
















 Maison
Maison
Un nouveau modèle de routeur d'une valeur de 1,5 milliard de dollars atteint une précision de 93 %, éliminant ainsi les coûts élevés de recyclage.
Les chercheurs de Katanemo Labs ont dévoilé Arch-Router, un modèle de routage avancé et un cadre conçu pour diriger intelligemment les requêtes des utilisateurs vers le modèle de grand langage (LLM) le plus approprié.
Pour les entreprises qui développent des produits exploitant plusieurs LLM, Arch-Router s'attaque à un dilemme central : comment acheminer automatiquement chaque requête vers le modèle idéal pour la tâche, sans dépendre d'une logique inflexible ou d'un recyclage coûteux chaque fois que des mises à jour sont nécessaires.
Les défis du routage LLM
Au fur et à mesure que la variété des LLM disponibles augmente, les développeurs passent de configurations à modèle unique à des architectures multi-modèles qui utilisent les capacités distinctes de différents modèles pour des fonctions spécialisées, telles que la génération de code, le résumé de texte ou l'édition d'images.
Le routage LLM est devenu une technique essentielle pour construire et faire fonctionner de tels systèmes, servant de directeur de trafic intelligent qui guide chaque requête d'utilisateur vers le modèle le mieux adapté pour la traiter.
Les approches de routage actuelles se répartissent généralement en deux groupes principaux : le routage basé sur les tâches, qui affecte les requêtes en fonction de catégories de tâches prédéfinies, et le routage basé sur les performances, qui recherche le meilleur compromis entre les dépenses et la qualité des résultats.
Cependant, les systèmes basés sur les tâches échouent souvent lorsque l'intention de l'utilisateur est ambiguë ou change au cours d'une conversation, en particulier dans les dialogues à plusieurs tours. Le routage basé sur les performances, quant à lui, a tendance à donner la priorité aux résultats de référence statiques, négligeant souvent les préférences réelles de l'utilisateur et s'adaptant lentement aux nouveaux modèles sans recyclage coûteux.
Comme l'indiquent les chercheurs de Katanemo Labs dans leur article, un problème plus profond réside dans le fait que "les méthodes de routage existantes ont des limites pratiques dans les applications du monde réel. La plupart sont optimisées pour des performances de référence mais ignorent les préférences humaines, qui sont guidées par des critères d'évaluation subjectifs".
L'équipe souligne l'importance des systèmes de routage qui "reflètent les jugements humains subjectifs, offrent une plus grande transparence et restent facilement ajustables à mesure que les modèles et les applications évoluent".
Un nouveau cadre pour le routage aligné sur les préférences
Pour résoudre ces problèmes, les chercheurs ont mis au point un cadre de "routage aligné sur les préférences" qui fait correspondre les requêtes entrantes à des règles de routage basées sur les préférences personnalisées des utilisateurs.
Dans ce système, les utilisateurs définissent leurs politiques de routage en utilisant le langage naturel par le biais d'une "taxonomie domaine-action" à deux niveaux. Cette structure reflète la façon dont les gens décrivent naturellement les tâches : en commençant par une grande catégorie - le domaine, comme "juridique" ou "financier" - et en descendant jusqu'à une tâche spécifique - l'action, comme "résumé" ou "codage".
Chaque politique est ensuite mise en correspondance avec un modèle préféré, ce qui permet aux développeurs de fonder leurs choix de routage sur des exigences pratiques plutôt que sur de simples mesures de référence. Selon l'article, "cette taxonomie sert de modèle mental pour aider les utilisateurs à créer des politiques de routage bien définies et structurées".
La procédure de routage se déroule en deux phases. Tout d'abord, un modèle de routeur aligné sur les préférences évalue la requête de l'utilisateur par rapport à toutes les politiques disponibles et choisit celle qui convient le mieux. Ensuite, une fonction de mise en correspondance relie la politique sélectionnée au LLM qui lui est attribué.
La logique de sélection d'un modèle étant séparée de la définition de la politique, les développeurs peuvent ajouter, supprimer ou mettre à jour des modèles en modifiant simplement les règles de routage, sans avoir à réapprendre ou à modifier le routeur. Cette séparation offre la flexibilité nécessaire aux environnements de production, où les modèles et les applications changent constamment.
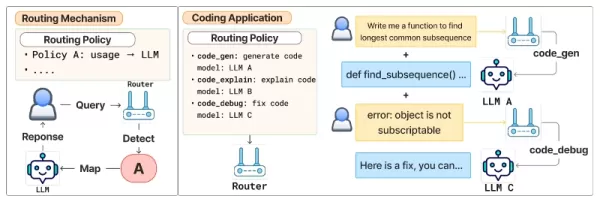
Cadre de routage aligné sur les préférences Source : arXiv La sélection des politiques est assurée par Arch-Router, un modèle de langage compact de 1,5 milliard de paramètres optimisé pour le routage tenant compte des préférences. Arch-Router prend en entrée la requête de l'utilisateur et la liste complète des descriptions de politiques, puis produit l'identifiant de la politique la plus appropriée.
Comme les politiques sont incluses dans l'entrée, le système peut s'adapter à des itinéraires nouveaux ou mis à jour pendant l'inférence grâce à l'apprentissage en contexte - aucun réapprentissage n'est nécessaire. Cette stratégie générative permet à Arch-Router de tirer parti de sa compréhension pré-entraînée pour interpréter le sens de la requête et des politiques, et d'analyser des historiques de conversation complets en une seule fois.
Le risque d'une latence plus élevée est une préoccupation courante lorsqu'il s'agit d'inclure de longues listes de politiques dans un message-guide. Cependant, l'équipe a conçu Arch-Router pour qu'il soit très efficace. "Même avec des politiques de routage étendues, nous pouvons élargir la fenêtre contextuelle d'Arch-Router avec très peu d'effet sur la latence", explique Salman Paracha, coauteur de l'article et fondateur/chef de la direction de Katanemo Labs. Il souligne que la latence est principalement déterminée par la longueur des sorties, et qu'Arch-Router n'émet qu'un nom de politique court, tel que "image_editing" (édition d'images) ou "document_creation" (création de documents).
Arch-Router en action
Pour créer Arch-Router, l'équipe a affiné une variante à 1,5 milliard de paramètres du modèle Qwen 2.5 à l'aide d'un ensemble de données soigneusement constitué de 43 000 exemples. Elle l'a ensuite comparé aux principaux modèles propriétaires d'OpenAI, d'Anthropic et de Google dans quatre ensembles de données publics conçus pour tester les systèmes d'IA conversationnelle.
Les résultats indiquent qu'Arch-Router a obtenu le meilleur score de routage global (93,17 %), surpassant tous les autres modèles, y compris les modèles propriétaires de premier plan, de 7,71 % en moyenne. L'avantage du modèle est devenu plus évident dans les conversations plus longues, mettant en évidence sa capacité supérieure à maintenir le contexte à travers de multiples échanges.
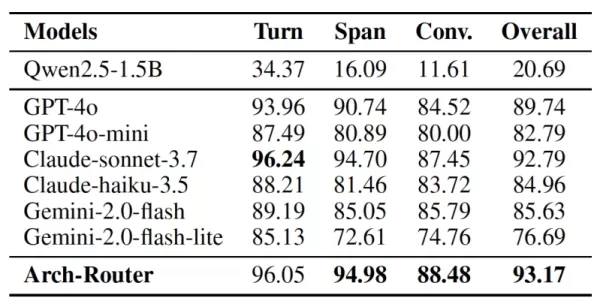
Arch-Router contre d'autres modèles Source : arXiv Dans le monde réel, cette méthodologie est déjà appliquée dans de nombreux contextes, note M. Paracha. Par exemple, dans les plateformes de codage open-source, les développeurs s'appuient sur Arch-Router pour guider les différentes parties de leur flux de travail - comme la "conception du code", la "compréhension du code" et la "génération du code" - vers les LLM les plus efficaces pour chaque étape. De même, les organisations peuvent acheminer les tâches de création de documents vers un modèle tel que Claude 3.7 Sonnet tout en envoyant les demandes d'édition d'images vers Gemini 2.5 Pro.
Le système est également bien adapté "aux assistants personnels dans divers domaines, où les utilisateurs effectuent une série d'activités allant du résumé de texte à la réponse à des questions factuelles", a expliqué M. Paracha, ajoutant que "dans de telles situations, Arch-Router aide les équipes de produits à consolider et à améliorer l'expérience globale de l'utilisateur".
Ce cadre est intégré à Arch, le serveur proxy pour agents natif de l'IA de Katanemo Labs, qui prend en charge la mise en œuvre de règles granulaires de gestion du trafic. Par exemple, lors de l'ajout d'un nouveau LLM, une équipe peut acheminer un petit pourcentage de trafic sous une certaine politique vers le nouveau modèle, valider sa performance à l'aide d'analyses internes, puis transférer en toute confiance l'ensemble du trafic. L'entreprise travaille également à l'intégration de ses outils avec des plateformes d'évaluation afin de rendre ce flux de travail encore plus fluide pour les développeurs d'entreprise.
Au fond, l'objectif est d'aider les organisations à aller au-delà des mises en œuvre déconnectées de l'IA. "Arch-Router - et la plateforme Arch dans son ensemble - permet aux développeurs et aux entreprises de passer d'une utilisation fragmentée des LLM à un système unifié et régi par des politiques", déclare M. Paracha. "Lorsque les utilisateurs effectuent un large éventail de tâches, notre plateforme convertit cette diversité de tâches et de modèles en une expérience cohésive, rendant le produit final transparent et intuitif."
Article connexe
 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Google déploie Gemini dans Chrome en Inde
Mercredi, Google a annoncé l'extension de l'intégration de Gemini dans Chrome à de nouvelles régions, notamment l'Inde, le Canada et la Nouvelle-Zélande. Ce déploiement permet aux utilisateurs d'ordin
Recommandations de sujets spéciaux liés
Synthèse vocale
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Google déploie Gemini dans Chrome en Inde
Mercredi, Google a annoncé l'extension de l'intégration de Gemini dans Chrome à de nouvelles régions, notamment l'Inde, le Canada et la Nouvelle-Zélande. Ce déploiement permet aux utilisateurs d'ordin
Recommandations de sujets spéciaux liés
Synthèse vocale
 Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
 10 outils
10 outils
 xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

 commentaires (1)
commentaires (1)
![WillGarcía]()
Arch-Routerの構想は面白いね。社内でどのLLMを使うか毎回悩んでたから、これがあれば効率化に繋がりそう。ただ、精度93%って、結局残りの7%で重大なミスルーティングが起きたりしない? 医療や法務のようなクリティカルな分野への適用は少し不安かな。😅 開発元のKatanemo Labs、これでインフラ市場に本格参戦するつもり?
Les chercheurs de Katanemo Labs ont dévoilé Arch-Router, un modèle de routage avancé et un cadre conçu pour diriger intelligemment les requêtes des utilisateurs vers le modèle de grand langage (LLM) le plus approprié.
Pour les entreprises qui développent des produits exploitant plusieurs LLM, Arch-Router s'attaque à un dilemme central : comment acheminer automatiquement chaque requête vers le modèle idéal pour la tâche, sans dépendre d'une logique inflexible ou d'un recyclage coûteux chaque fois que des mises à jour sont nécessaires.
Les défis du routage LLM
Au fur et à mesure que la variété des LLM disponibles augmente, les développeurs passent de configurations à modèle unique à des architectures multi-modèles qui utilisent les capacités distinctes de différents modèles pour des fonctions spécialisées, telles que la génération de code, le résumé de texte ou l'édition d'images.
Le routage LLM est devenu une technique essentielle pour construire et faire fonctionner de tels systèmes, servant de directeur de trafic intelligent qui guide chaque requête d'utilisateur vers le modèle le mieux adapté pour la traiter.
Les approches de routage actuelles se répartissent généralement en deux groupes principaux : le routage basé sur les tâches, qui affecte les requêtes en fonction de catégories de tâches prédéfinies, et le routage basé sur les performances, qui recherche le meilleur compromis entre les dépenses et la qualité des résultats.
Cependant, les systèmes basés sur les tâches échouent souvent lorsque l'intention de l'utilisateur est ambiguë ou change au cours d'une conversation, en particulier dans les dialogues à plusieurs tours. Le routage basé sur les performances, quant à lui, a tendance à donner la priorité aux résultats de référence statiques, négligeant souvent les préférences réelles de l'utilisateur et s'adaptant lentement aux nouveaux modèles sans recyclage coûteux.
Comme l'indiquent les chercheurs de Katanemo Labs dans leur article, un problème plus profond réside dans le fait que "les méthodes de routage existantes ont des limites pratiques dans les applications du monde réel. La plupart sont optimisées pour des performances de référence mais ignorent les préférences humaines, qui sont guidées par des critères d'évaluation subjectifs".
L'équipe souligne l'importance des systèmes de routage qui "reflètent les jugements humains subjectifs, offrent une plus grande transparence et restent facilement ajustables à mesure que les modèles et les applications évoluent".
Un nouveau cadre pour le routage aligné sur les préférences
Pour résoudre ces problèmes, les chercheurs ont mis au point un cadre de "routage aligné sur les préférences" qui fait correspondre les requêtes entrantes à des règles de routage basées sur les préférences personnalisées des utilisateurs.
Dans ce système, les utilisateurs définissent leurs politiques de routage en utilisant le langage naturel par le biais d'une "taxonomie domaine-action" à deux niveaux. Cette structure reflète la façon dont les gens décrivent naturellement les tâches : en commençant par une grande catégorie - le domaine, comme "juridique" ou "financier" - et en descendant jusqu'à une tâche spécifique - l'action, comme "résumé" ou "codage".
Chaque politique est ensuite mise en correspondance avec un modèle préféré, ce qui permet aux développeurs de fonder leurs choix de routage sur des exigences pratiques plutôt que sur de simples mesures de référence. Selon l'article, "cette taxonomie sert de modèle mental pour aider les utilisateurs à créer des politiques de routage bien définies et structurées".
La procédure de routage se déroule en deux phases. Tout d'abord, un modèle de routeur aligné sur les préférences évalue la requête de l'utilisateur par rapport à toutes les politiques disponibles et choisit celle qui convient le mieux. Ensuite, une fonction de mise en correspondance relie la politique sélectionnée au LLM qui lui est attribué.
La logique de sélection d'un modèle étant séparée de la définition de la politique, les développeurs peuvent ajouter, supprimer ou mettre à jour des modèles en modifiant simplement les règles de routage, sans avoir à réapprendre ou à modifier le routeur. Cette séparation offre la flexibilité nécessaire aux environnements de production, où les modèles et les applications changent constamment.
La sélection des politiques est assurée par Arch-Router, un modèle de langage compact de 1,5 milliard de paramètres optimisé pour le routage tenant compte des préférences. Arch-Router prend en entrée la requête de l'utilisateur et la liste complète des descriptions de politiques, puis produit l'identifiant de la politique la plus appropriée.
Comme les politiques sont incluses dans l'entrée, le système peut s'adapter à des itinéraires nouveaux ou mis à jour pendant l'inférence grâce à l'apprentissage en contexte - aucun réapprentissage n'est nécessaire. Cette stratégie générative permet à Arch-Router de tirer parti de sa compréhension pré-entraînée pour interpréter le sens de la requête et des politiques, et d'analyser des historiques de conversation complets en une seule fois.
Le risque d'une latence plus élevée est une préoccupation courante lorsqu'il s'agit d'inclure de longues listes de politiques dans un message-guide. Cependant, l'équipe a conçu Arch-Router pour qu'il soit très efficace. "Même avec des politiques de routage étendues, nous pouvons élargir la fenêtre contextuelle d'Arch-Router avec très peu d'effet sur la latence", explique Salman Paracha, coauteur de l'article et fondateur/chef de la direction de Katanemo Labs. Il souligne que la latence est principalement déterminée par la longueur des sorties, et qu'Arch-Router n'émet qu'un nom de politique court, tel que "image_editing" (édition d'images) ou "document_creation" (création de documents).
Arch-Router en action
Pour créer Arch-Router, l'équipe a affiné une variante à 1,5 milliard de paramètres du modèle Qwen 2.5 à l'aide d'un ensemble de données soigneusement constitué de 43 000 exemples. Elle l'a ensuite comparé aux principaux modèles propriétaires d'OpenAI, d'Anthropic et de Google dans quatre ensembles de données publics conçus pour tester les systèmes d'IA conversationnelle.
Les résultats indiquent qu'Arch-Router a obtenu le meilleur score de routage global (93,17 %), surpassant tous les autres modèles, y compris les modèles propriétaires de premier plan, de 7,71 % en moyenne. L'avantage du modèle est devenu plus évident dans les conversations plus longues, mettant en évidence sa capacité supérieure à maintenir le contexte à travers de multiples échanges.
Dans le monde réel, cette méthodologie est déjà appliquée dans de nombreux contextes, note M. Paracha. Par exemple, dans les plateformes de codage open-source, les développeurs s'appuient sur Arch-Router pour guider les différentes parties de leur flux de travail - comme la "conception du code", la "compréhension du code" et la "génération du code" - vers les LLM les plus efficaces pour chaque étape. De même, les organisations peuvent acheminer les tâches de création de documents vers un modèle tel que Claude 3.7 Sonnet tout en envoyant les demandes d'édition d'images vers Gemini 2.5 Pro.
Le système est également bien adapté "aux assistants personnels dans divers domaines, où les utilisateurs effectuent une série d'activités allant du résumé de texte à la réponse à des questions factuelles", a expliqué M. Paracha, ajoutant que "dans de telles situations, Arch-Router aide les équipes de produits à consolider et à améliorer l'expérience globale de l'utilisateur".
Ce cadre est intégré à Arch, le serveur proxy pour agents natif de l'IA de Katanemo Labs, qui prend en charge la mise en œuvre de règles granulaires de gestion du trafic. Par exemple, lors de l'ajout d'un nouveau LLM, une équipe peut acheminer un petit pourcentage de trafic sous une certaine politique vers le nouveau modèle, valider sa performance à l'aide d'analyses internes, puis transférer en toute confiance l'ensemble du trafic. L'entreprise travaille également à l'intégration de ses outils avec des plateformes d'évaluation afin de rendre ce flux de travail encore plus fluide pour les développeurs d'entreprise.
Au fond, l'objectif est d'aider les organisations à aller au-delà des mises en œuvre déconnectées de l'IA. "Arch-Router - et la plateforme Arch dans son ensemble - permet aux développeurs et aux entreprises de passer d'une utilisation fragmentée des LLM à un système unifié et régi par des politiques", déclare M. Paracha. "Lorsque les utilisateurs effectuent un large éventail de tâches, notre plateforme convertit cette diversité de tâches et de modèles en une expérience cohésive, rendant le produit final transparent et intuitif."










 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
 OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
 Google déploie Gemini dans Chrome en Inde
Mercredi, Google a annoncé l'extension de l'intégration de Gemini dans Chrome à de nouvelles régions, notamment l'Inde, le Canada et la Nouvelle-Zélande. Ce déploiement permet aux utilisateurs d'ordin
Google déploie Gemini dans Chrome en Inde
Mercredi, Google a annoncé l'extension de l'intégration de Gemini dans Chrome à de nouvelles régions, notamment l'Inde, le Canada et la Nouvelle-Zélande. Ce déploiement permet aux utilisateurs d'ordin

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Arch-Routerの構想は面白いね。社内でどのLLMを使うか毎回悩んでたから、これがあれば効率化に繋がりそう。ただ、精度93%って、結局残りの7%で重大なミスルーティングが起きたりしない? 医療や法務のようなクリティカルな分野への適用は少し不安かな。😅 開発元のKatanemo Labs、これでインフラ市場に本格参戦するつもり?













