




NvidiaはAIベンチマークを支配していますが、Intelは重要な競争を提供しています
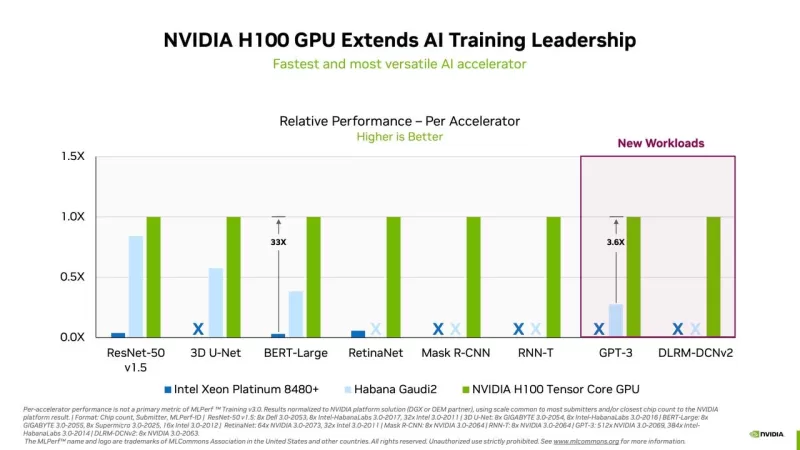
火曜日に業界コンソーシアムMLCommonsが発表した最新のニューラルネットワークトレーニング速度ベンチマークでは、NvidiaがMLPerfテストの全カテゴリーで再び最高のパフォーマーとして君臨しました。Google、Graphcore、Advanced Micro Devicesなどの主要な競合他社がこのラウンドに参加しなかったため、Nvidiaの完全な勝利は揺るぎないものでした。
しかし、IntelのHabana部門はGuadi2チップで顕著な成果を上げ、競争力のある優位性を示しました。Intelは大胆にも、今年の秋までにNvidiaのフラッグシップH100 GPUを上回ると約束しています。
MLPerfトレーニングバージョン3.0ベンチマークは、ニューラルネットワークの「重み」やパラメータを特定のタスクで設定された精度レベルに調整するのに必要な時間、つまり「トレーニング」に焦点を当てています。このバージョンのテストは8つの異なるタスクを包含し、複数の実験を通じてニューラルネットワークを改良するのに必要な時間を測定します。これはニューラルネットワークのパフォーマンスの一つの側面であり、もう一つは「推論」で、トレーニングされたネットワークが新しいデータに対して予測を行うものです。推論のパフォーマンスはMLCommonsによって別途評価されます。
サーバーベースのトレーニングに加えて、MLCommonsは超低消費電力デバイスでの予測パフォーマンスを評価するMLPerf Tinyバージョン1.1ベンチマークを導入しました。
Nvidiaは8つのテストすべてでトップを獲得し、最速のトレーニング時間を達成しました。新しいタスクとして、OpenAIのGPT-3大規模言語モデル(LLM)を含む2つのタスクが導入されました。ChatGPTの人気によって引き起こされた生成AIへの熱狂がこれを注目の的としています。NvidiaはCoreWeaveと協力して、896個のIntel Xeonプロセッサと3,584個のNvidia H100 GPUを搭載したシステムを利用し、GPT-3タスクでリードしました。このセットアップは、NvidiaのNeMOフレームワーク上で動作し、Colossal Cleaned Common Crawlデータセットを使用してわずか11分弱でトレーニングを完了しました。テストでは、実行時間を管理可能にするために、1750億パラメータを持つ「大規模」バージョンのGPT-3を使用し、完全なトレーニングセットの0.4%に制限しました。
もう一つの新しい追加は、レコメンダーエンジンのテストの拡張バージョンで、従来の1テラバイトのデータセットを置き換え、より大規模な4テラバイトのデータセットであるCriteo 4TBマルチホットを使用しました。MLCommonsは、サイズ、計算能力、メモリオペレーションの点で本番レコメンデーションモデルの規模が拡大していると指摘しました。
AIチップ分野での唯一の他の競合はIntelのHabanaで、Gaudi2アクセラレータを使用した5つの提出と、SuperMicroからの同じチップを使用した1つの提出がありました。これらのエントリーは8つのタスクのうち4つをカバーしましたが、Nvidiaの最良のシステムに大きく遅れをとりました。例えば、BERT Wikipediaテストでは、Habanaは5位で、Nvidia-CoreWeaveの3,072 GPUセットアップの8秒に対し、2分かかりました。
それでも、IntelのAI製品責任者であるJordan Plawnerは、ZDNETのインタビューで、同様の規模のシステムでは、HabanaとNvidiaのパフォーマンスギャップが多くの企業にとってそれほど重要ではないかもしれないと強調しました。彼は、2つのIntel Xeonプロセッサを搭載した8デバイスのHabanaシステムが、BERT Wikipediaタスクをわずか14分強で完了し、より多くのNvidia A100 GPUを使用した多くの提出を上回ったと指摘しました。
Plawnerは、Gaudi2のコスト効率を強調し、NvidiaのA100と同等の価格でありながら、トレーニングにおけるコストパフォーマンスが優れていると述べました。彼はまた、Nvidiaが提出でFP-8データ形式を使用したのに対し、Habanaはより高い精度を持つBF-16形式を使用したが、これがトレーニングをわずかに遅くしたと述べました。Plawnerは、今年後半にFP-8に切り替えることで、Gaudi2のパフォーマンスが向上し、NvidiaのH100を上回る可能性があると予測しています。
彼は、NvidiaのGPUの現在の供給制約を考慮して、Nvidiaの代替品が必要だと強調しました。遅延に不満を抱く顧客は、Nvidiaの部品を待たずにサービスを開始できるGaudi2のような代替品にますますオープンです。
世界第2位のチップメーカーであるIntelは、台湾セミコンダクターに次ぐ立場として、サプライチェーンを管理する戦略的優位性を持っています。Plawnerは、Intelが数千のGaudi2クラスタを構築する計画をほのめかし、将来のMLPerfテストでの強力な競争相手となる可能性を示唆しました。
これで、Nvidiaのトレーニングテストでのトップの地位に他のチップメーカーが挑戦しなかったのは2四半期連続です。1年前、GoogleはTPUを使用してNvidiaとトップの座を分け合いましたが、最新のラウンドではGoogleとGraphcoreはベンチマーク競争ではなくビジネスに注力し、参加しませんでした。
MLCommonsのディレクターであるDavid Kanterは、より多くの参加者を望むと述べ、幅広い参加が業界に利益をもたらすと指摘しました。GoogleとAMDはこのラウンドでの不参加についての問い合わせに応じませんでした。興味深いことに、AMDのCPUが競合システムで使用された一方、すべての勝利したNvidiaのセットアップはIntel Xeon CPUを使用し、IntelのSapphire Rapidsのリリースにより、昨年AMDのEPYCプロセッサが支配していた状況からの変化を示しました。
一部の大手企業の参加が欠けたにもかかわらず、MLPerfテストはCoreWeave、IEI、Quanta Cloud Technologyなどの新しい参加者を引きつけ続けており、AIチップパフォーマンスの分野での継続的な関心と競争を示しています。
関連記事
 AIファンフィクション革命:ChatGPTとM&M'sで創造性を高める
ChatGPTで、AIを駆使したストーリーテリングを通して、クリエイティブな境界線が溶け、想像力に限界のない、特別な旅に出かけましょう。この探検では、人工知能がどのように型破りなファンフィクションを作ることができるかを明らかにし、新たな創造の可能性を解き放ちながら、予想を裏切る物語と最愛のブランドキャラクターを融合させます。キーポイント想像力豊かな執筆プロジェクトにChatGPTのようなAIツール
GoogleのNotebookLMがスライドショーにAIを活用したナレーションを導入
グーグルのNotebookLMは、AI技術を活用してナレーション付きのスライドショー・プレゼンテーションを自動生成する革新的なビデオ・オーバービュー機能を導入する。現在、英語版のサポートが開始されていますが、近い将来、対応言語を拡大する予定です。この新しいビデオ・プレゼンテーションは、既存のオーディオ・オーバービューと視覚的に対をなすものである。公式ブログで説明されているように「AIを搭載した
DaVinci Resolveでオーディオ編集を極める:プロフェッショナルサウンドのためのフェアライトガイド
クリアなオーディオは、アマチュア作品とプロのビデオコンテンツを分けます。DaVinci ResolveのFairlightページは、サウンドデザインを完成させる洗練されたツールを映像制作者やコンテンツ制作者に提供します。この詳細なチュートリアルでは、基本的なレコーディングから洗練されたポストプロダクションマスタリングまで、オーディオを向上させるために必要なテクニック、最適な機材の選択、プロフェッシ
コメント (11)
0/200
AIファンフィクション革命:ChatGPTとM&M'sで創造性を高める
ChatGPTで、AIを駆使したストーリーテリングを通して、クリエイティブな境界線が溶け、想像力に限界のない、特別な旅に出かけましょう。この探検では、人工知能がどのように型破りなファンフィクションを作ることができるかを明らかにし、新たな創造の可能性を解き放ちながら、予想を裏切る物語と最愛のブランドキャラクターを融合させます。キーポイント想像力豊かな執筆プロジェクトにChatGPTのようなAIツール
GoogleのNotebookLMがスライドショーにAIを活用したナレーションを導入
グーグルのNotebookLMは、AI技術を活用してナレーション付きのスライドショー・プレゼンテーションを自動生成する革新的なビデオ・オーバービュー機能を導入する。現在、英語版のサポートが開始されていますが、近い将来、対応言語を拡大する予定です。この新しいビデオ・プレゼンテーションは、既存のオーディオ・オーバービューと視覚的に対をなすものである。公式ブログで説明されているように「AIを搭載した
DaVinci Resolveでオーディオ編集を極める:プロフェッショナルサウンドのためのフェアライトガイド
クリアなオーディオは、アマチュア作品とプロのビデオコンテンツを分けます。DaVinci ResolveのFairlightページは、サウンドデザインを完成させる洗練されたツールを映像制作者やコンテンツ制作者に提供します。この詳細なチュートリアルでは、基本的なレコーディングから洗練されたポストプロダクションマスタリングまで、オーディオを向上させるために必要なテクニック、最適な機材の選択、プロフェッシ
コメント (11)
0/200
![HarrySmith]() HarrySmith
HarrySmith
 2025年8月12日 2:01:02 JST
2025年8月12日 2:01:02 JST
Intel stepping up to Nvidia's AI game is wild! 🤯 It's like the underdog finally landing some solid punches. Curious to see how this shakes up the market!


 0
0
![HenryJackson]() HenryJackson
2025年4月23日 6:42:49 JST
HenryJackson
2025年4月23日 6:42:49 JST
NvidiaのAIベンチマークでの支配力は印象的ですが、Intelの競争が物事を面白くしています。私はプロジェクトにNvidiaのツールを使っていますが、速いです。しかし、Intelの提供するものにも興味があります。もっと詳細な比較があればいいのにと思います。同じように感じる人はいますか?🤔
0
![BruceSmith]() BruceSmith
2025年4月23日 4:22:27 JST
BruceSmith
2025年4月23日 4:22:27 JST
El dominio de Nvidia en los benchmarks de IA es impresionante, pero la competencia de Intel mantiene las cosas emocionantes. He estado usando las herramientas de Nvidia para mis proyectos, y son rápidas, pero las ofertas de Intel son intrigantes. Ojalá hubiera más comparaciones detalladas, sin embargo. ¿Alguien más siente lo mismo? 🤔
0
![AlbertDavis]() AlbertDavis
2025年4月22日 20:57:41 JST
AlbertDavis
2025年4月22日 20:57:41 JST
Nvidia's dominance in AI benchmarks is impressive, but Intel's competition keeps things interesting! I've been using Nvidia's tech for my projects, and it's super fast. Intel's not far behind though, which is great for us users. Keep pushing the limits, guys! 🚀
0
![ThomasYoung]() ThomasYoung
2025年4月22日 6:17:21 JST
ThomasYoung
2025年4月22日 6:17:21 JST
A dominância da Nvidia nos benchmarks de IA é impressionante, mas a competição da Intel está mantendo as coisas emocionantes. Estou usando as ferramentas da Nvidia para meus projetos, e elas são rápidas, mas as ofertas da Intel são intrigantes. Gostaria que houvesse comparações mais detalhadas, no entanto. Alguém mais sente o mesmo? 🤔
0
![WillieJackson]() WillieJackson
2025年4月22日 1:23:42 JST
WillieJackson
2025年4月22日 1:23:42 JST
La dominancia de Nvidia en los benchmarks de IA es impresionante, pero la competencia de Intel mantiene las cosas interesantes. He estado usando la tecnología de Nvidia para mis proyectos y es súper rápida. Intel no se queda atrás, lo cual es genial para nosotros los usuarios. ¡Sigan empujando los límites, chicos! 🚀
0
火曜日に業界コンソーシアムMLCommonsが発表した最新のニューラルネットワークトレーニング速度ベンチマークでは、NvidiaがMLPerfテストの全カテゴリーで再び最高のパフォーマーとして君臨しました。Google、Graphcore、Advanced Micro Devicesなどの主要な競合他社がこのラウンドに参加しなかったため、Nvidiaの完全な勝利は揺るぎないものでした。
しかし、IntelのHabana部門はGuadi2チップで顕著な成果を上げ、競争力のある優位性を示しました。Intelは大胆にも、今年の秋までにNvidiaのフラッグシップH100 GPUを上回ると約束しています。
MLPerfトレーニングバージョン3.0ベンチマークは、ニューラルネットワークの「重み」やパラメータを特定のタスクで設定された精度レベルに調整するのに必要な時間、つまり「トレーニング」に焦点を当てています。このバージョンのテストは8つの異なるタスクを包含し、複数の実験を通じてニューラルネットワークを改良するのに必要な時間を測定します。これはニューラルネットワークのパフォーマンスの一つの側面であり、もう一つは「推論」で、トレーニングされたネットワークが新しいデータに対して予測を行うものです。推論のパフォーマンスはMLCommonsによって別途評価されます。
サーバーベースのトレーニングに加えて、MLCommonsは超低消費電力デバイスでの予測パフォーマンスを評価するMLPerf Tinyバージョン1.1ベンチマークを導入しました。
Nvidiaは8つのテストすべてでトップを獲得し、最速のトレーニング時間を達成しました。新しいタスクとして、OpenAIのGPT-3大規模言語モデル(LLM)を含む2つのタスクが導入されました。ChatGPTの人気によって引き起こされた生成AIへの熱狂がこれを注目の的としています。NvidiaはCoreWeaveと協力して、896個のIntel Xeonプロセッサと3,584個のNvidia H100 GPUを搭載したシステムを利用し、GPT-3タスクでリードしました。このセットアップは、NvidiaのNeMOフレームワーク上で動作し、Colossal Cleaned Common Crawlデータセットを使用してわずか11分弱でトレーニングを完了しました。テストでは、実行時間を管理可能にするために、1750億パラメータを持つ「大規模」バージョンのGPT-3を使用し、完全なトレーニングセットの0.4%に制限しました。
もう一つの新しい追加は、レコメンダーエンジンのテストの拡張バージョンで、従来の1テラバイトのデータセットを置き換え、より大規模な4テラバイトのデータセットであるCriteo 4TBマルチホットを使用しました。MLCommonsは、サイズ、計算能力、メモリオペレーションの点で本番レコメンデーションモデルの規模が拡大していると指摘しました。
AIチップ分野での唯一の他の競合はIntelのHabanaで、Gaudi2アクセラレータを使用した5つの提出と、SuperMicroからの同じチップを使用した1つの提出がありました。これらのエントリーは8つのタスクのうち4つをカバーしましたが、Nvidiaの最良のシステムに大きく遅れをとりました。例えば、BERT Wikipediaテストでは、Habanaは5位で、Nvidia-CoreWeaveの3,072 GPUセットアップの8秒に対し、2分かかりました。
それでも、IntelのAI製品責任者であるJordan Plawnerは、ZDNETのインタビューで、同様の規模のシステムでは、HabanaとNvidiaのパフォーマンスギャップが多くの企業にとってそれほど重要ではないかもしれないと強調しました。彼は、2つのIntel Xeonプロセッサを搭載した8デバイスのHabanaシステムが、BERT Wikipediaタスクをわずか14分強で完了し、より多くのNvidia A100 GPUを使用した多くの提出を上回ったと指摘しました。
Plawnerは、Gaudi2のコスト効率を強調し、NvidiaのA100と同等の価格でありながら、トレーニングにおけるコストパフォーマンスが優れていると述べました。彼はまた、Nvidiaが提出でFP-8データ形式を使用したのに対し、Habanaはより高い精度を持つBF-16形式を使用したが、これがトレーニングをわずかに遅くしたと述べました。Plawnerは、今年後半にFP-8に切り替えることで、Gaudi2のパフォーマンスが向上し、NvidiaのH100を上回る可能性があると予測しています。
彼は、NvidiaのGPUの現在の供給制約を考慮して、Nvidiaの代替品が必要だと強調しました。遅延に不満を抱く顧客は、Nvidiaの部品を待たずにサービスを開始できるGaudi2のような代替品にますますオープンです。
世界第2位のチップメーカーであるIntelは、台湾セミコンダクターに次ぐ立場として、サプライチェーンを管理する戦略的優位性を持っています。Plawnerは、Intelが数千のGaudi2クラスタを構築する計画をほのめかし、将来のMLPerfテストでの強力な競争相手となる可能性を示唆しました。
これで、Nvidiaのトレーニングテストでのトップの地位に他のチップメーカーが挑戦しなかったのは2四半期連続です。1年前、GoogleはTPUを使用してNvidiaとトップの座を分け合いましたが、最新のラウンドではGoogleとGraphcoreはベンチマーク競争ではなくビジネスに注力し、参加しませんでした。
MLCommonsのディレクターであるDavid Kanterは、より多くの参加者を望むと述べ、幅広い参加が業界に利益をもたらすと指摘しました。GoogleとAMDはこのラウンドでの不参加についての問い合わせに応じませんでした。興味深いことに、AMDのCPUが競合システムで使用された一方、すべての勝利したNvidiaのセットアップはIntel Xeon CPUを使用し、IntelのSapphire Rapidsのリリースにより、昨年AMDのEPYCプロセッサが支配していた状況からの変化を示しました。
一部の大手企業の参加が欠けたにもかかわらず、MLPerfテストはCoreWeave、IEI、Quanta Cloud Technologyなどの新しい参加者を引きつけ続けており、AIチップパフォーマンスの分野での継続的な関心と競争を示しています。










 AIファンフィクション革命:ChatGPTとM&M'sで創造性を高める
ChatGPTで、AIを駆使したストーリーテリングを通して、クリエイティブな境界線が溶け、想像力に限界のない、特別な旅に出かけましょう。この探検では、人工知能がどのように型破りなファンフィクションを作ることができるかを明らかにし、新たな創造の可能性を解き放ちながら、予想を裏切る物語と最愛のブランドキャラクターを融合させます。キーポイント想像力豊かな執筆プロジェクトにChatGPTのようなAIツール
AIファンフィクション革命:ChatGPTとM&M'sで創造性を高める
ChatGPTで、AIを駆使したストーリーテリングを通して、クリエイティブな境界線が溶け、想像力に限界のない、特別な旅に出かけましょう。この探検では、人工知能がどのように型破りなファンフィクションを作ることができるかを明らかにし、新たな創造の可能性を解き放ちながら、予想を裏切る物語と最愛のブランドキャラクターを融合させます。キーポイント想像力豊かな執筆プロジェクトにChatGPTのようなAIツール
 GoogleのNotebookLMがスライドショーにAIを活用したナレーションを導入
グーグルのNotebookLMは、AI技術を活用してナレーション付きのスライドショー・プレゼンテーションを自動生成する革新的なビデオ・オーバービュー機能を導入する。現在、英語版のサポートが開始されていますが、近い将来、対応言語を拡大する予定です。この新しいビデオ・プレゼンテーションは、既存のオーディオ・オーバービューと視覚的に対をなすものである。公式ブログで説明されているように「AIを搭載した
GoogleのNotebookLMがスライドショーにAIを活用したナレーションを導入
グーグルのNotebookLMは、AI技術を活用してナレーション付きのスライドショー・プレゼンテーションを自動生成する革新的なビデオ・オーバービュー機能を導入する。現在、英語版のサポートが開始されていますが、近い将来、対応言語を拡大する予定です。この新しいビデオ・プレゼンテーションは、既存のオーディオ・オーバービューと視覚的に対をなすものである。公式ブログで説明されているように「AIを搭載した
 DaVinci Resolveでオーディオ編集を極める:プロフェッショナルサウンドのためのフェアライトガイド
クリアなオーディオは、アマチュア作品とプロのビデオコンテンツを分けます。DaVinci ResolveのFairlightページは、サウンドデザインを完成させる洗練されたツールを映像制作者やコンテンツ制作者に提供します。この詳細なチュートリアルでは、基本的なレコーディングから洗練されたポストプロダクションマスタリングまで、オーディオを向上させるために必要なテクニック、最適な機材の選択、プロフェッシ
2025年8月12日 2:01:02 JST
DaVinci Resolveでオーディオ編集を極める:プロフェッショナルサウンドのためのフェアライトガイド
クリアなオーディオは、アマチュア作品とプロのビデオコンテンツを分けます。DaVinci ResolveのFairlightページは、サウンドデザインを完成させる洗練されたツールを映像制作者やコンテンツ制作者に提供します。この詳細なチュートリアルでは、基本的なレコーディングから洗練されたポストプロダクションマスタリングまで、オーディオを向上させるために必要なテクニック、最適な機材の選択、プロフェッシ
2025年8月12日 2:01:02 JST
Intel stepping up to Nvidia's AI game is wild! 🤯 It's like the underdog finally landing some solid punches. Curious to see how this shakes up the market!
0
2025年4月23日 6:42:49 JST
NvidiaのAIベンチマークでの支配力は印象的ですが、Intelの競争が物事を面白くしています。私はプロジェクトにNvidiaのツールを使っていますが、速いです。しかし、Intelの提供するものにも興味があります。もっと詳細な比較があればいいのにと思います。同じように感じる人はいますか?🤔
0
2025年4月23日 4:22:27 JST
El dominio de Nvidia en los benchmarks de IA es impresionante, pero la competencia de Intel mantiene las cosas emocionantes. He estado usando las herramientas de Nvidia para mis proyectos, y son rápidas, pero las ofertas de Intel son intrigantes. Ojalá hubiera más comparaciones detalladas, sin embargo. ¿Alguien más siente lo mismo? 🤔
0
2025年4月22日 20:57:41 JST
Nvidia's dominance in AI benchmarks is impressive, but Intel's competition keeps things interesting! I've been using Nvidia's tech for my projects, and it's super fast. Intel's not far behind though, which is great for us users. Keep pushing the limits, guys! 🚀
0
2025年4月22日 6:17:21 JST
A dominância da Nvidia nos benchmarks de IA é impressionante, mas a competição da Intel está mantendo as coisas emocionantes. Estou usando as ferramentas da Nvidia para meus projetos, e elas são rápidas, mas as ofertas da Intel são intrigantes. Gostaria que houvesse comparações mais detalhadas, no entanto. Alguém mais sente o mesmo? 🤔
0
2025年4月22日 1:23:42 JST
La dominancia de Nvidia en los benchmarks de IA es impresionante, pero la competencia de Intel mantiene las cosas interesantes. He estado usando la tecnología de Nvidia para mis proyectos y es súper rápida. Intel no se queda atrás, lo cual es genial para nosotros los usuarios. ¡Sigan empujando los límites, chicos! 🚀
0













