
















 집
집오픈AI, 구글, 앤트로픽의 신제품 출시로 AI 헬스케어 기술 경쟁이 격화되고 있다
이번 달 들어 며칠 간격으로 OpenAI, 구글, 앤트로픽이 잇달아 전문 의료 AI 기능을 공개했다. 이러한 발표가 잇따른 것은 단순한 우연이 아니라 경쟁적 압박이 작용했음을 시사한다. 그러나 의료계를 혁신하겠다는 마케팅 문구와는 달리, 이들 제품 중 어느 것도 의료 기기로 인증받거나 임상 사용 승인을 받았거나 환자에 대한 직접적인 진단에 활용될 수 있는 것은 없다.
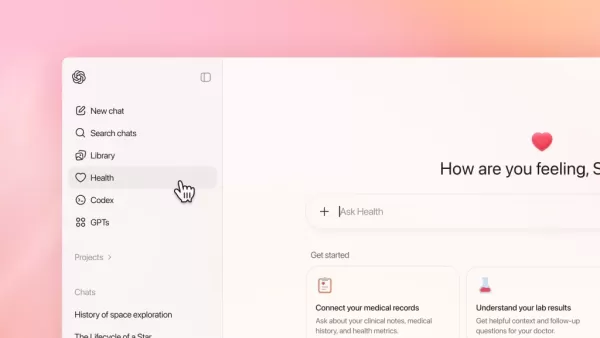
1월 7일, 오픈AI는 ChatGPT Health를 선보였으며, 이를 통해 미국 사용자들은 b.well, Apple Health, Function, MyFitnessPal과의 제휴를 통해 의료 기록을 연동할 수 있게 되었다. 구글은 1월 13일 MedGemma 1.5를 출시하며, 3D CT 및 MRI 스캔은 물론 전체 슬라이드 조직병리학 이미지를 해석할 수 있도록 자사의 오픈 의료 AI 모델을 확장했다.
Anthropic은 1월 11일 'Claude for Healthcare'를 출시하며, CMS 보장 데이터베이스, ICD-10 코딩 시스템, 국가 의료 제공자 식별자 등록부(National Provider Identifier Registry)에 대한 HIPAA 준수 연결 기능을 제공했다.
이 세 기업은 사전 승인 검토, 청구 처리, 임상 문서화 등 동일한 행정적 문제점을 해결 대상으로 삼고 있으며, 기술적 접근 방식은 비슷하지만 시장 진출 전략은 서로 다릅니다.
진단 제품이 아닌 개발자 플랫폼
아키텍처의 유사성은 눈에 띕니다. 각 시스템은 의학 문헌과 임상 데이터셋을 기반으로 미세 조정된 다중 모달 대규모 언어 모델을 사용합니다. 각 시스템은 개인정보 보호와 규제 관련 면책 조항을 강조합니다. 또한 각 시스템은 임상적 판단을 대체하는 것이 아니라 지원하는 역할을 한다고 포지셔닝합니다.
차이점은 배포 및 접근 모델에 있습니다. OpenAI의 ChatGPT Health는 EEA, 스위스, 영국 이외 지역의 ChatGPT Free, Plus, Pro 구독자를 대상으로 대기자 명단을 운영하는 소비자 대상 서비스로 운영됩니다. Google의 MedGemma 1.5는 Health AI Developer Foundations 프로그램을 통해 오픈 모델로 출시되었으며, Hugging Face를 통해 다운로드하거나 Google Cloud의 Vertex AI를 통해 배포할 수 있습니다.
Anthropic의 'Claude for Healthcare'는 'Claude for Enterprise'를 통해 기존 기업 워크플로우에 통합되며, 개인 소비자보다는 기관 구매자를 대상으로 합니다. 세 기업 모두 일관된 규제 입장을 공유합니다.
오픈AI는 Health가 "진단이나 치료를 목적으로 하지 않는다"고 명시하고 있습니다. 구글은 MedGemma를 "개발자가 의료용 사례를 평가하고 적용할 수 있는 출발점"으로 포지셔닝합니다. 앤트로픽은 출력 결과가 "임상 진단, 환자 관리 결정, 치료 권고 또는 기타 직접적인 임상 실무 적용에 직접적인 정보를 제공하기 위한 것이 아니다"라고 강조합니다.
벤치마크 성능 대 임상 검증
세 가지 릴리스 모두 의료 AI 벤치마크 점수가 크게 향상되었으나, 테스트 성능과 실제 임상 적용 간의 격차는 여전히 큽니다. 구글은 MedGemma 1.5가 의료 에이전트 완성도 벤치마크인 스탠포드 대학의 MedAgentBench에서 92.3%의 정확도를 달성했다고 보고했으며, 이는 이전 베이스라인인 Sonnet 3.5의 69.6%와 비교됩니다.
내부 테스트에서 이 모델은 MRI 질환 분류에서 14%포인트, CT 소견 분석에서 3%포인트의 성능 향상을 보였다. Anthropic의 Claude Opus 4.5는 Python 코드 실행이 활성화된 상태에서 MedCalc 의료 계산 정확도 테스트에서 61.3%, MedAgentBench에서는 92.3%의 정확도를 기록했다.
또한 이 회사는 사실적 환각에 대한 “정직성 평가”에서도 개선이 있었다고 주장했으나, 구체적인 지표는 공개하지 않았다.
오픈AI는 ChatGPT Health에 대한 구체적인 벤치마크 비교 결과를 공개하지 않았으나, 기존 사용 현황에 대한 비식별화 분석을 바탕으로 “전 세계적으로 매주 2억 3천만 명 이상이 ChatGPT에 건강 및 웰니스 관련 질문을 하고 있다”고 언급했다.
이러한 벤치마크는 선별된 테스트 데이터셋에서의 성능을 측정할 뿐, 임상적 결과를 측정하는 것은 아닙니다. 의료 오류는 생명을 위협할 수 있는 결과를 초래할 수 있으므로, 벤치마크 정확도를 실제 임상적 유용성으로 전환하는 것은 다른 AI 분야보다 훨씬 더 복잡합니다.
규제 경로는 여전히 불분명
이러한 의료용 AI 도구에 대한 규제 환경은 여전히 모호하다. 미국에서는 FDA의 감독 여부가 의도된 용도에 따라 결정된다. “예방, 진단 또는 치료에 관해 의료 전문가에게 지원을 제공하거나 권고 사항을 제시하는” 소프트웨어는 의료 기기로서 시판 전 심사를 받아야 할 수 있다. 현재 발표된 도구 중 어느 것도 FDA 승인을 받지 못했다.
책임 문제 역시 해결되지 않은 상태다. 배너 헬스(Banner Health)의 최고기술책임자(CTO) 마이크 리긴(Mike Reagin)이 이 시스템이 “AI 안전성에 중점을 둔 앤트로픽(Anthropic)의 접근 방식에 끌렸다”고 언급한 것은 기술 선택에 관한 것이지, 법적 책임 체계에 관한 것은 아니다.
만약 임상의가 클로드(Claude)의 사전 승인 분석에 의존했다가 치료 지연으로 인해 환자가 피해를 입는 경우, 기존 판례법은 책임 소재를 규명하는 데 거의 도움이 되지 않는다.
규제 접근 방식은 지역별로 크게 다릅니다. FDA와 유럽의 의료기기 규정(MDR)은 의료기기로서의 소프트웨어에 대해 확립된 프레임워크를 제공하지만, 많은 아시아태평양(APAC) 규제 당국은 아직 생성형 AI 진단 도구에 대한 구체적인 지침을 발표하지 않았습니다.
이러한 모호성은 의료 인프라의 격차로 인해 도입이 가속화될 수 있는 시장에서 도입 일정에 영향을 미치며, 임상적 필요성과 규제 당국의 신중한 태도 사이에 긴장을 야기합니다.
임상적 결정이 아닌 행정적 업무 흐름
실제 도입 범위는 여전히 좁은 수준에 머물러 있다. 노보 노르디스크(Novo Nordisk)의 콘텐츠 디지털화 담당 이사 루이즈 린드 스코브(Louise Lind Skov)는 클로드(Claude)를 “제약 개발 분야의 문서 및 콘텐츠 자동화”에 활용한다고 설명했으며, 이는 환자 진단보다는 규제 당국에 제출하는 서류에 중점을 둔다.
대만 국민건강보험국은 치료 결정이 아닌 정책 분석을 위해 3만 건의 병리 보고서를 분석하는 데 메드젬마(MedGemma)를 적용했다.
이러한 양상은 기관들의 도입이 AI가 환자 결과에 가장 극적인 영향을 미칠 수 있는 직접적인 임상 의사결정 지원보다는, 청구, 문서화, 프로토콜 작성 등 오류가 즉각적인 위험을 초래하지 않는 행정 업무 흐름에 집중되고 있음을 보여줍니다.
의료 AI의 발전 속도는 기관들이 규제, 책임, 워크플로 통합의 복잡성을 헤쳐 나갈 수 있는 속도를 앞지르고 있다. 기술은 이미 우리 곁에 있다. 정교한 의료 추론 도구를 월정액 요금으로 이용할 수 있다.
이것이 의료 서비스의 혁신으로 이어질지는, 이번 일련의 발표들이 아직 다루지 않은 핵심적인 질문들에 달려 있습니다.
관련 기사: 아스트라제네카, 종양학 연구 가속화를 위해 사내 AI에 베팅
업계 리더들의 AI 및 빅데이터에 대한 이야기를 더 듣고 싶으신가요? 암스테르담, 캘리포니아, 런던에서 열리는 AI & Big Data Expo를 확인해 보세요. 이 포괄적인 행사는 TechEx의 일환으로, 다른 주요 기술 행사와 함께 개최됩니다. 자세한 정보는 여기를 클릭하세요.
AI 뉴스는 TechForge Media에서 제공합니다. 다가오는 기업 기술 행사 및 웨비나를 여기서 확인해 보세요.
관련 기사
 스페이스X의 IPO 신청 자료에서 드러난 위성 인터넷 및 AI 분야 확장에 대한 야망
SpaceX가 계획 중인 IPO에 앞서 제출한 S-1 등록 서류에서, 항공우주 통신 및 인공지능 분야에서의 강력한 입지를 보여주는 여러 인상적인 재무 지표를 공개했습니다:Starlink 가입자 수 1,000만 명 돌파: 2026년 1분기 기준으로 전 세계에서 유료로 Starlink 서비스를 이용하는 가입자 수는 1,030만 명에 달했으며, 이는 지난 1년 동안 두 배로 증가한 수치입니다. 이러한 성장은 전 세계에서 가장 큰 저지구궤도 위성군을
알리바바 투하오 M890, 3배의 성능으로 출시되어 칩-클라우드-모델-추론을 위한 풀스택 에이전트 시대를 열다
2026년 5월 20일, 알리바바 클라우드 서밋에서 알리바바 클라우드는 에이전트 시대를 위해 설계된 풀스택 기술 시스템 업그레이드가 완료되었다고 발표했습니다. 이 변화는 기본 칩과 클라우드 플랫폼부터 모델 및 추론 솔루션에 이르기까지 전체 시스템을 재구성했습니다. 이를 통해 알리바바 클라우드는 거대한 에이전트들이 24시간 연중무휴로 작동할 수 있도록 지원하는 AI 공장으로 자리매김하게 되었으며, 이는 더 이상 인간 사용자에게 직접 서비스를 제공
펜티엄 4 리바이벌: 20년 된 CPU로 메타 라마 3 대형 모델을 실행하다
최근 유튜브의 기술 채널 Fully Buffered에서 인상적이고 대담한 실험을 진행했습니다. 2006년에 출시된 펜티엄 4 641 프로세서에서 메타의 최신 대형 모델인 Llama 3.2 3B를 성공적으로 실행한 것입니다.이 실험은 현대 인공지능을 20년 전의 하드웨어와 맞닿게 했으며, LLM의 기본적인 호환성 한계를 드러내는 동시에 많은 시청자들로 하여금 AI 시대에 무어의 법칙이 어떻게 이런 특이한 방식으로 세대 간의 교류를 이루었는지 생
관련 특별 주제 추천
비디오 제작
스페이스X의 IPO 신청 자료에서 드러난 위성 인터넷 및 AI 분야 확장에 대한 야망
SpaceX가 계획 중인 IPO에 앞서 제출한 S-1 등록 서류에서, 항공우주 통신 및 인공지능 분야에서의 강력한 입지를 보여주는 여러 인상적인 재무 지표를 공개했습니다:Starlink 가입자 수 1,000만 명 돌파: 2026년 1분기 기준으로 전 세계에서 유료로 Starlink 서비스를 이용하는 가입자 수는 1,030만 명에 달했으며, 이는 지난 1년 동안 두 배로 증가한 수치입니다. 이러한 성장은 전 세계에서 가장 큰 저지구궤도 위성군을
알리바바 투하오 M890, 3배의 성능으로 출시되어 칩-클라우드-모델-추론을 위한 풀스택 에이전트 시대를 열다
2026년 5월 20일, 알리바바 클라우드 서밋에서 알리바바 클라우드는 에이전트 시대를 위해 설계된 풀스택 기술 시스템 업그레이드가 완료되었다고 발표했습니다. 이 변화는 기본 칩과 클라우드 플랫폼부터 모델 및 추론 솔루션에 이르기까지 전체 시스템을 재구성했습니다. 이를 통해 알리바바 클라우드는 거대한 에이전트들이 24시간 연중무휴로 작동할 수 있도록 지원하는 AI 공장으로 자리매김하게 되었으며, 이는 더 이상 인간 사용자에게 직접 서비스를 제공
펜티엄 4 리바이벌: 20년 된 CPU로 메타 라마 3 대형 모델을 실행하다
최근 유튜브의 기술 채널 Fully Buffered에서 인상적이고 대담한 실험을 진행했습니다. 2006년에 출시된 펜티엄 4 641 프로세서에서 메타의 최신 대형 모델인 Llama 3.2 3B를 성공적으로 실행한 것입니다.이 실험은 현대 인공지능을 20년 전의 하드웨어와 맞닿게 했으며, LLM의 기본적인 호환성 한계를 드러내는 동시에 많은 시청자들로 하여금 AI 시대에 무어의 법칙이 어떻게 이런 특이한 방식으로 세대 간의 교류를 이루었는지 생
관련 특별 주제 추천
비디오 제작
 팟캐스터를 위한 최고의 AI 동영상 제작 도구: 오디오 파일을 흥미로운 토킹 헤드 영상으로 변환하세요
팟캐스터를 위한 최고의 AI 동영상 제작 도구: 오디오 파일을 흥미로운 토킹 헤드 영상으로 변환하세요
XIX.AI에서 팟캐스터를 위한 2026년 최고의 AI 동영상 제작 도구를 만나보세요. 엄선된 최고 평점 목록에는 오디오를 손쉽게 매력적인 토킹헤드 동영상으로 변환해 주는 강력한 도구들이 포함되어 있습니다. 실제 테스트와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 시각적 스토리텔링의 경쟁력을 확보하세요.
 10 도구
10 도구
 xix.ai
챗봇
이 역할극 도구들로 나만의 AI 러브 스토리를 만들어 보세요
xix.ai
챗봇
이 역할극 도구들로 나만의 AI 러브 스토리를 만들어 보세요
몰입감 넘치는 이야기를 만들어낼 수 있는 2026년 최신 최고 평점 AI 롤플레잉 도구를 만나보세요. XIX.AI가 엄선한 이 목록에는 창의적인 스토리텔링과 감성적 깊이를 이끌어내는 강력하고 혁신적인 어시스턴트들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 나만의 특별한 여정을 시작해 보세요.
10 도구
xix.ai
텍스트 음성 변환
인디 게임 개발자를 위한 최고의 AI 음성 도구: RPG와 비주얼 노벨의 성우 작업 시간을 단축하세요
게임 개발자를 위한 2026년 최고의 AI 음성 도구를 만나보세요! XIX.AI가 엄선한 이 목록에는 RPG와 비주얼 노벨의 성우 작업에 드는 시간과 비용을 절약해 줄, 최고 평점을 받은 혁신적인 솔루션들이 포함되어 있습니다. 무료 버전과 유료 버전의 비교 분석, 실제 테스트 결과, 매주 업데이트되는 순위 정보를 확인해 보세요. 지금 바로 여러분에게 딱 맞는 음성 도구를 찾아보세요!
10 도구
xix.ai
교육 및 학습
최고의 AI 기반 반복 학습 도구들: 의학 및 법학 전공 학생들을 위한 학습 계획 최적화 방법
2026년 최고의 AI 반복 학습 도구들을 만나보세요. XIX.AI가 엄선하여 제공합니다. 우리가 추천하는 이 도구들은 의학 및 법학 전공 학생들이 학습 계획을 최적화하여 최대한의 학습 효과를 얻는 데 도움을 줍니다. 무료 옵션과 유료 옵션을 실제 사용 사례와 매주 업데이트되는 순위를 통해 비교해 보세요. 지금 바로 학습 효율을 높이세요.
10 도구
xix.ai
비디오 제작
대본 작성과 시각적 스토리텔링을 위한 최고의 AI 텍스트-비디오 변환 플랫폼
2026년 최신 최고의 AI 텍스트-비디오 변환 플랫폼: 시나리오 작성과 시각적 스토리텔링을 위한 최고 평점 도구들. 텍스트를 매력적인 영상으로 변환해 줄 강력하고 혁신적인 솔루션을 만나보세요. 매주 업데이트되는 순위와 실제 테스트 결과를 통해 무료 및 유료 옵션을 비교해 보세요. 창의성과 생산성을 높여줄 완벽한 플랫폼을 찾아보세요. XIX.AI에서 엄선된 플랫폼을 확인해 보세요.
10 도구
xix.ai
챗봇
AI 멀티 에이전트 오케스트레이터: 자연어를 통해 복잡한 자동화 워크플로우를 설계하기
2026 최신 정보: 자연어를 통해 복잡한 자동화 워크플로우를 설계할 수 있는 최고의 AI 멀티 에이전트 오케스트레이터들을 만나보세요. 저희가 엄선한 이 목록에는 태스크 자동화와 지능형 프로세스 관리에 탁월한 최고의 플랫폼들이 포함되어 있습니다. 무료 옵션과 유료 옵션을 실제 사용 사례를 바탕으로 비교해 보세요. XIX.AI가 매주 업데이트하는 전문적인 순위를 통해 AI의 이점을 최대한 활용해 보세요.
10 도구
xix.ai

 의견 (1)
0/500
의견 (1)
0/500
![JuanThomas]()
Wow, this AI health race is getting intense! Just saw the news about OpenAI, Google, and Anthropic all dropping medical AI tools almost at the same time. It's clearly a strategic move, not a coincidence. Makes you wonder who's really leading the pack and what it means for our future healthcare. Exciting but also a bit scary, right? 🤔
이번 달 들어 며칠 간격으로 OpenAI, 구글, 앤트로픽이 잇달아 전문 의료 AI 기능을 공개했다. 이러한 발표가 잇따른 것은 단순한 우연이 아니라 경쟁적 압박이 작용했음을 시사한다. 그러나 의료계를 혁신하겠다는 마케팅 문구와는 달리, 이들 제품 중 어느 것도 의료 기기로 인증받거나 임상 사용 승인을 받았거나 환자에 대한 직접적인 진단에 활용될 수 있는 것은 없다.
1월 7일, 오픈AI는 ChatGPT Health를 선보였으며, 이를 통해 미국 사용자들은 b.well, Apple Health, Function, MyFitnessPal과의 제휴를 통해 의료 기록을 연동할 수 있게 되었다. 구글은 1월 13일 MedGemma 1.5를 출시하며, 3D CT 및 MRI 스캔은 물론 전체 슬라이드 조직병리학 이미지를 해석할 수 있도록 자사의 오픈 의료 AI 모델을 확장했다.
Anthropic은 1월 11일 'Claude for Healthcare'를 출시하며, CMS 보장 데이터베이스, ICD-10 코딩 시스템, 국가 의료 제공자 식별자 등록부(National Provider Identifier Registry)에 대한 HIPAA 준수 연결 기능을 제공했다.
이 세 기업은 사전 승인 검토, 청구 처리, 임상 문서화 등 동일한 행정적 문제점을 해결 대상으로 삼고 있으며, 기술적 접근 방식은 비슷하지만 시장 진출 전략은 서로 다릅니다.
진단 제품이 아닌 개발자 플랫폼
아키텍처의 유사성은 눈에 띕니다. 각 시스템은 의학 문헌과 임상 데이터셋을 기반으로 미세 조정된 다중 모달 대규모 언어 모델을 사용합니다. 각 시스템은 개인정보 보호와 규제 관련 면책 조항을 강조합니다. 또한 각 시스템은 임상적 판단을 대체하는 것이 아니라 지원하는 역할을 한다고 포지셔닝합니다.
차이점은 배포 및 접근 모델에 있습니다. OpenAI의 ChatGPT Health는 EEA, 스위스, 영국 이외 지역의 ChatGPT Free, Plus, Pro 구독자를 대상으로 대기자 명단을 운영하는 소비자 대상 서비스로 운영됩니다. Google의 MedGemma 1.5는 Health AI Developer Foundations 프로그램을 통해 오픈 모델로 출시되었으며, Hugging Face를 통해 다운로드하거나 Google Cloud의 Vertex AI를 통해 배포할 수 있습니다.
Anthropic의 'Claude for Healthcare'는 'Claude for Enterprise'를 통해 기존 기업 워크플로우에 통합되며, 개인 소비자보다는 기관 구매자를 대상으로 합니다. 세 기업 모두 일관된 규제 입장을 공유합니다.
오픈AI는 Health가 "진단이나 치료를 목적으로 하지 않는다"고 명시하고 있습니다. 구글은 MedGemma를 "개발자가 의료용 사례를 평가하고 적용할 수 있는 출발점"으로 포지셔닝합니다. 앤트로픽은 출력 결과가 "임상 진단, 환자 관리 결정, 치료 권고 또는 기타 직접적인 임상 실무 적용에 직접적인 정보를 제공하기 위한 것이 아니다"라고 강조합니다.
벤치마크 성능 대 임상 검증
세 가지 릴리스 모두 의료 AI 벤치마크 점수가 크게 향상되었으나, 테스트 성능과 실제 임상 적용 간의 격차는 여전히 큽니다. 구글은 MedGemma 1.5가 의료 에이전트 완성도 벤치마크인 스탠포드 대학의 MedAgentBench에서 92.3%의 정확도를 달성했다고 보고했으며, 이는 이전 베이스라인인 Sonnet 3.5의 69.6%와 비교됩니다.
내부 테스트에서 이 모델은 MRI 질환 분류에서 14%포인트, CT 소견 분석에서 3%포인트의 성능 향상을 보였다. Anthropic의 Claude Opus 4.5는 Python 코드 실행이 활성화된 상태에서 MedCalc 의료 계산 정확도 테스트에서 61.3%, MedAgentBench에서는 92.3%의 정확도를 기록했다.
또한 이 회사는 사실적 환각에 대한 “정직성 평가”에서도 개선이 있었다고 주장했으나, 구체적인 지표는 공개하지 않았다.
오픈AI는 ChatGPT Health에 대한 구체적인 벤치마크 비교 결과를 공개하지 않았으나, 기존 사용 현황에 대한 비식별화 분석을 바탕으로 “전 세계적으로 매주 2억 3천만 명 이상이 ChatGPT에 건강 및 웰니스 관련 질문을 하고 있다”고 언급했다.
이러한 벤치마크는 선별된 테스트 데이터셋에서의 성능을 측정할 뿐, 임상적 결과를 측정하는 것은 아닙니다. 의료 오류는 생명을 위협할 수 있는 결과를 초래할 수 있으므로, 벤치마크 정확도를 실제 임상적 유용성으로 전환하는 것은 다른 AI 분야보다 훨씬 더 복잡합니다.
규제 경로는 여전히 불분명
이러한 의료용 AI 도구에 대한 규제 환경은 여전히 모호하다. 미국에서는 FDA의 감독 여부가 의도된 용도에 따라 결정된다. “예방, 진단 또는 치료에 관해 의료 전문가에게 지원을 제공하거나 권고 사항을 제시하는” 소프트웨어는 의료 기기로서 시판 전 심사를 받아야 할 수 있다. 현재 발표된 도구 중 어느 것도 FDA 승인을 받지 못했다.
책임 문제 역시 해결되지 않은 상태다. 배너 헬스(Banner Health)의 최고기술책임자(CTO) 마이크 리긴(Mike Reagin)이 이 시스템이 “AI 안전성에 중점을 둔 앤트로픽(Anthropic)의 접근 방식에 끌렸다”고 언급한 것은 기술 선택에 관한 것이지, 법적 책임 체계에 관한 것은 아니다.
만약 임상의가 클로드(Claude)의 사전 승인 분석에 의존했다가 치료 지연으로 인해 환자가 피해를 입는 경우, 기존 판례법은 책임 소재를 규명하는 데 거의 도움이 되지 않는다.
규제 접근 방식은 지역별로 크게 다릅니다. FDA와 유럽의 의료기기 규정(MDR)은 의료기기로서의 소프트웨어에 대해 확립된 프레임워크를 제공하지만, 많은 아시아태평양(APAC) 규제 당국은 아직 생성형 AI 진단 도구에 대한 구체적인 지침을 발표하지 않았습니다.
이러한 모호성은 의료 인프라의 격차로 인해 도입이 가속화될 수 있는 시장에서 도입 일정에 영향을 미치며, 임상적 필요성과 규제 당국의 신중한 태도 사이에 긴장을 야기합니다.
임상적 결정이 아닌 행정적 업무 흐름
실제 도입 범위는 여전히 좁은 수준에 머물러 있다. 노보 노르디스크(Novo Nordisk)의 콘텐츠 디지털화 담당 이사 루이즈 린드 스코브(Louise Lind Skov)는 클로드(Claude)를 “제약 개발 분야의 문서 및 콘텐츠 자동화”에 활용한다고 설명했으며, 이는 환자 진단보다는 규제 당국에 제출하는 서류에 중점을 둔다.
대만 국민건강보험국은 치료 결정이 아닌 정책 분석을 위해 3만 건의 병리 보고서를 분석하는 데 메드젬마(MedGemma)를 적용했다.
이러한 양상은 기관들의 도입이 AI가 환자 결과에 가장 극적인 영향을 미칠 수 있는 직접적인 임상 의사결정 지원보다는, 청구, 문서화, 프로토콜 작성 등 오류가 즉각적인 위험을 초래하지 않는 행정 업무 흐름에 집중되고 있음을 보여줍니다.
의료 AI의 발전 속도는 기관들이 규제, 책임, 워크플로 통합의 복잡성을 헤쳐 나갈 수 있는 속도를 앞지르고 있다. 기술은 이미 우리 곁에 있다. 정교한 의료 추론 도구를 월정액 요금으로 이용할 수 있다.
이것이 의료 서비스의 혁신으로 이어질지는, 이번 일련의 발표들이 아직 다루지 않은 핵심적인 질문들에 달려 있습니다.
관련 기사: 아스트라제네카, 종양학 연구 가속화를 위해 사내 AI에 베팅
업계 리더들의 AI 및 빅데이터에 대한 이야기를 더 듣고 싶으신가요? 암스테르담, 캘리포니아, 런던에서 열리는 AI & Big Data Expo를 확인해 보세요. 이 포괄적인 행사는 TechEx의 일환으로, 다른 주요 기술 행사와 함께 개최됩니다. 자세한 정보는 여기를 클릭하세요.
AI 뉴스는 TechForge Media에서 제공합니다. 다가오는 기업 기술 행사 및 웨비나를 여기서 확인해 보세요.










 스페이스X의 IPO 신청 자료에서 드러난 위성 인터넷 및 AI 분야 확장에 대한 야망
SpaceX가 계획 중인 IPO에 앞서 제출한 S-1 등록 서류에서, 항공우주 통신 및 인공지능 분야에서의 강력한 입지를 보여주는 여러 인상적인 재무 지표를 공개했습니다:Starlink 가입자 수 1,000만 명 돌파: 2026년 1분기 기준으로 전 세계에서 유료로 Starlink 서비스를 이용하는 가입자 수는 1,030만 명에 달했으며, 이는 지난 1년 동안 두 배로 증가한 수치입니다. 이러한 성장은 전 세계에서 가장 큰 저지구궤도 위성군을
스페이스X의 IPO 신청 자료에서 드러난 위성 인터넷 및 AI 분야 확장에 대한 야망
SpaceX가 계획 중인 IPO에 앞서 제출한 S-1 등록 서류에서, 항공우주 통신 및 인공지능 분야에서의 강력한 입지를 보여주는 여러 인상적인 재무 지표를 공개했습니다:Starlink 가입자 수 1,000만 명 돌파: 2026년 1분기 기준으로 전 세계에서 유료로 Starlink 서비스를 이용하는 가입자 수는 1,030만 명에 달했으며, 이는 지난 1년 동안 두 배로 증가한 수치입니다. 이러한 성장은 전 세계에서 가장 큰 저지구궤도 위성군을
 알리바바 투하오 M890, 3배의 성능으로 출시되어 칩-클라우드-모델-추론을 위한 풀스택 에이전트 시대를 열다
2026년 5월 20일, 알리바바 클라우드 서밋에서 알리바바 클라우드는 에이전트 시대를 위해 설계된 풀스택 기술 시스템 업그레이드가 완료되었다고 발표했습니다. 이 변화는 기본 칩과 클라우드 플랫폼부터 모델 및 추론 솔루션에 이르기까지 전체 시스템을 재구성했습니다. 이를 통해 알리바바 클라우드는 거대한 에이전트들이 24시간 연중무휴로 작동할 수 있도록 지원하는 AI 공장으로 자리매김하게 되었으며, 이는 더 이상 인간 사용자에게 직접 서비스를 제공
알리바바 투하오 M890, 3배의 성능으로 출시되어 칩-클라우드-모델-추론을 위한 풀스택 에이전트 시대를 열다
2026년 5월 20일, 알리바바 클라우드 서밋에서 알리바바 클라우드는 에이전트 시대를 위해 설계된 풀스택 기술 시스템 업그레이드가 완료되었다고 발표했습니다. 이 변화는 기본 칩과 클라우드 플랫폼부터 모델 및 추론 솔루션에 이르기까지 전체 시스템을 재구성했습니다. 이를 통해 알리바바 클라우드는 거대한 에이전트들이 24시간 연중무휴로 작동할 수 있도록 지원하는 AI 공장으로 자리매김하게 되었으며, 이는 더 이상 인간 사용자에게 직접 서비스를 제공
 펜티엄 4 리바이벌: 20년 된 CPU로 메타 라마 3 대형 모델을 실행하다
최근 유튜브의 기술 채널 Fully Buffered에서 인상적이고 대담한 실험을 진행했습니다. 2006년에 출시된 펜티엄 4 641 프로세서에서 메타의 최신 대형 모델인 Llama 3.2 3B를 성공적으로 실행한 것입니다.이 실험은 현대 인공지능을 20년 전의 하드웨어와 맞닿게 했으며, LLM의 기본적인 호환성 한계를 드러내는 동시에 많은 시청자들로 하여금 AI 시대에 무어의 법칙이 어떻게 이런 특이한 방식으로 세대 간의 교류를 이루었는지 생
펜티엄 4 리바이벌: 20년 된 CPU로 메타 라마 3 대형 모델을 실행하다
최근 유튜브의 기술 채널 Fully Buffered에서 인상적이고 대담한 실험을 진행했습니다. 2006년에 출시된 펜티엄 4 641 프로세서에서 메타의 최신 대형 모델인 Llama 3.2 3B를 성공적으로 실행한 것입니다.이 실험은 현대 인공지능을 20년 전의 하드웨어와 맞닿게 했으며, LLM의 기본적인 호환성 한계를 드러내는 동시에 많은 시청자들로 하여금 AI 시대에 무어의 법칙이 어떻게 이런 특이한 방식으로 세대 간의 교류를 이루었는지 생

XIX.AI에서 팟캐스터를 위한 2026년 최고의 AI 동영상 제작 도구를 만나보세요. 엄선된 최고 평점 목록에는 오디오를 손쉽게 매력적인 토킹헤드 동영상으로 변환해 주는 강력한 도구들이 포함되어 있습니다. 실제 테스트와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 시각적 스토리텔링의 경쟁력을 확보하세요.
10 도구
xix.ai

몰입감 넘치는 이야기를 만들어낼 수 있는 2026년 최신 최고 평점 AI 롤플레잉 도구를 만나보세요. XIX.AI가 엄선한 이 목록에는 창의적인 스토리텔링과 감성적 깊이를 이끌어내는 강력하고 혁신적인 어시스턴트들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 나만의 특별한 여정을 시작해 보세요.
10 도구
xix.ai

게임 개발자를 위한 2026년 최고의 AI 음성 도구를 만나보세요! XIX.AI가 엄선한 이 목록에는 RPG와 비주얼 노벨의 성우 작업에 드는 시간과 비용을 절약해 줄, 최고 평점을 받은 혁신적인 솔루션들이 포함되어 있습니다. 무료 버전과 유료 버전의 비교 분석, 실제 테스트 결과, 매주 업데이트되는 순위 정보를 확인해 보세요. 지금 바로 여러분에게 딱 맞는 음성 도구를 찾아보세요!
10 도구
xix.ai

2026년 최고의 AI 반복 학습 도구들을 만나보세요. XIX.AI가 엄선하여 제공합니다. 우리가 추천하는 이 도구들은 의학 및 법학 전공 학생들이 학습 계획을 최적화하여 최대한의 학습 효과를 얻는 데 도움을 줍니다. 무료 옵션과 유료 옵션을 실제 사용 사례와 매주 업데이트되는 순위를 통해 비교해 보세요. 지금 바로 학습 효율을 높이세요.
10 도구
xix.ai

2026년 최신 최고의 AI 텍스트-비디오 변환 플랫폼: 시나리오 작성과 시각적 스토리텔링을 위한 최고 평점 도구들. 텍스트를 매력적인 영상으로 변환해 줄 강력하고 혁신적인 솔루션을 만나보세요. 매주 업데이트되는 순위와 실제 테스트 결과를 통해 무료 및 유료 옵션을 비교해 보세요. 창의성과 생산성을 높여줄 완벽한 플랫폼을 찾아보세요. XIX.AI에서 엄선된 플랫폼을 확인해 보세요.
10 도구
xix.ai

2026 최신 정보: 자연어를 통해 복잡한 자동화 워크플로우를 설계할 수 있는 최고의 AI 멀티 에이전트 오케스트레이터들을 만나보세요. 저희가 엄선한 이 목록에는 태스크 자동화와 지능형 프로세스 관리에 탁월한 최고의 플랫폼들이 포함되어 있습니다. 무료 옵션과 유료 옵션을 실제 사용 사례를 바탕으로 비교해 보세요. XIX.AI가 매주 업데이트하는 전문적인 순위를 통해 AI의 이점을 최대한 활용해 보세요.
10 도구
xix.ai

Wow, this AI health race is getting intense! Just saw the news about OpenAI, Google, and Anthropic all dropping medical AI tools almost at the same time. It's clearly a strategic move, not a coincidence. Makes you wonder who's really leading the pack and what it means for our future healthcare. Exciting but also a bit scary, right? 🤔













