
















 Hogar
Hogar
Cursor Composer 2 frente a Claude Opus 4.6: una prueba de rendimiento reaviva el debate sobre la programación con IA
El 19 de marzo, Cursor lanzó oficialmente su modelo de programación propio, Composer 2. El anuncio desató un debate inmediato en la comunidad de desarrolladores: según Cursor, Composer 2 obtuvo una puntuación del 61,7 % en Terminal-Bench 2.0, superando notablemente el 58,0 % de Claude Opus 4.6 en condiciones de prueba idénticas.
¿Ha sido superado el modelo insignia de Anthropic por un modelo integrado en su propio IDE? A medida que se difundía la noticia, surgieron rápidamente los debates.
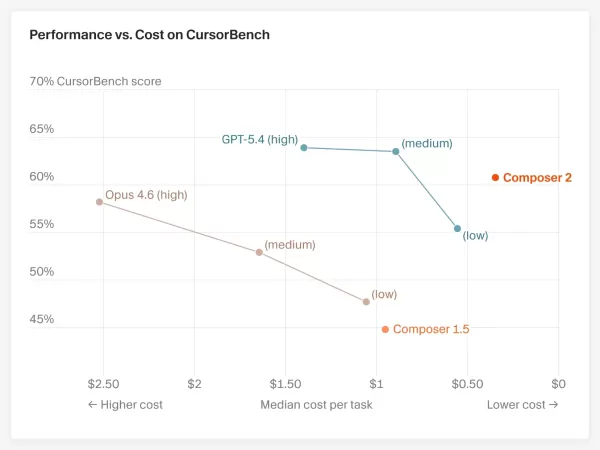
Tres resultados clave de las pruebas de rendimiento
Cursor publicó tres conjuntos de resultados de pruebas de rendimiento, todos ellos de dominio público:
Terminal-Bench 2.0 (tareas de programación en terminal de tipo agente): Composer 2 obtuvo una puntuación del 61,7 %, superando el 58,0 %de Claude Opus 4.6. Sin embargo, OpenAI GPT-5.4 sigue a la cabeza con un 75,1 %. CursorBench (escenarios de programación del mundo real dentro de Cursor): Composer 2 alcanzó el 61,3 %, un salto sustancial respecto al 44,2 % del anterior Composer 1.5, y también superior al 58,2 %de Claude Opus 4.6. SWE-bench Multilingual (ingeniería de software multilingüe): Composer 2 alcanzó el 73,7 %, una mejora notable con respecto a su predecesor.Sin embargo, hay un detalle que merece la pena destacar: Anthropic informó anteriormente de que Claude Opus 4.6 obtuvo un 65,4 % en Terminal-Bench 2.0 con una configuración optimizada, una cifra muy superior al 58,0 % citado por Cursor. La discrepancia se debe al marco de pruebas: Cursor utilizó entornos de agentes de terceros como Harbor y promedió los resultados de cinco ejecuciones, mientras que las cifras de Anthropic procedían de su propia configuración optimizada. Estos dos conjuntos de cifras no son directamente comparables, ya que utilizan sistemas de referencia diferentes. Cursor no eludió este tema; el comunicado indicaba explícitamente que «los resultados dependen del agente, el arnés y la configuración».
Un coste de solo una décima parte del de Opus 4.6
La rentabilidad es la verdadera ventaja oculta de Composer 2.
Con un precio de 0,50 $ / 2,50 $ por millón de tokens de entrada/salida, frente a los 5 $ / 25 $ de Claude Opus 4.6 y los 2,5 $ / 15 $ de GPT-5.4, el contraste es marcado. Cursor explica que Composer 2 se ha diseñado desde cero para tareas de codificación a largo plazo, utilizando su entrenamiento RL patentado y su tecnología de «auto-resumen» para reducir tanto la latencia como el coste, lo que describen como «inteligencia de vanguardia + velocidad extrema».
Composer 2 es el tercer modelo propio de Cursor, sucesor de Composer 1 (octubre de 2025) y de la versión 1.5 (febrero de 2026). Este lanzamiento hace hincapié en las «tareas a largo plazo» y convierte una variante más rápida y ligera en el modelo predeterminado del IDE de Cursor.
Qué significa este «resurgimiento de sus cenizas»
La decisión de Cursor de comparar directamente su modelo con Opus 4.6 marca un cambio en el panorama general de las herramientas de programación de IA.
OpenAI y Anthropic compiten en capacidades generales de vanguardia, mientras que los proveedores de herramientas verticales como Cursor han tomado un camino diferente: perfeccionar el rendimiento en tareas específicas hasta un nivel excepcional y luego utilizar las ventajas de precio para destacar. Medios de comunicación como VentureBeat y The New Stack señalaron que Composer 2 acelerará la implantación práctica del «enrutamiento multimodelo»: utilizar Opus o GPT para el razonamiento complejo y cambiar a Composer 2 para la programación cotidiana y de alta frecuencia, obteniendo beneficios en ambos frentes.
Claude Opus 4.6 se lanzó el 5 de febrero y lideró varias pruebas de rendimiento, entre ellas Terminal-Bench 2.0, Humanity's Last Exam y GDPval-AA. Los nuevos resultados de Cursor, como mínimo, plantean dudas sobre ese dominio en el segmento de la codificación especializada.
La respuesta de los desarrolladores ha sido en gran medida positiva hasta ahora, pero muchos afirman que quieren ver el rendimiento en proyectos del mundo real antes de sacar conclusiones, una postura razonable, ya que las pruebas de rendimiento no son más que eso. Cursor ya ha puesto Composer 2 a disposición de los usuarios con suscripción para una prueba gratuita dentro del IDE.
Fuente de datos: Anuncios oficiales de Cursor y principales medios tecnológicos, a 20 de marzo de 2026. Las clasificaciones actuales pueden consultarse en tbench.ai o en la página web de Cursor.
Artículo relacionado
 Baidu Health prueba internamente el asistente médico basado en IA «DoctorClaw» para la búsqueda de información académica y la asistencia administrativa a corto plazo
Según se ha informado, Baidu Health ha iniciado las pruebas internas de un asistente inteligente con IA profesional diseñado para médicos. Conocido internamente como «DoctorClaw» (la versión «Lobster
StrictlyVC San Francisco reunirá a líderes de TDK Ventures, Replit y otras empresas
El primer evento de StrictlyVC del año llega a San Francisco antes de lo que imaginas. Aún quedan entradas disponibles para nuestro encuentro del 30 de abril en el Centro Cultural Filipino Sentro, que
Notion convierte su espacio de trabajo en un centro para agentes de IA
Notion, la empresa de software de productividad, se adentra en la era de los agentes.Durante un anuncio de producto retransmitido en directo el miércoles, Notion —conocida sobre todo por su aplicación
Recomendaciones de temas especiales relacionados
escribiendo
Baidu Health prueba internamente el asistente médico basado en IA «DoctorClaw» para la búsqueda de información académica y la asistencia administrativa a corto plazo
Según se ha informado, Baidu Health ha iniciado las pruebas internas de un asistente inteligente con IA profesional diseñado para médicos. Conocido internamente como «DoctorClaw» (la versión «Lobster
StrictlyVC San Francisco reunirá a líderes de TDK Ventures, Replit y otras empresas
El primer evento de StrictlyVC del año llega a San Francisco antes de lo que imaginas. Aún quedan entradas disponibles para nuestro encuentro del 30 de abril en el Centro Cultural Filipino Sentro, que
Notion convierte su espacio de trabajo en un centro para agentes de IA
Notion, la empresa de software de productividad, se adentra en la era de los agentes.Durante un anuncio de producto retransmitido en directo el miércoles, Notion —conocida sobre todo por su aplicación
Recomendaciones de temas especiales relacionados
escribiendo
 Los mejores herramientas de scripting AI para la radio y los podcasts: Crea anuncios de audio atractivos.
Los mejores herramientas de scripting AI para la radio y los podcasts: Crea anuncios de audio atractivos.
Descubra los mejores herramientas de scripting de IA para la radio y los podcasts en 2026 en XIX.AI. Nuestra lista seleccionada y altamente valorada incluye soluciones poderosas que cambiarán completamente la forma en que crea anuncios de audio atractivos. Compare opciones gratuitas y pagadas mediante pruebas reales y clasificaciones actualizadas semanalmente. ¡Despliegue todo su potencial creativo hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Negocio
El mejor software de revisión de contratos con IA: detecta al instante las lagunas legales y los riesgos de cumplimiento normativo
xix.ai
Negocio
El mejor software de revisión de contratos con IA: detecta al instante las lagunas legales y los riesgos de cumplimiento normativo
Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
10 herramientas
xix.ai
Creación de animación
Generador de anime AI para Donghua: Crea personajes para novelas web y avatares para cómics
Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai
Negocio
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
El 19 de marzo, Cursor lanzó oficialmente su modelo de programación propio, Composer 2. El anuncio desató un debate inmediato en la comunidad de desarrolladores: según Cursor, Composer 2 obtuvo una puntuación del 61,7 % en Terminal-Bench 2.0, superando notablemente el 58,0 % de Claude Opus 4.6 en condiciones de prueba idénticas.
¿Ha sido superado el modelo insignia de Anthropic por un modelo integrado en su propio IDE? A medida que se difundía la noticia, surgieron rápidamente los debates.
Tres resultados clave de las pruebas de rendimiento
Cursor publicó tres conjuntos de resultados de pruebas de rendimiento, todos ellos de dominio público:
Terminal-Bench 2.0 (tareas de programación en terminal de tipo agente): Composer 2 obtuvo una puntuación del 61,7 %, superando el 58,0 %de Claude Opus 4.6. Sin embargo, OpenAI GPT-5.4 sigue a la cabeza con un 75,1 %. CursorBench (escenarios de programación del mundo real dentro de Cursor): Composer 2 alcanzó el 61,3 %, un salto sustancial respecto al 44,2 % del anterior Composer 1.5, y también superior al 58,2 %de Claude Opus 4.6. SWE-bench Multilingual (ingeniería de software multilingüe): Composer 2 alcanzó el 73,7 %, una mejora notable con respecto a su predecesor.Sin embargo, hay un detalle que merece la pena destacar: Anthropic informó anteriormente de que Claude Opus 4.6 obtuvo un 65,4 % en Terminal-Bench 2.0 con una configuración optimizada, una cifra muy superior al 58,0 % citado por Cursor. La discrepancia se debe al marco de pruebas: Cursor utilizó entornos de agentes de terceros como Harbor y promedió los resultados de cinco ejecuciones, mientras que las cifras de Anthropic procedían de su propia configuración optimizada. Estos dos conjuntos de cifras no son directamente comparables, ya que utilizan sistemas de referencia diferentes. Cursor no eludió este tema; el comunicado indicaba explícitamente que «los resultados dependen del agente, el arnés y la configuración».
Un coste de solo una décima parte del de Opus 4.6
La rentabilidad es la verdadera ventaja oculta de Composer 2.
Con un precio de 0,50 $ / 2,50 $ por millón de tokens de entrada/salida, frente a los 5 $ / 25 $ de Claude Opus 4.6 y los 2,5 $ / 15 $ de GPT-5.4, el contraste es marcado. Cursor explica que Composer 2 se ha diseñado desde cero para tareas de codificación a largo plazo, utilizando su entrenamiento RL patentado y su tecnología de «auto-resumen» para reducir tanto la latencia como el coste, lo que describen como «inteligencia de vanguardia + velocidad extrema».
Composer 2 es el tercer modelo propio de Cursor, sucesor de Composer 1 (octubre de 2025) y de la versión 1.5 (febrero de 2026). Este lanzamiento hace hincapié en las «tareas a largo plazo» y convierte una variante más rápida y ligera en el modelo predeterminado del IDE de Cursor.
Qué significa este «resurgimiento de sus cenizas»
La decisión de Cursor de comparar directamente su modelo con Opus 4.6 marca un cambio en el panorama general de las herramientas de programación de IA.
OpenAI y Anthropic compiten en capacidades generales de vanguardia, mientras que los proveedores de herramientas verticales como Cursor han tomado un camino diferente: perfeccionar el rendimiento en tareas específicas hasta un nivel excepcional y luego utilizar las ventajas de precio para destacar. Medios de comunicación como VentureBeat y The New Stack señalaron que Composer 2 acelerará la implantación práctica del «enrutamiento multimodelo»: utilizar Opus o GPT para el razonamiento complejo y cambiar a Composer 2 para la programación cotidiana y de alta frecuencia, obteniendo beneficios en ambos frentes.
Claude Opus 4.6 se lanzó el 5 de febrero y lideró varias pruebas de rendimiento, entre ellas Terminal-Bench 2.0, Humanity's Last Exam y GDPval-AA. Los nuevos resultados de Cursor, como mínimo, plantean dudas sobre ese dominio en el segmento de la codificación especializada.
La respuesta de los desarrolladores ha sido en gran medida positiva hasta ahora, pero muchos afirman que quieren ver el rendimiento en proyectos del mundo real antes de sacar conclusiones, una postura razonable, ya que las pruebas de rendimiento no son más que eso. Cursor ya ha puesto Composer 2 a disposición de los usuarios con suscripción para una prueba gratuita dentro del IDE.
Fuente de datos: Anuncios oficiales de Cursor y principales medios tecnológicos, a 20 de marzo de 2026. Las clasificaciones actuales pueden consultarse en tbench.ai o en la página web de Cursor.










 Baidu Health prueba internamente el asistente médico basado en IA «DoctorClaw» para la búsqueda de información académica y la asistencia administrativa a corto plazo
Según se ha informado, Baidu Health ha iniciado las pruebas internas de un asistente inteligente con IA profesional diseñado para médicos. Conocido internamente como «DoctorClaw» (la versión «Lobster
Baidu Health prueba internamente el asistente médico basado en IA «DoctorClaw» para la búsqueda de información académica y la asistencia administrativa a corto plazo
Según se ha informado, Baidu Health ha iniciado las pruebas internas de un asistente inteligente con IA profesional diseñado para médicos. Conocido internamente como «DoctorClaw» (la versión «Lobster
 StrictlyVC San Francisco reunirá a líderes de TDK Ventures, Replit y otras empresas
El primer evento de StrictlyVC del año llega a San Francisco antes de lo que imaginas. Aún quedan entradas disponibles para nuestro encuentro del 30 de abril en el Centro Cultural Filipino Sentro, que
StrictlyVC San Francisco reunirá a líderes de TDK Ventures, Replit y otras empresas
El primer evento de StrictlyVC del año llega a San Francisco antes de lo que imaginas. Aún quedan entradas disponibles para nuestro encuentro del 30 de abril en el Centro Cultural Filipino Sentro, que
 Notion convierte su espacio de trabajo en un centro para agentes de IA
Notion, la empresa de software de productividad, se adentra en la era de los agentes.Durante un anuncio de producto retransmitido en directo el miércoles, Notion —conocida sobre todo por su aplicación
Notion convierte su espacio de trabajo en un centro para agentes de IA
Notion, la empresa de software de productividad, se adentra en la era de los agentes.Durante un anuncio de producto retransmitido en directo el miércoles, Notion —conocida sobre todo por su aplicación

Descubra los mejores herramientas de scripting de IA para la radio y los podcasts en 2026 en XIX.AI. Nuestra lista seleccionada y altamente valorada incluye soluciones poderosas que cambiarán completamente la forma en que crea anuncios de audio atractivos. Compare opciones gratuitas y pagadas mediante pruebas reales y clasificaciones actualizadas semanalmente. ¡Despliegue todo su potencial creativo hoy mismo!
10 herramientas
xix.ai

Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
10 herramientas
xix.ai

Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai

Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai













