
















 家
家能動的AIの拡張には高度な記憶システムが必要
エージェント型AIは単純なチャットボットから複雑なワークフロー管理への重要な転換点であり、その拡張には記憶アーキテクチャへの新たなアプローチが求められる。
基盤モデルが数兆のパラメータに成長し、コンテキストウィンドウが数百万トークンに拡大するにつれ、履歴を保持するための計算コストが、それを効果的に処理する能力を上回りつつある。
これらのシステムを導入する組織は現在、膨大な量の「長期記憶」(技術的にはキーバリュー(KV)キャッシュ)が現行ハードウェア設計の能力を超えるボトルネックに直面している。
既存インフラでは選択肢が限られています:推論コンテキストを希少な高帯域GPUメモリ(HBM)に保存するか、低速な汎用ストレージに移すかです。前者は大規模コンテキストではコストがかかりすぎ、後者はリアルタイムのエージェント的相互作用を不可能にする遅延を発生させます。
この拡大するギャップはエージェント型AIのスケーリングを阻害しており、NVIDIAはRubinアーキテクチャ内に推論コンテキストメモリストレージ(ICMS)プラットフォームを導入。AIメモリの一時的かつ高速な要求に特化した新たなストレージ層を構築した。
「AIはコンピューティングスタック全体を変革しつつあり、今やストレージ領域にも及んでいる」と黄氏は述べた。「AIは単一応答型チャットボットを超え、物理世界を理解し、長期にわたる推論を行い、事実に基づき、実用的なタスクにツールを活用し、短期記憶と長期記憶の両方を維持する知的な協力者へと進化した」
中核的な運用課題は、トランスフォーマーベースモデルの動作原理に起因する。生成される新たな単語ごとに会話全体を再計算するのを防ぐため、モデルは過去の状態をKVキャッシュに保存する。エージェント型ワークフローでは、このキャッシュがツールやセッションを跨ぐ永続的メモリとして機能し、シーケンス長に比例して拡張する。
これにより独自のデータカテゴリーが生成される。財務記録や顧客ログとは異なり、KVキャッシュは派生データである。即時性能には不可欠だが、エンタープライズファイルシステムのような堅牢な耐久性保証を必要としない。汎用ストレージシステム(標準CPU上で動作)はメタデータ管理やレプリケーションにエネルギーを消費するが、エージェント型ワークロードはこれらの恩恵を受けない。
GPU HBM(G1)から共有ストレージ(G4)に至る既存の階層構造は、次第に非効率化が進んでいる:
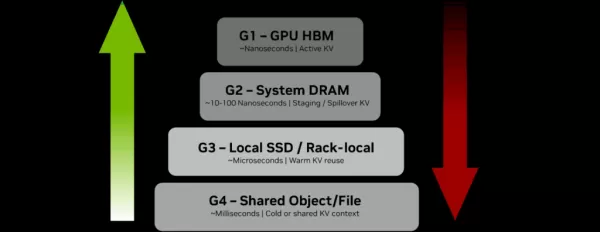
(出典: NVIDIA) コンテキストデータがGPU(G1)からシステムRAM(G2)、最終的に共有ストレージ(G4)へ移動するにつれ、効率は大幅に低下します。アクティブなコンテキストをG4層に転送するとミリ秒レベルの遅延が発生し、トークンあたりのエネルギーコストが上昇。データ待ちで高価なGPUがアイドル状態になります。
企業にとっては、インフラのオーバーヘッドに電力が消費され、アクティブな推論タスクに電力が使われないため、総所有コスト(TCO)の増加につながります。
AIファクトリー向け新メモリ階層
業界の解決策は、この階層にカスタム構築のレイヤーを追加することです。ICMSプラットフォームは「G3.5」層を創出します。これは大規模推論専用に設計されたイーサネット接続フラッシュストレージ層です。
この手法ではストレージをコンピューティングポッドに直接統合。NVIDIA BlueField-4データプロセッサを活用し、コンテキストデータ管理をホストCPUから移行させる。システムはポッドあたりペタバイト級の共有容量を提供し、エージェントが膨大な履歴を保持できるため、高価なHBMを消費せずにエージェント型AIのスケーリングを強化する。
運用上の利点はスループットとエネルギー使用量の両面で測定可能です。標準ストレージより高速でありながらHBMより低コストなこの中間層に関連コンテキストを保存することで、システムは事前にメモリをGPUへ「プリロード」できます。これによりGPUデコーダのアイドル時間が削減され、長コンテキストワークロードにおいて最大5倍のトークン毎秒処理能力(TPS)を実現します。
エネルギー効率の観点でも、同様に大きなメリットがあります。このアーキテクチャは汎用ストレージプロトコルのオーバーヘッドを排除するため、従来手法と比較して5倍の電力効率を実現します。
データプレーンの統合
このアーキテクチャの導入には、ITチームがストレージネットワークを捉える方法の転換が必要です。ICMSプラットフォームは、フラッシュストレージをローカルメモリのように扱うために必要な高帯域幅・低ジッター接続を実現するため、NVIDIA Spectrum-X Ethernetに依存しています。
エンタープライズインフラチームにとっての主要な統合ポイントはオーケストレーション層です。NVIDIA Dynamoや推論転送ライブラリ(NIXL)といったフレームワークが、異なる階層間でのKVブロックの移動を処理します。
これらのツールはストレージ層と連携し、AIモデルが必要とする正確なタイミングで適切なコンテキストがGPUメモリ(G1)またはホストメモリ(G2)にロードされることを保証します。NVIDIA DOCAフレームワークは、コンテキストキャッシュを主要リソースとして扱うKV通信層を提供することで、これをさらに支援します。
主要ストレージベンダーは既にこのアーキテクチャを採用しています。AIC、Cloudian、DDN、Dell Technologies、HPE、Hitachi Vantara、IBM、Nutanix、Pure Storage、Supermicro、VAST Data、WEKAなどの企業がBlueField-4搭載プラットフォームを開発中です。これらのソリューションは今年後半に提供開始が見込まれています。
エージェント型AIのスケーリングに向けたインフラの再定義
専用コンテキストメモリ層の採用は、キャパシティプランニングとデータセンター設計に影響を与えます。
- データの再分類:CIOはKVキャッシュを独自のデータタイプとして認識すべきである。これは「一時的だがレイテンシに敏感」であり、「耐久性がありコールドな」コンプライアンスデータとは異なる。G3.5層が前者を管理することで、耐久性のあるG4ストレージは長期ログやアーティファクトに集中できる。
- オーケストレーションの成熟度:成功はワークロードをインテリジェントに割り当てるソフトウェアに依存する。本システムはトポロジー認識型オーケストレーション(NVIDIA Grove経由)により、ジョブをキャッシュされたコンテキストの近くに配置し、ネットワーク間でのデータ移動を削減する。
- 電力密度:同一ラックスペースにより多くの実効容量を詰め込むことで、組織は既存施設の寿命を延長できる。ただしこれにより平方メートルあたりの演算密度が増加するため、冷却と電力分配の綿密な計画が不可欠となる。
エージェント型AIへの移行にはデータセンターの物理的再設計が不可欠である。計算処理と低速な永続ストレージを完全に分離する従来の手法は、膨大な記憶容量を持つエージェントのリアルタイム検索要件には不適である。
専用のコンテキスト層を導入することで、企業はモデルメモリの増大とGPU HBMコストを分離できる。このエージェント型AIアーキテクチャでは、複数のエージェントが低消費電力の大容量メモリプールを共有できるため、複雑なクエリ処理コストが削減され、高スループット推論のサポートによりスケーラビリティが向上する。
組織が次期インフラ投資を準備するにあたり、メモリ階層の効率性を評価することは、GPU自体の選択と同様に重要となる。
関連記事:2025年のAIチップ戦争:企業リーダーが学んだサプライチェーンの現実

業界リーダーからAIとビッグデータを学びたい方へ。アムステルダム、カリフォルニア、ロンドンで開催される「AI & Big Data Expo」をチェック。TechExの一環として開催されるこの包括的イベントは、他の主要技術イベントと同時開催されます。詳細はこちら。
AI NewsはTechForge Mediaが運営しています。その他の今後のエンタープライズ技術イベントやウェビナーはこちらからご覧ください。
関連記事
 Anthropic社の実験用AI「Claude」が、Eコマースのテストにおいて交渉と取引を完了した
人工知能(AI)が急速に進化する中、Anthropicは先週金曜日、「Project Deal」と呼ばれる社内実験をひっそりと開始し、EコマースにおけるAIの可能性を披露した。この実験では、同社のAIモデル「Claude」が、実際の金銭取引を伴うクローズドな市場環境において、購入、販売、価格交渉を自律的に行うよう設計された。実験の中核となったのは、Slack上に構築された社内マーケットプレイスであ
DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
関連特集おすすめ
仕事
Anthropic社の実験用AI「Claude」が、Eコマースのテストにおいて交渉と取引を完了した
人工知能(AI)が急速に進化する中、Anthropicは先週金曜日、「Project Deal」と呼ばれる社内実験をひっそりと開始し、EコマースにおけるAIの可能性を披露した。この実験では、同社のAIモデル「Claude」が、実際の金銭取引を伴うクローズドな市場環境において、購入、販売、価格交渉を自律的に行うよう設計された。実験の中核となったのは、Slack上に構築された社内マーケットプレイスであ
DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
関連特集おすすめ
仕事
 おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
 10 ツール
10 ツール
 xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
エージェント型AIは単純なチャットボットから複雑なワークフロー管理への重要な転換点であり、その拡張には記憶アーキテクチャへの新たなアプローチが求められる。
基盤モデルが数兆のパラメータに成長し、コンテキストウィンドウが数百万トークンに拡大するにつれ、履歴を保持するための計算コストが、それを効果的に処理する能力を上回りつつある。
これらのシステムを導入する組織は現在、膨大な量の「長期記憶」(技術的にはキーバリュー(KV)キャッシュ)が現行ハードウェア設計の能力を超えるボトルネックに直面している。
既存インフラでは選択肢が限られています:推論コンテキストを希少な高帯域GPUメモリ(HBM)に保存するか、低速な汎用ストレージに移すかです。前者は大規模コンテキストではコストがかかりすぎ、後者はリアルタイムのエージェント的相互作用を不可能にする遅延を発生させます。
この拡大するギャップはエージェント型AIのスケーリングを阻害しており、NVIDIAはRubinアーキテクチャ内に推論コンテキストメモリストレージ(ICMS)プラットフォームを導入。AIメモリの一時的かつ高速な要求に特化した新たなストレージ層を構築した。
「AIはコンピューティングスタック全体を変革しつつあり、今やストレージ領域にも及んでいる」と黄氏は述べた。「AIは単一応答型チャットボットを超え、物理世界を理解し、長期にわたる推論を行い、事実に基づき、実用的なタスクにツールを活用し、短期記憶と長期記憶の両方を維持する知的な協力者へと進化した」
中核的な運用課題は、トランスフォーマーベースモデルの動作原理に起因する。生成される新たな単語ごとに会話全体を再計算するのを防ぐため、モデルは過去の状態をKVキャッシュに保存する。エージェント型ワークフローでは、このキャッシュがツールやセッションを跨ぐ永続的メモリとして機能し、シーケンス長に比例して拡張する。
これにより独自のデータカテゴリーが生成される。財務記録や顧客ログとは異なり、KVキャッシュは派生データである。即時性能には不可欠だが、エンタープライズファイルシステムのような堅牢な耐久性保証を必要としない。汎用ストレージシステム(標準CPU上で動作)はメタデータ管理やレプリケーションにエネルギーを消費するが、エージェント型ワークロードはこれらの恩恵を受けない。
GPU HBM(G1)から共有ストレージ(G4)に至る既存の階層構造は、次第に非効率化が進んでいる:
コンテキストデータがGPU(G1)からシステムRAM(G2)、最終的に共有ストレージ(G4)へ移動するにつれ、効率は大幅に低下します。アクティブなコンテキストをG4層に転送するとミリ秒レベルの遅延が発生し、トークンあたりのエネルギーコストが上昇。データ待ちで高価なGPUがアイドル状態になります。
企業にとっては、インフラのオーバーヘッドに電力が消費され、アクティブな推論タスクに電力が使われないため、総所有コスト(TCO)の増加につながります。
AIファクトリー向け新メモリ階層
業界の解決策は、この階層にカスタム構築のレイヤーを追加することです。ICMSプラットフォームは「G3.5」層を創出します。これは大規模推論専用に設計されたイーサネット接続フラッシュストレージ層です。
この手法ではストレージをコンピューティングポッドに直接統合。NVIDIA BlueField-4データプロセッサを活用し、コンテキストデータ管理をホストCPUから移行させる。システムはポッドあたりペタバイト級の共有容量を提供し、エージェントが膨大な履歴を保持できるため、高価なHBMを消費せずにエージェント型AIのスケーリングを強化する。
運用上の利点はスループットとエネルギー使用量の両面で測定可能です。標準ストレージより高速でありながらHBMより低コストなこの中間層に関連コンテキストを保存することで、システムは事前にメモリをGPUへ「プリロード」できます。これによりGPUデコーダのアイドル時間が削減され、長コンテキストワークロードにおいて最大5倍のトークン毎秒処理能力(TPS)を実現します。
エネルギー効率の観点でも、同様に大きなメリットがあります。このアーキテクチャは汎用ストレージプロトコルのオーバーヘッドを排除するため、従来手法と比較して5倍の電力効率を実現します。
データプレーンの統合
このアーキテクチャの導入には、ITチームがストレージネットワークを捉える方法の転換が必要です。ICMSプラットフォームは、フラッシュストレージをローカルメモリのように扱うために必要な高帯域幅・低ジッター接続を実現するため、NVIDIA Spectrum-X Ethernetに依存しています。
エンタープライズインフラチームにとっての主要な統合ポイントはオーケストレーション層です。NVIDIA Dynamoや推論転送ライブラリ(NIXL)といったフレームワークが、異なる階層間でのKVブロックの移動を処理します。
これらのツールはストレージ層と連携し、AIモデルが必要とする正確なタイミングで適切なコンテキストがGPUメモリ(G1)またはホストメモリ(G2)にロードされることを保証します。NVIDIA DOCAフレームワークは、コンテキストキャッシュを主要リソースとして扱うKV通信層を提供することで、これをさらに支援します。
主要ストレージベンダーは既にこのアーキテクチャを採用しています。AIC、Cloudian、DDN、Dell Technologies、HPE、Hitachi Vantara、IBM、Nutanix、Pure Storage、Supermicro、VAST Data、WEKAなどの企業がBlueField-4搭載プラットフォームを開発中です。これらのソリューションは今年後半に提供開始が見込まれています。
エージェント型AIのスケーリングに向けたインフラの再定義
専用コンテキストメモリ層の採用は、キャパシティプランニングとデータセンター設計に影響を与えます。
- データの再分類:CIOはKVキャッシュを独自のデータタイプとして認識すべきである。これは「一時的だがレイテンシに敏感」であり、「耐久性がありコールドな」コンプライアンスデータとは異なる。G3.5層が前者を管理することで、耐久性のあるG4ストレージは長期ログやアーティファクトに集中できる。
- オーケストレーションの成熟度:成功はワークロードをインテリジェントに割り当てるソフトウェアに依存する。本システムはトポロジー認識型オーケストレーション(NVIDIA Grove経由)により、ジョブをキャッシュされたコンテキストの近くに配置し、ネットワーク間でのデータ移動を削減する。
- 電力密度:同一ラックスペースにより多くの実効容量を詰め込むことで、組織は既存施設の寿命を延長できる。ただしこれにより平方メートルあたりの演算密度が増加するため、冷却と電力分配の綿密な計画が不可欠となる。
エージェント型AIへの移行にはデータセンターの物理的再設計が不可欠である。計算処理と低速な永続ストレージを完全に分離する従来の手法は、膨大な記憶容量を持つエージェントのリアルタイム検索要件には不適である。
専用のコンテキスト層を導入することで、企業はモデルメモリの増大とGPU HBMコストを分離できる。このエージェント型AIアーキテクチャでは、複数のエージェントが低消費電力の大容量メモリプールを共有できるため、複雑なクエリ処理コストが削減され、高スループット推論のサポートによりスケーラビリティが向上する。
組織が次期インフラ投資を準備するにあたり、メモリ階層の効率性を評価することは、GPU自体の選択と同様に重要となる。
関連記事:2025年のAIチップ戦争:企業リーダーが学んだサプライチェーンの現実
業界リーダーからAIとビッグデータを学びたい方へ。アムステルダム、カリフォルニア、ロンドンで開催される「AI & Big Data Expo」をチェック。TechExの一環として開催されるこの包括的イベントは、他の主要技術イベントと同時開催されます。詳細はこちら。
AI NewsはTechForge Mediaが運営しています。その他の今後のエンタープライズ技術イベントやウェビナーはこちらからご覧ください。










 Anthropic社の実験用AI「Claude」が、Eコマースのテストにおいて交渉と取引を完了した
人工知能(AI)が急速に進化する中、Anthropicは先週金曜日、「Project Deal」と呼ばれる社内実験をひっそりと開始し、EコマースにおけるAIの可能性を披露した。この実験では、同社のAIモデル「Claude」が、実際の金銭取引を伴うクローズドな市場環境において、購入、販売、価格交渉を自律的に行うよう設計された。実験の中核となったのは、Slack上に構築された社内マーケットプレイスであ
Anthropic社の実験用AI「Claude」が、Eコマースのテストにおいて交渉と取引を完了した
人工知能(AI)が急速に進化する中、Anthropicは先週金曜日、「Project Deal」と呼ばれる社内実験をひっそりと開始し、EコマースにおけるAIの可能性を披露した。この実験では、同社のAIモデル「Claude」が、実際の金銭取引を伴うクローズドな市場環境において、購入、販売、価格交渉を自律的に行うよう設計された。実験の中核となったのは、Slack上に構築された社内マーケットプレイスであ
 DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
 マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai













