
















 Maison
Maison
Des opportunités et des obstacles émergent alors que l'équipe Red Team AI cherche à construire des modèles plus sûrs et plus intelligents pour demain.
Note de l'éditeur : Louis animera une table ronde éditoriale sur ce sujet à VB Transform dans le courant du mois. Inscrivez-vous dès maintenant.
Les modèles d'IA sont confrontés à des attaques incessantes. Avec 77 % des entreprises déjà ciblées par des assauts adverses, dont 41 % impliquent des injections rapides et des empoisonnements de données, les méthodes des attaquants progressent plus rapidement que les cyberdéfenses actuelles.
Pour inverser la tendance, nous devons repenser fondamentalement la façon dont la sécurité est intégrée dans les modèles d'IA actuels. Les équipes DevOps doivent passer de postures réactionnaires à l'intégration de tests contradictoires continus tout au long du cycle de développement.
Placer le Red Teaming au cœur de la défense de l'IA
La protection des grands modèles de langage (LLM) tout au long des cycles DevOps nécessite l'intégration du red teaming en tant que pratique de base. Au lieu de traiter la sécurité comme un point de contrôle final - ce qui est courant dans les pipelines d'applications web - des tests contradictoires continus doivent être intégrés à chaque phase du cycle de vie du développement logiciel (SDLC).
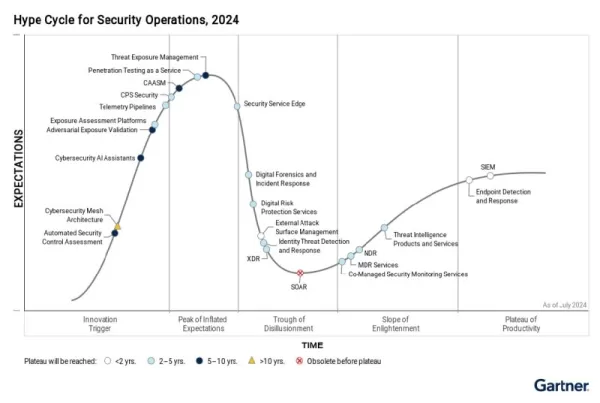
Le Hype Cycle de Gartner souligne le rôle croissant de la gestion continue de l'exposition aux menaces (CTEM), démontrant ainsi pourquoi le red teaming doit faire partie intégrante du cycle de vie DevSecOps. Source : Gartner, Hype Cycle for the DevSecOps : Gartner, Hype Cycle pour les opérations de sécurité, 2024 Une approche DevSecOps plus intégrée devient essentielle pour contrer les menaces croissantes telles que l'injection rapide, l'empoisonnement des données et la fuite d'informations sensibles. Ces attaques dangereuses sont de plus en plus courantes - elles se produisent de la conception du modèle au déploiement - ce qui souligne l'urgence d'une surveillance constante.
Les récentes lignes directrices de Microsoft sur la planification des exercices de l'équipe rouge pour les LLM et leurs applications offrent un point de départ solide pour un processus de sécurité intégré. De même, le cadre de gestion des risques liés à l'IA du NIST préconise une approche proactive, axée sur le cycle de vie, des tests d'adversité et de la réduction des risques. Les tests effectués par Microsoft sur plus de 100 produits d'IA générative renforcent la nécessité de combiner la détection automatisée des menaces avec l'analyse d'experts tout au long du développement du modèle.
Étant donné que des réglementations telles que la loi européenne sur l'IA imposent des exigences strictes en matière de tests contradictoires, le red teaming continu permet non seulement de garantir la conformité, mais aussi d'améliorer la résilience globale de la sécurité.
OpenAI incorpore un red teaming externe depuis la conception initiale jusqu'au déploiement, validant ainsi le fait que des tests de sécurité cohérents et préventifs sont essentiels au succès du développement d'un LLM.
