
















 Lar
Lar
A NVIDIA torna o Polar Framework de código aberto para a evolução de agentes de IA sem barreiras por meio do aprendizado por reforço
Em 28 de maio, a equipe de pesquisa da NVIDIA tornou o Polar, uma estrutura de treinamento de aprendizagem por reforço, de código aberto. Sua principal inovação reside na integração perfeita de agentes de código convencionais já existentes — como Codex, Claude Code e Qwen Code — ao treinamento de aprendizagem por reforço GRPO (Otimização Generalizada de Políticas Relativas), sem exigir nenhuma alteração no código original.
I. Desafios do setor: a barreira para o aprendizado por reforço de agentes
À medida que os agentes de código evoluem de tarefas simples de uma única etapa para processos complexos e de longa duração — como modificações de código em nível de repositório ou interações com o sistema operacional —, os desenvolvedores dependem cada vez mais de estruturas de execução maduras (Harness). No entanto, integrar essas estruturas complexas à infraestrutura tradicional de aprendizado por reforço apresenta desafios significativos:
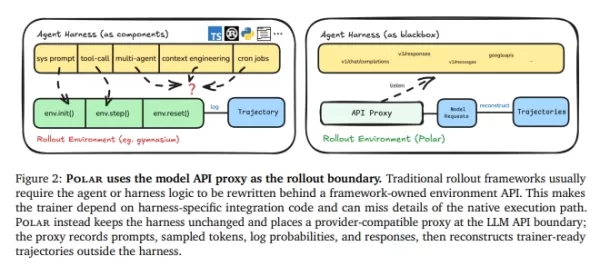
Alto custo de integração: os métodos tradicionais exigem a reescrita da lógica do código em interfaces de ambiente padrão, como env.init() e env.step(), um processo extremamente tedioso.
Perda de informações: durante a refatoração, detalhes críticos — como chamadas de ferramentas, contexto de diálogo de múltiplas rodadas ou lógica de colaboração entre subagentes — são frequentemente perdidos, impedindo que o modelo receba sinais de treinamento de alta qualidade.
II. Solução principal: usar o “limite” como ponto de entrada do treinamento
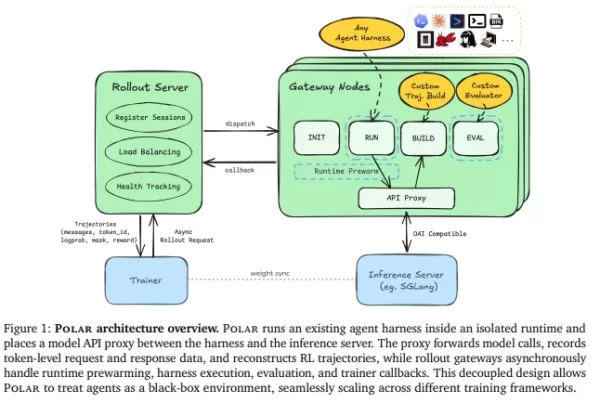
O Polar elimina a necessidade de reescrever a estrutura de execução. Em vez disso, ele trata o limite da API do modelo como o ponto de entrada do treinamento.
Processamento de caixa preta: O Polar coloca um proxy transparente (Gateway) entre a estrutura de execução de código e o servidor de inferência do modelo. Independentemente de o agente usar APIs da Anthropic, OpenAI ou Google, o Polar intercepta e encaminha as solicitações de forma integrada.
Reconstrução de rastreamento: durante o encaminhamento, o Polar registra dados-chave em tempo real — como prompts, tokens amostrados e probabilidades de log — e os reconstrói nos dados de “rastreamento” necessários ao treinador de aprendizado por reforço.
Arquitetura assíncrona eficiente: O sistema emprega um servidor de rollout para agendamento e persistência, enquanto os nós de gateway gerenciam o ciclo de vida e a reciclagem de recursos. Ao aproveitar um buffer pré-aquecido (buffer READY) e o processamento paralelo de tarefas, ele elimina efetivamente tarefas de cauda longa que poderiam bloquear o treinamento da GPU.
III. Salto de desempenho: transformando agentes de código
Dados experimentais mostram que o Polar, quando combinado com o treinamento GRPO, produz ganhos significativos de desempenho:
Teste de benchmark verificado pelo SWE-Bench: Usando o mesmo modelo base Qwen3.5-4B, o desempenho varia entre diferentes estruturas de código:
Estrutura Codex: a pontuação pass@1 salta de 3,8% para 26,4% — um aumento de 594,74%.
Estrutura de código Claude: de 29,8% para 34,6%.
Estrutura Pi: de 34,2% para 40,4%.
Eficiência extrema: Após a introdução da estratégia prefix_merging, o tempo de treinamento em tempo real é reduzido em cerca de 5,39 vezes em comparação com o modo tradicional por solicitação, e a utilização da GPU aumenta de 20,4% para 87,7%.
Comentário do setor
A abertura do código-fonte do Polar da NVIDIA basicamente constrói uma “rodovia” para que agentes de IA entrem no treinamento de aprendizado por reforço. Isso não apenas permite que pesquisadores treinem com eficiência usando enormes frameworks de código-fonte aberto, mas também reduz a barreira da computação em GPU por meio da otimização em nível de sistema.
Com a crescente popularidade do Polar, os desenvolvedores não precisam mais se preocupar com “como adaptar modelos às estruturas de treinamento”. No futuro, a evolução dos agentes de codificação de IA se tornará mais padronizada e eficiente. Isso marca uma mudança no treinamento de agentes de IA, passando do ajuste manual em laboratório para uma produção de engenharia sistemática em grande escala.
URL do artigo: https://arxiv.org/pdf/2605.24220
Artigo relacionado
 DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
Recomendações de tópicos especiais relacionados
Negócios
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
Recomendações de tópicos especiais relacionados
Negócios
 As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
 10 ferramentas
10 ferramentas
 xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

 Comentários (0)
Comentários (0)
Em 28 de maio, a equipe de pesquisa da NVIDIA tornou o Polar, uma estrutura de treinamento de aprendizagem por reforço, de código aberto. Sua principal inovação reside na integração perfeita de agentes de código convencionais já existentes — como Codex, Claude Code e Qwen Code — ao treinamento de aprendizagem por reforço GRPO (Otimização Generalizada de Políticas Relativas), sem exigir nenhuma alteração no código original.
I. Desafios do setor: a barreira para o aprendizado por reforço de agentes
À medida que os agentes de código evoluem de tarefas simples de uma única etapa para processos complexos e de longa duração — como modificações de código em nível de repositório ou interações com o sistema operacional —, os desenvolvedores dependem cada vez mais de estruturas de execução maduras (Harness). No entanto, integrar essas estruturas complexas à infraestrutura tradicional de aprendizado por reforço apresenta desafios significativos:
Alto custo de integração: os métodos tradicionais exigem a reescrita da lógica do código em interfaces de ambiente padrão, como env.init() e env.step(), um processo extremamente tedioso.
Perda de informações: durante a refatoração, detalhes críticos — como chamadas de ferramentas, contexto de diálogo de múltiplas rodadas ou lógica de colaboração entre subagentes — são frequentemente perdidos, impedindo que o modelo receba sinais de treinamento de alta qualidade.
II. Solução principal: usar o “limite” como ponto de entrada do treinamento
O Polar elimina a necessidade de reescrever a estrutura de execução. Em vez disso, ele trata o limite da API do modelo como o ponto de entrada do treinamento.
Processamento de caixa preta: O Polar coloca um proxy transparente (Gateway) entre a estrutura de execução de código e o servidor de inferência do modelo. Independentemente de o agente usar APIs da Anthropic, OpenAI ou Google, o Polar intercepta e encaminha as solicitações de forma integrada.
Reconstrução de rastreamento: durante o encaminhamento, o Polar registra dados-chave em tempo real — como prompts, tokens amostrados e probabilidades de log — e os reconstrói nos dados de “rastreamento” necessários ao treinador de aprendizado por reforço.
Arquitetura assíncrona eficiente: O sistema emprega um servidor de rollout para agendamento e persistência, enquanto os nós de gateway gerenciam o ciclo de vida e a reciclagem de recursos. Ao aproveitar um buffer pré-aquecido (buffer READY) e o processamento paralelo de tarefas, ele elimina efetivamente tarefas de cauda longa que poderiam bloquear o treinamento da GPU.
III. Salto de desempenho: transformando agentes de código
Dados experimentais mostram que o Polar, quando combinado com o treinamento GRPO, produz ganhos significativos de desempenho:
Teste de benchmark verificado pelo SWE-Bench: Usando o mesmo modelo base Qwen3.5-4B, o desempenho varia entre diferentes estruturas de código:
Estrutura Codex: a pontuação pass@1 salta de 3,8% para 26,4% — um aumento de 594,74%.
Estrutura de código Claude: de 29,8% para 34,6%.
Estrutura Pi: de 34,2% para 40,4%.
Eficiência extrema: Após a introdução da estratégia prefix_merging, o tempo de treinamento em tempo real é reduzido em cerca de 5,39 vezes em comparação com o modo tradicional por solicitação, e a utilização da GPU aumenta de 20,4% para 87,7%.
Comentário do setor
A abertura do código-fonte do Polar da NVIDIA basicamente constrói uma “rodovia” para que agentes de IA entrem no treinamento de aprendizado por reforço. Isso não apenas permite que pesquisadores treinem com eficiência usando enormes frameworks de código-fonte aberto, mas também reduz a barreira da computação em GPU por meio da otimização em nível de sistema.
Com a crescente popularidade do Polar, os desenvolvedores não precisam mais se preocupar com “como adaptar modelos às estruturas de treinamento”. No futuro, a evolução dos agentes de codificação de IA se tornará mais padronizada e eficiente. Isso marca uma mudança no treinamento de agentes de IA, passando do ajuste manual em laboratório para uma produção de engenharia sistemática em grande escala.
URL do artigo: https://arxiv.org/pdf/2605.24220










 DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
 O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
 A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai













