
















 Heim
Heim
NVIDIA veröffentlicht das „Polar“-Framework als Open Source – für die barrierefreie Entwicklung von KI-Agenten mittels bestärkendem Lernen
Am 28. Mai hat das NVIDIA-Forschungsteam „Polar“, ein Trainingsframework für verstärktes Lernen, als Open-Source-Projekt veröffentlicht. Die zentrale Innovation besteht darin, bestehende Mainstream-Code-Agenten – wie Codex, Claude Code und Qwen Code – nahtlos in das GRPO-Training (Generalized Relative Policy Optimization) für verstärktes Lernen zu integrieren, ohne dass Änderungen am ursprünglichen Code erforderlich sind.
I. Probleme der Branche: Die Hürde für das verstärkende Lernen von Agenten
Da sich Code-Agenten von einfachen Einzelschrittaufgaben zu komplexen, lang andauernden Prozessen entwickeln – wie beispielsweise Code-Änderungen auf Lagerebene oder Interaktionen mit dem Betriebssystem –, verlassen sich Entwickler zunehmend auf ausgereifte Ausführungsframeworks (Harness). Die Integration dieser komplexen Frameworks in die traditionelle Infrastruktur für verstärktes Lernen stellt jedoch erhebliche Herausforderungen dar:
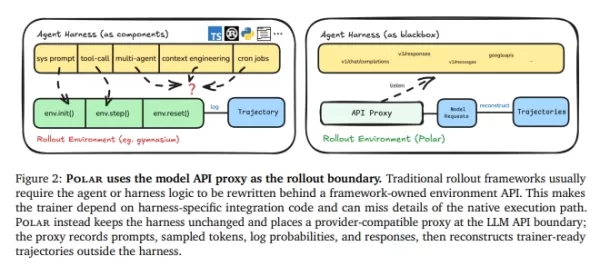
Hohe Integrationskosten: Herkömmliche Methoden erfordern das Umschreiben der Codelogik in Standardschnittstellen der Umgebung wie env.init() und env.step(), ein äußerst mühsamer Prozess.
Informationsverlust: Während der Refaktorisierung gehen oft kritische Details – wie Tool-Aufrufe, der Kontext mehrrundiger Dialoge oder die Logik der Zusammenarbeit zwischen Unteragenten – verloren, was verhindert, dass das Modell hochwertige Trainingssignale erhält.
II. Kernlösung: Nutzung der „Grenze“ als Einstiegspunkt für das Training
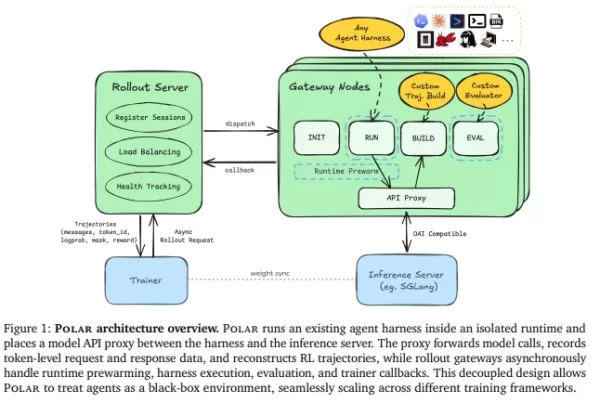
Polar macht das Umschreiben des Ausführungsframeworks überflüssig. Stattdessen behandelt es die Modell-API-Grenze als Einstiegspunkt für das Training.
Black-Box-Verarbeitung: Polar platziert einen transparenten Proxy (Gateway) zwischen dem Code-Ausführungsframework und dem Modell-Inferenzserver. Unabhängig davon, ob der Agent APIs von Anthropic, OpenAI oder Google verwendet, fängt Polar Anfragen nahtlos ab und leitet sie weiter.
Trace-Rekonstruktion: Während der Weiterleitung zeichnet Polar wichtige Echtzeitdaten – wie Prompts, abgetastete Tokens und Log-Wahrscheinlichkeiten – auf und rekonstruiert sie zu den „Trace“-Daten, die der Trainer für das verstärkende Lernen benötigt.
Effiziente asynchrone Architektur: Das System nutzt einen Rollout-Server für die Planung und Persistenz, während Gateway-Knoten den Lebenszyklus und die Wiederverwertung von Ressourcen verwalten. Durch die Nutzung eines vorgewärmten Puffers (READY-Puffer) und paralleler Aufgabenverarbeitung werden Long-Tail-Aufgaben, die das GPU-Training blockieren könnten, effektiv eliminiert.
III. Leistungssprung: Transformation von Code-Agenten
Experimentelle Daten zeigen, dass Polar in Kombination mit GRPO-Training erhebliche Leistungssteigerungen erzielt:
SWE-Bench-verifizierter Benchmark-Test: Bei Verwendung desselben Qwen3.5-4B-Basismodells variiert die Leistung je nach Code-Framework:
Codex-Framework: Der pass@1-Wert steigt von 3,8 % auf 26,4 % – ein Anstieg um 594,74 %.
Claude-Code-Framework: von 29,8 % auf 34,6 %.
Pi-Framework: von 34,2 % auf 40,4 %.
Extreme Effizienz: Nach Einführung der prefix_merging-Strategie verkürzt sich die Trainingszeit im Vergleich zum herkömmlichen Modus pro Anfrage um etwa das 5,39-Fache, und die GPU-Auslastung steigt von 20,4 % auf 87,7 %.
Kommentar aus der Branche
Die Open-Source-Veröffentlichung von NVIDIAs Polar schafft im Wesentlichen eine „Autobahn“ für KI-Agenten, um in das Training des verstärkenden Lernens einzusteigen. Sie ermöglicht es Forschern nicht nur, mithilfe umfangreicher Open-Source-Code-Frameworks effizient zu trainieren, sondern senkt auch die Hürde für GPU-Rechenleistung durch Optimierungen auf Systemebene.
Mit der wachsenden Popularität von Polar müssen sich Entwickler nicht mehr darum kümmern, „wie Modelle an Trainingsframeworks angepasst werden können“. In Zukunft wird die Entwicklung von KI-Codierungsagenten standardisierter und effizienter werden. Dies markiert einen Wandel im Training von KI-Agenten von manueller Feinabstimmung im Labor hin zu groß angelegter, systematischer technischer Produktion.
URL des Artikels: https://arxiv.org/pdf/2605.24220
Verwandter Artikel
 WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Empfehlungen zu verwandten Spezialthemen
Geschäft
WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
 10 Tools
10 Tools
 xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Am 28. Mai hat das NVIDIA-Forschungsteam „Polar“, ein Trainingsframework für verstärktes Lernen, als Open-Source-Projekt veröffentlicht. Die zentrale Innovation besteht darin, bestehende Mainstream-Code-Agenten – wie Codex, Claude Code und Qwen Code – nahtlos in das GRPO-Training (Generalized Relative Policy Optimization) für verstärktes Lernen zu integrieren, ohne dass Änderungen am ursprünglichen Code erforderlich sind.
I. Probleme der Branche: Die Hürde für das verstärkende Lernen von Agenten
Da sich Code-Agenten von einfachen Einzelschrittaufgaben zu komplexen, lang andauernden Prozessen entwickeln – wie beispielsweise Code-Änderungen auf Lagerebene oder Interaktionen mit dem Betriebssystem –, verlassen sich Entwickler zunehmend auf ausgereifte Ausführungsframeworks (Harness). Die Integration dieser komplexen Frameworks in die traditionelle Infrastruktur für verstärktes Lernen stellt jedoch erhebliche Herausforderungen dar:
Hohe Integrationskosten: Herkömmliche Methoden erfordern das Umschreiben der Codelogik in Standardschnittstellen der Umgebung wie env.init() und env.step(), ein äußerst mühsamer Prozess.
Informationsverlust: Während der Refaktorisierung gehen oft kritische Details – wie Tool-Aufrufe, der Kontext mehrrundiger Dialoge oder die Logik der Zusammenarbeit zwischen Unteragenten – verloren, was verhindert, dass das Modell hochwertige Trainingssignale erhält.
II. Kernlösung: Nutzung der „Grenze“ als Einstiegspunkt für das Training
Polar macht das Umschreiben des Ausführungsframeworks überflüssig. Stattdessen behandelt es die Modell-API-Grenze als Einstiegspunkt für das Training.
Black-Box-Verarbeitung: Polar platziert einen transparenten Proxy (Gateway) zwischen dem Code-Ausführungsframework und dem Modell-Inferenzserver. Unabhängig davon, ob der Agent APIs von Anthropic, OpenAI oder Google verwendet, fängt Polar Anfragen nahtlos ab und leitet sie weiter.
Trace-Rekonstruktion: Während der Weiterleitung zeichnet Polar wichtige Echtzeitdaten – wie Prompts, abgetastete Tokens und Log-Wahrscheinlichkeiten – auf und rekonstruiert sie zu den „Trace“-Daten, die der Trainer für das verstärkende Lernen benötigt.
Effiziente asynchrone Architektur: Das System nutzt einen Rollout-Server für die Planung und Persistenz, während Gateway-Knoten den Lebenszyklus und die Wiederverwertung von Ressourcen verwalten. Durch die Nutzung eines vorgewärmten Puffers (READY-Puffer) und paralleler Aufgabenverarbeitung werden Long-Tail-Aufgaben, die das GPU-Training blockieren könnten, effektiv eliminiert.
III. Leistungssprung: Transformation von Code-Agenten
Experimentelle Daten zeigen, dass Polar in Kombination mit GRPO-Training erhebliche Leistungssteigerungen erzielt:
SWE-Bench-verifizierter Benchmark-Test: Bei Verwendung desselben Qwen3.5-4B-Basismodells variiert die Leistung je nach Code-Framework:
Codex-Framework: Der pass@1-Wert steigt von 3,8 % auf 26,4 % – ein Anstieg um 594,74 %.
Claude-Code-Framework: von 29,8 % auf 34,6 %.
Pi-Framework: von 34,2 % auf 40,4 %.
Extreme Effizienz: Nach Einführung der prefix_merging-Strategie verkürzt sich die Trainingszeit im Vergleich zum herkömmlichen Modus pro Anfrage um etwa das 5,39-Fache, und die GPU-Auslastung steigt von 20,4 % auf 87,7 %.
Kommentar aus der Branche
Die Open-Source-Veröffentlichung von NVIDIAs Polar schafft im Wesentlichen eine „Autobahn“ für KI-Agenten, um in das Training des verstärkenden Lernens einzusteigen. Sie ermöglicht es Forschern nicht nur, mithilfe umfangreicher Open-Source-Code-Frameworks effizient zu trainieren, sondern senkt auch die Hürde für GPU-Rechenleistung durch Optimierungen auf Systemebene.
Mit der wachsenden Popularität von Polar müssen sich Entwickler nicht mehr darum kümmern, „wie Modelle an Trainingsframeworks angepasst werden können“. In Zukunft wird die Entwicklung von KI-Codierungsagenten standardisierter und effizienter werden. Dies markiert einen Wandel im Training von KI-Agenten von manueller Feinabstimmung im Labor hin zu groß angelegter, systematischer technischer Produktion.
URL des Artikels: https://arxiv.org/pdf/2605.24220










 WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
 Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
 DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai













