
















 Lar
LarA expansão da IA agênica exige sistemas de memória avançados
A IA agênica marca uma mudança significativa dos simples chatbots para o gerenciamento de fluxos de trabalho complexos, e sua expansão exige uma nova abordagem à arquitetura de memória.
À medida que os modelos básicos crescem para trilhões de parâmetros e as janelas de contexto se expandem para milhões de tokens, o custo computacional de reter o histórico está ultrapassando nossa capacidade de processá-lo de forma eficaz.
As organizações que implementam esses sistemas agora enfrentam um gargalo em que o imenso volume de “memória de longo prazo” (tecnicamente o cache Key-Value (KV)) excede as capacidades dos projetos de hardware atuais.
A infraestrutura existente apresenta uma escolha limitada: armazenar o contexto de inferência na escassa memória GPU de alta largura de banda (HBM) ou movê-lo para um armazenamento mais lento e de uso geral. A primeira opção se torna muito cara para contextos grandes, enquanto a segunda introduz latência que torna impraticáveis as interações agênicas em tempo real.
Para preencher essa lacuna crescente que impede o dimensionamento da IA agênica, a NVIDIA lançou a plataforma Inference Context Memory Storage (ICMS) dentro de sua arquitetura Rubin, introduzindo um novo nível de armazenamento criado especificamente para as demandas temporárias e de alta velocidade da memória de IA.
“A IA está transformando toda a pilha de computação — e agora, o armazenamento”, afirmou Huang. “A IA evoluiu além dos chatbots de resposta única para colaboradores inteligentes que compreendem o mundo físico, raciocinam por longos períodos, permanecem baseados em fatos, utilizam ferramentas para tarefas práticas e mantêm a memória de curto e longo prazo.”
A questão operacional central decorre de como os modelos baseados em transformadores funcionam. Para evitar o recálculo de toda uma conversa para cada nova palavra gerada, os modelos salvam os estados anteriores no cache KV. Em fluxos de trabalho agênicos, esse cache serve como memória persistente entre ferramentas e sessões, expandindo-se em proporção direta ao comprimento da sequência.
Isso cria uma categoria de dados única. Ao contrário de registros financeiros ou logs de clientes, o cache KV é um dado derivado; ele é crucial para o desempenho imediato, mas não precisa das garantias de durabilidade robustas dos sistemas de arquivos corporativos. Os sistemas de armazenamento de uso geral, executados em CPUs padrão, consomem energia no gerenciamento e na replicação de metadados, dos quais as cargas de trabalho de agentes não se beneficiam.
A hierarquia existente, que vai do GPU HBM (G1) ao armazenamento compartilhado (G4), está se mostrando cada vez mais ineficiente:
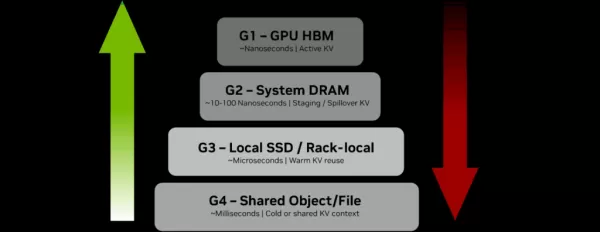
(Crédito: NVIDIA) À medida que os dados de contexto são transferidos da GPU (G1) para a RAM do sistema (G2) e, finalmente, para o armazenamento compartilhado (G4), a eficiência diminui significativamente. A transferência do contexto ativo para o nível G4 introduz atrasos na ordem de milissegundos e aumenta o custo de energia por token, deixando GPUs caras ociosas enquanto aguardam os dados.
Para as empresas, isso resulta em um custo total de propriedade (TCO) mais alto, em que a energia é consumida pela sobrecarga da infraestrutura, em vez de tarefas de raciocínio ativas.
Um novo nível de memória para a fábrica de IA
A solução do setor envolve adicionar uma camada personalizada a essa hierarquia. A plataforma ICMS cria um nível “G3.5” — uma camada de armazenamento flash conectada por Ethernet projetada especificamente para inferência em grande escala.
Esse método integra o armazenamento diretamente ao pod de computação. Ao aproveitar o processador de dados NVIDIA BlueField-4, a plataforma transfere o gerenciamento desses dados de contexto para fora da CPU host. O sistema oferece petabytes de capacidade compartilhada por pod, aprimorando o dimensionamento da IA agênica ao permitir que os agentes armazenem grandes quantidades de histórico sem consumir HBM caro.
A vantagem operacional é mensurável tanto em termos de rendimento quanto de uso de energia. Ao armazenar o contexto relevante nessa camada intermediária — que é mais rápida que o armazenamento padrão, mas mais acessível que o HBM —, o sistema pode “pré-carregar” a memória de volta para a GPU com antecedência. Isso reduz o tempo ocioso do decodificador da GPU, permitindo até 5 vezes mais tokens por segundo (TPS) em cargas de trabalho de contexto longo.
Do ponto de vista energético, os benefícios são igualmente significativos. Como a arquitetura elimina a sobrecarga dos protocolos de armazenamento de uso geral, ela alcança uma eficiência energética 5 vezes melhor do que as abordagens convencionais.
Integrando o plano de dados
A implantação dessa arquitetura requer uma mudança na forma como as equipes de TI percebem as redes de armazenamento. A plataforma ICMS depende da NVIDIA Spectrum-X Ethernet para fornecer a conectividade de alta largura de banda e baixo jitter necessária para tratar o armazenamento flash quase como memória local.
Para as equipes de infraestrutura empresarial, o principal ponto de integração é a camada de orquestração. Estruturas como NVIDIA Dynamo e Inference Transfer Library (NIXL) lidam com a movimentação de blocos KV entre diferentes camadas.
Essas ferramentas trabalham com a camada de armazenamento para garantir que o contexto correto seja carregado na memória da GPU (G1) ou na memória do host (G2) precisamente quando o modelo de IA precisar. A estrutura NVIDIA DOCA oferece suporte adicional a isso, fornecendo uma camada de comunicação KV que trata o cache de contexto como um recurso primário.
Os principais fornecedores de armazenamento já estão adotando essa arquitetura. Empresas como AIC, Cloudian, DDN, Dell Technologies, HPE, Hitachi Vantara, IBM, Nutanix, Pure Storage, Supermicro, VAST Data e WEKA estão desenvolvendo plataformas com BlueField-4. Essas soluções devem estar disponíveis no segundo semestre deste ano.
Redefinindo a infraestrutura para dimensionar a IA agênica
A adoção de uma camada de memória de contexto dedicada influencia o planejamento de capacidade e o projeto do data center.
- Reclassificação de dados: os CIOs devem reconhecer o cache KV como um tipo de dados distinto. Ele é “temporário, mas sensível à latência”, diferente dos dados de conformidade “duráveis e frios”. A camada G3.5 gerencia o primeiro, permitindo que o armazenamento G4 durável se concentre em logs e artefatos de longo prazo.
- Maturidade da orquestração: o sucesso depende de um software capaz de alocar cargas de trabalho de forma inteligente. O sistema usa orquestração sensível à topologia (via NVIDIA Grove) para posicionar as tarefas próximas ao seu contexto em cache, reduzindo a movimentação de dados pela rede.
- Densidade de energia: ao reunir mais capacidade utilizável no mesmo espaço de rack, as organizações podem prolongar a vida útil de suas instalações atuais. No entanto, isso aumenta a densidade de computação por metro quadrado, exigindo um planejamento cuidadoso para refrigeração e distribuição de energia.
A mudança para a IA agênica requer um redesenho físico do data center. A prática comum de separar completamente a computação do armazenamento lento e persistente é inadequada para os requisitos de recuperação em tempo real de agentes com memórias extensas.
Ao introduzir uma camada de contexto especializada, as empresas podem separar o crescimento da memória do modelo do custo da GPU HBM. Essa arquitetura de IA agênica permite que vários agentes compartilhem um pool de memória grande e de baixo consumo de energia, reduzindo o custo do tratamento de consultas complexas e aprimorando o dimensionamento ao oferecer suporte ao raciocínio de alto rendimento.
À medida que as organizações se preparam para sua próxima rodada de investimentos em infraestrutura, avaliar a eficiência da hierarquia de memória será tão crítico quanto escolher a própria GPU.
Veja também: Guerras dos chips de IA em 2025: o que os líderes empresariais aprenderam sobre a realidade da cadeia de suprimentos

Quer saber mais sobre IA e big data com os líderes do setor? Confira a AI & Big Data Expo, que acontecerá em Amsterdã, Califórnia e Londres. O evento abrangente faz parte da TechEx e é realizado em conjunto com outros eventos de tecnologia importantes. Clique aqui para obter mais informações.
O AI News é desenvolvido pela TechForge Media. Explore outros eventos e webinars de tecnologia empresarial que estão por vir aqui.
Artigo relacionado
 A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
Recomendações de tópicos especiais relacionados
Negócios
A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
Recomendações de tópicos especiais relacionados
Negócios
 As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
 10 ferramentas
10 ferramentas
 xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

 Comentários (0)
Comentários (0)
A IA agênica marca uma mudança significativa dos simples chatbots para o gerenciamento de fluxos de trabalho complexos, e sua expansão exige uma nova abordagem à arquitetura de memória.
À medida que os modelos básicos crescem para trilhões de parâmetros e as janelas de contexto se expandem para milhões de tokens, o custo computacional de reter o histórico está ultrapassando nossa capacidade de processá-lo de forma eficaz.
As organizações que implementam esses sistemas agora enfrentam um gargalo em que o imenso volume de “memória de longo prazo” (tecnicamente o cache Key-Value (KV)) excede as capacidades dos projetos de hardware atuais.
A infraestrutura existente apresenta uma escolha limitada: armazenar o contexto de inferência na escassa memória GPU de alta largura de banda (HBM) ou movê-lo para um armazenamento mais lento e de uso geral. A primeira opção se torna muito cara para contextos grandes, enquanto a segunda introduz latência que torna impraticáveis as interações agênicas em tempo real.
Para preencher essa lacuna crescente que impede o dimensionamento da IA agênica, a NVIDIA lançou a plataforma Inference Context Memory Storage (ICMS) dentro de sua arquitetura Rubin, introduzindo um novo nível de armazenamento criado especificamente para as demandas temporárias e de alta velocidade da memória de IA.
“A IA está transformando toda a pilha de computação — e agora, o armazenamento”, afirmou Huang. “A IA evoluiu além dos chatbots de resposta única para colaboradores inteligentes que compreendem o mundo físico, raciocinam por longos períodos, permanecem baseados em fatos, utilizam ferramentas para tarefas práticas e mantêm a memória de curto e longo prazo.”
A questão operacional central decorre de como os modelos baseados em transformadores funcionam. Para evitar o recálculo de toda uma conversa para cada nova palavra gerada, os modelos salvam os estados anteriores no cache KV. Em fluxos de trabalho agênicos, esse cache serve como memória persistente entre ferramentas e sessões, expandindo-se em proporção direta ao comprimento da sequência.
Isso cria uma categoria de dados única. Ao contrário de registros financeiros ou logs de clientes, o cache KV é um dado derivado; ele é crucial para o desempenho imediato, mas não precisa das garantias de durabilidade robustas dos sistemas de arquivos corporativos. Os sistemas de armazenamento de uso geral, executados em CPUs padrão, consomem energia no gerenciamento e na replicação de metadados, dos quais as cargas de trabalho de agentes não se beneficiam.
A hierarquia existente, que vai do GPU HBM (G1) ao armazenamento compartilhado (G4), está se mostrando cada vez mais ineficiente:
À medida que os dados de contexto são transferidos da GPU (G1) para a RAM do sistema (G2) e, finalmente, para o armazenamento compartilhado (G4), a eficiência diminui significativamente. A transferência do contexto ativo para o nível G4 introduz atrasos na ordem de milissegundos e aumenta o custo de energia por token, deixando GPUs caras ociosas enquanto aguardam os dados.
Para as empresas, isso resulta em um custo total de propriedade (TCO) mais alto, em que a energia é consumida pela sobrecarga da infraestrutura, em vez de tarefas de raciocínio ativas.
Um novo nível de memória para a fábrica de IA
A solução do setor envolve adicionar uma camada personalizada a essa hierarquia. A plataforma ICMS cria um nível “G3.5” — uma camada de armazenamento flash conectada por Ethernet projetada especificamente para inferência em grande escala.
Esse método integra o armazenamento diretamente ao pod de computação. Ao aproveitar o processador de dados NVIDIA BlueField-4, a plataforma transfere o gerenciamento desses dados de contexto para fora da CPU host. O sistema oferece petabytes de capacidade compartilhada por pod, aprimorando o dimensionamento da IA agênica ao permitir que os agentes armazenem grandes quantidades de histórico sem consumir HBM caro.
A vantagem operacional é mensurável tanto em termos de rendimento quanto de uso de energia. Ao armazenar o contexto relevante nessa camada intermediária — que é mais rápida que o armazenamento padrão, mas mais acessível que o HBM —, o sistema pode “pré-carregar” a memória de volta para a GPU com antecedência. Isso reduz o tempo ocioso do decodificador da GPU, permitindo até 5 vezes mais tokens por segundo (TPS) em cargas de trabalho de contexto longo.
Do ponto de vista energético, os benefícios são igualmente significativos. Como a arquitetura elimina a sobrecarga dos protocolos de armazenamento de uso geral, ela alcança uma eficiência energética 5 vezes melhor do que as abordagens convencionais.
Integrando o plano de dados
A implantação dessa arquitetura requer uma mudança na forma como as equipes de TI percebem as redes de armazenamento. A plataforma ICMS depende da NVIDIA Spectrum-X Ethernet para fornecer a conectividade de alta largura de banda e baixo jitter necessária para tratar o armazenamento flash quase como memória local.
Para as equipes de infraestrutura empresarial, o principal ponto de integração é a camada de orquestração. Estruturas como NVIDIA Dynamo e Inference Transfer Library (NIXL) lidam com a movimentação de blocos KV entre diferentes camadas.
Essas ferramentas trabalham com a camada de armazenamento para garantir que o contexto correto seja carregado na memória da GPU (G1) ou na memória do host (G2) precisamente quando o modelo de IA precisar. A estrutura NVIDIA DOCA oferece suporte adicional a isso, fornecendo uma camada de comunicação KV que trata o cache de contexto como um recurso primário.
Os principais fornecedores de armazenamento já estão adotando essa arquitetura. Empresas como AIC, Cloudian, DDN, Dell Technologies, HPE, Hitachi Vantara, IBM, Nutanix, Pure Storage, Supermicro, VAST Data e WEKA estão desenvolvendo plataformas com BlueField-4. Essas soluções devem estar disponíveis no segundo semestre deste ano.
Redefinindo a infraestrutura para dimensionar a IA agênica
A adoção de uma camada de memória de contexto dedicada influencia o planejamento de capacidade e o projeto do data center.
- Reclassificação de dados: os CIOs devem reconhecer o cache KV como um tipo de dados distinto. Ele é “temporário, mas sensível à latência”, diferente dos dados de conformidade “duráveis e frios”. A camada G3.5 gerencia o primeiro, permitindo que o armazenamento G4 durável se concentre em logs e artefatos de longo prazo.
- Maturidade da orquestração: o sucesso depende de um software capaz de alocar cargas de trabalho de forma inteligente. O sistema usa orquestração sensível à topologia (via NVIDIA Grove) para posicionar as tarefas próximas ao seu contexto em cache, reduzindo a movimentação de dados pela rede.
- Densidade de energia: ao reunir mais capacidade utilizável no mesmo espaço de rack, as organizações podem prolongar a vida útil de suas instalações atuais. No entanto, isso aumenta a densidade de computação por metro quadrado, exigindo um planejamento cuidadoso para refrigeração e distribuição de energia.
A mudança para a IA agênica requer um redesenho físico do data center. A prática comum de separar completamente a computação do armazenamento lento e persistente é inadequada para os requisitos de recuperação em tempo real de agentes com memórias extensas.
Ao introduzir uma camada de contexto especializada, as empresas podem separar o crescimento da memória do modelo do custo da GPU HBM. Essa arquitetura de IA agênica permite que vários agentes compartilhem um pool de memória grande e de baixo consumo de energia, reduzindo o custo do tratamento de consultas complexas e aprimorando o dimensionamento ao oferecer suporte ao raciocínio de alto rendimento.
À medida que as organizações se preparam para sua próxima rodada de investimentos em infraestrutura, avaliar a eficiência da hierarquia de memória será tão crítico quanto escolher a própria GPU.
Veja também: Guerras dos chips de IA em 2025: o que os líderes empresariais aprenderam sobre a realidade da cadeia de suprimentos
Quer saber mais sobre IA e big data com os líderes do setor? Confira a AI & Big Data Expo, que acontecerá em Amsterdã, Califórnia e Londres. O evento abrangente faz parte da TechEx e é realizado em conjunto com outros eventos de tecnologia importantes. Clique aqui para obter mais informações.
O AI News é desenvolvido pela TechForge Media. Explore outros eventos e webinars de tecnologia empresarial que estão por vir aqui.










 A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
 DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
 O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai













