捷利康押注內部 AI 以加速腫瘤學研究
想向業界領袖深入了解人工智慧與大數據?歡迎參加將於阿姆斯特丹、加州及倫敦舉辦的「人工智慧與大數據博覽會」。這場綜合性活動隸屬於 TechEx 系列,並與其他頂尖科技盛會同期舉行。點擊此處獲取更多資訊。
AI News 由 TechForge Media 提供技術支援。點此探索其他即將舉行的企業科技活動與線上研討會。
相關文章
 Github Copilot的基於令牌的計費方式引發了開發者的強烈不滿
微軟GitHub Copilot的黃金時代可能即將結束,尤其是對個人使用者而言。該公司正從統一的訂閱費模式轉向基於代幣的計費方式,這可能會大幅增加使用成本。雖然大型企業或許還能承受這種變化,但小型企業和自由職業者可能會發現新的收費機制讓他們的月預算難以承受。這些變更將於6月1日正式生效,屆時使用者將按照工作中消耗的代幣數量來支付費用,而不再是按每次請求收取固定費用。一些開發者受到這一財務變動的影響,在Reddit和X平臺上表達了他們對這種看似過高的成本增加的擔憂。一位Redditor最近寫道:“
SpaceX的IPO申請檔案重點體現了其在衛星網際網路和人工智慧領域的發展雄心
在為即將進行的IPO提交的S-1註冊檔案中,SpaceX公佈了一系列令人矚目的業務資料,這些資料凸顯了其在航空航天通訊和人工智慧領域的強大實力:Starlink使用者數突破1000萬:截至2026年第一季度,全球付費Starlink使用者數量已達到1030萬,這一數字在過去一年內翻了一番。這一增長充分證明了作為全球最大的近地軌道衛星星座,Starlink在寬頻和行動通訊領域的領先地位。目前該衛星網路由大約9600顆衛星組成,這些衛星佔在軌所有活躍衛星總數的65%。Grok與X人工智慧生態體系:通
阿里巴巴Tuhao M890上市,憑藉三重效能優勢開啟晶片-雲-模型-推理的全棧代理時代
2026年5月20日,在阿里雲峰會上,阿里雲宣佈完成了專為“智慧體時代”設計的全棧技術系統升級。這一變革重塑了整個技術體系——從底層晶片和雲平臺到模型與推理方案。此次升級使阿里雲成為一家能夠讓大量智慧體實現24/7連續執行的“AI工廠”,從而超越了單純為人類使用者提供服務的範疇。1. 核心基礎:騰迅振武M890晶片與超級節點伺服器此次升級的核心是騰迅推出的新一代AI晶片——振武M890,該晶片集訓練與推理功能於一體。效能提升:M890擁有144GB的記憶體,其效能是前代產品振武810E的三倍。
相關專題推薦
動畫創作
Github Copilot的基於令牌的計費方式引發了開發者的強烈不滿
微軟GitHub Copilot的黃金時代可能即將結束,尤其是對個人使用者而言。該公司正從統一的訂閱費模式轉向基於代幣的計費方式,這可能會大幅增加使用成本。雖然大型企業或許還能承受這種變化,但小型企業和自由職業者可能會發現新的收費機制讓他們的月預算難以承受。這些變更將於6月1日正式生效,屆時使用者將按照工作中消耗的代幣數量來支付費用,而不再是按每次請求收取固定費用。一些開發者受到這一財務變動的影響,在Reddit和X平臺上表達了他們對這種看似過高的成本增加的擔憂。一位Redditor最近寫道:“
SpaceX的IPO申請檔案重點體現了其在衛星網際網路和人工智慧領域的發展雄心
在為即將進行的IPO提交的S-1註冊檔案中,SpaceX公佈了一系列令人矚目的業務資料,這些資料凸顯了其在航空航天通訊和人工智慧領域的強大實力:Starlink使用者數突破1000萬:截至2026年第一季度,全球付費Starlink使用者數量已達到1030萬,這一數字在過去一年內翻了一番。這一增長充分證明了作為全球最大的近地軌道衛星星座,Starlink在寬頻和行動通訊領域的領先地位。目前該衛星網路由大約9600顆衛星組成,這些衛星佔在軌所有活躍衛星總數的65%。Grok與X人工智慧生態體系:通
阿里巴巴Tuhao M890上市,憑藉三重效能優勢開啟晶片-雲-模型-推理的全棧代理時代
2026年5月20日,在阿里雲峰會上,阿里雲宣佈完成了專為“智慧體時代”設計的全棧技術系統升級。這一變革重塑了整個技術體系——從底層晶片和雲平臺到模型與推理方案。此次升級使阿里雲成為一家能夠讓大量智慧體實現24/7連續執行的“AI工廠”,從而超越了單純為人類使用者提供服務的範疇。1. 核心基礎:騰迅振武M890晶片與超級節點伺服器此次升級的核心是騰迅推出的新一代AI晶片——振武M890,該晶片集訓練與推理功能於一體。效能提升:M890擁有144GB的記憶體,其效能是前代產品振武810E的三倍。
相關專題推薦
動畫創作
 頂級AI故事板生成工具:能夠自動將電影劇本轉化為動態動畫效果
頂級AI故事板生成工具:能夠自動將電影劇本轉化為動態動畫效果
在XIX.AI上,發現2026年最優秀的人工智慧故事板生成工具。我們精心挑選的這些高評分工具能夠自動將劇本轉化為電影風格的動畫效果,從而節省您的時間並提升前期製作效率。透過實際測試和每週更新的排名資訊,您可以瞭解免費選項與付費選項的差異。今天就找到最適合您的創意助手吧!
 10 個工具
10 個工具
 xix.ai
搜索引擎優化
最佳AI重定向與失效連結查詢工具:自動修復爬取錯誤,節省爬取預算
xix.ai
搜索引擎優化
最佳AI重定向與失效連結查詢工具:自動修復爬取錯誤,節省爬取預算
在XIX.AI上,發現2026年最優秀的人工智慧重定向工具和失效連結查詢工具。我們精心挑選的這些高評分工具能夠自動修復爬取錯誤,從而幫助您節省爬取預算。透過實際測試和每週更新的排名資訊,您可以比較免費選項和付費選項,立即找到最適合您的SEO解決方案!
10 個工具
xix.ai
視頻創作
播客創作者首選的頂尖 AI 影片製作工具:將音訊波形轉化為引人入勝的談話頭像影片
立即前往 XIX.AI,探索 2026 年最適合播客的頂尖 AI 影片製作工具。我們精心挑選並評選出的這份榜單,收錄了多款強大工具,能輕鬆將您的音訊轉化為引人入勝的談話頭像影片。透過實際測試與每週更新的排行榜,比較免費與付費選項的差異。立即解鎖您的視覺敘事優勢。
10 個工具
xix.ai
聊天機器人
利用這些角色扮演工具,打造屬於你的 AI 愛情故事
探索 2026 年最新、評價最高的 AI 角色扮演工具,打造身臨其境的敘事體驗。XIX.AI 精心整理的清單收錄了多款功能強大、能徹底改變遊戲規則的助手,助您釋放創意敘事潛能並增添情感深度。透過實際測試,比較免費與付費選項的差異。立即展開您的獨特旅程。
10 個工具
xix.ai
文字轉語音
獨立遊戲開發者必備的頂尖 AI 配音工具:為 RPG 與視覺小說節省配音時間
探索 2026 年最適合遊戲開發者的 AI 配音工具!XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲開發模式的解決方案,助您在角色扮演遊戲(RPG)和視覺小說(Visual Novel)的配音製作上節省時間與成本。探索免費與付費版本的比較、實際測試結果,以及每週更新的排行榜。立即找到最適合您的配音工具!
10 個工具
xix.ai
教育與學習
最佳人工智慧間隔重複學習工具:幫助醫學生和法律專業學生最佳化學習計劃
探索由 XIX.AI 精心挑選的 2026 年最佳 AI 間隔重複學習工具。我們推薦的這些極具創新性的工具能幫助醫學和法律專業的學生最佳化學習計劃,從而提高知識記憶效果。透過真實案例測試和每週更新的排名資訊,你可以瞭解免費選項與付費選項之間的差異。現在就開啟你的學習優勢吧!
10 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![JuanThomas]()
Wow, this AI health race is getting intense! Just saw the news about OpenAI, Google, and Anthropic all dropping medical AI tools almost at the same time. It's clearly a strategic move, not a coincidence. Makes you wonder who's really leading the pack and what it means for our future healthcare. Exciting but also a bit scary, right? 🤔
本月,OpenAI、Google 和 Anthropic 相隔僅數日便相繼揭露了各自專門的醫療 AI 功能。這波密集的公告顯示出競爭壓力,而非單純的巧合。然而,儘管行銷話術強調將徹底改變醫療保健,但這些產品均未獲准作為醫療器材、未獲准用於臨床,也無法直接用於患者診斷。
1月7日,OpenAI推出ChatGPT Health,透過與b.well、Apple Health、Function及MyFitnessPal的合作,讓美國用戶能串接醫療紀錄。Google則於1月13日發布MedGemma 1.5,將其開源醫療AI模型擴展至可解讀3D電腦斷層掃描(CT)與磁振造影(MRI)影像,以及全切片組織病理學影像。
Anthropic 隨後於 1 月 11 日推出「Claude for Healthcare」,提供符合 HIPAA 規範的連接器,可串接至 CMS 保險給付資料庫、ICD-10 編碼系統以及國家醫療服務提供者識別碼登記處。
這三家公司皆瞄準相同的行政痛點——事前授權審查、理賠處理及臨床文件記錄——雖採用相似的技術方法,但市場推廣策略各異。
開發者平台,而非診斷產品
其架構上的相似性令人驚嘆。每個系統皆採用針對醫學文獻與臨床資料集進行微調的多模態大型語言模型。各系統均強調隱私保護與法規免責聲明,並將自身定位為輔助而非取代臨床判斷。
差異在於部署與存取模式。OpenAI 的 ChatGPT Health 作為面向消費者的服務運作,針對歐洲經濟區(EEA)、瑞士及英國以外地區的 ChatGPT Free、Plus 和 Pro 訂閱用戶設有候補名單。Google 的 MedGemma 1.5 則透過其「健康 AI 開發者基礎計畫」以開放模型形式發布,使用者可透過 Hugging Face 下載,或透過 Google Cloud 的 Vertex AI 進行部署。
Anthropic 的 Claude for Healthcare 則透過 Claude for Enterprise 整合至現有企業工作流程,目標客群為機構買家而非個人消費者。這三者均持一致的監管立場。
OpenAI 明確聲明 Health「不適用於診斷或治療」。Google 將 MedGemma 定位為「開發者評估並適應其醫療應用場景的起點」。Anthropic 則強調其輸出結果「不應直接用於臨床診斷、病患管理決策、治療建議,或任何其他直接的臨床實踐應用」。
基準測試表現與臨床驗證
這三款產品在醫療 AI 基準測試中的表現均有顯著提升,但測試表現與實際臨床部署之間的差距依然龐大。Google 報告指出,MedGemma 1.5 在斯坦福大學的 MedAgentBench(醫療代理完成度基準測試)上達到了 92.3% 的準確度,而之前的 Sonnet 3.5 基準版本僅為 69.6%。
在內部測試中,該模型在 MRI 疾病分類上的表現提升了 14 個百分點,在 CT 檢查結果判讀上則提升了 3 個百分點。Anthropic 的 Claude Opus 4.5 在啟用 Python 程式碼執行功能的 MedCalc 醫療計算準確度測試中獲得 61.3% 的成績,而在 MedAgentBench 測試中則達到 92.3%。
該公司還聲稱在針對事實性幻覺的「誠實度評估」方面有所改善,但未公開具體指標。
OpenAI 並未針對 ChatGPT Health 發布具體的基準比較,而是根據對現有使用情況的去識別化分析指出,「全球每週有超過 2.3 億人透過 ChatGPT 提出健康與保健相關的問題」。
這些基準測試衡量的是在精選測試資料集上的表現,而非臨床結果。由於醫療錯誤可能導致危及生命的後果,將基準準確度轉化為實際臨床實用性,遠比其他 AI 領域複雜得多。
監管路徑仍不明朗
這些醫療 AI 工具的監管環境仍不明朗。在美國,FDA 的監管取決於產品的使用目的。任何「協助或向醫療專業人員提供關於預防、診斷或治療建議」的軟體,可能需作為醫療器材接受上市前審查。目前已公布的工具均未獲得 FDA 核准。
責任歸屬問題同樣懸而未決。當班納健康(Banner Health)的技術長麥克·雷金(Mike Reagin)表示該系統是「被 Anthropic 對 AI 安全的重視所吸引」時,這僅涉及技術選擇,而非法律責任框架。
若臨床醫師依賴 Claude 的預先授權分析,而患者因延誤治療而遭受傷害,現行判例法對責任歸屬幾乎沒有提供任何指引。
各區域的監管方針差異顯著。雖然美國食品藥物管理局(FDA)與歐洲《醫療器材法規》針對作為醫療器材的軟體提供了既定框架,但許多亞太地區監管機構尚未針對生成式人工智慧診斷工具發布具體指引。
這種不確定性影響了各市場的採用時程——在醫療基礎設施尚有缺口的市場中,這本可能加速技術導入,卻反而造成臨床需求與監管謹慎之間的張力。
行政工作流程,而非臨床決策
實際部署範圍仍相當有限。諾和諾德(Novo Nordisk)內容數位化總監 Louise Lind Skov 描述了將 Claude 用於「藥品開發中的文件與內容自動化」,重點在於法規申報而非患者診斷。
台灣健保署採用 MedGemma 從 30,000 份病理報告中提取數據進行政策分析,而非用於治療決策。
此模式顯示,機構採用AI的重點集中在行政工作流程上——例如帳務處理、文件記錄及試驗方案起草等,這些環節的錯誤通常不會立即造成危險;而非直接的臨床決策支援,儘管AI在後者領域對患者預後的影響可能最為顯著。
醫療 AI 的發展速度,已超越機構處理監管、法律責任及工作流程整合等複雜問題的能力。這項技術已然存在,只需支付月費,即可使用先進的醫療推理工具。
這是否能轉化為醫療服務的變革,取決於這些協調發布的聲明尚未解決的關鍵問題。
另請參閱:阿斯特捷利康押注內部 AI 以加速腫瘤學研究
想向業界領袖深入了解人工智慧與大數據?歡迎參加將於阿姆斯特丹、加州及倫敦舉辦的「人工智慧與大數據博覽會」。這場綜合性活動隸屬於 TechEx 系列,並與其他頂尖科技盛會同期舉行。點擊此處獲取更多資訊。
AI News 由 TechForge Media 提供技術支援。點此探索其他即將舉行的企業科技活動與線上研討會。










 Github Copilot的基於令牌的計費方式引發了開發者的強烈不滿
微軟GitHub Copilot的黃金時代可能即將結束,尤其是對個人使用者而言。該公司正從統一的訂閱費模式轉向基於代幣的計費方式,這可能會大幅增加使用成本。雖然大型企業或許還能承受這種變化,但小型企業和自由職業者可能會發現新的收費機制讓他們的月預算難以承受。這些變更將於6月1日正式生效,屆時使用者將按照工作中消耗的代幣數量來支付費用,而不再是按每次請求收取固定費用。一些開發者受到這一財務變動的影響,在Reddit和X平臺上表達了他們對這種看似過高的成本增加的擔憂。一位Redditor最近寫道:“
Github Copilot的基於令牌的計費方式引發了開發者的強烈不滿
微軟GitHub Copilot的黃金時代可能即將結束,尤其是對個人使用者而言。該公司正從統一的訂閱費模式轉向基於代幣的計費方式,這可能會大幅增加使用成本。雖然大型企業或許還能承受這種變化,但小型企業和自由職業者可能會發現新的收費機制讓他們的月預算難以承受。這些變更將於6月1日正式生效,屆時使用者將按照工作中消耗的代幣數量來支付費用,而不再是按每次請求收取固定費用。一些開發者受到這一財務變動的影響,在Reddit和X平臺上表達了他們對這種看似過高的成本增加的擔憂。一位Redditor最近寫道:“
 SpaceX的IPO申請檔案重點體現了其在衛星網際網路和人工智慧領域的發展雄心
在為即將進行的IPO提交的S-1註冊檔案中,SpaceX公佈了一系列令人矚目的業務資料,這些資料凸顯了其在航空航天通訊和人工智慧領域的強大實力:Starlink使用者數突破1000萬:截至2026年第一季度,全球付費Starlink使用者數量已達到1030萬,這一數字在過去一年內翻了一番。這一增長充分證明了作為全球最大的近地軌道衛星星座,Starlink在寬頻和行動通訊領域的領先地位。目前該衛星網路由大約9600顆衛星組成,這些衛星佔在軌所有活躍衛星總數的65%。Grok與X人工智慧生態體系:通
SpaceX的IPO申請檔案重點體現了其在衛星網際網路和人工智慧領域的發展雄心
在為即將進行的IPO提交的S-1註冊檔案中,SpaceX公佈了一系列令人矚目的業務資料,這些資料凸顯了其在航空航天通訊和人工智慧領域的強大實力:Starlink使用者數突破1000萬:截至2026年第一季度,全球付費Starlink使用者數量已達到1030萬,這一數字在過去一年內翻了一番。這一增長充分證明了作為全球最大的近地軌道衛星星座,Starlink在寬頻和行動通訊領域的領先地位。目前該衛星網路由大約9600顆衛星組成,這些衛星佔在軌所有活躍衛星總數的65%。Grok與X人工智慧生態體系:通
 阿里巴巴Tuhao M890上市,憑藉三重效能優勢開啟晶片-雲-模型-推理的全棧代理時代
2026年5月20日,在阿里雲峰會上,阿里雲宣佈完成了專為“智慧體時代”設計的全棧技術系統升級。這一變革重塑了整個技術體系——從底層晶片和雲平臺到模型與推理方案。此次升級使阿里雲成為一家能夠讓大量智慧體實現24/7連續執行的“AI工廠”,從而超越了單純為人類使用者提供服務的範疇。1. 核心基礎:騰迅振武M890晶片與超級節點伺服器此次升級的核心是騰迅推出的新一代AI晶片——振武M890,該晶片集訓練與推理功能於一體。效能提升:M890擁有144GB的記憶體,其效能是前代產品振武810E的三倍。
阿里巴巴Tuhao M890上市,憑藉三重效能優勢開啟晶片-雲-模型-推理的全棧代理時代
2026年5月20日,在阿里雲峰會上,阿里雲宣佈完成了專為“智慧體時代”設計的全棧技術系統升級。這一變革重塑了整個技術體系——從底層晶片和雲平臺到模型與推理方案。此次升級使阿里雲成為一家能夠讓大量智慧體實現24/7連續執行的“AI工廠”,從而超越了單純為人類使用者提供服務的範疇。1. 核心基礎:騰迅振武M890晶片與超級節點伺服器此次升級的核心是騰迅推出的新一代AI晶片——振武M890,該晶片集訓練與推理功能於一體。效能提升:M890擁有144GB的記憶體,其效能是前代產品振武810E的三倍。

在XIX.AI上,發現2026年最優秀的人工智慧故事板生成工具。我們精心挑選的這些高評分工具能夠自動將劇本轉化為電影風格的動畫效果,從而節省您的時間並提升前期製作效率。透過實際測試和每週更新的排名資訊,您可以瞭解免費選項與付費選項的差異。今天就找到最適合您的創意助手吧!
10 個工具
xix.ai

在XIX.AI上,發現2026年最優秀的人工智慧重定向工具和失效連結查詢工具。我們精心挑選的這些高評分工具能夠自動修復爬取錯誤,從而幫助您節省爬取預算。透過實際測試和每週更新的排名資訊,您可以比較免費選項和付費選項,立即找到最適合您的SEO解決方案!
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最適合播客的頂尖 AI 影片製作工具。我們精心挑選並評選出的這份榜單,收錄了多款強大工具,能輕鬆將您的音訊轉化為引人入勝的談話頭像影片。透過實際測試與每週更新的排行榜,比較免費與付費選項的差異。立即解鎖您的視覺敘事優勢。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 角色扮演工具,打造身臨其境的敘事體驗。XIX.AI 精心整理的清單收錄了多款功能強大、能徹底改變遊戲規則的助手,助您釋放創意敘事潛能並增添情感深度。透過實際測試,比較免費與付費選項的差異。立即展開您的獨特旅程。
10 個工具
xix.ai

探索 2026 年最適合遊戲開發者的 AI 配音工具!XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲開發模式的解決方案,助您在角色扮演遊戲(RPG)和視覺小說(Visual Novel)的配音製作上節省時間與成本。探索免費與付費版本的比較、實際測試結果,以及每週更新的排行榜。立即找到最適合您的配音工具!
10 個工具
xix.ai

探索由 XIX.AI 精心挑選的 2026 年最佳 AI 間隔重複學習工具。我們推薦的這些極具創新性的工具能幫助醫學和法律專業的學生最佳化學習計劃,從而提高知識記憶效果。透過真實案例測試和每週更新的排名資訊,你可以瞭解免費選項與付費選項之間的差異。現在就開啟你的學習優勢吧!
10 個工具
xix.ai

Wow, this AI health race is getting intense! Just saw the news about OpenAI, Google, and Anthropic all dropping medical AI tools almost at the same time. It's clearly a strategic move, not a coincidence. Makes you wonder who's really leading the pack and what it means for our future healthcare. Exciting but also a bit scary, right? 🤔













