
















 家
家「Cursor Composer 2」対「Claude Opus 4.6」:ベンチマークテストがAIコーディングを巡る新たな議論を巻き起こす
3月19日、Cursorは自社開発のコーディングモデル「Composer 2」を正式にリリースした。 この発表は開発者コミュニティで即座に議論を巻き起こした。Cursorによると、Composer 2はTerminal-Bench 2.0で61.7%のスコアを記録し、同一のテスト条件下でClaude Opus 4.6の58.0%を大幅に上回ったという。
Anthropicのフラッグシップモデルが、自社のIDEに組み込まれたモデルに性能で敗れたのか?このニュースが広まるにつれ、議論が急速に巻き起こった。
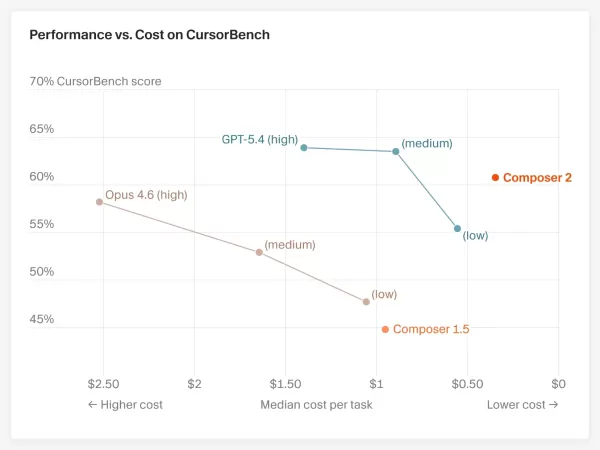
3つの主要なベンチマーク結果
Cursorは3つのベンチマーク結果セットを公開し、いずれも一般に公開されています:
Terminal-Bench 2.0(エージェントスタイルのターミナルコーディングタスク):Composer 2は61.7%を記録し、Claude Opus 4.6の58.0%を上回った。 しかし、OpenAIのGPT-5.4は75.1%で依然としてトップを維持している。CursorBench(Cursor内での実世界コーディングシナリオ): Composer 2は61.3%を記録し、前バージョンのComposer 1.5の44.2%から大幅な向上を見せたほか、Claude Opus 4.6の58.2%をも上回った。SWE-bench Multilingual(多言語ソフトウェアエンジニアリング): Composer 2は73.7%を達成し、前世代モデルから著しい改善が見られた。ただし、1点注目すべき点がある。Anthropicは以前、最適化された設定下でClaude Opus 4.6がTerminal-Bench 2.0において65.4%のスコアを記録したと報告しており、これはCursorが引用した58.0%を大幅に上回る数値である。 この相違はテスト環境に起因する。CursorはHarborのようなサードパーティ製エージェント環境を使用し、5回の実行結果の平均を算出したのに対し、Anthropicの数値は自社独自の最適化された構成によるものである。これらは異なる基準体系を用いているため、両者の数値を直接比較することはできない。 Cursorはこの点を隠そうとはしなかった。発表文では、「結果はエージェント、ハーネス、および設定に依存する」と明示されていた。
Opus 4.6のわずか10分の1のコスト
コストパフォーマンスこそが、Composer 2の真の隠れた強みです。
入力/出力トークン100万単位あたりの価格が0.50ドル/2.50ドルであるのに対し、Claude Opus 4.6は5ドル/25ドル、GPT-5.4は2.5ドル/15ドルであり、その対比は際立っている。 Cursor社によると、Composer 2は長期的なコーディングタスクのためにゼロから構築され、独自のRL(強化学習)トレーニングと「自己要約」技術を用いて、レイテンシとコストの両方を低減しているとのことです。同社はこれを「フロンティア・インテリジェンス+極限のスピード」と表現しています。
Composer 2は、Composer 1(2025年10月)およびバージョン1.5(2026年2月)に続く、Cursorの3番目の自社開発モデルです。今回のリリースでは「長期的なタスク」に重点が置かれており、より高速で軽量なバリエーションがCursor IDEのデフォルトモデルとなっています。
この「灰からの復活」が意味するもの
Cursorが自社のモデルをOpus 4.6と直接比較するという決断は、AIコーディングツール業界全体の動向に変化が生じていることを示唆している。
OpenAIやAnthropicが汎用的な最先端機能で競い合う一方、Cursorのような垂直型ツールプロバイダーは異なる道を選んでいます。それは、特定のタスクにおける性能を卓越したレベルまで磨き上げ、価格面での優位性を活かして差別化を図るというものです。 VentureBeatやThe New Stackなどのメディアは、Composer 2が「マルチモデル・ルーティング」の実用化を加速させると指摘しています。これは、複雑な推論にはOpusやGPTを使用し、日常的な高頻度のコーディングにはComposer 2に切り替えることで、双方の利点を享受する手法です。
2月5日にリリースされたClaude Opus 4.6は、Terminal-Bench 2.0、Humanity's Last Exam、GDPval-AAを含む複数のベンチマークで首位を獲得した。Cursorの新たな結果は、少なくともこの専門的なコーディング分野におけるその優位性に疑問を投げかけている。
現時点での開発者の反応は概ね好意的だが、結論を出す前に実際のプロジェクトでのパフォーマンスを確認したいという声も多い。ベンチマークはあくまでベンチマークに過ぎないため、これは妥当な姿勢だ。Cursorはすでに、サブスクリプションユーザー向けにIDE内でComposer 2の無料トライアルを提供している。
データソース:Cursorの公式発表および主要テックメディア(2026年3月20日時点)。現在のランキングはtbench.aiまたはCursorのウェブサイトで確認できます。
関連記事
 Baidu Healthは、学術情報の検索や事務支援を目的としたAI医師アシスタント「DoctorClaw」を、短期的に社内テストしている。
報道によると、百度健康(Baidu Health)は、医師向けに設計された専門的なAIスマートアシスタントの社内テストを開始した。社内で「DoctorClaw」(ロブスター・ドクター版)と呼ばれるこの製品は、医療分野における百度の大規模言語モデルの展開において、重要な一歩となるものだ。関係者によると、このプロジェクトは依然として非公開の開発段階にあり、現在は社内テスト段階に入っている。具体的な製品
「StrictlyVC サンフランシスコ」に、TDKベンチャーズやReplitなどのリーダーが集結
今年最初のStrictlyVCイベントが、あっという間にサンフランシスコで開催されます。 4月30日にセントロ・フィリピーノ・カルチュラル・センターで開催される本イベントのチケットは、現在も販売中です。豪華なスピーカー陣が登壇するこのイベントでは、StrictlyVCならではのネットワーキングやコミュニティ交流に加え、資金調達に関する最新の知見を求めるAI分野のイノベーターや起業家の方々にとって、
Notionは、ワークスペースをAIエージェントのハブへと変革します
生産性向上ソフトウェア企業であるNotionが、「エージェント時代」に突入する。水曜日にライブ配信された製品発表会で、共同ノート作成アプリで知られるNotionは、カスタムAIエージェントの機能を拡張し、外部エージェントと連携し、あらゆるデータベースからデータを取得できる自動化された多段階ワークフローをチームが構築できるようにする新しい開発者向けプラットフォームを発表した。複数のツールやデータソー
関連特集おすすめ
書き込み
Baidu Healthは、学術情報の検索や事務支援を目的としたAI医師アシスタント「DoctorClaw」を、短期的に社内テストしている。
報道によると、百度健康(Baidu Health)は、医師向けに設計された専門的なAIスマートアシスタントの社内テストを開始した。社内で「DoctorClaw」(ロブスター・ドクター版)と呼ばれるこの製品は、医療分野における百度の大規模言語モデルの展開において、重要な一歩となるものだ。関係者によると、このプロジェクトは依然として非公開の開発段階にあり、現在は社内テスト段階に入っている。具体的な製品
「StrictlyVC サンフランシスコ」に、TDKベンチャーズやReplitなどのリーダーが集結
今年最初のStrictlyVCイベントが、あっという間にサンフランシスコで開催されます。 4月30日にセントロ・フィリピーノ・カルチュラル・センターで開催される本イベントのチケットは、現在も販売中です。豪華なスピーカー陣が登壇するこのイベントでは、StrictlyVCならではのネットワーキングやコミュニティ交流に加え、資金調達に関する最新の知見を求めるAI分野のイノベーターや起業家の方々にとって、
Notionは、ワークスペースをAIエージェントのハブへと変革します
生産性向上ソフトウェア企業であるNotionが、「エージェント時代」に突入する。水曜日にライブ配信された製品発表会で、共同ノート作成アプリで知られるNotionは、カスタムAIエージェントの機能を拡張し、外部エージェントと連携し、あらゆるデータベースからデータを取得できる自動化された多段階ワークフローをチームが構築できるようにする新しい開発者向けプラットフォームを発表した。複数のツールやデータソー
関連特集おすすめ
書き込み
 ラジオおよびポッドキャスト用の最適なAIスクリプティングツール:魅力的なオーディオコマーシャルを作成する
ラジオおよびポッドキャスト用の最適なAIスクリプティングツール:魅力的なオーディオコマーシャルを作成する
XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
 10 ツール
10 ツール
 xix.ai
仕事
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
xix.ai
仕事
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai
アニメーション制作
東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai
漫画制作
漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
書き込み
AI小説プロファイル作成のトップクリエイター:一貫性のあるキャラクターの動機と致命的な欠点を生成する
深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai
仕事
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
3月19日、Cursorは自社開発のコーディングモデル「Composer 2」を正式にリリースした。 この発表は開発者コミュニティで即座に議論を巻き起こした。Cursorによると、Composer 2はTerminal-Bench 2.0で61.7%のスコアを記録し、同一のテスト条件下でClaude Opus 4.6の58.0%を大幅に上回ったという。
Anthropicのフラッグシップモデルが、自社のIDEに組み込まれたモデルに性能で敗れたのか?このニュースが広まるにつれ、議論が急速に巻き起こった。
3つの主要なベンチマーク結果
Cursorは3つのベンチマーク結果セットを公開し、いずれも一般に公開されています:
Terminal-Bench 2.0(エージェントスタイルのターミナルコーディングタスク):Composer 2は61.7%を記録し、Claude Opus 4.6の58.0%を上回った。 しかし、OpenAIのGPT-5.4は75.1%で依然としてトップを維持している。CursorBench(Cursor内での実世界コーディングシナリオ): Composer 2は61.3%を記録し、前バージョンのComposer 1.5の44.2%から大幅な向上を見せたほか、Claude Opus 4.6の58.2%をも上回った。SWE-bench Multilingual(多言語ソフトウェアエンジニアリング): Composer 2は73.7%を達成し、前世代モデルから著しい改善が見られた。ただし、1点注目すべき点がある。Anthropicは以前、最適化された設定下でClaude Opus 4.6がTerminal-Bench 2.0において65.4%のスコアを記録したと報告しており、これはCursorが引用した58.0%を大幅に上回る数値である。 この相違はテスト環境に起因する。CursorはHarborのようなサードパーティ製エージェント環境を使用し、5回の実行結果の平均を算出したのに対し、Anthropicの数値は自社独自の最適化された構成によるものである。これらは異なる基準体系を用いているため、両者の数値を直接比較することはできない。 Cursorはこの点を隠そうとはしなかった。発表文では、「結果はエージェント、ハーネス、および設定に依存する」と明示されていた。
Opus 4.6のわずか10分の1のコスト
コストパフォーマンスこそが、Composer 2の真の隠れた強みです。
入力/出力トークン100万単位あたりの価格が0.50ドル/2.50ドルであるのに対し、Claude Opus 4.6は5ドル/25ドル、GPT-5.4は2.5ドル/15ドルであり、その対比は際立っている。 Cursor社によると、Composer 2は長期的なコーディングタスクのためにゼロから構築され、独自のRL(強化学習)トレーニングと「自己要約」技術を用いて、レイテンシとコストの両方を低減しているとのことです。同社はこれを「フロンティア・インテリジェンス+極限のスピード」と表現しています。
Composer 2は、Composer 1(2025年10月)およびバージョン1.5(2026年2月)に続く、Cursorの3番目の自社開発モデルです。今回のリリースでは「長期的なタスク」に重点が置かれており、より高速で軽量なバリエーションがCursor IDEのデフォルトモデルとなっています。
この「灰からの復活」が意味するもの
Cursorが自社のモデルをOpus 4.6と直接比較するという決断は、AIコーディングツール業界全体の動向に変化が生じていることを示唆している。
OpenAIやAnthropicが汎用的な最先端機能で競い合う一方、Cursorのような垂直型ツールプロバイダーは異なる道を選んでいます。それは、特定のタスクにおける性能を卓越したレベルまで磨き上げ、価格面での優位性を活かして差別化を図るというものです。 VentureBeatやThe New Stackなどのメディアは、Composer 2が「マルチモデル・ルーティング」の実用化を加速させると指摘しています。これは、複雑な推論にはOpusやGPTを使用し、日常的な高頻度のコーディングにはComposer 2に切り替えることで、双方の利点を享受する手法です。
2月5日にリリースされたClaude Opus 4.6は、Terminal-Bench 2.0、Humanity's Last Exam、GDPval-AAを含む複数のベンチマークで首位を獲得した。Cursorの新たな結果は、少なくともこの専門的なコーディング分野におけるその優位性に疑問を投げかけている。
現時点での開発者の反応は概ね好意的だが、結論を出す前に実際のプロジェクトでのパフォーマンスを確認したいという声も多い。ベンチマークはあくまでベンチマークに過ぎないため、これは妥当な姿勢だ。Cursorはすでに、サブスクリプションユーザー向けにIDE内でComposer 2の無料トライアルを提供している。
データソース:Cursorの公式発表および主要テックメディア(2026年3月20日時点)。現在のランキングはtbench.aiまたはCursorのウェブサイトで確認できます。










 Baidu Healthは、学術情報の検索や事務支援を目的としたAI医師アシスタント「DoctorClaw」を、短期的に社内テストしている。
報道によると、百度健康(Baidu Health)は、医師向けに設計された専門的なAIスマートアシスタントの社内テストを開始した。社内で「DoctorClaw」(ロブスター・ドクター版)と呼ばれるこの製品は、医療分野における百度の大規模言語モデルの展開において、重要な一歩となるものだ。関係者によると、このプロジェクトは依然として非公開の開発段階にあり、現在は社内テスト段階に入っている。具体的な製品
Baidu Healthは、学術情報の検索や事務支援を目的としたAI医師アシスタント「DoctorClaw」を、短期的に社内テストしている。
報道によると、百度健康(Baidu Health)は、医師向けに設計された専門的なAIスマートアシスタントの社内テストを開始した。社内で「DoctorClaw」(ロブスター・ドクター版)と呼ばれるこの製品は、医療分野における百度の大規模言語モデルの展開において、重要な一歩となるものだ。関係者によると、このプロジェクトは依然として非公開の開発段階にあり、現在は社内テスト段階に入っている。具体的な製品
 「StrictlyVC サンフランシスコ」に、TDKベンチャーズやReplitなどのリーダーが集結
今年最初のStrictlyVCイベントが、あっという間にサンフランシスコで開催されます。 4月30日にセントロ・フィリピーノ・カルチュラル・センターで開催される本イベントのチケットは、現在も販売中です。豪華なスピーカー陣が登壇するこのイベントでは、StrictlyVCならではのネットワーキングやコミュニティ交流に加え、資金調達に関する最新の知見を求めるAI分野のイノベーターや起業家の方々にとって、
「StrictlyVC サンフランシスコ」に、TDKベンチャーズやReplitなどのリーダーが集結
今年最初のStrictlyVCイベントが、あっという間にサンフランシスコで開催されます。 4月30日にセントロ・フィリピーノ・カルチュラル・センターで開催される本イベントのチケットは、現在も販売中です。豪華なスピーカー陣が登壇するこのイベントでは、StrictlyVCならではのネットワーキングやコミュニティ交流に加え、資金調達に関する最新の知見を求めるAI分野のイノベーターや起業家の方々にとって、
 Notionは、ワークスペースをAIエージェントのハブへと変革します
生産性向上ソフトウェア企業であるNotionが、「エージェント時代」に突入する。水曜日にライブ配信された製品発表会で、共同ノート作成アプリで知られるNotionは、カスタムAIエージェントの機能を拡張し、外部エージェントと連携し、あらゆるデータベースからデータを取得できる自動化された多段階ワークフローをチームが構築できるようにする新しい開発者向けプラットフォームを発表した。複数のツールやデータソー
Notionは、ワークスペースをAIエージェントのハブへと変革します
生産性向上ソフトウェア企業であるNotionが、「エージェント時代」に突入する。水曜日にライブ配信された製品発表会で、共同ノート作成アプリで知られるNotionは、カスタムAIエージェントの機能を拡張し、外部エージェントと連携し、あらゆるデータベースからデータを取得できる自動化された多段階ワークフローをチームが構築できるようにする新しい開発者向けプラットフォームを発表した。複数のツールやデータソー

XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
10 ツール
xix.ai

XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai

2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai

XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai













