
















 Maison
Maison
Cursor Composer 2 contre Claude Opus 4.6 : un test de performance relance le débat sur la programmation par IA
Le 19 mars, Cursor a officiellement lancé son modèle de codage développé en interne, Composer 2. Cette annonce a immédiatement suscité des discussions au sein de la communauté des développeurs : selon Cursor, Composer 2 a obtenu un score de 61,7 % sur Terminal-Bench 2.0, surpassant nettement les 58,0 % de Claude Opus 4.6 dans des conditions de test identiques.
Le modèle phare d'Anthropic a-t-il été surpassé par un modèle intégré à son propre IDE ? À mesure que la nouvelle se répandait, des débats ont rapidement émergé.
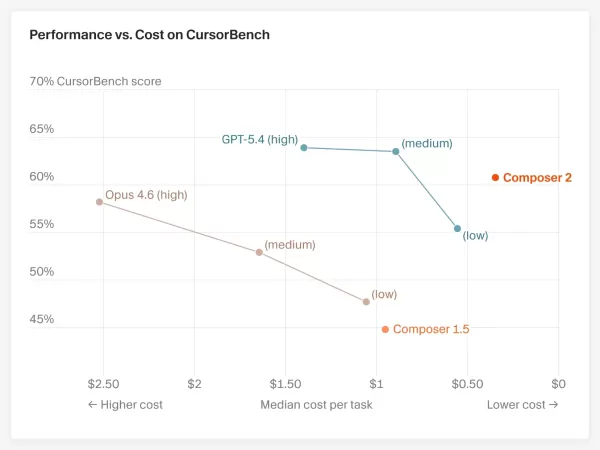
Trois résultats de benchmark clés
Cursor a publié trois séries de résultats de benchmark, toutes rendues publiques :
Terminal-Bench 2.0 (tâches de codage en terminal de type agent) : Composer 2 a obtenu un score de 61,7 %, devançant les 58,0 %de Claude Opus 4.6. Cependant, OpenAI GPT-5.4 reste en tête avec 75,1 %. CursorBench (scénarios de codage réels au sein de Cursor) : Composer 2 a atteint 61,3 %, soit une progression substantielle par rapport aux 44,2 % de la version précédente, Composer 1.5, et un score supérieur aux 58,2 %de Claude Opus 4.6. SWE-bench Multilingual (ingénierie logicielle multilingue) : Composer 2 a atteint 73,7 %, une amélioration notable par rapport à son prédécesseur.Cependant, un détail mérite d'être souligné : Anthropic avait précédemment indiqué que Claude Opus 4.6 avait obtenu un score de 65,4 % sur Terminal-Bench 2.0 avec des paramètres optimisés, un résultat bien supérieur aux 58,0 % cités par Cursor. Cette divergence provient du cadre de test : Cursor a utilisé des environnements d'agents tiers tels que Harbor et a calculé la moyenne des résultats sur cinq exécutions, tandis que les chiffres d'Anthropic provenaient de sa propre configuration optimisée. Ces deux séries de chiffres ne sont pas directement comparables, car elles utilisent des systèmes de référence différents. Cursor n'a pas éludé cette question ; l'annonce indiquait explicitement que « les résultats dépendent de l'agent, du harnais et des paramètres ».
Un coût représentant seulement un dixième de celui d'Opus 4.6
La rentabilité est le véritable atout caché de Composer 2.
Avec un prix de 0,50 $ / 2,50 $ par million de tokens d'entrée/sortie, contre 5 $ / 25 $ pour Claude Opus 4.6 et 2,5 $ / 15 $ pour GPT-5.4, le contraste est saisissant. Cursor explique que Composer 2 a été entièrement conçu pour des tâches de codage à long terme, en utilisant sa technologie propriétaire d’entraînement RL et d’« auto-résumé » pour réduire à la fois la latence et le coût – ce qu’ils décrivent comme « une intelligence de pointe + une vitesse extrême ».
Composer 2 est le troisième modèle développé en interne par Cursor, succédant à Composer 1 (octobre 2025) et à la version 1.5 (février 2026). Cette version met l'accent sur les « tâches à long terme » et fait d'une variante plus rapide et plus légère le modèle par défaut dans l'IDE Cursor.
Ce que signifie cette « renaissance »
La décision de Cursor de comparer directement son modèle à Opus 4.6 marque un tournant dans le paysage plus large des outils de codage IA.
OpenAI et Anthropic se font concurrence sur les capacités de pointe générales, tandis que les fournisseurs d'outils verticaux comme Cursor ont emprunté une voie différente : affiner les performances sur des tâches spécifiques jusqu'à un niveau exceptionnel, puis utiliser leurs avantages en termes de prix pour se démarquer. Des médias tels que VentureBeat et The New Stack ont noté que Composer 2 accélérera le déploiement pratique du « routage multimodèle » : utiliser Opus ou GPT pour le raisonnement complexe et passer à Composer 2 pour le codage quotidien à haute fréquence, tirant ainsi parti des avantages des deux côtés.
Claude Opus 4.6 a été lancé le 5 février et s’est classé en tête de plusieurs benchmarks, notamment Terminal-Bench 2.0, Humanity’s Last Exam et GDPval-AA. Les nouveaux résultats de Cursor remettent au moins en question cette domination dans le segment du codage spécialisé.
La réaction des développeurs a été largement positive jusqu'à présent, mais beaucoup affirment vouloir observer les performances du projet en conditions réelles avant de tirer des conclusions – une position légitime, car les benchmarks ne sont que des benchmarks. Cursor a déjà mis Composer 2 à disposition en essai gratuit au sein de l'IDE pour les utilisateurs abonnés.
Source des données : annonces officielles de Cursor et principaux médias technologiques, au 20 mars 2026. Les classements actuels peuvent être consultés sur tbench.ai ou sur le site web de Cursor.
Article connexe
 Baidu Health teste en interne son assistant médical basé sur l'IA, DoctorClaw, pour la recherche documentaire et l'assistance administrative à court terme
Baidu Health aurait commencé à tester en interne un assistant intelligent basé sur l'IA, destiné aux médecins. Baptisé en interne « DoctorClaw » (la version « Lobster Doctor »), ce produit marque
StrictlyVC San Francisco réunira des dirigeants de TDK Ventures, Replit et d'autres entreprises
Le premier événement StrictlyVC de l'année arrive à San Francisco plus tôt que vous ne le pensez. Il reste encore des billets pour notre rencontre du 30 avril au Sentro Filipino Cultural Center,
Notion transforme son espace de travail en une plateforme centralisée pour les agents IA
Notion, l'éditeur de logiciels de productivité, entre dans l'ère des agents.Lors d'une annonce de produit diffusée en direct mercredi, Notion — surtout connu pour son application de pri
Recommandations de sujets spéciaux liés
en écrivant
Baidu Health teste en interne son assistant médical basé sur l'IA, DoctorClaw, pour la recherche documentaire et l'assistance administrative à court terme
Baidu Health aurait commencé à tester en interne un assistant intelligent basé sur l'IA, destiné aux médecins. Baptisé en interne « DoctorClaw » (la version « Lobster Doctor »), ce produit marque
StrictlyVC San Francisco réunira des dirigeants de TDK Ventures, Replit et d'autres entreprises
Le premier événement StrictlyVC de l'année arrive à San Francisco plus tôt que vous ne le pensez. Il reste encore des billets pour notre rencontre du 30 avril au Sentro Filipino Cultural Center,
Notion transforme son espace de travail en une plateforme centralisée pour les agents IA
Notion, l'éditeur de logiciels de productivité, entre dans l'ère des agents.Lors d'une annonce de produit diffusée en direct mercredi, Notion — surtout connu pour son application de pri
Recommandations de sujets spéciaux liés
en écrivant
 Meilleurs outils d’scriptage AI pour la radio et la production de podcasts : rédiger des publicités audio captivantes
Meilleurs outils d’scriptage AI pour la radio et la production de podcasts : rédiger des publicités audio captivantes
Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
 10 outils
10 outils
 xix.ai
Entreprise
Le meilleur logiciel d'analyse de contrats basé sur l'IA : identifiez instantanément les failles juridiques et les risques de non-conformité
xix.ai
Entreprise
Le meilleur logiciel d'analyse de contrats basé sur l'IA : identifiez instantanément les failles juridiques et les risques de non-conformité
Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai
Création d'animations
Generateur d'animation AI pour Donghua : Créer des personnages de romans web et des avatars de bandes dessinées
Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Le 19 mars, Cursor a officiellement lancé son modèle de codage développé en interne, Composer 2. Cette annonce a immédiatement suscité des discussions au sein de la communauté des développeurs : selon Cursor, Composer 2 a obtenu un score de 61,7 % sur Terminal-Bench 2.0, surpassant nettement les 58,0 % de Claude Opus 4.6 dans des conditions de test identiques.
Le modèle phare d'Anthropic a-t-il été surpassé par un modèle intégré à son propre IDE ? À mesure que la nouvelle se répandait, des débats ont rapidement émergé.
Trois résultats de benchmark clés
Cursor a publié trois séries de résultats de benchmark, toutes rendues publiques :
Terminal-Bench 2.0 (tâches de codage en terminal de type agent) : Composer 2 a obtenu un score de 61,7 %, devançant les 58,0 %de Claude Opus 4.6. Cependant, OpenAI GPT-5.4 reste en tête avec 75,1 %. CursorBench (scénarios de codage réels au sein de Cursor) : Composer 2 a atteint 61,3 %, soit une progression substantielle par rapport aux 44,2 % de la version précédente, Composer 1.5, et un score supérieur aux 58,2 %de Claude Opus 4.6. SWE-bench Multilingual (ingénierie logicielle multilingue) : Composer 2 a atteint 73,7 %, une amélioration notable par rapport à son prédécesseur.Cependant, un détail mérite d'être souligné : Anthropic avait précédemment indiqué que Claude Opus 4.6 avait obtenu un score de 65,4 % sur Terminal-Bench 2.0 avec des paramètres optimisés, un résultat bien supérieur aux 58,0 % cités par Cursor. Cette divergence provient du cadre de test : Cursor a utilisé des environnements d'agents tiers tels que Harbor et a calculé la moyenne des résultats sur cinq exécutions, tandis que les chiffres d'Anthropic provenaient de sa propre configuration optimisée. Ces deux séries de chiffres ne sont pas directement comparables, car elles utilisent des systèmes de référence différents. Cursor n'a pas éludé cette question ; l'annonce indiquait explicitement que « les résultats dépendent de l'agent, du harnais et des paramètres ».
Un coût représentant seulement un dixième de celui d'Opus 4.6
La rentabilité est le véritable atout caché de Composer 2.
Avec un prix de 0,50 $ / 2,50 $ par million de tokens d'entrée/sortie, contre 5 $ / 25 $ pour Claude Opus 4.6 et 2,5 $ / 15 $ pour GPT-5.4, le contraste est saisissant. Cursor explique que Composer 2 a été entièrement conçu pour des tâches de codage à long terme, en utilisant sa technologie propriétaire d’entraînement RL et d’« auto-résumé » pour réduire à la fois la latence et le coût – ce qu’ils décrivent comme « une intelligence de pointe + une vitesse extrême ».
Composer 2 est le troisième modèle développé en interne par Cursor, succédant à Composer 1 (octobre 2025) et à la version 1.5 (février 2026). Cette version met l'accent sur les « tâches à long terme » et fait d'une variante plus rapide et plus légère le modèle par défaut dans l'IDE Cursor.
Ce que signifie cette « renaissance »
La décision de Cursor de comparer directement son modèle à Opus 4.6 marque un tournant dans le paysage plus large des outils de codage IA.
OpenAI et Anthropic se font concurrence sur les capacités de pointe générales, tandis que les fournisseurs d'outils verticaux comme Cursor ont emprunté une voie différente : affiner les performances sur des tâches spécifiques jusqu'à un niveau exceptionnel, puis utiliser leurs avantages en termes de prix pour se démarquer. Des médias tels que VentureBeat et The New Stack ont noté que Composer 2 accélérera le déploiement pratique du « routage multimodèle » : utiliser Opus ou GPT pour le raisonnement complexe et passer à Composer 2 pour le codage quotidien à haute fréquence, tirant ainsi parti des avantages des deux côtés.
Claude Opus 4.6 a été lancé le 5 février et s’est classé en tête de plusieurs benchmarks, notamment Terminal-Bench 2.0, Humanity’s Last Exam et GDPval-AA. Les nouveaux résultats de Cursor remettent au moins en question cette domination dans le segment du codage spécialisé.
La réaction des développeurs a été largement positive jusqu'à présent, mais beaucoup affirment vouloir observer les performances du projet en conditions réelles avant de tirer des conclusions – une position légitime, car les benchmarks ne sont que des benchmarks. Cursor a déjà mis Composer 2 à disposition en essai gratuit au sein de l'IDE pour les utilisateurs abonnés.
Source des données : annonces officielles de Cursor et principaux médias technologiques, au 20 mars 2026. Les classements actuels peuvent être consultés sur tbench.ai ou sur le site web de Cursor.










 Baidu Health teste en interne son assistant médical basé sur l'IA, DoctorClaw, pour la recherche documentaire et l'assistance administrative à court terme
Baidu Health aurait commencé à tester en interne un assistant intelligent basé sur l'IA, destiné aux médecins. Baptisé en interne « DoctorClaw » (la version « Lobster Doctor »), ce produit marque
Baidu Health teste en interne son assistant médical basé sur l'IA, DoctorClaw, pour la recherche documentaire et l'assistance administrative à court terme
Baidu Health aurait commencé à tester en interne un assistant intelligent basé sur l'IA, destiné aux médecins. Baptisé en interne « DoctorClaw » (la version « Lobster Doctor »), ce produit marque
 StrictlyVC San Francisco réunira des dirigeants de TDK Ventures, Replit et d'autres entreprises
Le premier événement StrictlyVC de l'année arrive à San Francisco plus tôt que vous ne le pensez. Il reste encore des billets pour notre rencontre du 30 avril au Sentro Filipino Cultural Center,
StrictlyVC San Francisco réunira des dirigeants de TDK Ventures, Replit et d'autres entreprises
Le premier événement StrictlyVC de l'année arrive à San Francisco plus tôt que vous ne le pensez. Il reste encore des billets pour notre rencontre du 30 avril au Sentro Filipino Cultural Center,
 Notion transforme son espace de travail en une plateforme centralisée pour les agents IA
Notion, l'éditeur de logiciels de productivité, entre dans l'ère des agents.Lors d'une annonce de produit diffusée en direct mercredi, Notion — surtout connu pour son application de pri
Notion transforme son espace de travail en une plateforme centralisée pour les agents IA
Notion, l'éditeur de logiciels de productivité, entre dans l'ère des agents.Lors d'une annonce de produit diffusée en direct mercredi, Notion — surtout connu pour son application de pri

Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
10 outils
xix.ai

Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai

Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai