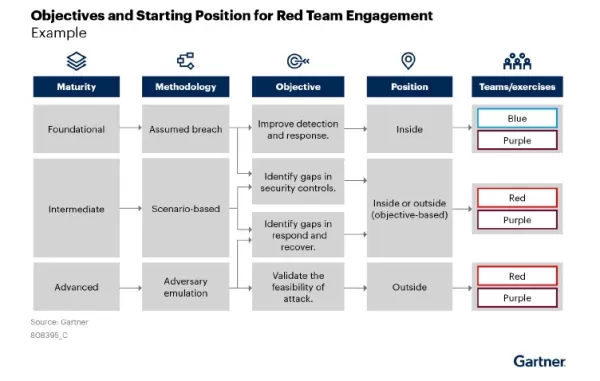
Le cadre de travail de Gartner illustre les étapes de maturité progressive du red teaming, depuis les exercices de base jusqu'aux simulations avancées, ce qui est essentiel pour renforcer systématiquement les protections des modèles d'IA. Source : Gartner, Improve Cyber Resilience : Gartner, Improve Cyber Resilience by Conducting Red Team Exercises (Améliorer la résilience cybernétique en organisant des exercices en équipe rouge) Pourquoi la cybersécurité classique n'est pas à la hauteur des menaces de l'IA
Les méthodes traditionnelles de cybersécurité ne parviennent pas à contrer les attaques basées sur l'IA, car ces menaces fonctionnent selon des principes totalement différents. Comme les tactiques adverses dépassent les défenses conventionnelles, de nouvelles techniques d'équipe rouge sont nécessaires. Voici plusieurs méthodes d'attaque spécialement conçues pour cibler les modèles d'IA pendant les cycles DevOps et après le déploiement :
- Empoisonnement des données : Les attaquants introduisent des données malveillantes ou biaisées dans les ensembles de données d'entraînement, ce qui entraîne un apprentissage imprécis des modèles d'IA. Cela crée des erreurs persistantes et des failles opérationnelles qui peuvent passer inaperçues, érodant ainsi la confiance dans les résultats obtenus par l'IA.
- Évasion de modèle : Les adversaires modifient subtilement les données d'entrée pour contourner les mécanismes de détection, en exploitant les limites des règles statiques et des systèmes de sécurité basés sur des modèles.
- Inversion de modèle : Grâce à des requêtes répétées et systématiques, les attaquants peuvent reconstituer ou exposer les données confidentielles utilisées pour la formation, ce qui entraîne de graves atteintes à la vie privée.
- Injection rapide : Les attaquants conçoivent des entrées qui manipulent l'IA générative de manière à ce qu'elle ignore les mesures de protection, produisant potentiellement un contenu nuisible, non intentionnel ou non autorisé.
- Risques liés au double usage : Comme le souligne le récent document intitulé Benchmark Early and Red Team Often : A Framework for Assessing and Managing Dual-Use Hazards of AI Foundation Models, des chercheurs du Center for Long-Term Cybersecurity de l'université de Berkeley mettent en garde contre le fait que les modèles d'IA avancés abaissent la barrière qui empêche les non-experts d'exécuter des cyberattaques complexes, des menaces chimiques ou d'autres exploits dangereux, ce qui amplifie considérablement les risques à l'échelle mondiale.
La nature interconnectée des opérations intégrées d'apprentissage automatique (MLOps) amplifie encore ces risques. Le LLM et les pipelines de développement de l'IA élargissent la surface d'attaque, ce qui exige des pratiques d'équipe rouge plus sophistiquées.
Pour contrer ces menaces IA en constante évolution, les responsables de la cybersécurité adoptent des tests contradictoires continus. Les exercices structurés en équipe rouge qui simulent des attaques d'IA réelles sont désormais essentiels pour identifier les faiblesses cachées et combler les lacunes de sécurité avant qu'elles ne soient exploitées.
Comment les organisations leaders en matière d'IA utilisent le Red Teaming pour devancer les attaquants
Les adversaires utilisent de plus en plus l'IA pour développer des méthodes d'attaque sans précédent qui échappent aux contrôles de sécurité traditionnels. Leur objectif est de découvrir et d'exploiter le plus grand nombre possible de vulnérabilités émergentes.
En réponse, les grandes entreprises d'IA ont fait du red teaming systématique la pierre angulaire de leur stratégie de sécurité. Plutôt que de procéder à un red teaming sporadique, elles mettent en œuvre des tests contradictoires continus qui combinent l'expertise humaine, l'automatisation disciplinée et les évaluations itératives de l'homme dans la boucle. Cette approche proactive permet d'identifier et de neutraliser les menaces avant qu'elles ne deviennent des armes.
Grâce à des méthodologies de test rigoureuses, ces leaders identifient systématiquement les faiblesses et renforcent leurs modèles par rapport à des scénarios adverses réels.
Les principales approches sont les suivantes
- Anthropic s'appuie sur une évaluation humaine rigoureuse dans le cadre de son processus continu de red-teaming. En intégrant des évaluations humaines en boucle à des attaques adverses automatisées, l'entreprise découvre de manière proactive les vulnérabilités et améliore en permanence la fiabilité et l'interprétabilité de ses modèles.
- Meta renforce la sécurité grâce à une approche axée sur l'automatisation. Son système MART (Multi-round Automatic Red-Teaming) génère de manière itérative des messages contradictoires, identifiant rapidement les failles cachées et réduisant les vecteurs d'attaque dans les déploiements d'IA à grande échelle.
- Microsoft s'appuie sur une collaboration interdisciplinaire pour assurer l'efficacité de l'équipe rouge. Grâce à son kit d'identification des risques Python (PyRIT), Microsoft associe son savoir-faire en matière de cybersécurité à des analyses avancées et à une validation humaine, ce qui permet d'accélérer la découverte des vulnérabilités et de fournir des informations exploitables pour renforcer la résilience des modèles.
- OpenAI fait appel à des experts mondiaux en sécurité pour améliorer les défenses de l'IA à grande échelle. En combinant les connaissances de spécialistes externes avec des tests contradictoires automatisés et des cycles de validation humaine, OpenAI s'attaque aux menaces sophistiquées - en particulier les risques de désinformation et d'injection rapide - afin de maintenir des performances de modèle robustes et fiables.
En fait, les principales organisations d'IA reconnaissent que pour garder une longueur d'avance sur les attaquants, il faut déployer des efforts constants et proactifs. En intégrant une supervision humaine structurée, une automatisation disciplinée et un raffinement itératif dans leurs efforts de red teaming, ces entreprises établissent une référence pour la construction de systèmes d'IA résilients et dignes de confiance.
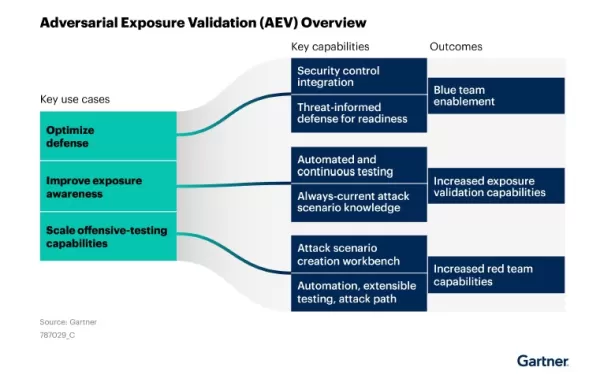
Gartner montre comment la validation de l'exposition aux adversaires (AEV) permet d'optimiser les stratégies de défense, d'améliorer la connaissance des menaces et d'effectuer des tests offensifs évolutifs, ce qui est essentiel pour sécuriser les modèles d'IA. Source : Gartner : Gartner, Market Guide for Adversarial Exposure Validation (Guide du marché pour la validation de l'exposition aux menaces) Cinq stratégies actionnables pour renforcer la sécurité de l'IA dès maintenant
Alors que les attaques contre les LLM et les modèles d'IA gagnent en complexité, les équipes DevOps et DevSecOps doivent collaborer étroitement pour renforcer la sécurité de l'IA. VentureBeat recommande ces cinq stratégies à fort impact que les responsables de la sécurité peuvent mettre en œuvre immédiatement :
- Intégrer la sécurité dès le début (Anthropic, OpenAI)
Intégrer des tests contradictoires directement dans la phase de conception initiale et les maintenir tout au long du cycle de vie du modèle. La détection précoce des vulnérabilités réduit les risques, minimise les perturbations et diminue les coûts à long terme.
- Déployer une surveillance adaptative en temps réel (Microsoft)
Les défenses statiques sont insuffisantes contre les menaces avancées de l'IA. Utilisez des outils de surveillance continue alimentés par l'IA comme CyberAlly pour détecter rapidement les anomalies subtiles, réduisant ainsi la fenêtre d'exploitation.
- Équilibrer l'automatisation et le jugement humain (Meta, Microsoft)
L'automatisation seule manque de nuances, et les tests manuels ne sont pas évolutifs. Combinez les analyses contradictoires automatisées et les évaluations des vulnérabilités avec des analyses d'experts pour garantir des résultats précis et exploitables.
- Engager régulièrement des équipes rouges externes (OpenAI)
Les équipes internes peuvent développer des angles morts. Des évaluations périodiques par des équipes rouges externes permettent de découvrir des faiblesses négligées, de fournir une validation indépendante et d'apporter des améliorations continues à la sécurité.
- Maintenir une veille dynamique sur les menaces (Meta, Microsoft, OpenAI)
Les attaquants affinent constamment leurs méthodes. Intégrez continuellement des renseignements sur les menaces en temps réel, des analyses automatisées et des avis d'experts pour mettre à jour et renforcer vos mesures défensives de manière proactive.
Ensemble, ces stratégies aident les flux de travail DevOps à rester résilients et sécurisés face à l'évolution rapide des menaces adverses.
Le Red Teaming est désormais essentiel, et non plus facultatif
Les menaces liées à l'IA sont devenues trop sophistiquées et trop fréquentes pour que la cybersécurité traditionnelle et réactive puisse les gérer efficacement. Pour conserver un avantage défensif, les entreprises doivent intégrer des tests continus sur les adversaires à chaque étape du développement d'un modèle. En équilibrant l'automatisation avec la perspicacité humaine et en adaptant les défenses de manière dynamique, les principaux fournisseurs d'IA démontrent qu'une sécurité solide et une innovation rapide peuvent aller de pair.
En fin de compte, le red teaming va au-delà de la simple protection des modèles d'IA : il s'agit d'instaurer la confiance, la résilience et l'assurance dans un avenir dominé par l'IA.
Participez à la discussion lors de Transform 2025
J'animerai deux tables rondes sur la cybersécurité lors de l'événement Transform 2025 de VentureBeat, qui se tiendra les 24 et 25 juin à Fort Mason, à San Francisco. Inscrivez-vous dès maintenant pour y participer.
Une session, intitulée AI Red Teaming and Adversarial Testing, explorera les stratégies de test et de renforcement des solutions de cybersécurité alimentées par l'IA contre les menaces adverses avancées.
Article connexe
 Cursor Composer 2 contre Claude Opus 4.6 : un test de performance relance le débat sur la programmation par IA
Le 19 mars, Cursor a officiellement lancé son modèle de codage développé en interne, Composer 2. Cette annonce a immédiatement suscité des discussions au sein de la communauté des développeurs : selon
StrictlyVC San Francisco réunira des dirigeants de TDK Ventures, Replit et d'autres entreprises
Le premier événement StrictlyVC de l'année arrive à San Francisco plus tôt que vous ne le pensez. Il reste encore des billets pour notre rencontre du 30 avril au Sentro Filipino Cultural Center,
Notion transforme son espace de travail en une plateforme centralisée pour les agents IA
Notion, l'éditeur de logiciels de productivité, entre dans l'ère des agents.Lors d'une annonce de produit diffusée en direct mercredi, Notion — surtout connu pour son application de pri
Recommandations de sujets spéciaux liés
en écrivant
Cursor Composer 2 contre Claude Opus 4.6 : un test de performance relance le débat sur la programmation par IA
Le 19 mars, Cursor a officiellement lancé son modèle de codage développé en interne, Composer 2. Cette annonce a immédiatement suscité des discussions au sein de la communauté des développeurs : selon
StrictlyVC San Francisco réunira des dirigeants de TDK Ventures, Replit et d'autres entreprises
Le premier événement StrictlyVC de l'année arrive à San Francisco plus tôt que vous ne le pensez. Il reste encore des billets pour notre rencontre du 30 avril au Sentro Filipino Cultural Center,
Notion transforme son espace de travail en une plateforme centralisée pour les agents IA
Notion, l'éditeur de logiciels de productivité, entre dans l'ère des agents.Lors d'une annonce de produit diffusée en direct mercredi, Notion — surtout connu pour son application de pri
Recommandations de sujets spéciaux liés
en écrivant
 Meilleurs outils d’scriptage AI pour la radio et la production de podcasts : rédiger des publicités audio captivantes
Meilleurs outils d’scriptage AI pour la radio et la production de podcasts : rédiger des publicités audio captivantes
Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
 10 outils
10 outils
 xix.ai
Entreprise
Le meilleur logiciel d'analyse de contrats basé sur l'IA : identifiez instantanément les failles juridiques et les risques de non-conformité
xix.ai
Entreprise
Le meilleur logiciel d'analyse de contrats basé sur l'IA : identifiez instantanément les failles juridiques et les risques de non-conformité
Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai
Création d'animations
Generateur d'animation AI pour Donghua : Créer des personnages de romans web et des avatars de bandes dessinées
Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Note de l'éditeur : Louis animera une table ronde éditoriale sur ce sujet à VB Transform dans le courant du mois. Inscrivez-vous dès maintenant.
Les modèles d'IA sont confrontés à des attaques incessantes. Avec 77 % des entreprises déjà ciblées par des assauts adverses, dont 41 % impliquent des injections rapides et des empoisonnements de données, les méthodes des attaquants progressent plus rapidement que les cyberdéfenses actuelles.
Pour inverser la tendance, nous devons repenser fondamentalement la façon dont la sécurité est intégrée dans les modèles d'IA actuels. Les équipes DevOps doivent passer de postures réactionnaires à l'intégration de tests contradictoires continus tout au long du cycle de développement.
Placer le Red Teaming au cœur de la défense de l'IA
La protection des grands modèles de langage (LLM) tout au long des cycles DevOps nécessite l'intégration du red teaming en tant que pratique de base. Au lieu de traiter la sécurité comme un point de contrôle final - ce qui est courant dans les pipelines d'applications web - des tests contradictoires continus doivent être intégrés à chaque phase du cycle de vie du développement logiciel (SDLC).
Une approche DevSecOps plus intégrée devient essentielle pour contrer les menaces croissantes telles que l'injection rapide, l'empoisonnement des données et la fuite d'informations sensibles. Ces attaques dangereuses sont de plus en plus courantes - elles se produisent de la conception du modèle au déploiement - ce qui souligne l'urgence d'une surveillance constante.
Les récentes lignes directrices de Microsoft sur la planification des exercices de l'équipe rouge pour les LLM et leurs applications offrent un point de départ solide pour un processus de sécurité intégré. De même, le cadre de gestion des risques liés à l'IA du NIST préconise une approche proactive, axée sur le cycle de vie, des tests d'adversité et de la réduction des risques. Les tests effectués par Microsoft sur plus de 100 produits d'IA générative renforcent la nécessité de combiner la détection automatisée des menaces avec l'analyse d'experts tout au long du développement du modèle.
Étant donné que des réglementations telles que la loi européenne sur l'IA imposent des exigences strictes en matière de tests contradictoires, le red teaming continu permet non seulement de garantir la conformité, mais aussi d'améliorer la résilience globale de la sécurité.
OpenAI incorpore un red teaming externe depuis la conception initiale jusqu'au déploiement, validant ainsi le fait que des tests de sécurité cohérents et préventifs sont essentiels au succès du développement d'un LLM.
Pourquoi la cybersécurité classique n'est pas à la hauteur des menaces de l'IA
Les méthodes traditionnelles de cybersécurité ne parviennent pas à contrer les attaques basées sur l'IA, car ces menaces fonctionnent selon des principes totalement différents. Comme les tactiques adverses dépassent les défenses conventionnelles, de nouvelles techniques d'équipe rouge sont nécessaires. Voici plusieurs méthodes d'attaque spécialement conçues pour cibler les modèles d'IA pendant les cycles DevOps et après le déploiement :
- Empoisonnement des données : Les attaquants introduisent des données malveillantes ou biaisées dans les ensembles de données d'entraînement, ce qui entraîne un apprentissage imprécis des modèles d'IA. Cela crée des erreurs persistantes et des failles opérationnelles qui peuvent passer inaperçues, érodant ainsi la confiance dans les résultats obtenus par l'IA.
- Évasion de modèle : Les adversaires modifient subtilement les données d'entrée pour contourner les mécanismes de détection, en exploitant les limites des règles statiques et des systèmes de sécurité basés sur des modèles.
- Inversion de modèle : Grâce à des requêtes répétées et systématiques, les attaquants peuvent reconstituer ou exposer les données confidentielles utilisées pour la formation, ce qui entraîne de graves atteintes à la vie privée.
- Injection rapide : Les attaquants conçoivent des entrées qui manipulent l'IA générative de manière à ce qu'elle ignore les mesures de protection, produisant potentiellement un contenu nuisible, non intentionnel ou non autorisé.
- Risques liés au double usage : Comme le souligne le récent document intitulé Benchmark Early and Red Team Often : A Framework for Assessing and Managing Dual-Use Hazards of AI Foundation Models, des chercheurs du Center for Long-Term Cybersecurity de l'université de Berkeley mettent en garde contre le fait que les modèles d'IA avancés abaissent la barrière qui empêche les non-experts d'exécuter des cyberattaques complexes, des menaces chimiques ou d'autres exploits dangereux, ce qui amplifie considérablement les risques à l'échelle mondiale.
La nature interconnectée des opérations intégrées d'apprentissage automatique (MLOps) amplifie encore ces risques. Le LLM et les pipelines de développement de l'IA élargissent la surface d'attaque, ce qui exige des pratiques d'équipe rouge plus sophistiquées.
Pour contrer ces menaces IA en constante évolution, les responsables de la cybersécurité adoptent des tests contradictoires continus. Les exercices structurés en équipe rouge qui simulent des attaques d'IA réelles sont désormais essentiels pour identifier les faiblesses cachées et combler les lacunes de sécurité avant qu'elles ne soient exploitées.
Comment les organisations leaders en matière d'IA utilisent le Red Teaming pour devancer les attaquants
Les adversaires utilisent de plus en plus l'IA pour développer des méthodes d'attaque sans précédent qui échappent aux contrôles de sécurité traditionnels. Leur objectif est de découvrir et d'exploiter le plus grand nombre possible de vulnérabilités émergentes.
En réponse, les grandes entreprises d'IA ont fait du red teaming systématique la pierre angulaire de leur stratégie de sécurité. Plutôt que de procéder à un red teaming sporadique, elles mettent en œuvre des tests contradictoires continus qui combinent l'expertise humaine, l'automatisation disciplinée et les évaluations itératives de l'homme dans la boucle. Cette approche proactive permet d'identifier et de neutraliser les menaces avant qu'elles ne deviennent des armes.
Grâce à des méthodologies de test rigoureuses, ces leaders identifient systématiquement les faiblesses et renforcent leurs modèles par rapport à des scénarios adverses réels.
Les principales approches sont les suivantes
- Anthropic s'appuie sur une évaluation humaine rigoureuse dans le cadre de son processus continu de red-teaming. En intégrant des évaluations humaines en boucle à des attaques adverses automatisées, l'entreprise découvre de manière proactive les vulnérabilités et améliore en permanence la fiabilité et l'interprétabilité de ses modèles.
- Meta renforce la sécurité grâce à une approche axée sur l'automatisation. Son système MART (Multi-round Automatic Red-Teaming) génère de manière itérative des messages contradictoires, identifiant rapidement les failles cachées et réduisant les vecteurs d'attaque dans les déploiements d'IA à grande échelle.
- Microsoft s'appuie sur une collaboration interdisciplinaire pour assurer l'efficacité de l'équipe rouge. Grâce à son kit d'identification des risques Python (PyRIT), Microsoft associe son savoir-faire en matière de cybersécurité à des analyses avancées et à une validation humaine, ce qui permet d'accélérer la découverte des vulnérabilités et de fournir des informations exploitables pour renforcer la résilience des modèles.
- OpenAI fait appel à des experts mondiaux en sécurité pour améliorer les défenses de l'IA à grande échelle. En combinant les connaissances de spécialistes externes avec des tests contradictoires automatisés et des cycles de validation humaine, OpenAI s'attaque aux menaces sophistiquées - en particulier les risques de désinformation et d'injection rapide - afin de maintenir des performances de modèle robustes et fiables.
En fait, les principales organisations d'IA reconnaissent que pour garder une longueur d'avance sur les attaquants, il faut déployer des efforts constants et proactifs. En intégrant une supervision humaine structurée, une automatisation disciplinée et un raffinement itératif dans leurs efforts de red teaming, ces entreprises établissent une référence pour la construction de systèmes d'IA résilients et dignes de confiance.
Cinq stratégies actionnables pour renforcer la sécurité de l'IA dès maintenant
Alors que les attaques contre les LLM et les modèles d'IA gagnent en complexité, les équipes DevOps et DevSecOps doivent collaborer étroitement pour renforcer la sécurité de l'IA. VentureBeat recommande ces cinq stratégies à fort impact que les responsables de la sécurité peuvent mettre en œuvre immédiatement :
- Intégrer la sécurité dès le début (Anthropic, OpenAI)
Intégrer des tests contradictoires directement dans la phase de conception initiale et les maintenir tout au long du cycle de vie du modèle. La détection précoce des vulnérabilités réduit les risques, minimise les perturbations et diminue les coûts à long terme.
- Déployer une surveillance adaptative en temps réel (Microsoft)
Les défenses statiques sont insuffisantes contre les menaces avancées de l'IA. Utilisez des outils de surveillance continue alimentés par l'IA comme CyberAlly pour détecter rapidement les anomalies subtiles, réduisant ainsi la fenêtre d'exploitation.
- Équilibrer l'automatisation et le jugement humain (Meta, Microsoft)
L'automatisation seule manque de nuances, et les tests manuels ne sont pas évolutifs. Combinez les analyses contradictoires automatisées et les évaluations des vulnérabilités avec des analyses d'experts pour garantir des résultats précis et exploitables.
- Engager régulièrement des équipes rouges externes (OpenAI)
Les équipes internes peuvent développer des angles morts. Des évaluations périodiques par des équipes rouges externes permettent de découvrir des faiblesses négligées, de fournir une validation indépendante et d'apporter des améliorations continues à la sécurité.
- Maintenir une veille dynamique sur les menaces (Meta, Microsoft, OpenAI)
Les attaquants affinent constamment leurs méthodes. Intégrez continuellement des renseignements sur les menaces en temps réel, des analyses automatisées et des avis d'experts pour mettre à jour et renforcer vos mesures défensives de manière proactive.
Ensemble, ces stratégies aident les flux de travail DevOps à rester résilients et sécurisés face à l'évolution rapide des menaces adverses.
Le Red Teaming est désormais essentiel, et non plus facultatif
Les menaces liées à l'IA sont devenues trop sophistiquées et trop fréquentes pour que la cybersécurité traditionnelle et réactive puisse les gérer efficacement. Pour conserver un avantage défensif, les entreprises doivent intégrer des tests continus sur les adversaires à chaque étape du développement d'un modèle. En équilibrant l'automatisation avec la perspicacité humaine et en adaptant les défenses de manière dynamique, les principaux fournisseurs d'IA démontrent qu'une sécurité solide et une innovation rapide peuvent aller de pair.
En fin de compte, le red teaming va au-delà de la simple protection des modèles d'IA : il s'agit d'instaurer la confiance, la résilience et l'assurance dans un avenir dominé par l'IA.
Participez à la discussion lors de Transform 2025
J'animerai deux tables rondes sur la cybersécurité lors de l'événement Transform 2025 de VentureBeat, qui se tiendra les 24 et 25 juin à Fort Mason, à San Francisco. Inscrivez-vous dès maintenant pour y participer.
Une session, intitulée AI Red Teaming and Adversarial Testing, explorera les stratégies de test et de renforcement des solutions de cybersécurité alimentées par l'IA contre les menaces adverses avancées.










 Cursor Composer 2 contre Claude Opus 4.6 : un test de performance relance le débat sur la programmation par IA
Le 19 mars, Cursor a officiellement lancé son modèle de codage développé en interne, Composer 2. Cette annonce a immédiatement suscité des discussions au sein de la communauté des développeurs : selon
Cursor Composer 2 contre Claude Opus 4.6 : un test de performance relance le débat sur la programmation par IA
Le 19 mars, Cursor a officiellement lancé son modèle de codage développé en interne, Composer 2. Cette annonce a immédiatement suscité des discussions au sein de la communauté des développeurs : selon
 StrictlyVC San Francisco réunira des dirigeants de TDK Ventures, Replit et d'autres entreprises
Le premier événement StrictlyVC de l'année arrive à San Francisco plus tôt que vous ne le pensez. Il reste encore des billets pour notre rencontre du 30 avril au Sentro Filipino Cultural Center,
StrictlyVC San Francisco réunira des dirigeants de TDK Ventures, Replit et d'autres entreprises
Le premier événement StrictlyVC de l'année arrive à San Francisco plus tôt que vous ne le pensez. Il reste encore des billets pour notre rencontre du 30 avril au Sentro Filipino Cultural Center,
 Notion transforme son espace de travail en une plateforme centralisée pour les agents IA
Notion, l'éditeur de logiciels de productivité, entre dans l'ère des agents.Lors d'une annonce de produit diffusée en direct mercredi, Notion — surtout connu pour son application de pri
Notion transforme son espace de travail en une plateforme centralisée pour les agents IA
Notion, l'éditeur de logiciels de productivité, entre dans l'ère des agents.Lors d'une annonce de produit diffusée en direct mercredi, Notion — surtout connu pour son application de pri

Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
10 outils
xix.ai

Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai

Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai













