
















 Heim
Heim
Der Wettstreit im Bereich KI-Gesundheitstechnologie spitzt sich mit neuen Produkten von OpenAI, Google und Anthropic zu
Innerhalb weniger Tage haben OpenAI, Google und Anthropic in diesem Monat jeweils spezielle medizinische KI-Funktionen vorgestellt. Diese Häufung von Ankündigungen deutet eher auf Wettbewerbsdruck als auf einen bloßen Zufall hin. Allerdings ist keines dieser Produkte als Medizinprodukt zugelassen, für den klinischen Einsatz freigegeben oder für die direkte Patientendiagnose verfügbar – trotz einer Marketingrhetorik, die die Transformation des Gesundheitswesens betont.
Am 7. Januar stellte OpenAI ChatGPT Health vor, das US-Nutzern über Partnerschaften mit b.well, Apple Health, Function und MyFitnessPal die Anbindung von Krankenakten ermöglicht. Google veröffentlichte am 13. Januar MedGemma 1.5 und erweiterte damit sein offenes medizinisches KI-Modell, um 3D-CT- und MRT-Scans sowie histopathologische Ganzpräparat-Bilder zu interpretieren.
Anthropic folgte am 11. Januar mit Claude for Healthcare und bietet HIPAA-konforme Schnittstellen zu CMS-Versicherungsdatenbanken, ICD-10-Kodierungssystemen und dem National Provider Identifier Registry.
Alle drei Unternehmen zielen auf dieselben administrativen Schwachstellen ab – Vorabgenehmigungsprüfungen, Schadenbearbeitung und klinische Dokumentation – mit ähnlichen technischen Ansätzen, aber unterschiedlichen Markteinführungsstrategien.
Entwicklerplattformen, keine Diagnoseprodukte
Die architektonischen Ähnlichkeiten sind auffällig. Jedes System nutzt multimodale große Sprachmodelle, die auf medizinische Literatur und klinische Datensätze abgestimmt sind. Jedes betont Datenschutzmaßnahmen und rechtliche Hinweise. Jedes positioniert sich als Unterstützung und nicht als Ersatz für das klinische Urteilsvermögen.
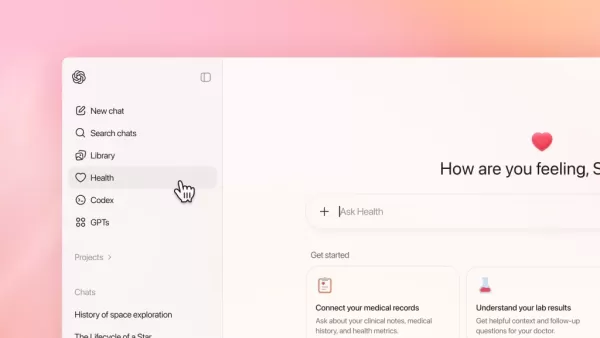
Die Unterschiede liegen in den Bereitstellungs- und Zugangsmodellen. ChatGPT Health von OpenAI fungiert als verbraucherorientierter Dienst mit einer Warteliste für Abonnenten von ChatGPT Free, Plus und Pro außerhalb des EWR, der Schweiz und des Vereinigten Königreichs. MedGemma 1.5 von Google wird als offenes Modell über das „Health AI Developer Foundations“-Programm veröffentlicht und steht zum Download über Hugging Face oder zur Bereitstellung über Vertex AI von Google Cloud zur Verfügung.
Anthropics „Claude for Healthcare“ lässt sich über „Claude for Enterprise“ in bestehende Unternehmensabläufe integrieren und richtet sich eher an institutionelle Käufer als an einzelne Verbraucher. Alle drei verfolgen eine einheitliche regulatorische Haltung.
OpenAI erklärt ausdrücklich, dass Health „nicht für Diagnose- oder Behandlungszwecke bestimmt ist“. Google positioniert MedGemma als „Ausgangspunkt für Entwickler, um ihre medizinischen Anwendungsfälle zu bewerten und anzupassen“. Anthropic betont, dass die Ergebnisse „nicht dazu bestimmt sind, direkt in klinische Diagnosen, Entscheidungen zum Patientenmanagement, Behandlungsempfehlungen oder andere direkte Anwendungen in der klinischen Praxis einfließen“.
Benchmark-Leistung vs. klinische Validierung
Die Benchmark-Ergebnisse für medizinische KI zeigten bei allen drei Versionen erhebliche Verbesserungen, obwohl die Kluft zwischen Testleistung und dem klinischen Einsatz in der Praxis nach wie vor groß ist. Google berichtet, dass MedGemma 1.5 auf dem MedAgentBench von Stanford, einem Benchmark für die Vervollständigung medizinischer Agenten, eine Genauigkeit von 92,3 % erreichte, verglichen mit 69,6 % bei der vorherigen Baseline Sonnet 3.5.
In internen Tests verbesserte sich das Modell um 14 Prozentpunkte bei der MRT-Krankheitsklassifizierung und um 3 Prozentpunkte bei CT-Befunden. Anthropics Claude Opus 4.5 erzielte 61,3 % bei den MedCalc-Tests zur medizinischen Berechnungsgenauigkeit mit aktivierter Python-Codeausführung und 92,3 % auf dem MedAgentBench.
Das Unternehmen gibt zudem Verbesserungen bei den „Ehrlichkeitsbewertungen“ in Bezug auf faktische Halluzinationen an, obwohl keine konkreten Kennzahlen genannt wurden.
OpenAI hat keine Benchmark-Vergleiche speziell für ChatGPT Health veröffentlicht, sondern weist darauf hin, dass „weltweit über 230 Millionen Menschen jede Woche gesundheits- und wellnessbezogene Fragen auf ChatGPT stellen“, basierend auf einer anonymisierten Analyse der bestehenden Nutzung.
Diese Benchmarks messen die Leistung anhand kuratierter Testdatensätze, nicht anhand klinischer Ergebnisse. Da medizinische Fehler lebensbedrohliche Folgen haben können, ist die Übertragung der Benchmark-Genauigkeit auf den tatsächlichen klinischen Nutzen weitaus komplexer als in anderen KI-Bereichen.
Regulatorischer Weg bleibt unklar
Die regulatorische Landschaft für diese medizinischen KI-Tools ist nach wie vor unklar. In den USA hängt die Aufsicht durch die FDA vom Verwendungszweck ab. Software, die „medizinisches Fachpersonal bei der Prävention, Diagnose oder Behandlung unterstützt oder Empfehlungen gibt“, muss möglicherweise als Medizinprodukt vor der Markteinführung geprüft werden. Keines der angekündigten Tools verfügt derzeit über eine FDA-Zulassung.
Haftungsfragen sind ebenfalls ungeklärt. Wenn Mike Reagin, CTO von Banner Health, erklärt, das System sei „von Anthropics Fokus auf KI-Sicherheit angezogen worden“, bezieht sich dies auf die Technologieauswahl, nicht auf rechtliche Haftungsrahmen.
Wenn sich ein Kliniker auf die Vorabgenehmigungsanalyse von Claude verlässt und einem Patienten durch eine verzögerte Behandlung Schaden entsteht, bietet die bestehende Rechtsprechung wenig Orientierung bei der Zuweisung der Verantwortung.
Die regulatorischen Ansätze variieren je nach Region erheblich. Während die FDA und die europäische Medizinprodukteverordnung etablierte Rahmenbedingungen für Software als Medizinprodukt bieten, haben viele Regulierungsbehörden im asiatisch-pazifischen Raum noch keine spezifischen Leitlinien für generative KI-Diagnosetools herausgegeben.
Diese Unklarheit wirkt sich auf die Einführungszeitpläne in Märkten aus, in denen Lücken in der Gesundheitsinfrastruktur die Implementierung andernfalls beschleunigen könnten, was zu Spannungen zwischen klinischem Bedarf und regulatorischer Vorsicht führt.
Administrative Arbeitsabläufe, keine klinischen Entscheidungen
Die tatsächlichen Einsatzbereiche sind nach wie vor eng gefasst. Louise Lind Skov, Director of Content Digitalisation bei Novo Nordisk, beschrieb den Einsatz von Claude für die „Automatisierung von Dokumenten und Inhalten in der pharmazeutischen Entwicklung“, wobei der Schwerpunkt auf Zulassungsanträgen und nicht auf der Patientendiagnose lag.
Die taiwanesische Nationale Krankenversicherungsbehörde setzte MedGemma ein, um Daten aus 30.000 pathologischen Befunden für politische Analysen zu extrahieren, nicht für Behandlungsentscheidungen.
Dieses Muster zeigt, dass sich die institutionelle Einführung auf administrative Arbeitsabläufe konzentriert, bei denen Fehler weniger unmittelbar gefährlich sind – wie Abrechnung, Dokumentation und Protokollentwürfe –, anstatt auf die direkte Unterstützung klinischer Entscheidungen, wo KI die Patientenergebnisse am dramatischsten beeinflussen könnte.
Die Fähigkeiten der medizinischen KI entwickeln sich schneller, als Institutionen die Komplexität in Bezug auf Regulierung, Haftung und Workflow-Integration bewältigen können. Die Technologie ist bereits vorhanden. Ausgefeilte Tools für medizinisches Schlussfolgern sind gegen eine monatliche Gebühr zugänglich.
Ob dies zu einer transformierten Gesundheitsversorgung führt, hängt von entscheidenden Fragen ab, die diese koordinierten Ankündigungen noch nicht beantwortet haben.
Siehe auch: AstraZeneca setzt auf interne KI, um die Krebsforschung zu beschleunigen
Möchten Sie mehr über KI und Big Data von Branchenführern erfahren? Besuchen Sie die AI & Big Data Expo in Amsterdam, Kalifornien und London. Die umfassende Veranstaltung ist Teil der TechEx und findet gemeinsam mit anderen führenden Technologieveranstaltungen statt. Klicken Sie hier für weitere Informationen.
AI News wird von TechForge Media bereitgestellt. Entdecken Sie hier weitere bevorstehende Veranstaltungen und Webinare zum Thema Unternehmenstechnologie.
Verwandter Artikel
 Hervorhebungen aus der IPO-Dokumentation von SpaceX: Ambitionen für die Ausweitung des Satelliten-Internet- und KI-Geschäfts
In ihrer S-1-Einreichung vor der geplanten IPO hat SpaceX kürzlich eine Reihe beeindruckender Geschäftszahlen veröffentlicht, die ihre starke Position im Bereich der Luftfahrtkommunikation und Künstlichen Intelligenz unterstreichen:Starlink-Abonnente
Alibaba Tuhao M890 debütiert mit dreifacher Leistungsfähigkeit und markiert den Beginn der Ära der vollständig integrierten Agenten für das Chip-Cloud-Modell-Inferenz-Verfahren.
Am 20. Mai 2026 kündigte Alibaba Cloud auf dem Alibaba Cloud Summit die Fertigstellung eines umfassenden Upgrades des Technologiesystems an, das speziell für die Ära der Agenten entwickelt wurde. Diese Umstrukturierung prägte den gesamten Prozess – v
Pentium 4 Revival: Ein 20 Jahre alter Prozessor läuft das Meta Llama 3 Large Model
Kürzlich führte der YouTube-Technikkanal Fully Buffered ein beeindruckendes und anspruchsvolles Experiment durch: Es gelang, Metas neuestes großes Modell Llama 3.2 3B erfolgreich auf dem Pentium 4 641-Prozessor zu betreiben – einem Chip, der im Jahr
Empfehlungen zu verwandten Spezialthemen
Videoerstellung
Hervorhebungen aus der IPO-Dokumentation von SpaceX: Ambitionen für die Ausweitung des Satelliten-Internet- und KI-Geschäfts
In ihrer S-1-Einreichung vor der geplanten IPO hat SpaceX kürzlich eine Reihe beeindruckender Geschäftszahlen veröffentlicht, die ihre starke Position im Bereich der Luftfahrtkommunikation und Künstlichen Intelligenz unterstreichen:Starlink-Abonnente
Alibaba Tuhao M890 debütiert mit dreifacher Leistungsfähigkeit und markiert den Beginn der Ära der vollständig integrierten Agenten für das Chip-Cloud-Modell-Inferenz-Verfahren.
Am 20. Mai 2026 kündigte Alibaba Cloud auf dem Alibaba Cloud Summit die Fertigstellung eines umfassenden Upgrades des Technologiesystems an, das speziell für die Ära der Agenten entwickelt wurde. Diese Umstrukturierung prägte den gesamten Prozess – v
Pentium 4 Revival: Ein 20 Jahre alter Prozessor läuft das Meta Llama 3 Large Model
Kürzlich führte der YouTube-Technikkanal Fully Buffered ein beeindruckendes und anspruchsvolles Experiment durch: Es gelang, Metas neuestes großes Modell Llama 3.2 3B erfolgreich auf dem Pentium 4 641-Prozessor zu betreiben – einem Chip, der im Jahr
Empfehlungen zu verwandten Spezialthemen
Videoerstellung
 Die besten KI-Videotools für Podcaster: Verwandeln Sie Audioaufnahmen in fesselnde Talking-Head-Videos
Die besten KI-Videotools für Podcaster: Verwandeln Sie Audioaufnahmen in fesselnde Talking-Head-Videos
Entdecken Sie bei XIX.AI die besten KI-Videotools für Podcaster im Jahr 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, mit denen Sie Ihre Audioaufnahmen mühelos in ansprechende Talking-Head-Videos umwandeln können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schaffen Sie sich jetzt einen Vorsprung beim visuellen Storytelling.
 10 Tools
10 Tools
 xix.ai
Chatbot
Erstelle deine eigene KI-Liebesgeschichte mit diesen Rollenspiel-Tools
xix.ai
Chatbot
Erstelle deine eigene KI-Liebesgeschichte mit diesen Rollenspiel-Tools
Entdecken Sie die besten KI-Tools für Rollenspiele des Jahres 2026, mit denen Sie fesselnde Geschichten erschaffen können. Die von XIX.AI zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Assistenten, die kreatives Storytelling und emotionale Tiefe ermöglichen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Beginnen Sie noch heute Ihre ganz persönliche Reise.
10 Tools
xix.ai
Text-zu-Sprache
Die besten KI-Sprachtools für Indie-Spieleentwickler: Sparen Sie Zeit bei der Sprachausgabe für RPGs und Visual Novels
Entdecken Sie die besten KI-Sprachtools für Spieleentwickler im Jahr 2026! Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, mit denen Sie bei der Sprachausgabe für RPGs und Visual Novels Zeit und Geld sparen. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings. Finden Sie noch heute Ihr perfektes Sprachtool!
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-basierten Werkzeuge für geplantes Wiederholen: Optimieren Sie Ihr Lernplan für Medizinstudenten und Jurastudenten
Entdecken Sie die besten KI-basierten Wiederholungstools für das Jahr 2026, ausgewählt von XIX.AI. Unsere hochbewerteten, bahnbrechenden Tools helfen Medizinstudenten und Jurastudenten dabei, ihre Lernpläne so zu optimieren, dass das Gelernte optimal im Gedächtnis bleibt. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie jetzt Ihren Vorsprung beim Lernen.
10 Tools
xix.ai
Videoerstellung
Die besten KI-Plattformen für die Umwandlung von Text in Video zum Verfassen von Drehbüchern und für visuelles Storytelling
Die besten KI-Plattformen für die Umwandlung von Text in Video im Jahr 2026: Erstklassige Tools für das Verfassen von Drehbüchern und visuelles Storytelling. Entdecken Sie leistungsstarke, bahnbrechende Lösungen, mit denen Sie Ihren Text in fesselnde Videos verwandeln können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand unserer wöchentlich aktualisierten Ranglisten und Praxistests. Finden Sie die perfekte Plattform, um Ihre Kreativität und Produktivität zu steigern. Entdecken Sie die sorgfältig zusammengestellte Auswahl bei XIX.AI.
10 Tools
xix.ai
Chatbot
KI-Multi-Agent-Orchestratoren: Gestaltung komplexer automatisierter Arbeitsabläufe mithilfe natürlicher Sprache
2026 Neuestes: Entdecken Sie die besten AI-Multi-Agenten-Orchestratoren, um mithilfe natürlicher Sprache komplexe automatisierte Arbeitsabläufe zu gestalten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete, leistungsstarke Plattformen für reibungslose Aufgabenerstellung und intelligente Prozessverwaltung. Vergleichen Sie kostenlose und kostenpflichtige Optionen unter Berücksichtigung praktischer Erfahrungen. Nutzen Sie die wöchentlich aktualisierten Rankings von XIX.AI, um einen Vorsprung durch künstliche Intelligenz zu erlangen.
10 Tools
xix.ai

 Kommentare (1)
Kommentare (1)
![JuanThomas]()
Wow, this AI health race is getting intense! Just saw the news about OpenAI, Google, and Anthropic all dropping medical AI tools almost at the same time. It's clearly a strategic move, not a coincidence. Makes you wonder who's really leading the pack and what it means for our future healthcare. Exciting but also a bit scary, right? 🤔
Innerhalb weniger Tage haben OpenAI, Google und Anthropic in diesem Monat jeweils spezielle medizinische KI-Funktionen vorgestellt. Diese Häufung von Ankündigungen deutet eher auf Wettbewerbsdruck als auf einen bloßen Zufall hin. Allerdings ist keines dieser Produkte als Medizinprodukt zugelassen, für den klinischen Einsatz freigegeben oder für die direkte Patientendiagnose verfügbar – trotz einer Marketingrhetorik, die die Transformation des Gesundheitswesens betont.
Am 7. Januar stellte OpenAI ChatGPT Health vor, das US-Nutzern über Partnerschaften mit b.well, Apple Health, Function und MyFitnessPal die Anbindung von Krankenakten ermöglicht. Google veröffentlichte am 13. Januar MedGemma 1.5 und erweiterte damit sein offenes medizinisches KI-Modell, um 3D-CT- und MRT-Scans sowie histopathologische Ganzpräparat-Bilder zu interpretieren.
Anthropic folgte am 11. Januar mit Claude for Healthcare und bietet HIPAA-konforme Schnittstellen zu CMS-Versicherungsdatenbanken, ICD-10-Kodierungssystemen und dem National Provider Identifier Registry.
Alle drei Unternehmen zielen auf dieselben administrativen Schwachstellen ab – Vorabgenehmigungsprüfungen, Schadenbearbeitung und klinische Dokumentation – mit ähnlichen technischen Ansätzen, aber unterschiedlichen Markteinführungsstrategien.
Entwicklerplattformen, keine Diagnoseprodukte
Die architektonischen Ähnlichkeiten sind auffällig. Jedes System nutzt multimodale große Sprachmodelle, die auf medizinische Literatur und klinische Datensätze abgestimmt sind. Jedes betont Datenschutzmaßnahmen und rechtliche Hinweise. Jedes positioniert sich als Unterstützung und nicht als Ersatz für das klinische Urteilsvermögen.
Die Unterschiede liegen in den Bereitstellungs- und Zugangsmodellen. ChatGPT Health von OpenAI fungiert als verbraucherorientierter Dienst mit einer Warteliste für Abonnenten von ChatGPT Free, Plus und Pro außerhalb des EWR, der Schweiz und des Vereinigten Königreichs. MedGemma 1.5 von Google wird als offenes Modell über das „Health AI Developer Foundations“-Programm veröffentlicht und steht zum Download über Hugging Face oder zur Bereitstellung über Vertex AI von Google Cloud zur Verfügung.
Anthropics „Claude for Healthcare“ lässt sich über „Claude for Enterprise“ in bestehende Unternehmensabläufe integrieren und richtet sich eher an institutionelle Käufer als an einzelne Verbraucher. Alle drei verfolgen eine einheitliche regulatorische Haltung.
OpenAI erklärt ausdrücklich, dass Health „nicht für Diagnose- oder Behandlungszwecke bestimmt ist“. Google positioniert MedGemma als „Ausgangspunkt für Entwickler, um ihre medizinischen Anwendungsfälle zu bewerten und anzupassen“. Anthropic betont, dass die Ergebnisse „nicht dazu bestimmt sind, direkt in klinische Diagnosen, Entscheidungen zum Patientenmanagement, Behandlungsempfehlungen oder andere direkte Anwendungen in der klinischen Praxis einfließen“.
Benchmark-Leistung vs. klinische Validierung
Die Benchmark-Ergebnisse für medizinische KI zeigten bei allen drei Versionen erhebliche Verbesserungen, obwohl die Kluft zwischen Testleistung und dem klinischen Einsatz in der Praxis nach wie vor groß ist. Google berichtet, dass MedGemma 1.5 auf dem MedAgentBench von Stanford, einem Benchmark für die Vervollständigung medizinischer Agenten, eine Genauigkeit von 92,3 % erreichte, verglichen mit 69,6 % bei der vorherigen Baseline Sonnet 3.5.
In internen Tests verbesserte sich das Modell um 14 Prozentpunkte bei der MRT-Krankheitsklassifizierung und um 3 Prozentpunkte bei CT-Befunden. Anthropics Claude Opus 4.5 erzielte 61,3 % bei den MedCalc-Tests zur medizinischen Berechnungsgenauigkeit mit aktivierter Python-Codeausführung und 92,3 % auf dem MedAgentBench.
Das Unternehmen gibt zudem Verbesserungen bei den „Ehrlichkeitsbewertungen“ in Bezug auf faktische Halluzinationen an, obwohl keine konkreten Kennzahlen genannt wurden.
OpenAI hat keine Benchmark-Vergleiche speziell für ChatGPT Health veröffentlicht, sondern weist darauf hin, dass „weltweit über 230 Millionen Menschen jede Woche gesundheits- und wellnessbezogene Fragen auf ChatGPT stellen“, basierend auf einer anonymisierten Analyse der bestehenden Nutzung.
Diese Benchmarks messen die Leistung anhand kuratierter Testdatensätze, nicht anhand klinischer Ergebnisse. Da medizinische Fehler lebensbedrohliche Folgen haben können, ist die Übertragung der Benchmark-Genauigkeit auf den tatsächlichen klinischen Nutzen weitaus komplexer als in anderen KI-Bereichen.
Regulatorischer Weg bleibt unklar
Die regulatorische Landschaft für diese medizinischen KI-Tools ist nach wie vor unklar. In den USA hängt die Aufsicht durch die FDA vom Verwendungszweck ab. Software, die „medizinisches Fachpersonal bei der Prävention, Diagnose oder Behandlung unterstützt oder Empfehlungen gibt“, muss möglicherweise als Medizinprodukt vor der Markteinführung geprüft werden. Keines der angekündigten Tools verfügt derzeit über eine FDA-Zulassung.
Haftungsfragen sind ebenfalls ungeklärt. Wenn Mike Reagin, CTO von Banner Health, erklärt, das System sei „von Anthropics Fokus auf KI-Sicherheit angezogen worden“, bezieht sich dies auf die Technologieauswahl, nicht auf rechtliche Haftungsrahmen.
Wenn sich ein Kliniker auf die Vorabgenehmigungsanalyse von Claude verlässt und einem Patienten durch eine verzögerte Behandlung Schaden entsteht, bietet die bestehende Rechtsprechung wenig Orientierung bei der Zuweisung der Verantwortung.
Die regulatorischen Ansätze variieren je nach Region erheblich. Während die FDA und die europäische Medizinprodukteverordnung etablierte Rahmenbedingungen für Software als Medizinprodukt bieten, haben viele Regulierungsbehörden im asiatisch-pazifischen Raum noch keine spezifischen Leitlinien für generative KI-Diagnosetools herausgegeben.
Diese Unklarheit wirkt sich auf die Einführungszeitpläne in Märkten aus, in denen Lücken in der Gesundheitsinfrastruktur die Implementierung andernfalls beschleunigen könnten, was zu Spannungen zwischen klinischem Bedarf und regulatorischer Vorsicht führt.
Administrative Arbeitsabläufe, keine klinischen Entscheidungen
Die tatsächlichen Einsatzbereiche sind nach wie vor eng gefasst. Louise Lind Skov, Director of Content Digitalisation bei Novo Nordisk, beschrieb den Einsatz von Claude für die „Automatisierung von Dokumenten und Inhalten in der pharmazeutischen Entwicklung“, wobei der Schwerpunkt auf Zulassungsanträgen und nicht auf der Patientendiagnose lag.
Die taiwanesische Nationale Krankenversicherungsbehörde setzte MedGemma ein, um Daten aus 30.000 pathologischen Befunden für politische Analysen zu extrahieren, nicht für Behandlungsentscheidungen.
Dieses Muster zeigt, dass sich die institutionelle Einführung auf administrative Arbeitsabläufe konzentriert, bei denen Fehler weniger unmittelbar gefährlich sind – wie Abrechnung, Dokumentation und Protokollentwürfe –, anstatt auf die direkte Unterstützung klinischer Entscheidungen, wo KI die Patientenergebnisse am dramatischsten beeinflussen könnte.
Die Fähigkeiten der medizinischen KI entwickeln sich schneller, als Institutionen die Komplexität in Bezug auf Regulierung, Haftung und Workflow-Integration bewältigen können. Die Technologie ist bereits vorhanden. Ausgefeilte Tools für medizinisches Schlussfolgern sind gegen eine monatliche Gebühr zugänglich.
Ob dies zu einer transformierten Gesundheitsversorgung führt, hängt von entscheidenden Fragen ab, die diese koordinierten Ankündigungen noch nicht beantwortet haben.
Siehe auch: AstraZeneca setzt auf interne KI, um die Krebsforschung zu beschleunigen
Möchten Sie mehr über KI und Big Data von Branchenführern erfahren? Besuchen Sie die AI & Big Data Expo in Amsterdam, Kalifornien und London. Die umfassende Veranstaltung ist Teil der TechEx und findet gemeinsam mit anderen führenden Technologieveranstaltungen statt. Klicken Sie hier für weitere Informationen.
AI News wird von TechForge Media bereitgestellt. Entdecken Sie hier weitere bevorstehende Veranstaltungen und Webinare zum Thema Unternehmenstechnologie.










 Hervorhebungen aus der IPO-Dokumentation von SpaceX: Ambitionen für die Ausweitung des Satelliten-Internet- und KI-Geschäfts
In ihrer S-1-Einreichung vor der geplanten IPO hat SpaceX kürzlich eine Reihe beeindruckender Geschäftszahlen veröffentlicht, die ihre starke Position im Bereich der Luftfahrtkommunikation und Künstlichen Intelligenz unterstreichen:Starlink-Abonnente
Hervorhebungen aus der IPO-Dokumentation von SpaceX: Ambitionen für die Ausweitung des Satelliten-Internet- und KI-Geschäfts
In ihrer S-1-Einreichung vor der geplanten IPO hat SpaceX kürzlich eine Reihe beeindruckender Geschäftszahlen veröffentlicht, die ihre starke Position im Bereich der Luftfahrtkommunikation und Künstlichen Intelligenz unterstreichen:Starlink-Abonnente
 Alibaba Tuhao M890 debütiert mit dreifacher Leistungsfähigkeit und markiert den Beginn der Ära der vollständig integrierten Agenten für das Chip-Cloud-Modell-Inferenz-Verfahren.
Am 20. Mai 2026 kündigte Alibaba Cloud auf dem Alibaba Cloud Summit die Fertigstellung eines umfassenden Upgrades des Technologiesystems an, das speziell für die Ära der Agenten entwickelt wurde. Diese Umstrukturierung prägte den gesamten Prozess – v
Alibaba Tuhao M890 debütiert mit dreifacher Leistungsfähigkeit und markiert den Beginn der Ära der vollständig integrierten Agenten für das Chip-Cloud-Modell-Inferenz-Verfahren.
Am 20. Mai 2026 kündigte Alibaba Cloud auf dem Alibaba Cloud Summit die Fertigstellung eines umfassenden Upgrades des Technologiesystems an, das speziell für die Ära der Agenten entwickelt wurde. Diese Umstrukturierung prägte den gesamten Prozess – v
 Pentium 4 Revival: Ein 20 Jahre alter Prozessor läuft das Meta Llama 3 Large Model
Kürzlich führte der YouTube-Technikkanal Fully Buffered ein beeindruckendes und anspruchsvolles Experiment durch: Es gelang, Metas neuestes großes Modell Llama 3.2 3B erfolgreich auf dem Pentium 4 641-Prozessor zu betreiben – einem Chip, der im Jahr
Pentium 4 Revival: Ein 20 Jahre alter Prozessor läuft das Meta Llama 3 Large Model
Kürzlich führte der YouTube-Technikkanal Fully Buffered ein beeindruckendes und anspruchsvolles Experiment durch: Es gelang, Metas neuestes großes Modell Llama 3.2 3B erfolgreich auf dem Pentium 4 641-Prozessor zu betreiben – einem Chip, der im Jahr

Entdecken Sie bei XIX.AI die besten KI-Videotools für Podcaster im Jahr 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, mit denen Sie Ihre Audioaufnahmen mühelos in ansprechende Talking-Head-Videos umwandeln können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schaffen Sie sich jetzt einen Vorsprung beim visuellen Storytelling.
10 Tools
xix.ai

Entdecken Sie die besten KI-Tools für Rollenspiele des Jahres 2026, mit denen Sie fesselnde Geschichten erschaffen können. Die von XIX.AI zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Assistenten, die kreatives Storytelling und emotionale Tiefe ermöglichen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Beginnen Sie noch heute Ihre ganz persönliche Reise.
10 Tools
xix.ai

Entdecken Sie die besten KI-Sprachtools für Spieleentwickler im Jahr 2026! Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, mit denen Sie bei der Sprachausgabe für RPGs und Visual Novels Zeit und Geld sparen. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings. Finden Sie noch heute Ihr perfektes Sprachtool!
10 Tools
xix.ai

Entdecken Sie die besten KI-basierten Wiederholungstools für das Jahr 2026, ausgewählt von XIX.AI. Unsere hochbewerteten, bahnbrechenden Tools helfen Medizinstudenten und Jurastudenten dabei, ihre Lernpläne so zu optimieren, dass das Gelernte optimal im Gedächtnis bleibt. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie jetzt Ihren Vorsprung beim Lernen.
10 Tools
xix.ai

Die besten KI-Plattformen für die Umwandlung von Text in Video im Jahr 2026: Erstklassige Tools für das Verfassen von Drehbüchern und visuelles Storytelling. Entdecken Sie leistungsstarke, bahnbrechende Lösungen, mit denen Sie Ihren Text in fesselnde Videos verwandeln können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand unserer wöchentlich aktualisierten Ranglisten und Praxistests. Finden Sie die perfekte Plattform, um Ihre Kreativität und Produktivität zu steigern. Entdecken Sie die sorgfältig zusammengestellte Auswahl bei XIX.AI.
10 Tools
xix.ai

2026 Neuestes: Entdecken Sie die besten AI-Multi-Agenten-Orchestratoren, um mithilfe natürlicher Sprache komplexe automatisierte Arbeitsabläufe zu gestalten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete, leistungsstarke Plattformen für reibungslose Aufgabenerstellung und intelligente Prozessverwaltung. Vergleichen Sie kostenlose und kostenpflichtige Optionen unter Berücksichtigung praktischer Erfahrungen. Nutzen Sie die wöchentlich aktualisierten Rankings von XIX.AI, um einen Vorsprung durch künstliche Intelligenz zu erlangen.
10 Tools
xix.ai

Wow, this AI health race is getting intense! Just saw the news about OpenAI, Google, and Anthropic all dropping medical AI tools almost at the same time. It's clearly a strategic move, not a coincidence. Makes you wonder who's really leading the pack and what it means for our future healthcare. Exciting but also a bit scary, right? 🤔













