




Nvidia는 AI 벤치 마크를 지배하지만 인텔은 상당한 경쟁을 제공합니다
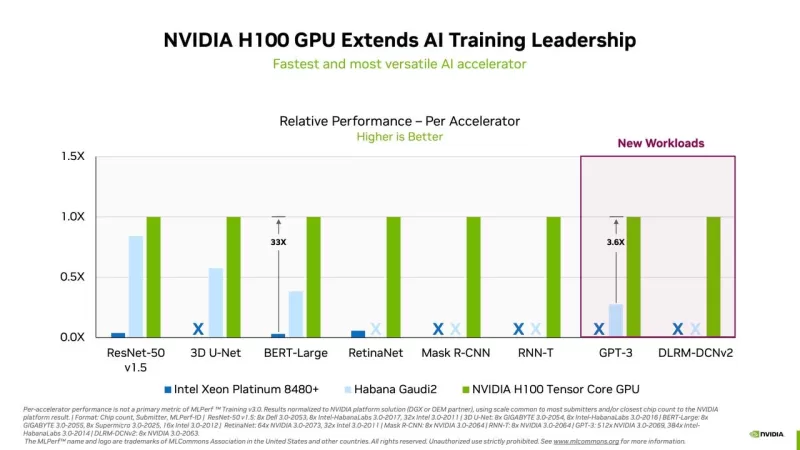
산업 컨소시엄 MLCommons가 화요일에 발표한 최신 신경망 훈련 속도 벤치마크에서 Nvidia가 MLPerf 테스트의 모든 카테고리에서 다시 한 번 최고 성능을 달성했습니다. Google, Graphcore, Advanced Micro Devices와 같은 주요 경쟁자들이 이번 라운드에 참여하지 않으면서 Nvidia의 완전하고 도전받지 않은 독주가 이루어졌습니다.
그러나 Intel의 Habana 부문은 Gaudi2 칩으로 상당한 성과를 보이며 경쟁력을 드러냈습니다. Intel은 이번 가을까지 Nvidia의 플래그십 H100 GPU를 능가하겠다고 과감히 약속했습니다.
MLPerf Training 버전 3.0 벤치마크는 특정 작업에 대해 설정된 정확도 수준을 달성하기 위해 신경망의 "가중치" 또는 매개변수를 조정하는 데 필요한 시간, 즉 "훈련" 과정에 초점을 맞춥니다. 이 테스트 버전은 8가지 서로 다른 작업을 포함하며, 여러 실험을 통해 신경망을 개선하는 데 필요한 시간을 측정합니다. 이는 신경망 성능의 한 측면이며, 다른 측면은 훈련된 네트워크가 새로운 데이터에 대해 예측을 수행하는 "추론"입니다. 추론 성능은 MLCommons에 의해 별도로 평가됩니다.
서버 기반 훈련 외에도 MLCommons는 초저전력 장치에서 예측 성능을 평가하는 MLPerf Tiny 버전 1.1 벤치마크를 도입했습니다.
Nvidia는 8가지 테스트 모두에서 선두를 달리며 가장 빠른 훈련 시간을 달성했습니다. 새롭게 추가된 두 가지 작업에는 OpenAI의 GPT-3 대형 언어 모델(LLM)이 포함되었습니다. ChatGPT의 인기로 촉발된 생성 AI에 대한 열풍은 이를 주요 초점으로 만들었습니다. Nvidia는 CoreWeave와 협력하여 896개의 Intel Xeon 프로세서와 3,584개의 Nvidia H100 GPU로 구성된 시스템을 활용해 GPT-3 작업에서 선두를 차지했습니다. 이 설정은 Nvidia의 NeMO 프레임워크를 사용해 Colossal Cleaned Common Crawl 데이터셋으로 11분 미만 만에 훈련을 완료했습니다. 테스트는 1750억 개의 매개변수를 가진 "대형" GPT-3 버전을 사용했으며, 실행 시간을 관리 가능하게 유지하기 위해 전체 훈련 세트의 0.4%로 제한되었습니다.
또 다른 새로운 추가 사항은 추천 엔진 테스트의 확장된 버전으로, 기존의 1테라바이트 데이터셋을 대체하여 4테라바이트 크기의 Criteo 4TB multi-hot 데이터셋을 사용했습니다. MLCommons는 생산 추천 모델의 크기, 연산 능력, 메모리 작업 규모가 증가하고 있다고 언급했습니다.
AI 칩 분야의 유일한 다른 경쟁자는 Intel의 Habana로, Gaudi2 가속기를 사용한 5개 제출과 SuperMicro의 동일 칩을 사용한 1개를 포함했습니다. 이 제출은 8개 작업 중 4개를 다루었지만, Nvidia의 최고 시스템에 비해 크게 뒤처졌습니다. 예를 들어, BERT Wikipedia 테스트에서 Habana는 5위를 기록하며 2분이 걸린 반면, Nvidia-CoreWeave는 3,072개의 GPU 설정으로 8초 만에 완료했습니다.
그럼에도 불구하고 Intel의 AI 제품 책임자인 Jordan Plawner는 ZDNET 인터뷰에서 비슷한 규모의 시스템에서 Habana와 Nvidia 간의 성능 격차가 많은 기업にとって 결정적이지 않을 수 있다고 강조했습니다. 그는 2개의 Intel Xeon 프로세서를 포함한 8개의 Habana 시스템이 BERT Wikipedia 작업을 14분 남짓 만에 완료하여 더 많은 Nvidia A100 GPU를 사용한 여러 제출을 능가했다고 지적했습니다.
Plawner는 Gaudi2의 비용 효율성을 강조하며, Nvidia의 A100과 비슷한 가격대이지만 훈련에서 더 나은 가치를 제공한다고 언급했습니다. 그는 또한 Nvidia가 제출에서 FP-8 데이터 형식을 사용한 반면, Habana는 더 높은 정밀도를 가진 BF-16 형식을 사용했으며, 이는 훈련 속도를 약간 늦춘다고 설명했습니다. Plawner는 올해 말 FP-8로 전환하면 Gaudi2의 성능이 향상되어 Nvidia의 H100을 잠재적으로 능가할 수 있을 것이라고 기대했습니다.
그는 Nvidia GPU의 현재 공급 제약을 고려할 때 Nvidia에 대한 대안이 필요하다고 강조했습니다. 지연에 좌절한 고객들은 Gaudi2와 같은 대안을 통해 Nvidia 부품을 기다리지 않고 서비스를 시작할 수 있을 것입니다.
세계에서 두 번째로 큰 �ip 제조업체인 Intel은 Taiwan Semiconductor 다음으로, 공급망을 통제하는 전략적 이점을 가지고 있습니다. Plawner는 Intel이 수천 개의 Gaudi2 클러스터를 구축할 계획을 암시하며, 향후 MLPerf 테스트에서 강력한 경쟁자가 될 가능성을 시사했습니다.
이번 분기는 다른 칩 제조업체가 훈련 테스트에서 Nvidia의 선두 자리를 도전하지 않은 두 번째 연속 분기입니다. 1년 전 Google은 TPU를 사용해 Nvidia와 선두를 공유했지만, 이번 라운드에서는 Google과 Graphcore가 벤치마크 경쟁 대신 사업에 집중하며 불참했습니다.
MLCommons의 디렉터 David Kanter는 더 많은 참여자를 원한다고 밝히며, 광범위한 참여가 산업에 이익이 된다고 언급했습니다. Google과 AMD는 이번 라운드 불참에 대한 문의에 응답하지 않았습니다. 흥미롭게도 AMD의 CPU는 경쟁 시스템에 사용되었지만, 모든 우승 Nvidia 설정은 Intel의 Sapphire Rapids 출시로 이전 AMD EPYC 프로세서의 지배에서 전환된 Intel Xeon CPU를 사용했습니다.
일부 주요 업체의 참여 부족에도 불구하고, MLPerf 테스트는 CoreWeave, IEI, Quanta Cloud Technology와 같은 새로운 참가자를 계속 끌어들이며 AI 칩 성능 분야의 지속적인 관심과 경쟁을 보여줍니다.
관련 기사
 다빈치 레졸브에서 오디오 편집 마스터하기: 프로페셔널 사운드를 위한 페어라이트 가이드
선명한 오디오는 아마추어 프로덕션과 전문 비디오 콘텐츠를 구분합니다. 다빈치 Resolve의 페어라이트 페이지에서는 영화 제작자와 콘텐츠 크리에이터가 사운드 디자인을 완성할 수 있는 정교한 도구를 제공합니다. 이 심층 튜토리얼에서는 기본 레코딩부터 세련된 포스트 프로덕션 마스터링까지 오디오를 향상시키기 위한 필수 기술, 최적의 장비 선택, 전문적인 워크플로
이제 구글의 AI가 전화 통화를 대신 처리합니다.
Google은 검색을 통해 모든 미국 사용자에게 AI 통화 기능을 확대하여 고객이 전화 통화 없이도 현지 비즈니스에 가격 및 이용 가능 여부를 문의할 수 있도록 했습니다. 1월에 처음 테스트된 이 기능은 현재 애완동물 미용사, 세탁 서비스, 자동차 수리점 등 서비스 중심 비즈니스를 지원합니다.검색자는 적격 업체 목록 아래에 'AI에게 가격 확인' 옵션이 표
트럼프, 스마트폰, 컴퓨터, 칩 관세 인상 면제
블룸버그 통신에 따르면 트럼프 행정부는 스마트폰, 컴퓨터 및 다양한 전자 기기에 대해 중국에서 수입되는 경우에도 최근 관세 인상에서 예외를 인정했습니다. 그러나 이러한 제품은 4월 9일 이전에 시행된 이전 관세의 적용을 받습니다.미국 관세국경보호청은 수요일 늦게 스마트폰, 노트북, 컴퓨터 부품, 반도체 제조 장비 등 주요 기술 제품을 중국산 수입품에 대한
의견 (11)
0/200
다빈치 레졸브에서 오디오 편집 마스터하기: 프로페셔널 사운드를 위한 페어라이트 가이드
선명한 오디오는 아마추어 프로덕션과 전문 비디오 콘텐츠를 구분합니다. 다빈치 Resolve의 페어라이트 페이지에서는 영화 제작자와 콘텐츠 크리에이터가 사운드 디자인을 완성할 수 있는 정교한 도구를 제공합니다. 이 심층 튜토리얼에서는 기본 레코딩부터 세련된 포스트 프로덕션 마스터링까지 오디오를 향상시키기 위한 필수 기술, 최적의 장비 선택, 전문적인 워크플로
이제 구글의 AI가 전화 통화를 대신 처리합니다.
Google은 검색을 통해 모든 미국 사용자에게 AI 통화 기능을 확대하여 고객이 전화 통화 없이도 현지 비즈니스에 가격 및 이용 가능 여부를 문의할 수 있도록 했습니다. 1월에 처음 테스트된 이 기능은 현재 애완동물 미용사, 세탁 서비스, 자동차 수리점 등 서비스 중심 비즈니스를 지원합니다.검색자는 적격 업체 목록 아래에 'AI에게 가격 확인' 옵션이 표
트럼프, 스마트폰, 컴퓨터, 칩 관세 인상 면제
블룸버그 통신에 따르면 트럼프 행정부는 스마트폰, 컴퓨터 및 다양한 전자 기기에 대해 중국에서 수입되는 경우에도 최근 관세 인상에서 예외를 인정했습니다. 그러나 이러한 제품은 4월 9일 이전에 시행된 이전 관세의 적용을 받습니다.미국 관세국경보호청은 수요일 늦게 스마트폰, 노트북, 컴퓨터 부품, 반도체 제조 장비 등 주요 기술 제품을 중국산 수입품에 대한
의견 (11)
0/200
![HarrySmith]() HarrySmith
HarrySmith
 2025년 8월 12일 오전 2시 1분 2초 GMT+09:00
2025년 8월 12일 오전 2시 1분 2초 GMT+09:00
Intel stepping up to Nvidia's AI game is wild! 🤯 It's like the underdog finally landing some solid punches. Curious to see how this shakes up the market!


 0
0
![HenryJackson]() HenryJackson
2025년 4월 23일 오전 6시 42분 49초 GMT+09:00
HenryJackson
2025년 4월 23일 오전 6시 42분 49초 GMT+09:00
NvidiaのAIベンチマークでの支配力は印象的ですが、Intelの競争が物事を面白くしています。私はプロジェクトにNvidiaのツールを使っていますが、速いです。しかし、Intelの提供するものにも興味があります。もっと詳細な比較があればいいのにと思います。同じように感じる人はいますか?🤔
0
![BruceSmith]() BruceSmith
2025년 4월 23일 오전 4시 22분 27초 GMT+09:00
BruceSmith
2025년 4월 23일 오전 4시 22분 27초 GMT+09:00
El dominio de Nvidia en los benchmarks de IA es impresionante, pero la competencia de Intel mantiene las cosas emocionantes. He estado usando las herramientas de Nvidia para mis proyectos, y son rápidas, pero las ofertas de Intel son intrigantes. Ojalá hubiera más comparaciones detalladas, sin embargo. ¿Alguien más siente lo mismo? 🤔
0
![AlbertDavis]() AlbertDavis
2025년 4월 22일 오후 8시 57분 41초 GMT+09:00
AlbertDavis
2025년 4월 22일 오후 8시 57분 41초 GMT+09:00
Nvidia's dominance in AI benchmarks is impressive, but Intel's competition keeps things interesting! I've been using Nvidia's tech for my projects, and it's super fast. Intel's not far behind though, which is great for us users. Keep pushing the limits, guys! 🚀
0
![ThomasYoung]() ThomasYoung
2025년 4월 22일 오전 6시 17분 21초 GMT+09:00
ThomasYoung
2025년 4월 22일 오전 6시 17분 21초 GMT+09:00
A dominância da Nvidia nos benchmarks de IA é impressionante, mas a competição da Intel está mantendo as coisas emocionantes. Estou usando as ferramentas da Nvidia para meus projetos, e elas são rápidas, mas as ofertas da Intel são intrigantes. Gostaria que houvesse comparações mais detalhadas, no entanto. Alguém mais sente o mesmo? 🤔
0
![WillieJackson]() WillieJackson
2025년 4월 22일 오전 1시 23분 42초 GMT+09:00
WillieJackson
2025년 4월 22일 오전 1시 23분 42초 GMT+09:00
La dominancia de Nvidia en los benchmarks de IA es impresionante, pero la competencia de Intel mantiene las cosas interesantes. He estado usando la tecnología de Nvidia para mis proyectos y es súper rápida. Intel no se queda atrás, lo cual es genial para nosotros los usuarios. ¡Sigan empujando los límites, chicos! 🚀
0
산업 컨소시엄 MLCommons가 화요일에 발표한 최신 신경망 훈련 속도 벤치마크에서 Nvidia가 MLPerf 테스트의 모든 카테고리에서 다시 한 번 최고 성능을 달성했습니다. Google, Graphcore, Advanced Micro Devices와 같은 주요 경쟁자들이 이번 라운드에 참여하지 않으면서 Nvidia의 완전하고 도전받지 않은 독주가 이루어졌습니다.
그러나 Intel의 Habana 부문은 Gaudi2 칩으로 상당한 성과를 보이며 경쟁력을 드러냈습니다. Intel은 이번 가을까지 Nvidia의 플래그십 H100 GPU를 능가하겠다고 과감히 약속했습니다.
MLPerf Training 버전 3.0 벤치마크는 특정 작업에 대해 설정된 정확도 수준을 달성하기 위해 신경망의 "가중치" 또는 매개변수를 조정하는 데 필요한 시간, 즉 "훈련" 과정에 초점을 맞춥니다. 이 테스트 버전은 8가지 서로 다른 작업을 포함하며, 여러 실험을 통해 신경망을 개선하는 데 필요한 시간을 측정합니다. 이는 신경망 성능의 한 측면이며, 다른 측면은 훈련된 네트워크가 새로운 데이터에 대해 예측을 수행하는 "추론"입니다. 추론 성능은 MLCommons에 의해 별도로 평가됩니다.
서버 기반 훈련 외에도 MLCommons는 초저전력 장치에서 예측 성능을 평가하는 MLPerf Tiny 버전 1.1 벤치마크를 도입했습니다.
Nvidia는 8가지 테스트 모두에서 선두를 달리며 가장 빠른 훈련 시간을 달성했습니다. 새롭게 추가된 두 가지 작업에는 OpenAI의 GPT-3 대형 언어 모델(LLM)이 포함되었습니다. ChatGPT의 인기로 촉발된 생성 AI에 대한 열풍은 이를 주요 초점으로 만들었습니다. Nvidia는 CoreWeave와 협력하여 896개의 Intel Xeon 프로세서와 3,584개의 Nvidia H100 GPU로 구성된 시스템을 활용해 GPT-3 작업에서 선두를 차지했습니다. 이 설정은 Nvidia의 NeMO 프레임워크를 사용해 Colossal Cleaned Common Crawl 데이터셋으로 11분 미만 만에 훈련을 완료했습니다. 테스트는 1750억 개의 매개변수를 가진 "대형" GPT-3 버전을 사용했으며, 실행 시간을 관리 가능하게 유지하기 위해 전체 훈련 세트의 0.4%로 제한되었습니다.
또 다른 새로운 추가 사항은 추천 엔진 테스트의 확장된 버전으로, 기존의 1테라바이트 데이터셋을 대체하여 4테라바이트 크기의 Criteo 4TB multi-hot 데이터셋을 사용했습니다. MLCommons는 생산 추천 모델의 크기, 연산 능력, 메모리 작업 규모가 증가하고 있다고 언급했습니다.
AI 칩 분야의 유일한 다른 경쟁자는 Intel의 Habana로, Gaudi2 가속기를 사용한 5개 제출과 SuperMicro의 동일 칩을 사용한 1개를 포함했습니다. 이 제출은 8개 작업 중 4개를 다루었지만, Nvidia의 최고 시스템에 비해 크게 뒤처졌습니다. 예를 들어, BERT Wikipedia 테스트에서 Habana는 5위를 기록하며 2분이 걸린 반면, Nvidia-CoreWeave는 3,072개의 GPU 설정으로 8초 만에 완료했습니다.
그럼에도 불구하고 Intel의 AI 제품 책임자인 Jordan Plawner는 ZDNET 인터뷰에서 비슷한 규모의 시스템에서 Habana와 Nvidia 간의 성능 격차가 많은 기업にとって 결정적이지 않을 수 있다고 강조했습니다. 그는 2개의 Intel Xeon 프로세서를 포함한 8개의 Habana 시스템이 BERT Wikipedia 작업을 14분 남짓 만에 완료하여 더 많은 Nvidia A100 GPU를 사용한 여러 제출을 능가했다고 지적했습니다.
Plawner는 Gaudi2의 비용 효율성을 강조하며, Nvidia의 A100과 비슷한 가격대이지만 훈련에서 더 나은 가치를 제공한다고 언급했습니다. 그는 또한 Nvidia가 제출에서 FP-8 데이터 형식을 사용한 반면, Habana는 더 높은 정밀도를 가진 BF-16 형식을 사용했으며, 이는 훈련 속도를 약간 늦춘다고 설명했습니다. Plawner는 올해 말 FP-8로 전환하면 Gaudi2의 성능이 향상되어 Nvidia의 H100을 잠재적으로 능가할 수 있을 것이라고 기대했습니다.
