
















 집
집15억 달러 규모의 새로운 라우터 모델, 93%의 정확도를 달성하여 값비싼 재교육 비용 제거
카타네모 연구소의 연구원들은 사용자 쿼리를 가장 적합한 대규모 언어 모델(LLM)로 지능적으로 전달하도록 설계된 고급 라우팅 모델 및 프레임워크인 Arch-Router를 공개했습니다.
여러 LLM을 활용하는 제품을 개발하는 기업의 경우 Arch-Rolver는 업데이트가 필요할 때마다 유연하지 않은 로직이나 값비싼 재교육에 의존하지 않고 각 요청을 작업에 가장 적합한 모델로 자동 라우팅하는 방법이라는 핵심 딜레마를 해결해 줍니다.
LLM 라우팅의 과제
사용 가능한 LLM의 종류가 다양해지면서 개발자들은 단일 모델 구성에서 코드 생성, 텍스트 요약, 이미지 편집과 같은 특수 기능을 위해 여러 모델의 고유한 기능을 활용하는 다중 모델 아키텍처로 전환하고 있습니다.
LLM 라우팅은 이러한 시스템을 구축하고 실행하는 데 필수적인 기술이 되었으며, 각 사용자 쿼리를 처리하는 데 가장 적합한 모델로 안내하는 지능형 트래픽 디렉터 역할을 합니다.
현재의 라우팅 접근 방식은 일반적으로 사전 정의된 작업 범주에 따라 쿼리를 할당하는 작업 기반 라우팅과 비용과 출력 품질 간의 최적의 절충점을 찾는 성능 기반 라우팅의 두 가지 주요 그룹으로 나뉩니다.
그러나 작업 기반 시스템은 사용자의 의도가 모호하거나 대화가 진행되는 동안 변경되는 경우, 특히 여러 차례에 걸친 대화에서 종종 흔들리는 경우가 있습니다. 반면 성능 기반 라우팅은 정적인 벤치마크 결과를 우선시하는 경향이 있어 실제 사용자 선호도를 간과하는 경우가 많으며 비용이 많이 드는 재교육 없이 새로운 모델에 느리게 적응하는 경우가 많습니다.
카타네모 연구소의 연구원들은 논문에서 "기존 라우팅 방법은 실제 애플리케이션에서 실질적인 한계가 있다는 것이 더 큰 문제"라고 지적합니다. 대부분 벤치마크 성능에 최적화되어 있지만 주관적인 평가 기준에 따라 사람의 선호도를 무시하고 있습니다."
연구팀은 "인간의 주관적인 판단을 반영하고, 투명성을 높이며, 모델과 애플리케이션이 발전함에 따라 쉽게 조정할 수 있는" 라우팅 시스템의 중요성을 강조합니다.
선호도에 따른 라우팅을 위한 새로운 프레임워크
이러한 문제를 극복하기 위해 연구진은 사용자 기본 설정에 따라 들어오는 쿼리를 라우팅 규칙에 일치시키는 '기본 설정 정렬 라우팅' 프레임워크를 개발했습니다.
이 시스템에서 사용자는 2계층 "도메인-행동 분류"를 통해 자연어를 사용하여 라우팅 정책을 정의합니다. 이 구조는 사람들이 "법률" 또는 "재무"와 같은 광범위한 범주인 도메인에서 시작하여 "요약" 또는 "코딩"과 같은 특정 작업인 액션으로 드릴다운하여 작업을 자연스럽게 설명하는 방식을 반영합니다.
그런 다음 각 정책을 선호하는 모델에 매핑하여 개발자가 벤치마크 지표에만 의존하지 않고 실질적인 요구사항에 따라 라우팅을 선택할 수 있도록 지원합니다. 백서에 따르면 "이 분류 체계는 사용자가 잘 정의되고 구조화된 라우팅 정책을 만드는 데 도움이 되는 정신적 모델 역할을 합니다."
라우팅 절차는 두 단계로 진행됩니다. 먼저 기본 설정에 맞춘 라우터 모델이 사용 가능한 모든 정책과 함께 사용자의 쿼리를 평가하여 가장 적합한 정책을 선택합니다. 둘째, 매핑 기능이 선택한 정책을 할당된 LLM에 연결합니다.
모델 선택 로직이 정책 정의와 분리되어 있으므로 개발자는 라우터를 재교육하거나 변경하지 않고도 라우팅 규칙을 편집하는 것만으로 모델을 추가, 제거 또는 업데이트할 수 있습니다. 이러한 분리 덕분에 모델과 애플리케이션이 지속적으로 변경되는 프로덕션 환경에 필요한 유연성을 확보할 수 있습니다.
