
















 Maison
Maison
NVIDIA open source le framework Polar pour l'évolution sans barrières des agents d'IA par apprentissage par renforcement
Le 28 mai, l'équipe de recherche de NVIDIA a mis en open source Polar, un cadre d'entraînement à l'apprentissage par renforcement. Son innovation principale réside dans l'intégration transparente d'agents de code courants existants — tels que Codex, Claude Code et Qwen Code — dans l'entraînement à l'apprentissage par renforcement GRPO (Generalized Relative Policy Optimization), sans nécessiter aucune modification du code d'origine.
I. Les difficultés du secteur : l'obstacle à l'apprentissage par renforcement des agents
À mesure que les agents de code évoluent de simples tâches en une seule étape vers des processus complexes et de longue durée — tels que les modifications de code au niveau de l'entrepôt ou les interactions avec le système d'exploitation —, les développeurs s'appuient de plus en plus sur des frameworks d'exécution matures (Harness). Cependant, l'intégration de ces frameworks complexes dans l'infrastructure traditionnelle d'apprentissage par renforcement présente des défis importants :
Coût d'intégration élevé : les méthodes traditionnelles nécessitent de réécrire la logique du code dans des interfaces d'environnement standard telles que env.init() et env.step(), un processus extrêmement fastidieux.
Perte d'informations : lors de la refactorisation, des détails critiques — tels que les appels d'outils, le contexte des dialogues à plusieurs tours ou la logique de collaboration entre sous-agents — sont souvent perdus, empêchant le modèle de recevoir des signaux d'entraînement de haute qualité.
II. Solution principale : utiliser la « frontière » comme point d'entrée de l'entraînement
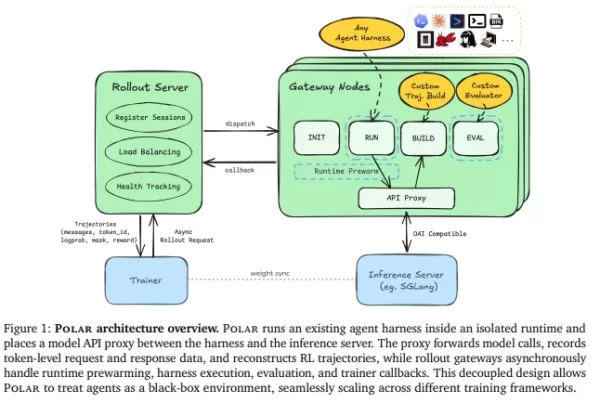
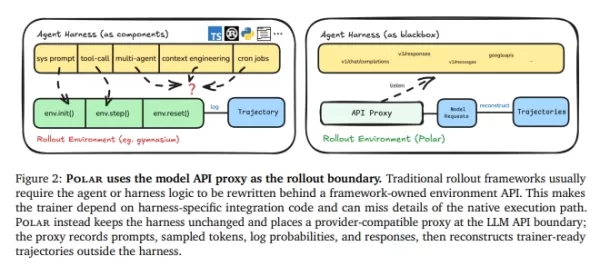
Polar élimine la nécessité de réécrire le cadre d'exécution. Au lieu de cela, il traite la limite de l'API du modèle comme point d'entrée de l'entraînement.
Traitement en boîte noire : Polar place un proxy transparent (Gateway) entre le cadre d'exécution du code et le serveur d'inférence du modèle. Que l'agent utilise les API d'Anthropic, d'OpenAI ou de Google, Polar intercepte et transmet les requêtes de manière transparente.
Reconstruction de traces : lors du transfert, Polar enregistre en temps réel des données clés — telles que les invites, les tokens échantillonnés et les probabilités de journalisation — et les reconstitue en données de « trace » nécessaires au formateur d'apprentissage par renforcement.
Architecture asynchrone efficace : le système utilise un serveur de déploiement (Rollout Server) pour la planification et la persistance, tandis que les nœuds de passerelle (Gateway Nodes) gèrent le cycle de vie et le recyclage des ressources. En tirant parti d’un tampon préchauffé (tampon READY) et du traitement parallèle des tâches, il élimine efficacement les tâches à longue traîne susceptibles de bloquer l’entraînement du GPU.
III. Bond de performance : transformation des agents de code
Les données expérimentales montrent que Polar, lorsqu'il est combiné à l'entraînement GRPO, permet des gains de performances significatifs :
Test de benchmark vérifié par SWE-Bench : en utilisant le même modèle de base Qwen3.5-4B, les performances varient selon les différents frameworks de code :
Cadre Codex : le score pass@1 passe de 3,8 % à 26,4 %, soit une hausse de 594,74 %.
Cadre Claude Code : de 29,8 % à 34,6 %.
Framework Pi : de 34,2 % à 40,4 %.
Efficacité extrême : après l'introduction de la stratégie prefix_merging, la durée d'entraînement en temps réel est réduite d'environ 5,39 fois par rapport au mode traditionnel par requête, et l'utilisation du GPU passe de 20,4 % à 87,7 %.
Commentaire du secteur
L'ouverture du code source de Polar de NVIDIA revient essentiellement à construire une « autoroute » permettant aux agents IA d'accéder à l'apprentissage par renforcement. Cela permet non seulement aux chercheurs de s'entraîner efficacement à l'aide de frameworks open source massifs, mais abaisse également la barrière du calcul GPU grâce à une optimisation au niveau du système.
Avec la popularité croissante de Polar, les développeurs n’ont plus à se soucier de « comment adapter les modèles aux frameworks d’entraînement ». À l’avenir, l’évolution des agents de codage IA deviendra plus standardisée et plus efficace. Cela marque un tournant dans l’entraînement des agents IA, qui passe d’un réglage manuel en laboratoire à une production technique systématique à grande échelle.
URL de l'article : https://arxiv.org/pdf/2605.24220
Article connexe
 DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla
OpenAI modifie discrètement ses statuts pour compliquer le licenciement d'Altman
À la suite de l'incident de 2023, qui s'apparentait à un coup d'État, OpenAI a encore renforcé les protections dont bénéficie son PDG, Sam Altman, en mettant à jour ses statuts. Des doc
Recommandations de sujets spéciaux liés
Entreprise
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla
OpenAI modifie discrètement ses statuts pour compliquer le licenciement d'Altman
À la suite de l'incident de 2023, qui s'apparentait à un coup d'État, OpenAI a encore renforcé les protections dont bénéficie son PDG, Sam Altman, en mettant à jour ses statuts. Des doc