그는 Nvidia GPU의 현재 공급 제약을 고려할 때 Nvidia에 대한 대안이 필요하다고 강조했습니다. 지연에 좌절한 고객들은 Gaudi2와 같은 대안을 통해 Nvidia 부품을 기다리지 않고 서비스를 시작할 수 있을 것입니다.
세계에서 두 번째로 큰 �ip 제조업체인 Intel은 Taiwan Semiconductor 다음으로, 공급망을 통제하는 전략적 이점을 가지고 있습니다. Plawner는 Intel이 수천 개의 Gaudi2 클러스터를 구축할 계획을 암시하며, 향후 MLPerf 테스트에서 강력한 경쟁자가 될 가능성을 시사했습니다.
이번 분기는 다른 칩 제조업체가 훈련 테스트에서 Nvidia의 선두 자리를 도전하지 않은 두 번째 연속 분기입니다. 1년 전 Google은 TPU를 사용해 Nvidia와 선두를 공유했지만, 이번 라운드에서는 Google과 Graphcore가 벤치마크 경쟁 대신 사업에 집중하며 불참했습니다.
MLCommons의 디렉터 David Kanter는 더 많은 참여자를 원한다고 밝히며, 광범위한 참여가 산업에 이익이 된다고 언급했습니다. Google과 AMD는 이번 라운드 불참에 대한 문의에 응답하지 않았습니다. 흥미롭게도 AMD의 CPU는 경쟁 시스템에 사용되었지만, 모든 우승 Nvidia 설정은 Intel의 Sapphire Rapids 출시로 이전 AMD EPYC 프로세서의 지배에서 전환된 Intel Xeon CPU를 사용했습니다.
일부 주요 업체의 참여 부족에도 불구하고, MLPerf 테스트는 CoreWeave, IEI, Quanta Cloud Technology와 같은 새로운 참가자를 계속 끌어들이며 AI 칩 성능 분야의 지속적인 관심과 경쟁을 보여줍니다.










 다빈치 레졸브에서 오디오 편집 마스터하기: 프로페셔널 사운드를 위한 페어라이트 가이드
선명한 오디오는 아마추어 프로덕션과 전문 비디오 콘텐츠를 구분합니다. 다빈치 Resolve의 페어라이트 페이지에서는 영화 제작자와 콘텐츠 크리에이터가 사운드 디자인을 완성할 수 있는 정교한 도구를 제공합니다. 이 심층 튜토리얼에서는 기본 레코딩부터 세련된 포스트 프로덕션 마스터링까지 오디오를 향상시키기 위한 필수 기술, 최적의 장비 선택, 전문적인 워크플로
다빈치 레졸브에서 오디오 편집 마스터하기: 프로페셔널 사운드를 위한 페어라이트 가이드
선명한 오디오는 아마추어 프로덕션과 전문 비디오 콘텐츠를 구분합니다. 다빈치 Resolve의 페어라이트 페이지에서는 영화 제작자와 콘텐츠 크리에이터가 사운드 디자인을 완성할 수 있는 정교한 도구를 제공합니다. 이 심층 튜토리얼에서는 기본 레코딩부터 세련된 포스트 프로덕션 마스터링까지 오디오를 향상시키기 위한 필수 기술, 최적의 장비 선택, 전문적인 워크플로
 이제 구글의 AI가 전화 통화를 대신 처리합니다.
Google은 검색을 통해 모든 미국 사용자에게 AI 통화 기능을 확대하여 고객이 전화 통화 없이도 현지 비즈니스에 가격 및 이용 가능 여부를 문의할 수 있도록 했습니다. 1월에 처음 테스트된 이 기능은 현재 애완동물 미용사, 세탁 서비스, 자동차 수리점 등 서비스 중심 비즈니스를 지원합니다.검색자는 적격 업체 목록 아래에 'AI에게 가격 확인' 옵션이 표
이제 구글의 AI가 전화 통화를 대신 처리합니다.
Google은 검색을 통해 모든 미국 사용자에게 AI 통화 기능을 확대하여 고객이 전화 통화 없이도 현지 비즈니스에 가격 및 이용 가능 여부를 문의할 수 있도록 했습니다. 1월에 처음 테스트된 이 기능은 현재 애완동물 미용사, 세탁 서비스, 자동차 수리점 등 서비스 중심 비즈니스를 지원합니다.검색자는 적격 업체 목록 아래에 'AI에게 가격 확인' 옵션이 표
 트럼프, 스마트폰, 컴퓨터, 칩 관세 인상 면제
블룸버그 통신에 따르면 트럼프 행정부는 스마트폰, 컴퓨터 및 다양한 전자 기기에 대해 중국에서 수입되는 경우에도 최근 관세 인상에서 예외를 인정했습니다. 그러나 이러한 제품은 4월 9일 이전에 시행된 이전 관세의 적용을 받습니다.미국 관세국경보호청은 수요일 늦게 스마트폰, 노트북, 컴퓨터 부품, 반도체 제조 장비 등 주요 기술 제품을 중국산 수입품에 대한
2025년 8월 12일 오전 2시 1분 2초 GMT+09:00
트럼프, 스마트폰, 컴퓨터, 칩 관세 인상 면제
블룸버그 통신에 따르면 트럼프 행정부는 스마트폰, 컴퓨터 및 다양한 전자 기기에 대해 중국에서 수입되는 경우에도 최근 관세 인상에서 예외를 인정했습니다. 그러나 이러한 제품은 4월 9일 이전에 시행된 이전 관세의 적용을 받습니다.미국 관세국경보호청은 수요일 늦게 스마트폰, 노트북, 컴퓨터 부품, 반도체 제조 장비 등 주요 기술 제품을 중국산 수입품에 대한
2025년 8월 12일 오전 2시 1분 2초 GMT+09:00
Intel stepping up to Nvidia's AI game is wild! 🤯 It's like the underdog finally landing some solid punches. Curious to see how this shakes up the market!
0
2025년 4월 23일 오전 6시 42분 49초 GMT+09:00
NvidiaのAIベンチマークでの支配力は印象的ですが、Intelの競争が物事を面白くしています。私はプロジェクトにNvidiaのツールを使っていますが、速いです。しかし、Intelの提供するものにも興味があります。もっと詳細な比較があればいいのにと思います。同じように感じる人はいますか?🤔
0
2025년 4월 23일 오전 4시 22분 27초 GMT+09:00
El dominio de Nvidia en los benchmarks de IA es impresionante, pero la competencia de Intel mantiene las cosas emocionantes. He estado usando las herramientas de Nvidia para mis proyectos, y son rápidas, pero las ofertas de Intel son intrigantes. Ojalá hubiera más comparaciones detalladas, sin embargo. ¿Alguien más siente lo mismo? 🤔
0
2025년 4월 22일 오후 8시 57분 41초 GMT+09:00
Nvidia's dominance in AI benchmarks is impressive, but Intel's competition keeps things interesting! I've been using Nvidia's tech for my projects, and it's super fast. Intel's not far behind though, which is great for us users. Keep pushing the limits, guys! 🚀
0
2025년 4월 22일 오전 6시 17분 21초 GMT+09:00
A dominância da Nvidia nos benchmarks de IA é impressionante, mas a competição da Intel está mantendo as coisas emocionantes. Estou usando as ferramentas da Nvidia para meus projetos, e elas são rápidas, mas as ofertas da Intel são intrigantes. Gostaria que houvesse comparações mais detalhadas, no entanto. Alguém mais sente o mesmo? 🤔
0
2025년 4월 22일 오전 1시 23분 42초 GMT+09:00
La dominancia de Nvidia en los benchmarks de IA es impresionante, pero la competencia de Intel mantiene las cosas interesantes. He estado usando la tecnología de Nvidia para mis proyectos y es súper rápida. Intel no se queda atrás, lo cual es genial para nosotros los usuarios. ¡Sigan empujando los límites, chicos! 🚀
0













