
















 Hogar
Hogar
NVIDIA abre el código fuente del marco Polar para la evolución de agentes de IA sin barreras mediante el aprendizaje por refuerzo
El 28 de mayo, el equipo de investigación de NVIDIA publicó en código abierto Polar, un marco de entrenamiento de aprendizaje por refuerzo. Su principal innovación radica en la integración perfecta de los principales agentes de código existentes —como Codex, Claude Code y Qwen Code— en el entrenamiento de aprendizaje por refuerzo GRPO (Optimización Generalizada de Políticas Relativas), sin necesidad de realizar ningún cambio en el código original.
I. Problemas del sector: la barrera para el aprendizaje por refuerzo de los agentes
A medida que los agentes de código evolucionan de tareas sencillas de un solo paso a procesos complejos y de larga duración —como modificaciones de código a nivel de almacén o interacciones con el sistema operativo—, los desarrolladores recurren cada vez más a marcos de ejecución maduros (Harness). Sin embargo, la integración de estos marcos complejos en la infraestructura tradicional de aprendizaje por refuerzo plantea importantes retos:
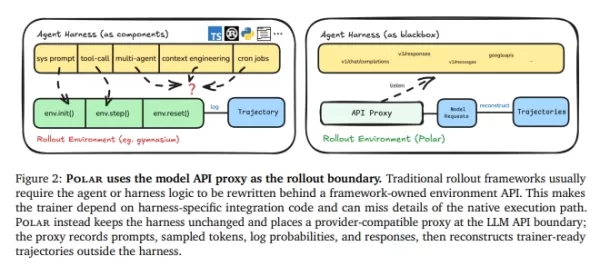
Alto coste de integración: Los métodos tradicionales requieren reescribir la lógica del código en interfaces de entorno estándar como env.init() y env.step(), un proceso extremadamente tedioso.
Pérdida de información: Durante la refactorización, a menudo se pierden detalles críticos —como llamadas a herramientas, el contexto de diálogos de varios turnos o la lógica de colaboración entre subagentes—, lo que impide que el modelo reciba señales de entrenamiento de alta calidad.
II. Solución principal: utilizar el «límite» como punto de entrada del entrenamiento
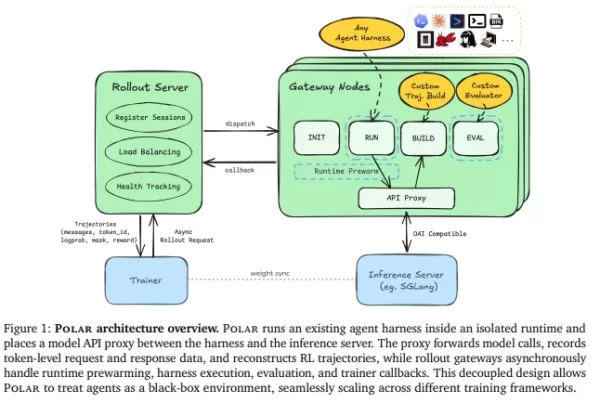
Polar elimina la necesidad de reescribir el marco de ejecución. En su lugar, trata el límite de la API del modelo como punto de entrada del entrenamiento.
Procesamiento de caja negra: Polar coloca un proxy transparente (Gateway) entre el marco de ejecución del código y el servidor de inferencia del modelo. Independientemente de si el agente utiliza API de Anthropic, OpenAI o Google, Polar intercepta y reenvía las solicitudes de forma fluida.
Reconstrucción de trazas: durante el reenvío, Polar registra datos clave en tiempo real —como indicaciones, tokens muestreados y probabilidades de registro— y los reconstruye en los datos de «traza» que necesita el entrenador de aprendizaje por refuerzo.
Arquitectura asíncrona eficiente: El sistema emplea un servidor de despliegue (Rollout Server) para la programación y la persistencia, mientras que los nodos de puerta de enlace (Gateway Nodes) gestionan el ciclo de vida y el reciclaje de recursos. Al aprovechar un búfer precalentado (búfer READY) y el procesamiento paralelo de tareas, elimina de forma efectiva las tareas de cola larga que podrían bloquear el entrenamiento de la GPU.
III. Salto de rendimiento: transformación de los agentes de código
Los datos experimentales muestran que Polar, cuando se combina con el entrenamiento GRPO, produce mejoras significativas en el rendimiento:
Prueba de referencia verificada por SWE-Bench: utilizando el mismo modelo base Qwen3.5-4B, el rendimiento varía entre los diferentes marcos de código:
Marco Codex: la puntuación pass@1 pasa del 3,8 % al 26,4 %, lo que supone un aumento del 594,74 %.
Marco de trabajo Claude Code: del 29,8 % al 34,6 %.
Marco Pi: del 34,2 % al 40,4 %.
Eficiencia extrema: tras introducir la estrategia prefix_merging, el tiempo de entrenamiento en tiempo real se reduce aproximadamente 5,39 veces en comparación con el modo tradicional por solicitud, y la utilización de la GPU aumenta del 20,4 % al 87,7 %.
Comentario del sector
La apertura del código fuente de Polar de NVIDIA construye, en esencia, una «autopista» para que los agentes de IA accedan al entrenamiento de aprendizaje por refuerzo. No solo permite a los investigadores entrenar de forma eficiente utilizando marcos de código abierto a gran escala, sino que también reduce la barrera de la computación en GPU mediante la optimización a nivel de sistema.
Con la creciente popularidad de Polar, los desarrolladores ya no tienen que preocuparse por «cómo adaptar los modelos a los marcos de entrenamiento». En el futuro, la evolución de los agentes de codificación de IA será más estandarizada y eficiente. Esto marca un cambio en el entrenamiento de agentes de IA, pasando del ajuste manual en laboratorio a una producción de ingeniería sistemática a gran escala.
URL del artículo: https://arxiv.org/pdf/2605.24220
Artículo relacionado
 DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
Recomendaciones de temas especiales relacionados
Negocio
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
Recomendaciones de temas especiales relacionados
Negocio
 Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
El 28 de mayo, el equipo de investigación de NVIDIA publicó en código abierto Polar, un marco de entrenamiento de aprendizaje por refuerzo. Su principal innovación radica en la integración perfecta de los principales agentes de código existentes —como Codex, Claude Code y Qwen Code— en el entrenamiento de aprendizaje por refuerzo GRPO (Optimización Generalizada de Políticas Relativas), sin necesidad de realizar ningún cambio en el código original.
I. Problemas del sector: la barrera para el aprendizaje por refuerzo de los agentes
A medida que los agentes de código evolucionan de tareas sencillas de un solo paso a procesos complejos y de larga duración —como modificaciones de código a nivel de almacén o interacciones con el sistema operativo—, los desarrolladores recurren cada vez más a marcos de ejecución maduros (Harness). Sin embargo, la integración de estos marcos complejos en la infraestructura tradicional de aprendizaje por refuerzo plantea importantes retos:
Alto coste de integración: Los métodos tradicionales requieren reescribir la lógica del código en interfaces de entorno estándar como env.init() y env.step(), un proceso extremadamente tedioso.
Pérdida de información: Durante la refactorización, a menudo se pierden detalles críticos —como llamadas a herramientas, el contexto de diálogos de varios turnos o la lógica de colaboración entre subagentes—, lo que impide que el modelo reciba señales de entrenamiento de alta calidad.
II. Solución principal: utilizar el «límite» como punto de entrada del entrenamiento
Polar elimina la necesidad de reescribir el marco de ejecución. En su lugar, trata el límite de la API del modelo como punto de entrada del entrenamiento.
Procesamiento de caja negra: Polar coloca un proxy transparente (Gateway) entre el marco de ejecución del código y el servidor de inferencia del modelo. Independientemente de si el agente utiliza API de Anthropic, OpenAI o Google, Polar intercepta y reenvía las solicitudes de forma fluida.
Reconstrucción de trazas: durante el reenvío, Polar registra datos clave en tiempo real —como indicaciones, tokens muestreados y probabilidades de registro— y los reconstruye en los datos de «traza» que necesita el entrenador de aprendizaje por refuerzo.
Arquitectura asíncrona eficiente: El sistema emplea un servidor de despliegue (Rollout Server) para la programación y la persistencia, mientras que los nodos de puerta de enlace (Gateway Nodes) gestionan el ciclo de vida y el reciclaje de recursos. Al aprovechar un búfer precalentado (búfer READY) y el procesamiento paralelo de tareas, elimina de forma efectiva las tareas de cola larga que podrían bloquear el entrenamiento de la GPU.
III. Salto de rendimiento: transformación de los agentes de código
Los datos experimentales muestran que Polar, cuando se combina con el entrenamiento GRPO, produce mejoras significativas en el rendimiento:
Prueba de referencia verificada por SWE-Bench: utilizando el mismo modelo base Qwen3.5-4B, el rendimiento varía entre los diferentes marcos de código:
Marco Codex: la puntuación pass@1 pasa del 3,8 % al 26,4 %, lo que supone un aumento del 594,74 %.
Marco de trabajo Claude Code: del 29,8 % al 34,6 %.
Marco Pi: del 34,2 % al 40,4 %.
Eficiencia extrema: tras introducir la estrategia prefix_merging, el tiempo de entrenamiento en tiempo real se reduce aproximadamente 5,39 veces en comparación con el modo tradicional por solicitud, y la utilización de la GPU aumenta del 20,4 % al 87,7 %.
Comentario del sector
La apertura del código fuente de Polar de NVIDIA construye, en esencia, una «autopista» para que los agentes de IA accedan al entrenamiento de aprendizaje por refuerzo. No solo permite a los investigadores entrenar de forma eficiente utilizando marcos de código abierto a gran escala, sino que también reduce la barrera de la computación en GPU mediante la optimización a nivel de sistema.
Con la creciente popularidad de Polar, los desarrolladores ya no tienen que preocuparse por «cómo adaptar los modelos a los marcos de entrenamiento». En el futuro, la evolución de los agentes de codificación de IA será más estandarizada y eficiente. Esto marca un cambio en el entrenamiento de agentes de IA, pasando del ajuste manual en laboratorio a una producción de ingeniería sistemática a gran escala.
URL del artículo: https://arxiv.org/pdf/2605.24220










 DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
 Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
 OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai