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
 10 outils
10 outils
 xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Le 28 mai, l'équipe de recherche de NVIDIA a mis en open source Polar, un cadre d'entraînement à l'apprentissage par renforcement. Son innovation principale réside dans l'intégration transparente d'agents de code courants existants — tels que Codex, Claude Code et Qwen Code — dans l'entraînement à l'apprentissage par renforcement GRPO (Generalized Relative Policy Optimization), sans nécessiter aucune modification du code d'origine.
I. Les difficultés du secteur : l'obstacle à l'apprentissage par renforcement des agents
À mesure que les agents de code évoluent de simples tâches en une seule étape vers des processus complexes et de longue durée — tels que les modifications de code au niveau de l'entrepôt ou les interactions avec le système d'exploitation —, les développeurs s'appuient de plus en plus sur des frameworks d'exécution matures (Harness). Cependant, l'intégration de ces frameworks complexes dans l'infrastructure traditionnelle d'apprentissage par renforcement présente des défis importants :
Coût d'intégration élevé : les méthodes traditionnelles nécessitent de réécrire la logique du code dans des interfaces d'environnement standard telles que env.init() et env.step(), un processus extrêmement fastidieux.
Perte d'informations : lors de la refactorisation, des détails critiques — tels que les appels d'outils, le contexte des dialogues à plusieurs tours ou la logique de collaboration entre sous-agents — sont souvent perdus, empêchant le modèle de recevoir des signaux d'entraînement de haute qualité.
II. Solution principale : utiliser la « frontière » comme point d'entrée de l'entraînement
Polar élimine la nécessité de réécrire le cadre d'exécution. Au lieu de cela, il traite la limite de l'API du modèle comme point d'entrée de l'entraînement.
Traitement en boîte noire : Polar place un proxy transparent (Gateway) entre le cadre d'exécution du code et le serveur d'inférence du modèle. Que l'agent utilise les API d'Anthropic, d'OpenAI ou de Google, Polar intercepte et transmet les requêtes de manière transparente.
Reconstruction de traces : lors du transfert, Polar enregistre en temps réel des données clés — telles que les invites, les tokens échantillonnés et les probabilités de journalisation — et les reconstitue en données de « trace » nécessaires au formateur d'apprentissage par renforcement.
Architecture asynchrone efficace : le système utilise un serveur de déploiement (Rollout Server) pour la planification et la persistance, tandis que les nœuds de passerelle (Gateway Nodes) gèrent le cycle de vie et le recyclage des ressources. En tirant parti d’un tampon préchauffé (tampon READY) et du traitement parallèle des tâches, il élimine efficacement les tâches à longue traîne susceptibles de bloquer l’entraînement du GPU.
III. Bond de performance : transformation des agents de code
Les données expérimentales montrent que Polar, lorsqu'il est combiné à l'entraînement GRPO, permet des gains de performances significatifs :
Test de benchmark vérifié par SWE-Bench : en utilisant le même modèle de base Qwen3.5-4B, les performances varient selon les différents frameworks de code :
Cadre Codex : le score pass@1 passe de 3,8 % à 26,4 %, soit une hausse de 594,74 %.
Cadre Claude Code : de 29,8 % à 34,6 %.
Framework Pi : de 34,2 % à 40,4 %.
Efficacité extrême : après l'introduction de la stratégie prefix_merging, la durée d'entraînement en temps réel est réduite d'environ 5,39 fois par rapport au mode traditionnel par requête, et l'utilisation du GPU passe de 20,4 % à 87,7 %.
Commentaire du secteur
L'ouverture du code source de Polar de NVIDIA revient essentiellement à construire une « autoroute » permettant aux agents IA d'accéder à l'apprentissage par renforcement. Cela permet non seulement aux chercheurs de s'entraîner efficacement à l'aide de frameworks open source massifs, mais abaisse également la barrière du calcul GPU grâce à une optimisation au niveau du système.
Avec la popularité croissante de Polar, les développeurs n’ont plus à se soucier de « comment adapter les modèles aux frameworks d’entraînement ». À l’avenir, l’évolution des agents de codage IA deviendra plus standardisée et plus efficace. Cela marque un tournant dans l’entraînement des agents IA, qui passe d’un réglage manuel en laboratoire à une production technique systématique à grande échelle.
URL de l'article : https://arxiv.org/pdf/2605.24220










 DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
 Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla
Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla
 OpenAI modifie discrètement ses statuts pour compliquer le licenciement d'Altman
À la suite de l'incident de 2023, qui s'apparentait à un coup d'État, OpenAI a encore renforcé les protections dont bénéficie son PDG, Sam Altman, en mettant à jour ses statuts. Des doc
OpenAI modifie discrètement ses statuts pour compliquer le licenciement d'Altman
À la suite de l'incident de 2023, qui s'apparentait à un coup d'État, OpenAI a encore renforcé les protections dont bénéficie son PDG, Sam Altman, en mettant à jour ses statuts. Des doc

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai













