
















 Lar
Lar
Novo modelo de roteador de US$ 1,5 bilhão atinge 93% de precisão, eliminando custos dispendiosos de retreinamento
Os pesquisadores do Katanemo Labs revelaram o Arch-Router, um modelo avançado de roteamento e uma estrutura projetada para direcionar de forma inteligente as consultas dos usuários para o modelo de linguagem grande (LLM) mais adequado.
Para as empresas que desenvolvem produtos que utilizam vários LLMs, o Arch-Rolver resolve um dilema central: como encaminhar automaticamente cada solicitação para o modelo ideal para a tarefa, sem depender de uma lógica inflexível ou de um retreinamento dispendioso sempre que forem necessárias atualizações.
Os desafios do roteamento de LLMs
À medida que a variedade de LLMs disponíveis se expande, os desenvolvedores estão mudando de configurações de modelo único para arquiteturas de vários modelos que utilizam os recursos distintos de modelos diferentes para funções especializadas, como geração de código, resumo de texto ou edição de imagens.
O roteamento LLM tornou-se uma técnica essencial para a construção e a execução desses sistemas, atuando como um diretor de tráfego inteligente que orienta cada consulta do usuário para o modelo mais adequado para lidar com ela.
As abordagens de roteamento atuais geralmente se enquadram em dois grupos principais: roteamento baseado em tarefas, que atribui consultas de acordo com categorias de tarefas predefinidas, e roteamento baseado em desempenho, que busca o melhor equilíbrio entre despesas e qualidade de saída.
No entanto, os sistemas baseados em tarefas costumam falhar quando a intenção do usuário é ambígua ou muda no decorrer de uma conversa, especialmente em diálogos com várias voltas. O roteamento baseado em desempenho, por sua vez, tende a priorizar resultados de benchmark estáticos, frequentemente ignorando as preferências reais do usuário e se adaptando lentamente a novos modelos sem um retreinamento dispendioso.
Como os pesquisadores do Katanemo Labs afirmam em seu artigo, um problema mais profundo é que "os métodos de roteamento existentes têm limitações práticas em aplicações do mundo real. A maioria é otimizada para desempenho de benchmark, mas ignora as preferências humanas, que são guiadas por critérios de avaliação subjetivos".
A equipe enfatiza a importância dos sistemas de roteamento que "refletem julgamentos humanos subjetivos, oferecem maior transparência e permanecem facilmente ajustáveis à medida que os modelos e os aplicativos evoluem".
Uma nova estrutura para roteamento alinhado às preferências
Para superar esses problemas, os pesquisadores desenvolveram uma estrutura de "roteamento alinhado a preferências" que combina as consultas recebidas com as regras de roteamento com base nas preferências personalizadas do usuário.
Nesse sistema, os usuários definem suas políticas de roteamento usando linguagem natural por meio de uma "Taxonomia de Domínio-Ação" de duas camadas. Essa estrutura reflete a forma como as pessoas descrevem naturalmente as tarefas: começando com uma categoria ampla - o domínio, como "jurídico" ou "financeiro" - e chegando a uma tarefa específica - a ação, como "resumo" ou "codificação".
Cada política é então mapeada para um modelo preferido, permitindo que os desenvolvedores baseiem as escolhas de roteamento em requisitos práticos em vez de apenas em métricas de referência. De acordo com o documento, "essa taxonomia funciona como um modelo mental para ajudar os usuários a criar políticas de roteamento bem definidas e estruturadas".
O procedimento de roteamento opera em duas fases. Primeiro, um modelo de roteador alinhado às preferências avalia a consulta do usuário juntamente com todas as políticas disponíveis e escolhe a mais adequada. Em segundo lugar, uma função de mapeamento conecta a política selecionada ao seu LLM atribuído.
Como a lógica de seleção de um modelo é separada da definição da política, os desenvolvedores podem adicionar, remover ou atualizar modelos apenas editando as regras de roteamento - sem treinar novamente ou alterar o roteador. Essa separação permite a flexibilidade necessária para ambientes de produção, em que os modelos e aplicativos estão em constante mudança.
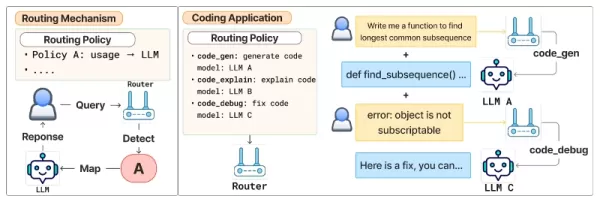
Estrutura de roteamento alinhada às preferências Fonte: arXiv A seleção de políticas é alimentada pelo Arch-Router, um modelo de linguagem compacto de 1,5 bilhão de parâmetros otimizado para roteamento com reconhecimento de preferências. O Arch-Router recebe a consulta do usuário e a lista completa de descrições de políticas como entrada e, em seguida, gera o identificador da política mais adequada.
Como as políticas são incluídas na entrada, o sistema pode se ajustar a rotas novas ou atualizadas durante a inferência por meio do aprendizado no contexto - sem necessidade de retreinamento. Essa estratégia generativa permite que o Arch-Router aproveite sua compreensão pré-treinada para interpretar o significado da consulta e das políticas e para analisar históricos completos de conversas de uma só vez.
Uma preocupação comum com a inclusão de longas listas de políticas em um prompt é o risco de maior latência. No entanto, a equipe criou o Arch-Router para obter alta eficiência. "Mesmo com políticas de roteamento extensas, podemos expandir a janela de contexto do Arch-Router com muito pouco efeito sobre a latência", diz Salman Paracha, coautor do artigo e fundador/CEO da Katanemo Labs. Ele ressalta que a latência é determinada principalmente pelo comprimento da saída, e o Arch-Router só gera um nome curto de política, como "image_editing" ou "document_creation".
Arch-Router em ação
Para criar o Arch-Router, a equipe ajustou uma variante de 1,5B parâmetros do modelo Qwen 2.5 usando um conjunto de dados cuidadosamente montado com 43.000 exemplos. Em seguida, compararam-no com os principais modelos proprietários da OpenAI, Anthropic e Google em quatro conjuntos de dados públicos criados para testar sistemas de IA de conversação.
As descobertas indicam que o Arch-Router obteve a melhor pontuação geral de roteamento de 93,17%, superando todos os outros modelos - inclusive os proprietários de primeira linha - em uma média de 7,71%. A vantagem do modelo ficou mais evidente em conversas mais longas, demonstrando sua capacidade superior de manter o contexto em várias trocas.
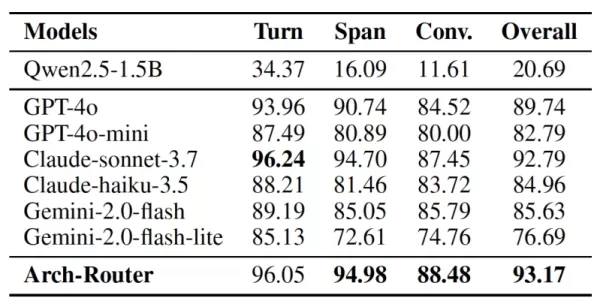
Arch-Router versus outros modelos Fonte: arXiv No uso no mundo real, essa metodologia já está sendo aplicada em vários ambientes, observa Paracha. Por exemplo, em plataformas de codificação de código aberto, os desenvolvedores contam com o Arch-Router para orientar diferentes partes de seu fluxo de trabalho - como "design de código", "compreensão de código" e "geração de código" - para os LLMs mais eficazes para cada etapa. Da mesma forma, as organizações podem encaminhar tarefas de criação de documentos para um modelo como o Claude 3.7 Sonnet e enviar solicitações de edição de imagens para o Gemini 2.5 Pro.
O sistema também é adequado "para assistentes pessoais em vários campos, nos quais os usuários realizam uma série de atividades, desde resumir textos até responder a consultas factuais", explicou Paracha, acrescentando que "nessas situações, o Arch-Router ajuda as equipes de produtos a consolidar e melhorar a experiência geral do usuário".
Essa estrutura é incorporada ao Arch, o servidor proxy nativo de IA da Katanemo Labs para agentes, que oferece suporte à implementação de regras granulares de gerenciamento de tráfego. Por exemplo, ao adicionar um novo LLM, uma equipe pode rotear uma pequena porcentagem do tráfego sob uma determinada política para o novo modelo, validar seu desempenho usando análises internas e, em seguida, transferir todo o tráfego com confiança. A empresa também está trabalhando para integrar suas ferramentas com plataformas de avaliação para tornar esse fluxo de trabalho ainda mais suave para os desenvolvedores corporativos.
Em sua essência, o objetivo é ajudar as organizações a ir além das implementações desconectadas de IA. "O Arch-Router - e a plataforma Arch em geral - permite que os desenvolvedores e as empresas evoluam do uso fragmentado do LLM para um sistema unificado e governado por políticas", afirma Paracha. "Quando os usuários executam uma ampla gama de tarefas, nossa plataforma converte essa diversidade de tarefas e modelos em uma experiência coesa, fazendo com que o produto final pareça perfeito e intuitivo."
Artigo relacionado
 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
O Google lança o Gemini no Chrome na Índia
Na quarta-feira, o Google anunciou que está expandindo a integração do Gemini com o Chrome para novas regiões, incluindo Índia, Canadá e Nova Zelândia. Essa implementação permite que os usuários de co
Recomendações de tópicos especiais relacionados
Conversão de texto para fala
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
O Google lança o Gemini no Chrome na Índia
Na quarta-feira, o Google anunciou que está expandindo a integração do Gemini com o Chrome para novas regiões, incluindo Índia, Canadá e Nova Zelândia. Essa implementação permite que os usuários de co
Recomendações de tópicos especiais relacionados
Conversão de texto para fala
 Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
 10 ferramentas
10 ferramentas
 xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

 Comentários (1)
Comentários (1)
![WillGarcía]()
Arch-Routerの構想は面白いね。社内でどのLLMを使うか毎回悩んでたから、これがあれば効率化に繋がりそう。ただ、精度93%って、結局残りの7%で重大なミスルーティングが起きたりしない? 医療や法務のようなクリティカルな分野への適用は少し不安かな。😅 開発元のKatanemo Labs、これでインフラ市場に本格参戦するつもり?
Os pesquisadores do Katanemo Labs revelaram o Arch-Router, um modelo avançado de roteamento e uma estrutura projetada para direcionar de forma inteligente as consultas dos usuários para o modelo de linguagem grande (LLM) mais adequado.
Para as empresas que desenvolvem produtos que utilizam vários LLMs, o Arch-Rolver resolve um dilema central: como encaminhar automaticamente cada solicitação para o modelo ideal para a tarefa, sem depender de uma lógica inflexível ou de um retreinamento dispendioso sempre que forem necessárias atualizações.
Os desafios do roteamento de LLMs
À medida que a variedade de LLMs disponíveis se expande, os desenvolvedores estão mudando de configurações de modelo único para arquiteturas de vários modelos que utilizam os recursos distintos de modelos diferentes para funções especializadas, como geração de código, resumo de texto ou edição de imagens.
O roteamento LLM tornou-se uma técnica essencial para a construção e a execução desses sistemas, atuando como um diretor de tráfego inteligente que orienta cada consulta do usuário para o modelo mais adequado para lidar com ela.
As abordagens de roteamento atuais geralmente se enquadram em dois grupos principais: roteamento baseado em tarefas, que atribui consultas de acordo com categorias de tarefas predefinidas, e roteamento baseado em desempenho, que busca o melhor equilíbrio entre despesas e qualidade de saída.
No entanto, os sistemas baseados em tarefas costumam falhar quando a intenção do usuário é ambígua ou muda no decorrer de uma conversa, especialmente em diálogos com várias voltas. O roteamento baseado em desempenho, por sua vez, tende a priorizar resultados de benchmark estáticos, frequentemente ignorando as preferências reais do usuário e se adaptando lentamente a novos modelos sem um retreinamento dispendioso.
Como os pesquisadores do Katanemo Labs afirmam em seu artigo, um problema mais profundo é que "os métodos de roteamento existentes têm limitações práticas em aplicações do mundo real. A maioria é otimizada para desempenho de benchmark, mas ignora as preferências humanas, que são guiadas por critérios de avaliação subjetivos".
A equipe enfatiza a importância dos sistemas de roteamento que "refletem julgamentos humanos subjetivos, oferecem maior transparência e permanecem facilmente ajustáveis à medida que os modelos e os aplicativos evoluem".
Uma nova estrutura para roteamento alinhado às preferências
Para superar esses problemas, os pesquisadores desenvolveram uma estrutura de "roteamento alinhado a preferências" que combina as consultas recebidas com as regras de roteamento com base nas preferências personalizadas do usuário.
Nesse sistema, os usuários definem suas políticas de roteamento usando linguagem natural por meio de uma "Taxonomia de Domínio-Ação" de duas camadas. Essa estrutura reflete a forma como as pessoas descrevem naturalmente as tarefas: começando com uma categoria ampla - o domínio, como "jurídico" ou "financeiro" - e chegando a uma tarefa específica - a ação, como "resumo" ou "codificação".
Cada política é então mapeada para um modelo preferido, permitindo que os desenvolvedores baseiem as escolhas de roteamento em requisitos práticos em vez de apenas em métricas de referência. De acordo com o documento, "essa taxonomia funciona como um modelo mental para ajudar os usuários a criar políticas de roteamento bem definidas e estruturadas".
O procedimento de roteamento opera em duas fases. Primeiro, um modelo de roteador alinhado às preferências avalia a consulta do usuário juntamente com todas as políticas disponíveis e escolhe a mais adequada. Em segundo lugar, uma função de mapeamento conecta a política selecionada ao seu LLM atribuído.
Como a lógica de seleção de um modelo é separada da definição da política, os desenvolvedores podem adicionar, remover ou atualizar modelos apenas editando as regras de roteamento - sem treinar novamente ou alterar o roteador. Essa separação permite a flexibilidade necessária para ambientes de produção, em que os modelos e aplicativos estão em constante mudança.
A seleção de políticas é alimentada pelo Arch-Router, um modelo de linguagem compacto de 1,5 bilhão de parâmetros otimizado para roteamento com reconhecimento de preferências. O Arch-Router recebe a consulta do usuário e a lista completa de descrições de políticas como entrada e, em seguida, gera o identificador da política mais adequada.
Como as políticas são incluídas na entrada, o sistema pode se ajustar a rotas novas ou atualizadas durante a inferência por meio do aprendizado no contexto - sem necessidade de retreinamento. Essa estratégia generativa permite que o Arch-Router aproveite sua compreensão pré-treinada para interpretar o significado da consulta e das políticas e para analisar históricos completos de conversas de uma só vez.
Uma preocupação comum com a inclusão de longas listas de políticas em um prompt é o risco de maior latência. No entanto, a equipe criou o Arch-Router para obter alta eficiência. "Mesmo com políticas de roteamento extensas, podemos expandir a janela de contexto do Arch-Router com muito pouco efeito sobre a latência", diz Salman Paracha, coautor do artigo e fundador/CEO da Katanemo Labs. Ele ressalta que a latência é determinada principalmente pelo comprimento da saída, e o Arch-Router só gera um nome curto de política, como "image_editing" ou "document_creation".
Arch-Router em ação
Para criar o Arch-Router, a equipe ajustou uma variante de 1,5B parâmetros do modelo Qwen 2.5 usando um conjunto de dados cuidadosamente montado com 43.000 exemplos. Em seguida, compararam-no com os principais modelos proprietários da OpenAI, Anthropic e Google em quatro conjuntos de dados públicos criados para testar sistemas de IA de conversação.
As descobertas indicam que o Arch-Router obteve a melhor pontuação geral de roteamento de 93,17%, superando todos os outros modelos - inclusive os proprietários de primeira linha - em uma média de 7,71%. A vantagem do modelo ficou mais evidente em conversas mais longas, demonstrando sua capacidade superior de manter o contexto em várias trocas.
No uso no mundo real, essa metodologia já está sendo aplicada em vários ambientes, observa Paracha. Por exemplo, em plataformas de codificação de código aberto, os desenvolvedores contam com o Arch-Router para orientar diferentes partes de seu fluxo de trabalho - como "design de código", "compreensão de código" e "geração de código" - para os LLMs mais eficazes para cada etapa. Da mesma forma, as organizações podem encaminhar tarefas de criação de documentos para um modelo como o Claude 3.7 Sonnet e enviar solicitações de edição de imagens para o Gemini 2.5 Pro.
O sistema também é adequado "para assistentes pessoais em vários campos, nos quais os usuários realizam uma série de atividades, desde resumir textos até responder a consultas factuais", explicou Paracha, acrescentando que "nessas situações, o Arch-Router ajuda as equipes de produtos a consolidar e melhorar a experiência geral do usuário".
Essa estrutura é incorporada ao Arch, o servidor proxy nativo de IA da Katanemo Labs para agentes, que oferece suporte à implementação de regras granulares de gerenciamento de tráfego. Por exemplo, ao adicionar um novo LLM, uma equipe pode rotear uma pequena porcentagem do tráfego sob uma determinada política para o novo modelo, validar seu desempenho usando análises internas e, em seguida, transferir todo o tráfego com confiança. A empresa também está trabalhando para integrar suas ferramentas com plataformas de avaliação para tornar esse fluxo de trabalho ainda mais suave para os desenvolvedores corporativos.
Em sua essência, o objetivo é ajudar as organizações a ir além das implementações desconectadas de IA. "O Arch-Router - e a plataforma Arch em geral - permite que os desenvolvedores e as empresas evoluam do uso fragmentado do LLM para um sistema unificado e governado por políticas", afirma Paracha. "Quando os usuários executam uma ampla gama de tarefas, nossa plataforma converte essa diversidade de tarefas e modelos em uma experiência coesa, fazendo com que o produto final pareça perfeito e intuitivo."










 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
 A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
 O Google lança o Gemini no Chrome na Índia
Na quarta-feira, o Google anunciou que está expandindo a integração do Gemini com o Chrome para novas regiões, incluindo Índia, Canadá e Nova Zelândia. Essa implementação permite que os usuários de co
O Google lança o Gemini no Chrome na Índia
Na quarta-feira, o Google anunciou que está expandindo a integração do Gemini com o Chrome para novas regiões, incluindo Índia, Canadá e Nova Zelândia. Essa implementação permite que os usuários de co

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Arch-Routerの構想は面白いね。社内でどのLLMを使うか毎回悩んでたから、これがあれば効率化に繋がりそう。ただ、精度93%って、結局残りの7%で重大なミスルーティングが起きたりしない? 医療や法務のようなクリティカルな分野への適用は少し不安かな。😅 開発元のKatanemo Labs、これでインフラ市場に本格参戦するつもり?













