
















 Hogar
Hogar
Un nuevo modelo de enrutador de 1.500 millones de dólares alcanza una precisión del 93%, eliminando los costosos costes de reentrenamiento
Los investigadores de Katanemo Labs han presentado Arch-Router, un modelo de enrutamiento avanzado y un marco diseñado para dirigir de forma inteligente las consultas de los usuarios al modelo de gran lenguaje (LLM) más apropiado.
Para las empresas que desarrollan productos que utilizan múltiples LLM, Arch-Rolver aborda un dilema central: cómo dirigir automáticamente cada solicitud al modelo ideal para la tarea, sin depender de una lógica inflexible o de un costoso reentrenamiento cada vez que se necesitan actualizaciones.
Los retos del enrutamiento LLM
A medida que aumenta la variedad de LLM disponibles, los desarrolladores están pasando de configuraciones de un solo modelo a arquitecturas multimodelo que utilizan las distintas capacidades de diferentes modelos para funciones especializadas, como generar código, resumir texto o editar imágenes.
El enrutamiento LLM se ha convertido en una técnica esencial para construir y ejecutar este tipo de sistemas, ya que actúa como un director de tráfico inteligente que guía cada consulta del usuario hacia el modelo más adecuado para gestionarla.
Los métodos actuales de enrutamiento se dividen en dos grupos principales: el enrutamiento basado en tareas, que asigna las consultas según categorías de tareas predefinidas, y el enrutamiento basado en el rendimiento, que busca el mejor equilibrio entre gasto y calidad del resultado.
Sin embargo, los sistemas basados en tareas suelen fallar cuando la intención del usuario es ambigua o cambia a lo largo de la conversación, sobre todo en diálogos de varios turnos. Por su parte, el enrutamiento basado en el rendimiento tiende a dar prioridad a los resultados estáticos de referencia, pasando por alto con frecuencia las preferencias reales del usuario y adaptándose lentamente a los nuevos modelos sin un costoso reciclaje.
Como afirman los investigadores de Katanemo Labs en su artículo, un problema más profundo es que "los métodos de enrutamiento existentes tienen limitaciones prácticas en las aplicaciones del mundo real. La mayoría están optimizados para obtener un rendimiento de referencia, pero ignoran las preferencias humanas, que se guían por criterios de evaluación subjetivos".
El equipo subraya la importancia de los sistemas de enrutamiento que "reflejan juicios humanos subjetivos, ofrecen mayor transparencia y siguen siendo fácilmente ajustables a medida que evolucionan tanto los modelos como las aplicaciones."
Un nuevo marco para el encaminamiento alineado con las preferencias
Para superar estos problemas, los investigadores desarrollaron un marco de "enrutamiento alineado con las preferencias" que empareja las consultas entrantes con las reglas de enrutamiento basadas en las preferencias personalizadas del usuario.
En este sistema, los usuarios definen sus políticas de enrutamiento mediante lenguaje natural a través de una "taxonomía dominio-acción" de dos niveles. Esta estructura refleja la forma en que las personas describen naturalmente las tareas: empezando por una categoría amplia -el dominio, como "jurídico" o "financiero"- y profundizando en una tarea específica -la acción, como "resumir" o "codificar"-.
A continuación, cada política se asigna a un modelo preferido, lo que permite a los desarrolladores basar sus decisiones de enrutamiento en requisitos prácticos y no sólo en parámetros de referencia. Según el artículo, "esta taxonomía actúa como modelo mental para ayudar a los usuarios a crear políticas de enrutamiento bien definidas y estructuradas".
El procedimiento de enrutamiento funciona en dos fases. En primer lugar, un modelo de enrutador alineado con las preferencias evalúa la consulta del usuario junto con todas las políticas disponibles y elige la que mejor se ajusta. En segundo lugar, una función de mapeo conecta la política seleccionada con su LLM asignado.
Dado que la lógica de selección de un modelo está separada de la definición de la política, los desarrolladores pueden añadir, eliminar o actualizar modelos simplemente editando las reglas de enrutamiento, sin necesidad de volver a entrenar o cambiar el enrutador. Esta separación ofrece la flexibilidad necesaria para los entornos de producción, en los que los modelos y las aplicaciones cambian constantemente.
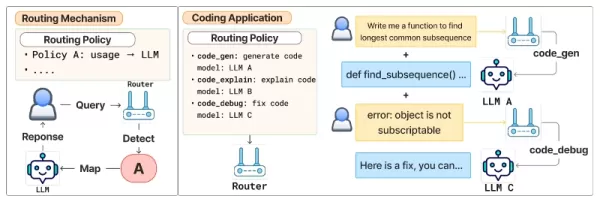
Marco de enrutamiento alineado con las preferencias Fuente: arXiv La selección de políticas se realiza mediante Arch-Router, un modelo de lenguaje compacto de 1.500 millones de parámetros optimizado para el enrutamiento basado en preferencias. Arch-Router toma como datos de entrada la consulta del usuario y la lista completa de descripciones de políticas, y a continuación proporciona el identificador de la política más adecuada.
Dado que las políticas se incluyen en la entrada, el sistema puede ajustarse a rutas nuevas o actualizadas durante la inferencia a través del aprendizaje en contexto, sin necesidad de reentrenamiento. Esta estrategia generativa permite a Arch-Router aprovechar su conocimiento preformado para interpretar el significado tanto de la consulta como de las políticas, y analizar historiales de conversación completos de una sola vez.
Una de las preocupaciones habituales a la hora de incluir largas listas de políticas en una consulta es el riesgo de que aumente la latencia. Sin embargo, el equipo construyó Arch-Router para lograr una alta eficiencia. "Incluso con políticas de enrutamiento extensas, podemos ampliar la ventana de contexto de Arch-Router con muy poco efecto sobre la latencia", afirma Salman Paracha, coautor del artículo y fundador y director ejecutivo de Katanemo Labs. Señala que la latencia está determinada principalmente por la longitud de la salida, y Arch-Router sólo emite un nombre de política corto, como "image_editing" o "document_creation".
Arch-Router en acción
Para crear Arch-Router, el equipo ajustó una variante de 1,5 mil millones de parámetros del modelo Qwen 2.5 utilizando un conjunto de datos cuidadosamente recopilado de 43.000 ejemplos. A continuación, lo compararon con los principales modelos patentados de OpenAI, Anthropic y Google en cuatro conjuntos de datos públicos diseñados para probar sistemas de IA conversacional.
Los resultados indican que Arch-Router obtuvo la mejor puntuación global de enrutamiento, un 93,17%, superando a todos los demás modelos -incluidos los patentados de primer nivel- en una media del 7,71%. La ventaja del modelo se hizo más evidente en las conversaciones más largas, mostrando su capacidad superior para mantener el contexto a través de múltiples intercambios.
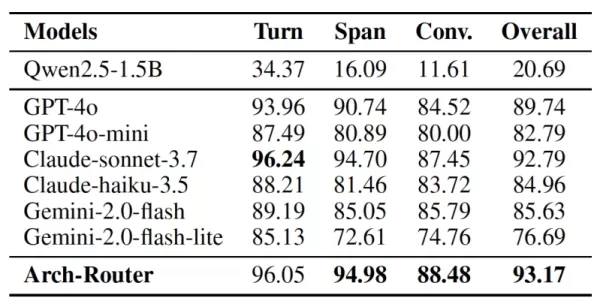
Arch-Router frente a otros modelos Fuente: arXiv En el mundo real, esta metodología ya se está aplicando en múltiples entornos, señala Paracha. Por ejemplo, en las plataformas de codificación de código abierto, los desarrolladores confían en Arch-Router para guiar las distintas partes de su flujo de trabajo -como el "diseño de código", la "comprensión de código" y la "generación de código"- hacia los LLM más eficaces para cada paso. Del mismo modo, las organizaciones pueden dirigir las tareas de creación de documentos a un modelo como Claude 3.7 Sonnet y enviar las solicitudes de edición de imágenes a Gemini 2.5 Pro.
El sistema también es adecuado "para asistentes personales de diversos campos, en los que los usuarios realizan toda una serie de actividades, desde resumir textos hasta responder a consultas sobre hechos", explica Paracha, y añade que "en tales situaciones, Arch-Router ayuda a los equipos de producto a consolidar y mejorar la experiencia global del usuario".
Este marco está integrado en Arch, el servidor proxy nativo de IA para agentes de Katanemo Labs, que admite la implementación de reglas granulares de gestión del tráfico. Por ejemplo, al añadir un nuevo LLM, un equipo puede enrutar un pequeño porcentaje del tráfico bajo una determinada política al nuevo modelo, validar su rendimiento utilizando análisis internos y, a continuación, cambiar con confianza todo el tráfico. La empresa también está trabajando en la integración de sus herramientas con plataformas de evaluación para facilitar aún más este flujo de trabajo a los desarrolladores corporativos.
En el fondo, el objetivo es ayudar a las organizaciones a ir más allá de las implementaciones de IA desconectadas. "Arch-Router -y la plataforma Arch en general- permite a los desarrolladores y a las empresas evolucionar desde un uso fragmentado de la IA a un sistema unificado y gobernado por políticas", afirma Paracha. "Cuando los usuarios realizan una amplia gama de tareas, nuestra plataforma convierte esa diversidad de tareas y modelos en una experiencia cohesiva, haciendo que el producto final se sienta fluido e intuitivo."
Artículo relacionado
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Google lanza Gemini en Chrome en la India
El miércoles, Google anunció que ampliará la integración de Gemini en Chrome a nuevas regiones, entre las que se incluyen la India, Canadá y Nueva Zelanda. Esta actualización permite a los usuarios de
Recomendaciones de temas especiales relacionados
Texto a voz
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Google lanza Gemini en Chrome en la India
El miércoles, Google anunció que ampliará la integración de Gemini en Chrome a nuevas regiones, entre las que se incluyen la India, Canadá y Nueva Zelanda. Esta actualización permite a los usuarios de
Recomendaciones de temas especiales relacionados
Texto a voz
 Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
 10 herramientas
10 herramientas
 xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

 comentario (1)
0/500
comentario (1)
0/500
![WillGarcía]()
Arch-Routerの構想は面白いね。社内でどのLLMを使うか毎回悩んでたから、これがあれば効率化に繋がりそう。ただ、精度93%って、結局残りの7%で重大なミスルーティングが起きたりしない? 医療や法務のようなクリティカルな分野への適用は少し不安かな。😅 開発元のKatanemo Labs、これでインフラ市場に本格参戦するつもり?
Los investigadores de Katanemo Labs han presentado Arch-Router, un modelo de enrutamiento avanzado y un marco diseñado para dirigir de forma inteligente las consultas de los usuarios al modelo de gran lenguaje (LLM) más apropiado.
Para las empresas que desarrollan productos que utilizan múltiples LLM, Arch-Rolver aborda un dilema central: cómo dirigir automáticamente cada solicitud al modelo ideal para la tarea, sin depender de una lógica inflexible o de un costoso reentrenamiento cada vez que se necesitan actualizaciones.
Los retos del enrutamiento LLM
A medida que aumenta la variedad de LLM disponibles, los desarrolladores están pasando de configuraciones de un solo modelo a arquitecturas multimodelo que utilizan las distintas capacidades de diferentes modelos para funciones especializadas, como generar código, resumir texto o editar imágenes.
El enrutamiento LLM se ha convertido en una técnica esencial para construir y ejecutar este tipo de sistemas, ya que actúa como un director de tráfico inteligente que guía cada consulta del usuario hacia el modelo más adecuado para gestionarla.
Los métodos actuales de enrutamiento se dividen en dos grupos principales: el enrutamiento basado en tareas, que asigna las consultas según categorías de tareas predefinidas, y el enrutamiento basado en el rendimiento, que busca el mejor equilibrio entre gasto y calidad del resultado.
Sin embargo, los sistemas basados en tareas suelen fallar cuando la intención del usuario es ambigua o cambia a lo largo de la conversación, sobre todo en diálogos de varios turnos. Por su parte, el enrutamiento basado en el rendimiento tiende a dar prioridad a los resultados estáticos de referencia, pasando por alto con frecuencia las preferencias reales del usuario y adaptándose lentamente a los nuevos modelos sin un costoso reciclaje.
Como afirman los investigadores de Katanemo Labs en su artículo, un problema más profundo es que "los métodos de enrutamiento existentes tienen limitaciones prácticas en las aplicaciones del mundo real. La mayoría están optimizados para obtener un rendimiento de referencia, pero ignoran las preferencias humanas, que se guían por criterios de evaluación subjetivos".
El equipo subraya la importancia de los sistemas de enrutamiento que "reflejan juicios humanos subjetivos, ofrecen mayor transparencia y siguen siendo fácilmente ajustables a medida que evolucionan tanto los modelos como las aplicaciones."
Un nuevo marco para el encaminamiento alineado con las preferencias
Para superar estos problemas, los investigadores desarrollaron un marco de "enrutamiento alineado con las preferencias" que empareja las consultas entrantes con las reglas de enrutamiento basadas en las preferencias personalizadas del usuario.
En este sistema, los usuarios definen sus políticas de enrutamiento mediante lenguaje natural a través de una "taxonomía dominio-acción" de dos niveles. Esta estructura refleja la forma en que las personas describen naturalmente las tareas: empezando por una categoría amplia -el dominio, como "jurídico" o "financiero"- y profundizando en una tarea específica -la acción, como "resumir" o "codificar"-.
A continuación, cada política se asigna a un modelo preferido, lo que permite a los desarrolladores basar sus decisiones de enrutamiento en requisitos prácticos y no sólo en parámetros de referencia. Según el artículo, "esta taxonomía actúa como modelo mental para ayudar a los usuarios a crear políticas de enrutamiento bien definidas y estructuradas".
El procedimiento de enrutamiento funciona en dos fases. En primer lugar, un modelo de enrutador alineado con las preferencias evalúa la consulta del usuario junto con todas las políticas disponibles y elige la que mejor se ajusta. En segundo lugar, una función de mapeo conecta la política seleccionada con su LLM asignado.
Dado que la lógica de selección de un modelo está separada de la definición de la política, los desarrolladores pueden añadir, eliminar o actualizar modelos simplemente editando las reglas de enrutamiento, sin necesidad de volver a entrenar o cambiar el enrutador. Esta separación ofrece la flexibilidad necesaria para los entornos de producción, en los que los modelos y las aplicaciones cambian constantemente.
La selección de políticas se realiza mediante Arch-Router, un modelo de lenguaje compacto de 1.500 millones de parámetros optimizado para el enrutamiento basado en preferencias. Arch-Router toma como datos de entrada la consulta del usuario y la lista completa de descripciones de políticas, y a continuación proporciona el identificador de la política más adecuada.
Dado que las políticas se incluyen en la entrada, el sistema puede ajustarse a rutas nuevas o actualizadas durante la inferencia a través del aprendizaje en contexto, sin necesidad de reentrenamiento. Esta estrategia generativa permite a Arch-Router aprovechar su conocimiento preformado para interpretar el significado tanto de la consulta como de las políticas, y analizar historiales de conversación completos de una sola vez.
Una de las preocupaciones habituales a la hora de incluir largas listas de políticas en una consulta es el riesgo de que aumente la latencia. Sin embargo, el equipo construyó Arch-Router para lograr una alta eficiencia. "Incluso con políticas de enrutamiento extensas, podemos ampliar la ventana de contexto de Arch-Router con muy poco efecto sobre la latencia", afirma Salman Paracha, coautor del artículo y fundador y director ejecutivo de Katanemo Labs. Señala que la latencia está determinada principalmente por la longitud de la salida, y Arch-Router sólo emite un nombre de política corto, como "image_editing" o "document_creation".
Arch-Router en acción
Para crear Arch-Router, el equipo ajustó una variante de 1,5 mil millones de parámetros del modelo Qwen 2.5 utilizando un conjunto de datos cuidadosamente recopilado de 43.000 ejemplos. A continuación, lo compararon con los principales modelos patentados de OpenAI, Anthropic y Google en cuatro conjuntos de datos públicos diseñados para probar sistemas de IA conversacional.
Los resultados indican que Arch-Router obtuvo la mejor puntuación global de enrutamiento, un 93,17%, superando a todos los demás modelos -incluidos los patentados de primer nivel- en una media del 7,71%. La ventaja del modelo se hizo más evidente en las conversaciones más largas, mostrando su capacidad superior para mantener el contexto a través de múltiples intercambios.
En el mundo real, esta metodología ya se está aplicando en múltiples entornos, señala Paracha. Por ejemplo, en las plataformas de codificación de código abierto, los desarrolladores confían en Arch-Router para guiar las distintas partes de su flujo de trabajo -como el "diseño de código", la "comprensión de código" y la "generación de código"- hacia los LLM más eficaces para cada paso. Del mismo modo, las organizaciones pueden dirigir las tareas de creación de documentos a un modelo como Claude 3.7 Sonnet y enviar las solicitudes de edición de imágenes a Gemini 2.5 Pro.
El sistema también es adecuado "para asistentes personales de diversos campos, en los que los usuarios realizan toda una serie de actividades, desde resumir textos hasta responder a consultas sobre hechos", explica Paracha, y añade que "en tales situaciones, Arch-Router ayuda a los equipos de producto a consolidar y mejorar la experiencia global del usuario".
Este marco está integrado en Arch, el servidor proxy nativo de IA para agentes de Katanemo Labs, que admite la implementación de reglas granulares de gestión del tráfico. Por ejemplo, al añadir un nuevo LLM, un equipo puede enrutar un pequeño porcentaje del tráfico bajo una determinada política al nuevo modelo, validar su rendimiento utilizando análisis internos y, a continuación, cambiar con confianza todo el tráfico. La empresa también está trabajando en la integración de sus herramientas con plataformas de evaluación para facilitar aún más este flujo de trabajo a los desarrolladores corporativos.
En el fondo, el objetivo es ayudar a las organizaciones a ir más allá de las implementaciones de IA desconectadas. "Arch-Router -y la plataforma Arch en general- permite a los desarrolladores y a las empresas evolucionar desde un uso fragmentado de la IA a un sistema unificado y gobernado por políticas", afirma Paracha. "Cuando los usuarios realizan una amplia gama de tareas, nuestra plataforma convierte esa diversidad de tareas y modelos en una experiencia cohesiva, haciendo que el producto final se sienta fluido e intuitivo."










 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
 OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
 Google lanza Gemini en Chrome en la India
El miércoles, Google anunció que ampliará la integración de Gemini en Chrome a nuevas regiones, entre las que se incluyen la India, Canadá y Nueva Zelanda. Esta actualización permite a los usuarios de
Google lanza Gemini en Chrome en la India
El miércoles, Google anunció que ampliará la integración de Gemini en Chrome a nuevas regiones, entre las que se incluyen la India, Canadá y Nueva Zelanda. Esta actualización permite a los usuarios de

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Arch-Routerの構想は面白いね。社内でどのLLMを使うか毎回悩んでたから、これがあれば効率化に繋がりそう。ただ、精度93%って、結局残りの7%で重大なミスルーティングが起きたりしない? 医療や法務のようなクリティカルな分野への適用は少し不安かな。😅 開発元のKatanemo Labs、これでインフラ市場に本格参戦するつもり?













