
















 Heim
Heim
Cursor Composer 2 vs. Claude Opus 4.6: Benchmark-Test entfacht neue Debatte über KI-Programmierung
Am 19. März veröffentlichte Cursor offiziell sein hauseigenes Programmiermodell Composer 2. Die Ankündigung löste in der Entwickler-Community sofort Diskussionen aus – laut Cursor erzielte Composer 2 bei Terminal-Bench 2.0 eine Punktzahl von 61,7 % und übertraf damit deutlich die 58,0 % von Claude Opus 4.6 unter identischen Testbedingungen.
Wurde das Flaggschiff-Modell von Anthropic von einem Modell übertroffen, das in die eigene IDE integriert ist? Als sich die Nachricht verbreitete, entbrannten schnell Debatten.
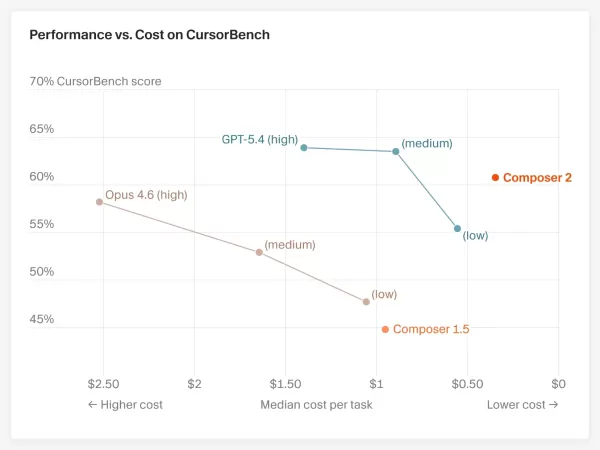
Drei wichtige Benchmark-Ergebnisse
Cursor veröffentlichte drei Sätze von Benchmark-Ergebnissen, die alle öffentlich zugänglich sind:
Terminal-Bench 2.0 (Terminal-Codierungsaufgaben im Agent-Stil): Composer 2 erzielte 61,7 % und schlug damit die 58,0 %von Claude Opus 4.6. OpenAI GPT-5.4 liegt jedoch mit 75,1 %weiterhin vorne. CursorBench (realistische Programmier-Szenarien innerhalb von Cursor): Composer 2 erreichte 61,3 %, was einen deutlichen Sprung gegenüber den 44,2 % des Vorgängers Composer 1.5 darstellt und auch über den 58,2 %von Claude Opus 4.6 liegt. SWE-bench Multilingual (mehrsprachige Softwareentwicklung): Composer 2 erreichte 73,7 %, eine bemerkenswerte Verbesserung gegenüber seinem Vorgänger.Ein Detail ist jedoch erwähnenswert: Anthropic berichtete zuvor, dass Claude Opus 4.6 unter optimierten Einstellungen 65,4 % auf Terminal-Bench 2.0 erzielte, was deutlich über den von Cursor genannten 58,0 % liegt. Die Diskrepanz rührt vom Testframework her – Cursor verwendete Agent-Umgebungen von Drittanbietern wie Harbor und mittelte die Ergebnisse aus fünf Durchläufen, während die Zahlen von Anthropic aus der eigenen optimierten Konfiguration stammten. Diese beiden Zahlenreihen sind nicht direkt vergleichbar, da sie unterschiedliche Referenzsysteme verwenden. Cursor hat dies nicht verschwiegen; in der Ankündigung wurde ausdrücklich darauf hingewiesen, dass „die Ergebnisse vom Agenten, dem Test-Harness und den Einstellungen abhängen“.
Kosten bei nur einem Zehntel von Opus 4.6
Die Kosteneffizienz ist der wahre versteckte Vorteil von Composer 2.
Mit einem Preis von 0,50 $ / 2,50 $ pro Million Input-/Output-Token im Vergleich zu 5 $ / 25 $ bei Claude Opus 4.6 und 2,5 $ / 15 $ bei GPT-5.4 ist der Kontrast eklatant. Cursor erklärt, dass Composer 2 von Grund auf für Codierungsaufgaben mit langfristigem Horizont entwickelt wurde und dabei seine proprietäre RL-Trainings- und „Selbstzusammenfassungs“-Technologie nutzt, um sowohl Latenz als auch Kosten zu senken – was sie als „Frontier Intelligence + extreme Geschwindigkeit“ bezeichnen.
Composer 2 ist das dritte hauseigene Modell von Cursor und folgt auf Composer 1 (Oktober 2025) und Version 1.5 (Februar 2026). Diese Version legt den Schwerpunkt auf „langfristige Aufgaben“ und macht eine schnellere, schlankere Variante zum Standardmodell in der Cursor-IDE.
Was dieser „Aufstieg aus der Asche“ bedeutet
Die Entscheidung von Cursor, sein Modell direkt mit Opus 4.6 zu vergleichen, signalisiert eine Verschiebung in der breiteren Landschaft der KI-Codierungstools.
OpenAI und Anthropic konkurrieren um allgemeine Spitzenleistungen, während vertikale Tool-Anbieter wie Cursor einen anderen Weg eingeschlagen haben: Sie optimieren die Leistung bei spezifischen Aufgaben auf ein außergewöhnliches Niveau und nutzen dann Preisvorteile, um sich abzuheben. Medien wie VentureBeat und The New Stack stellten fest, dass Composer 2 die praktische Einführung von „Multi-Model-Routing“ beschleunigen wird – wobei Opus oder GPT für komplexe Schlussfolgerungen genutzt werden und für alltägliche, hochfrequente Programmieraufgaben auf Composer 2 umgeschaltet wird, um so Vorteile auf beiden Seiten zu erzielen.
Claude Opus 4.6 wurde am 5. Februar veröffentlicht und führte in mehreren Benchmarks, darunter Terminal-Bench 2.0, Humanity’s Last Exam und GDPval-AA. Die neuen Ergebnisse von Cursor werfen zumindest Fragen hinsichtlich dieser Dominanz im spezialisierten Programmierbereich auf.
Die Reaktionen der Entwickler waren bisher überwiegend positiv, doch viele geben an, dass sie erst die Leistung in realen Projekten sehen wollen, bevor sie Schlussfolgerungen ziehen – eine berechtigte Haltung, da Benchmarks eben nur Benchmarks sind. Cursor hat Composer 2 für Abonnenten bereits als kostenlose Testversion innerhalb der IDE zur Verfügung gestellt.
Datenquelle: Offizielle Ankündigungen von Cursor und führende Tech-Medien, Stand: 20. März 2026. Aktuelle Ranglisten können unter tbench.ai oder auf der Website von Cursor eingesehen werden.
Verwandter Artikel
 Baidu Health testet intern den KI-Arztassistenten „DoctorClaw“ für die Recherche wissenschaftlicher Informationen und die Unterstützung im Büro auf kurze Sicht
Baidu Health hat Berichten zufolge mit internen Tests eines professionellen KI-Assistenten für Ärzte begonnen. Das intern als „DoctorClaw“ (die „Lobster Doctor“-Version) bezeichnete Produkt stellt ein
StrictlyVC San Francisco versammelt Führungskräfte von TDK Ventures, Replit und anderen Unternehmen
Die erste StrictlyVC-Veranstaltung des Jahres findet schon früher in San Francisco statt, als Sie denken. Es sind noch Tickets für unser Treffen am 30. April im Sentro Filipino Cultural Center erhältl
Notion verwandelt seinen Arbeitsbereich in eine Drehscheibe für KI-Agenten
Notion, der Anbieter von Produktivitätssoftware, tritt in das Zeitalter der agentenbasierten Lösungen ein.Während einer live gestreamten Produktankündigung am Mittwoch stellte Notion – bekannt für sei
Empfehlungen zu verwandten Spezialthemen
Schreiben
Baidu Health testet intern den KI-Arztassistenten „DoctorClaw“ für die Recherche wissenschaftlicher Informationen und die Unterstützung im Büro auf kurze Sicht
Baidu Health hat Berichten zufolge mit internen Tests eines professionellen KI-Assistenten für Ärzte begonnen. Das intern als „DoctorClaw“ (die „Lobster Doctor“-Version) bezeichnete Produkt stellt ein
StrictlyVC San Francisco versammelt Führungskräfte von TDK Ventures, Replit und anderen Unternehmen
Die erste StrictlyVC-Veranstaltung des Jahres findet schon früher in San Francisco statt, als Sie denken. Es sind noch Tickets für unser Treffen am 30. April im Sentro Filipino Cultural Center erhältl
Notion verwandelt seinen Arbeitsbereich in eine Drehscheibe für KI-Agenten
Notion, der Anbieter von Produktivitätssoftware, tritt in das Zeitalter der agentenbasierten Lösungen ein.Während einer live gestreamten Produktankündigung am Mittwoch stellte Notion – bekannt für sei
Empfehlungen zu verwandten Spezialthemen
Schreiben
 Die besten AI-Skripting-Tools für Radio und Podcasting: Erstellen Sie ansprechende Audowerbung.
Die besten AI-Skripting-Tools für Radio und Podcasting: Erstellen Sie ansprechende Audowerbung.
Entdecken Sie die besten KI-Skripting-Tools für Radio und Podcasting im Jahr 2026 bei XIX.AI. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, mit denen Sie ansprechende Audio-Werbespots schnell erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie noch heute Ihr kreatives Potenzial!
 10 Tools
10 Tools
 xix.ai
Geschäft
Die beste KI-Software zur Vertragsprüfung: Erkennen Sie rechtliche Lücken und Compliance-Risiken sofort
xix.ai
Geschäft
Die beste KI-Software zur Vertragsprüfung: Erkennen Sie rechtliche Lücken und Compliance-Risiken sofort
Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
10 Tools
xix.ai
Animationserstellung
AI-Anime-Generator für Donghua: Erstellen Sie Charaktere für Web-Romane und Comic-Avatare
Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai
Geschäft
Die beste Software zur Preisoptimierung mittels KI: Beobachten Sie die Konkurrenz und passen Sie Ihre Shop-Preise automatisch an
Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Am 19. März veröffentlichte Cursor offiziell sein hauseigenes Programmiermodell Composer 2. Die Ankündigung löste in der Entwickler-Community sofort Diskussionen aus – laut Cursor erzielte Composer 2 bei Terminal-Bench 2.0 eine Punktzahl von 61,7 % und übertraf damit deutlich die 58,0 % von Claude Opus 4.6 unter identischen Testbedingungen.
Wurde das Flaggschiff-Modell von Anthropic von einem Modell übertroffen, das in die eigene IDE integriert ist? Als sich die Nachricht verbreitete, entbrannten schnell Debatten.
Drei wichtige Benchmark-Ergebnisse
Cursor veröffentlichte drei Sätze von Benchmark-Ergebnissen, die alle öffentlich zugänglich sind:
Terminal-Bench 2.0 (Terminal-Codierungsaufgaben im Agent-Stil): Composer 2 erzielte 61,7 % und schlug damit die 58,0 %von Claude Opus 4.6. OpenAI GPT-5.4 liegt jedoch mit 75,1 %weiterhin vorne. CursorBench (realistische Programmier-Szenarien innerhalb von Cursor): Composer 2 erreichte 61,3 %, was einen deutlichen Sprung gegenüber den 44,2 % des Vorgängers Composer 1.5 darstellt und auch über den 58,2 %von Claude Opus 4.6 liegt. SWE-bench Multilingual (mehrsprachige Softwareentwicklung): Composer 2 erreichte 73,7 %, eine bemerkenswerte Verbesserung gegenüber seinem Vorgänger.Ein Detail ist jedoch erwähnenswert: Anthropic berichtete zuvor, dass Claude Opus 4.6 unter optimierten Einstellungen 65,4 % auf Terminal-Bench 2.0 erzielte, was deutlich über den von Cursor genannten 58,0 % liegt. Die Diskrepanz rührt vom Testframework her – Cursor verwendete Agent-Umgebungen von Drittanbietern wie Harbor und mittelte die Ergebnisse aus fünf Durchläufen, während die Zahlen von Anthropic aus der eigenen optimierten Konfiguration stammten. Diese beiden Zahlenreihen sind nicht direkt vergleichbar, da sie unterschiedliche Referenzsysteme verwenden. Cursor hat dies nicht verschwiegen; in der Ankündigung wurde ausdrücklich darauf hingewiesen, dass „die Ergebnisse vom Agenten, dem Test-Harness und den Einstellungen abhängen“.
Kosten bei nur einem Zehntel von Opus 4.6
Die Kosteneffizienz ist der wahre versteckte Vorteil von Composer 2.
Mit einem Preis von 0,50 $ / 2,50 $ pro Million Input-/Output-Token im Vergleich zu 5 $ / 25 $ bei Claude Opus 4.6 und 2,5 $ / 15 $ bei GPT-5.4 ist der Kontrast eklatant. Cursor erklärt, dass Composer 2 von Grund auf für Codierungsaufgaben mit langfristigem Horizont entwickelt wurde und dabei seine proprietäre RL-Trainings- und „Selbstzusammenfassungs“-Technologie nutzt, um sowohl Latenz als auch Kosten zu senken – was sie als „Frontier Intelligence + extreme Geschwindigkeit“ bezeichnen.
Composer 2 ist das dritte hauseigene Modell von Cursor und folgt auf Composer 1 (Oktober 2025) und Version 1.5 (Februar 2026). Diese Version legt den Schwerpunkt auf „langfristige Aufgaben“ und macht eine schnellere, schlankere Variante zum Standardmodell in der Cursor-IDE.
Was dieser „Aufstieg aus der Asche“ bedeutet
Die Entscheidung von Cursor, sein Modell direkt mit Opus 4.6 zu vergleichen, signalisiert eine Verschiebung in der breiteren Landschaft der KI-Codierungstools.
OpenAI und Anthropic konkurrieren um allgemeine Spitzenleistungen, während vertikale Tool-Anbieter wie Cursor einen anderen Weg eingeschlagen haben: Sie optimieren die Leistung bei spezifischen Aufgaben auf ein außergewöhnliches Niveau und nutzen dann Preisvorteile, um sich abzuheben. Medien wie VentureBeat und The New Stack stellten fest, dass Composer 2 die praktische Einführung von „Multi-Model-Routing“ beschleunigen wird – wobei Opus oder GPT für komplexe Schlussfolgerungen genutzt werden und für alltägliche, hochfrequente Programmieraufgaben auf Composer 2 umgeschaltet wird, um so Vorteile auf beiden Seiten zu erzielen.
Claude Opus 4.6 wurde am 5. Februar veröffentlicht und führte in mehreren Benchmarks, darunter Terminal-Bench 2.0, Humanity’s Last Exam und GDPval-AA. Die neuen Ergebnisse von Cursor werfen zumindest Fragen hinsichtlich dieser Dominanz im spezialisierten Programmierbereich auf.
Die Reaktionen der Entwickler waren bisher überwiegend positiv, doch viele geben an, dass sie erst die Leistung in realen Projekten sehen wollen, bevor sie Schlussfolgerungen ziehen – eine berechtigte Haltung, da Benchmarks eben nur Benchmarks sind. Cursor hat Composer 2 für Abonnenten bereits als kostenlose Testversion innerhalb der IDE zur Verfügung gestellt.
Datenquelle: Offizielle Ankündigungen von Cursor und führende Tech-Medien, Stand: 20. März 2026. Aktuelle Ranglisten können unter tbench.ai oder auf der Website von Cursor eingesehen werden.










 Baidu Health testet intern den KI-Arztassistenten „DoctorClaw“ für die Recherche wissenschaftlicher Informationen und die Unterstützung im Büro auf kurze Sicht
Baidu Health hat Berichten zufolge mit internen Tests eines professionellen KI-Assistenten für Ärzte begonnen. Das intern als „DoctorClaw“ (die „Lobster Doctor“-Version) bezeichnete Produkt stellt ein
Baidu Health testet intern den KI-Arztassistenten „DoctorClaw“ für die Recherche wissenschaftlicher Informationen und die Unterstützung im Büro auf kurze Sicht
Baidu Health hat Berichten zufolge mit internen Tests eines professionellen KI-Assistenten für Ärzte begonnen. Das intern als „DoctorClaw“ (die „Lobster Doctor“-Version) bezeichnete Produkt stellt ein
 StrictlyVC San Francisco versammelt Führungskräfte von TDK Ventures, Replit und anderen Unternehmen
Die erste StrictlyVC-Veranstaltung des Jahres findet schon früher in San Francisco statt, als Sie denken. Es sind noch Tickets für unser Treffen am 30. April im Sentro Filipino Cultural Center erhältl
StrictlyVC San Francisco versammelt Führungskräfte von TDK Ventures, Replit und anderen Unternehmen
Die erste StrictlyVC-Veranstaltung des Jahres findet schon früher in San Francisco statt, als Sie denken. Es sind noch Tickets für unser Treffen am 30. April im Sentro Filipino Cultural Center erhältl
 Notion verwandelt seinen Arbeitsbereich in eine Drehscheibe für KI-Agenten
Notion, der Anbieter von Produktivitätssoftware, tritt in das Zeitalter der agentenbasierten Lösungen ein.Während einer live gestreamten Produktankündigung am Mittwoch stellte Notion – bekannt für sei
Notion verwandelt seinen Arbeitsbereich in eine Drehscheibe für KI-Agenten
Notion, der Anbieter von Produktivitätssoftware, tritt in das Zeitalter der agentenbasierten Lösungen ein.Während einer live gestreamten Produktankündigung am Mittwoch stellte Notion – bekannt für sei

Entdecken Sie die besten KI-Skripting-Tools für Radio und Podcasting im Jahr 2026 bei XIX.AI. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, mit denen Sie ansprechende Audio-Werbespots schnell erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie noch heute Ihr kreatives Potenzial!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
10 Tools
xix.ai

Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai