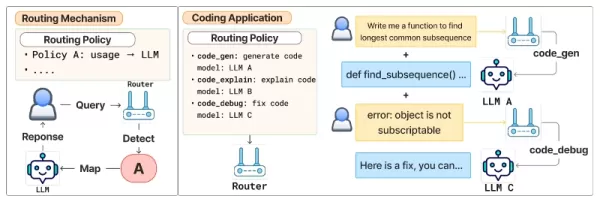
기본 설정에 따른 라우팅 프레임워크 출처: arXiv 정책 선택은 선호도 인식 라우팅에 최적화된 15억 개의 파라미터로 구성된 컴팩트한 언어 모델인 Arch-Router에 의해 구동됩니다. Arch-Router는 사용자 쿼리와 정책 설명의 전체 목록을 입력으로 받은 다음 가장 적합한 정책의 식별자를 출력합니다.
입력에 정책이 포함되어 있기 때문에 시스템은 상황에 맞는 학습을 통해 추론하는 동안 새로운 경로 또는 업데이트된 경로에 적응할 수 있으므로 재교육이 필요하지 않습니다. 이러한 생성 전략을 통해 Arch-Router는 사전 학습된 이해를 활용하여 쿼리와 정책의 의미를 모두 해석하고 전체 대화 내역을 한 번에 분석할 수 있습니다.
프롬프트에 긴 정책 목록을 포함할 때 흔히 우려하는 것은 지연 시간이 길어질 수 있다는 점입니다. 하지만 팀은 높은 효율성을 위해 Arch-Router를 구축했습니다. "광범위한 라우팅 정책을 사용하더라도 지연 시간에 거의 영향을 미치지 않으면서 Arch-Router의 컨텍스트 창을 확장할 수 있습니다."라고 이 백서의 공동 저자이자 Katanemo Labs의 설립자 겸 CEO인 Salman Paracha는 말합니다. 그는 지연 시간은 주로 출력 길이에 의해 결정되며 Arch-Router는 "image_editing" 또는 "document_creation"과 같은 짧은 정책 이름만 출력한다고 지적합니다.
실제 Arch-Router
Arch-Router를 만들기 위해 팀은 43,000개의 예제로 구성된 데이터 세트를 신중하게 조합하여 Qwen 2.5 모델의 15억 개의 매개변수 변형을 미세 조정했습니다. 그런 다음 대화형 AI 시스템을 테스트하기 위해 설계된 4개의 공개 데이터 세트에서 OpenAI, Anthropic, Google의 주요 독점 모델과 비교하여 벤치마킹했습니다.
그 결과 아치 라우터는 전체 라우팅 점수에서 93.17%로 최상위 독점 모델을 포함한 다른 모든 모델보다 평균 7.71% 앞선 것으로 나타났습니다. 이 모델의 우위는 긴 대화에서 더욱 분명해졌으며, 여러 교환에서 컨텍스트를 유지하는 뛰어난 능력을 보여주었습니다.
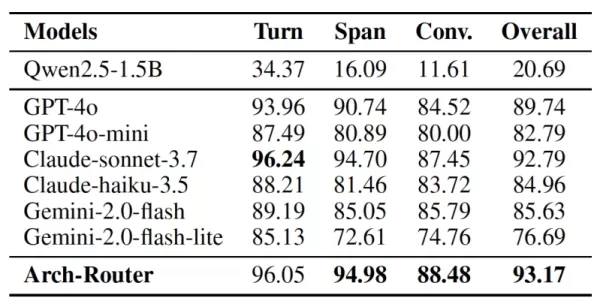
아치 라우터와 다른 모델 비교 출처: arXiv 파라차는 실제 환경에서 이 방법론은 이미 여러 환경에서 적용되고 있다고 말합니다. 예를 들어 오픈 소스 코딩 플랫폼에서 개발자는 '코드 설계', '코드 이해', '코드 생성'과 같은 워크플로우의 여러 부분을 각 단계에 가장 효과적인 LLM으로 안내하기 위해 Arch-Router를 사용합니다. 마찬가지로 조직은 이미지 편집 요청을 Gemini 2.5 Pro로 보내면서 문서 작성 작업을 Claude 3.7 Sonnet과 같은 모델로 라우팅할 수 있습니다.
또한 이 시스템은 "사용자가 텍스트 요약부터 사실적인 질문에 대한 답변까지 다양한 활동을 수행하는 다양한 분야의 개인 비서에도 적합합니다."라고 Paracha는 설명하며 "이러한 상황에서 Arch-Router는 제품 팀이 사용자의 전반적인 경험을 통합하고 개선하는 데 도움이 됩니다."라고 덧붙였습니다.
이 프레임워크는 세분화된 트래픽 관리 규칙 구현을 지원하는 카타네모 랩스의 에이전트용 AI 네이티브 프록시 서버인 Arch에 내장되어 있습니다. 예를 들어, 새 LLM을 추가할 때 팀은 특정 정책에 따라 일부 트래픽을 새 모델로 라우팅하고 내부 분석을 통해 성능을 검증한 다음 모든 트래픽을 자신 있게 전환할 수 있습니다. 또한 기업 개발자가 이 워크플로우를 더욱 원활하게 진행할 수 있도록 도구를 평가 플랫폼과 통합하기 위해 노력하고 있습니다.
이 프로젝트의 핵심 목표는 조직이 단절된 AI 구현을 뛰어넘을 수 있도록 지원하는 것입니다. "아치 라우터와 아치 플랫폼 전반을 통해 개발자와 기업은 파편화된 LLM 사용에서 정책으로 관리되는 통합 시스템으로 진화할 수 있습니다."라고 파라차는 말합니다. "사용자가 다양한 작업을 수행할 때, 저희 플랫폼은 다양한 작업과 모델을 일관된 경험으로 변환하여 최종 제품이 원활하고 직관적으로 느껴지도록 합니다."
관련 기사
 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
구글, 인도에서 크롬용 제미니 서비스 출시
수요일, 구글은 크롬용 제미니(Gemini) 통합 기능을 인도, 캐나다, 뉴질랜드를 포함한 새로운 지역으로 확대한다고 발표했습니다. 이번 업데이트를 통해 데스크톱 사용자는 사이드바를 통해 제미니에 접속할 수 있게 되며, 여기서 구글의 AI 챗봇에게 화면상의 콘텐츠에 대해 질문하거나, 지메일(Gmail), 킵(Keep), 드라이브(Drive), 유튜브(You
관련 특별 주제 추천
텍스트 음성 변환
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
구글, 인도에서 크롬용 제미니 서비스 출시
수요일, 구글은 크롬용 제미니(Gemini) 통합 기능을 인도, 캐나다, 뉴질랜드를 포함한 새로운 지역으로 확대한다고 발표했습니다. 이번 업데이트를 통해 데스크톱 사용자는 사이드바를 통해 제미니에 접속할 수 있게 되며, 여기서 구글의 AI 챗봇에게 화면상의 콘텐츠에 대해 질문하거나, 지메일(Gmail), 킵(Keep), 드라이브(Drive), 유튜브(You
관련 특별 주제 추천
텍스트 음성 변환
 난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
 10 도구
10 도구
 xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

 의견 (1)
0/500
의견 (1)
0/500
![WillGarcía]()
Arch-Routerの構想は面白いね。社内でどのLLMを使うか毎回悩んでたから、これがあれば効率化に繋がりそう。ただ、精度93%って、結局残りの7%で重大なミスルーティングが起きたりしない? 医療や法務のようなクリティカルな分野への適用は少し不安かな。😅 開発元のKatanemo Labs、これでインフラ市場に本格参戦するつもり?
카타네모 연구소의 연구원들은 사용자 쿼리를 가장 적합한 대규모 언어 모델(LLM)로 지능적으로 전달하도록 설계된 고급 라우팅 모델 및 프레임워크인 Arch-Router를 공개했습니다.
여러 LLM을 활용하는 제품을 개발하는 기업의 경우 Arch-Rolver는 업데이트가 필요할 때마다 유연하지 않은 로직이나 값비싼 재교육에 의존하지 않고 각 요청을 작업에 가장 적합한 모델로 자동 라우팅하는 방법이라는 핵심 딜레마를 해결해 줍니다.
LLM 라우팅의 과제
사용 가능한 LLM의 종류가 다양해지면서 개발자들은 단일 모델 구성에서 코드 생성, 텍스트 요약, 이미지 편집과 같은 특수 기능을 위해 여러 모델의 고유한 기능을 활용하는 다중 모델 아키텍처로 전환하고 있습니다.
LLM 라우팅은 이러한 시스템을 구축하고 실행하는 데 필수적인 기술이 되었으며, 각 사용자 쿼리를 처리하는 데 가장 적합한 모델로 안내하는 지능형 트래픽 디렉터 역할을 합니다.
현재의 라우팅 접근 방식은 일반적으로 사전 정의된 작업 범주에 따라 쿼리를 할당하는 작업 기반 라우팅과 비용과 출력 품질 간의 최적의 절충점을 찾는 성능 기반 라우팅의 두 가지 주요 그룹으로 나뉩니다.
그러나 작업 기반 시스템은 사용자의 의도가 모호하거나 대화가 진행되는 동안 변경되는 경우, 특히 여러 차례에 걸친 대화에서 종종 흔들리는 경우가 있습니다. 반면 성능 기반 라우팅은 정적인 벤치마크 결과를 우선시하는 경향이 있어 실제 사용자 선호도를 간과하는 경우가 많으며 비용이 많이 드는 재교육 없이 새로운 모델에 느리게 적응하는 경우가 많습니다.
카타네모 연구소의 연구원들은 논문에서 "기존 라우팅 방법은 실제 애플리케이션에서 실질적인 한계가 있다는 것이 더 큰 문제"라고 지적합니다. 대부분 벤치마크 성능에 최적화되어 있지만 주관적인 평가 기준에 따라 사람의 선호도를 무시하고 있습니다."
연구팀은 "인간의 주관적인 판단을 반영하고, 투명성을 높이며, 모델과 애플리케이션이 발전함에 따라 쉽게 조정할 수 있는" 라우팅 시스템의 중요성을 강조합니다.
선호도에 따른 라우팅을 위한 새로운 프레임워크
이러한 문제를 극복하기 위해 연구진은 사용자 기본 설정에 따라 들어오는 쿼리를 라우팅 규칙에 일치시키는 '기본 설정 정렬 라우팅' 프레임워크를 개발했습니다.
이 시스템에서 사용자는 2계층 "도메인-행동 분류"를 통해 자연어를 사용하여 라우팅 정책을 정의합니다. 이 구조는 사람들이 "법률" 또는 "재무"와 같은 광범위한 범주인 도메인에서 시작하여 "요약" 또는 "코딩"과 같은 특정 작업인 액션으로 드릴다운하여 작업을 자연스럽게 설명하는 방식을 반영합니다.
그런 다음 각 정책을 선호하는 모델에 매핑하여 개발자가 벤치마크 지표에만 의존하지 않고 실질적인 요구사항에 따라 라우팅을 선택할 수 있도록 지원합니다. 백서에 따르면 "이 분류 체계는 사용자가 잘 정의되고 구조화된 라우팅 정책을 만드는 데 도움이 되는 정신적 모델 역할을 합니다."
라우팅 절차는 두 단계로 진행됩니다. 먼저 기본 설정에 맞춘 라우터 모델이 사용 가능한 모든 정책과 함께 사용자의 쿼리를 평가하여 가장 적합한 정책을 선택합니다. 둘째, 매핑 기능이 선택한 정책을 할당된 LLM에 연결합니다.
모델 선택 로직이 정책 정의와 분리되어 있으므로 개발자는 라우터를 재교육하거나 변경하지 않고도 라우팅 규칙을 편집하는 것만으로 모델을 추가, 제거 또는 업데이트할 수 있습니다. 이러한 분리 덕분에 모델과 애플리케이션이 지속적으로 변경되는 프로덕션 환경에 필요한 유연성을 확보할 수 있습니다.
정책 선택은 선호도 인식 라우팅에 최적화된 15억 개의 파라미터로 구성된 컴팩트한 언어 모델인 Arch-Router에 의해 구동됩니다. Arch-Router는 사용자 쿼리와 정책 설명의 전체 목록을 입력으로 받은 다음 가장 적합한 정책의 식별자를 출력합니다.
입력에 정책이 포함되어 있기 때문에 시스템은 상황에 맞는 학습을 통해 추론하는 동안 새로운 경로 또는 업데이트된 경로에 적응할 수 있으므로 재교육이 필요하지 않습니다. 이러한 생성 전략을 통해 Arch-Router는 사전 학습된 이해를 활용하여 쿼리와 정책의 의미를 모두 해석하고 전체 대화 내역을 한 번에 분석할 수 있습니다.
프롬프트에 긴 정책 목록을 포함할 때 흔히 우려하는 것은 지연 시간이 길어질 수 있다는 점입니다. 하지만 팀은 높은 효율성을 위해 Arch-Router를 구축했습니다. "광범위한 라우팅 정책을 사용하더라도 지연 시간에 거의 영향을 미치지 않으면서 Arch-Router의 컨텍스트 창을 확장할 수 있습니다."라고 이 백서의 공동 저자이자 Katanemo Labs의 설립자 겸 CEO인 Salman Paracha는 말합니다. 그는 지연 시간은 주로 출력 길이에 의해 결정되며 Arch-Router는 "image_editing" 또는 "document_creation"과 같은 짧은 정책 이름만 출력한다고 지적합니다.
실제 Arch-Router
Arch-Router를 만들기 위해 팀은 43,000개의 예제로 구성된 데이터 세트를 신중하게 조합하여 Qwen 2.5 모델의 15억 개의 매개변수 변형을 미세 조정했습니다. 그런 다음 대화형 AI 시스템을 테스트하기 위해 설계된 4개의 공개 데이터 세트에서 OpenAI, Anthropic, Google의 주요 독점 모델과 비교하여 벤치마킹했습니다.
그 결과 아치 라우터는 전체 라우팅 점수에서 93.17%로 최상위 독점 모델을 포함한 다른 모든 모델보다 평균 7.71% 앞선 것으로 나타났습니다. 이 모델의 우위는 긴 대화에서 더욱 분명해졌으며, 여러 교환에서 컨텍스트를 유지하는 뛰어난 능력을 보여주었습니다.
파라차는 실제 환경에서 이 방법론은 이미 여러 환경에서 적용되고 있다고 말합니다. 예를 들어 오픈 소스 코딩 플랫폼에서 개발자는 '코드 설계', '코드 이해', '코드 생성'과 같은 워크플로우의 여러 부분을 각 단계에 가장 효과적인 LLM으로 안내하기 위해 Arch-Router를 사용합니다. 마찬가지로 조직은 이미지 편집 요청을 Gemini 2.5 Pro로 보내면서 문서 작성 작업을 Claude 3.7 Sonnet과 같은 모델로 라우팅할 수 있습니다.
또한 이 시스템은 "사용자가 텍스트 요약부터 사실적인 질문에 대한 답변까지 다양한 활동을 수행하는 다양한 분야의 개인 비서에도 적합합니다."라고 Paracha는 설명하며 "이러한 상황에서 Arch-Router는 제품 팀이 사용자의 전반적인 경험을 통합하고 개선하는 데 도움이 됩니다."라고 덧붙였습니다.
이 프레임워크는 세분화된 트래픽 관리 규칙 구현을 지원하는 카타네모 랩스의 에이전트용 AI 네이티브 프록시 서버인 Arch에 내장되어 있습니다. 예를 들어, 새 LLM을 추가할 때 팀은 특정 정책에 따라 일부 트래픽을 새 모델로 라우팅하고 내부 분석을 통해 성능을 검증한 다음 모든 트래픽을 자신 있게 전환할 수 있습니다. 또한 기업 개발자가 이 워크플로우를 더욱 원활하게 진행할 수 있도록 도구를 평가 플랫폼과 통합하기 위해 노력하고 있습니다.
이 프로젝트의 핵심 목표는 조직이 단절된 AI 구현을 뛰어넘을 수 있도록 지원하는 것입니다. "아치 라우터와 아치 플랫폼 전반을 통해 개발자와 기업은 파편화된 LLM 사용에서 정책으로 관리되는 통합 시스템으로 진화할 수 있습니다."라고 파라차는 말합니다. "사용자가 다양한 작업을 수행할 때, 저희 플랫폼은 다양한 작업과 모델을 일관된 경험으로 변환하여 최종 제품이 원활하고 직관적으로 느껴지도록 합니다."










 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
 오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
 구글, 인도에서 크롬용 제미니 서비스 출시
수요일, 구글은 크롬용 제미니(Gemini) 통합 기능을 인도, 캐나다, 뉴질랜드를 포함한 새로운 지역으로 확대한다고 발표했습니다. 이번 업데이트를 통해 데스크톱 사용자는 사이드바를 통해 제미니에 접속할 수 있게 되며, 여기서 구글의 AI 챗봇에게 화면상의 콘텐츠에 대해 질문하거나, 지메일(Gmail), 킵(Keep), 드라이브(Drive), 유튜브(You
구글, 인도에서 크롬용 제미니 서비스 출시
수요일, 구글은 크롬용 제미니(Gemini) 통합 기능을 인도, 캐나다, 뉴질랜드를 포함한 새로운 지역으로 확대한다고 발표했습니다. 이번 업데이트를 통해 데스크톱 사용자는 사이드바를 통해 제미니에 접속할 수 있게 되며, 여기서 구글의 AI 챗봇에게 화면상의 콘텐츠에 대해 질문하거나, 지메일(Gmail), 킵(Keep), 드라이브(Drive), 유튜브(You

난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

Arch-Routerの構想は面白いね。社内でどのLLMを使うか毎回悩んでたから、これがあれば効率化に繋がりそう。ただ、精度93%って、結局残りの7%で重大なミスルーティングが起きたりしない? 医療や法務のようなクリティカルな分野への適用は少し不安かな。😅 開発元のKatanemo Labs、これでインフラ市場に本格参戦するつもり?













