
















 家
家レッドチームAIがより安全でスマートなモデルの明日を目指す中で、チャンスと障害が浮かび上がってきた。
編集部注:ルイスは今月末、VB Transformでこのテーマに関する編集ラウンドテーブルの司会を務める。今すぐ登録してください。
AIモデルは容赦ない攻撃に直面している。企業の77%がすでに敵対的攻撃の標的になっており、そのうちの41%がプロンプト・インジェクションやデータ・ポイズニングに関与している。
この流れを変えるには、今日のAIモデルにどのようにセキュリティを組み込むかを根本的に考え直す必要がある。DevOpsチームは、開発ライフサイクル全体を通じて継続的な敵対的テストを組み込む方向に、反応的な姿勢からシフトしなければならない。
AI防御の中心をレッドチーム化する
DevOpsサイクルを通じて大規模言語モデル(LLM)を保護するには、レッド・チーミングを中核的なプラクティスとして統合する必要がある。Webアプリケーションのパイプラインでよく見られるように、セキュリティを最終チェックポイントとして扱うのではなく、継続的な敵対的テストをソフトウェア開発ライフサイクル(SDLC)のすべてのフェーズに組み込む必要がある。
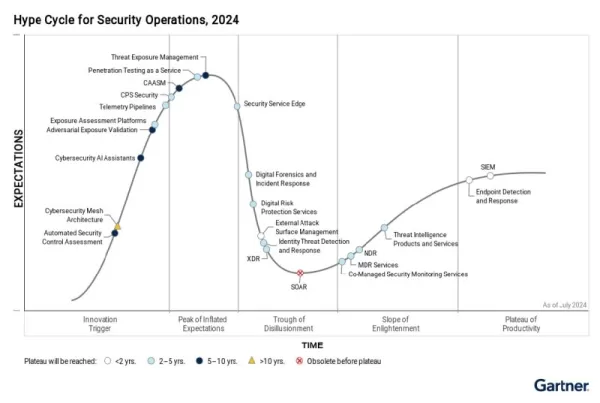
ガートナー社のハイプ・サイクルは、継続的な脅威暴露管理(CTEM)の役割の増大を強調し、レッド・チーミングがDevSecOpsライフサイクルに不可欠にならなければならない理由を示している。出典ガートナー、セキュリティ・オペレーションのハイプ・サイクル、2024年 プロンプト・インジェクション、データ・ポイズニング、機密情報の漏えいといった脅威の増加に対抗するためには、より統合的なDevSecOpsアプローチが不可欠になっている。このような危険な攻撃は、モデル設計からデプロイまで、ますます一般的になっており、常時監視の緊急性が高まっている。
マイクロソフト社が最近発表した、LLMとそのアプリケーションに対するレッドチーム演習の計画に関するガイドラインは、統合されたセキュリティ・プロセスの確かな出発点を示している。同様に、NISTのAIリスクマネジメントフレームワークは、敵対的なテストとリスク削減に対する、ライフサイクル指向のプロアクティブなアプローチを求めている。マイクロソフトが100以上のジェネレーティブAI製品をテストした結果、モデル開発全体を通じて自動脅威検知と専門家による分析を組み合わせる必要性が強化された。
EUのAI法のような規制が厳しい敵対的テスト要件を課す中、継続的なレッドチームはコンプライアンスを保証するだけでなく、全体的なセキュリティ回復力を向上させます。
OpenAIは、初期設計から配備まで外部のレッド・チーミングを取り入れ、一貫した予防的セキュリティ・テストがLLM開発の成功に不可欠であることを検証しています。
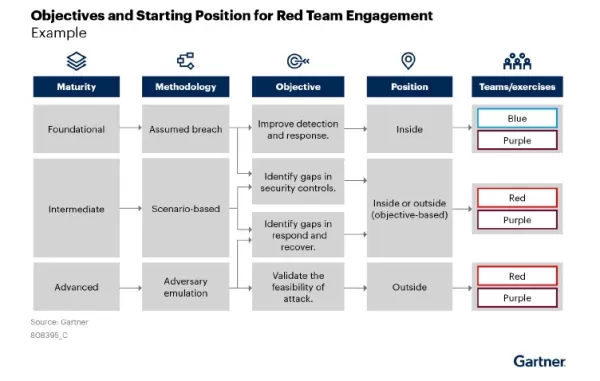
ガートナー社のフレームワークは、基礎的なドリルから高度なシミュレーションまで、レッドチーミングの段階的な成熟度を示しています。 出典出典:ガートナー、レッドチーム演習の実施によるサイバー耐性の向上 AIの脅威に対して従来のサイバーセキュリティが不十分な理由
従来のサイバーセキュリティ手法は、AI主導の攻撃に対して苦戦を強いられる。敵対的な戦術が従来の防御を凌駕するにつれ、新たなレッド・チーミングのテクニックが必要となります。以下に、DevOps サイクル中およびデプロイ後の AI モデルを標的とするために特別に設計された攻撃手法をいくつか紹介する:
- データポイズニング:データポイズニング:攻撃者は悪意のあるデータや偏ったデータをトレーニングデータセットに導入し、AIモデルの不正確な学習を引き起こします。これにより、検出されないまま持続的なエラーや運用上の欠陥が発生し、AI主導の成果に対する信頼が損なわれます。
- モデル回避:敵は、静的ルールやパターンベースのセキュリティシステムの限界を悪用して、検出メカニズムを回避するために入力を微妙に変更します。
- モデルの逆転:組織的なクエリーを繰り返すことで、攻撃者はトレーニングで使用した機密データを再構築したり、暴露したりすることができ、深刻なプライバシー侵害につながります。
- プロンプト・インジェクション:攻撃者は、生成AIを操作してセーフガードを無視するような入力を設計し、有害な、意図しない、または未承認のコンテンツを生成する可能性がある。
- デュアルユース・フロンティアリスク:最近の論文「Benchmark Early and Red Team Often」で強調されている:A Framework for Assessing and Managing Dual-Use Hazards of AI Foundation Models(AI基盤モデルの二重使用の危険性を評価し管理するためのフレームワーク)」で強調されているように、カリフォルニア大学バークレー校の長期サイバーセキュリティセンターの研究者は、高度なAIモデルは、複雑なサイバー攻撃、化学的脅威、その他の危険な悪用を実行するための専門家以外の障壁を低くし、世界的なリスクを大幅に増幅させると警告している。
統合された機械学習オペレーション(MLOps)の相互接続性は、こうしたリスクをさらに増幅させる。LLMと広範なAI開発パイプラインは攻撃対象領域を拡大し、より洗練されたレッドチーム活動を要求している。
こうした進化するAIの脅威に対抗するため、サイバーセキュリティのリーダーは継続的な敵対的テストを採用している。実際のAI攻撃をシミュレートする構造化されたレッドチーム演習は、隠れた弱点を特定し、それが悪用される前にセキュリティギャップを埋めるために、今や不可欠なものとなっている。
先進的なAI組織が攻撃者を出し抜くためにレッドチームを活用する方法
攻撃者はますますAIを利用して、従来のセキュリティ制御を回避する前例のない攻撃手法を開発するようになっています。彼らの目的は、できるだけ多くの新たな脆弱性を発見し、悪用することです。
これに対し、トップクラスのAI企業は、組織的なレッド・チーミングをセキュリティ戦略の要としています。レッド・チーミングを散発的に実施するのではなく、人間の専門知識、統制された自動化、反復的な人間によるイン・ザ・ループ評価を融合させた継続的な敵対的テストを実施している。このプロアクティブなアプローチは、脅威が武器化される前に特定し、無力化するのに役立ちます。
厳格なテスト方法論を通じて、これらのリーダーは体系的に弱点を特定し、実世界の敵対シナリオに対してモデルを強化します。
主なアプローチ
- Anthropicは、継続的なレッドチームプロセスの中で、厳格な人的評価を活用しています。人間による評価を自動化された敵対的攻撃と統合することで、同社は積極的に脆弱性を発見し、モデルの信頼性と解釈可能性を継続的に強化しています。
- Metaは、自動化第一のアプローチによってセキュリティを拡張します。同社のMART(Multi-round Automatic Red-Teaming)システムは、敵対的なプロンプトを繰り返し生成することで、大規模なAI導入において隠れた欠陥を迅速に特定し、攻撃ベクトルを絞り込む。
- マイクロソフトは、レッドチーミングの効果を高めるために、学際的なコラボレーションに依存している。Python Risk Identification Toolkit (PyRIT)を使用することで、マイクロソフトはサイバーセキュリティのノウハウと高度なアナリティクスおよび人間による検証を組み合わせ、脆弱性の発見を迅速化し、モデルの回復力を強化するための実用的な洞察を提供します。
- OpenAIは、グローバルなセキュリティ専門家と連携し、AIによる防御を大規模に強化しています。OpenAIは、外部の専門家の知見を自動敵対的テストと人間による検証サイクルと融合させることで、高度な脅威、特に誤情報やプロンプトインジェクションリスクに対処し、堅牢で信頼できるモデルのパフォーマンスを維持します。
要するに、一流のAI企業は、攻撃者の先を行くには、揺るぎない積極的な努力が必要であることを認識しています。これらの企業は、レッド・チーミングの取り組みに、構造化された人的監視、規律ある自動化、反復的な改良を組み込むことで、レジリエントで信頼性の高いAIシステムを構築するためのベンチマークを確立しています。
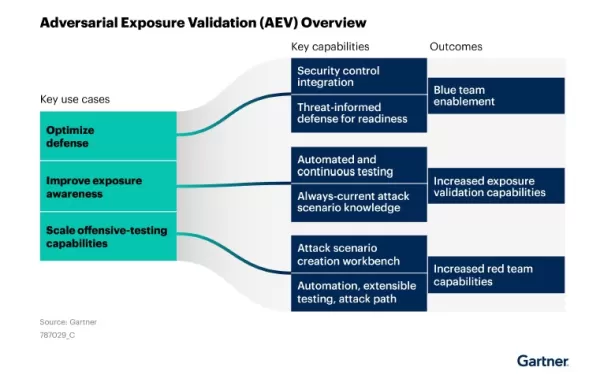
ガートナーは、敵対的暴露検証(AEV)がどのように最適化された防御戦略、脅威認識の向上、拡張可能な攻撃テストをサポートするかを説明しています。出典ガートナー、敵対的暴露検証のマーケットガイド AIセキュリティを強化するための5つの実行可能な戦略
LLMやAIモデルに対する攻撃が複雑化する中、DevOpsチームとDevSecOpsチームは緊密に連携してAIセキュリティを強化する必要がある。VentureBeatは、セキュリティリーダーがすぐに実行できる、インパクトの大きい5つの戦略を推奨する:
- 早期にセキュリティを統合する(Anthropic、OpenAI)
敵対的テストを初期設計フェーズに直接組み込み、モデルのライフサイクル全体にわたって持続させる。早期に脆弱性を検出することで、リスクを低減し、混乱を最小化し、長期的なコストを削減する。
- 適応的なリアルタイム・モニタリングの導入(マイクロソフト)
高度なAIの脅威に対しては、静的な防御では不十分です。CyberAllyのようなAIを活用した継続的な監視ツールを使用することで、微妙な異常を迅速に検出し、悪用の機会を減らすことができます。
- 自動化と人間の判断のバランス(Meta、Microsoft)
自動化だけではニュアンスに欠け、手動テストでは拡張性がない。自動化された敵対的スキャンと脆弱性評価を専門家の分析と組み合わせることで、正確で実用的な結果を得ることができます。
- 外部のレッドチームを定期的に参加させる(OpenAI)
内部チームには盲点があります。定期的な外部レッドチームの評価により、見過ごされていた弱点を発見し、独立した検証を行い、継続的なセキュリティ改善を推進する。
- 動的脅威インテリジェンスの維持(Meta、Microsoft、OpenAI)
攻撃者は常に手法を改良しています。リアルタイムの脅威インテリジェンス、自動分析、専門家の洞察を継続的に統合し、防御策をプロアクティブに更新・強化する。
これらの戦略を組み合わせることで、急速に進化する敵対的脅威に直面しても、DevOpsワークフローが弾力性と安全性を維持できるようになります。
レッドチームは今や必須であり、オプションではない
AIの脅威は、従来の消極的なサイバーセキュリティでは効果的に管理できないほど高度化し、頻発している。防御力を維持するために、組織はモデル開発のあらゆる段階に継続的な敵対的テストを組み込む必要がある。自動化と人間の洞察力のバランスを取り、防御をダイナミックに適応させることで、主要なAIプロバイダーは、強力なセキュリティと迅速なイノベーションが両立できることを実証している。
最終的に、レッドチームはAIモデルを保護する以上のものであり、AI主導の未来における信頼性、回復力、信頼性を構築するものである。
Transform 2025で議論に参加しよう
私は、6月24~25日にサンフランシスコのフォート・メイソンで開催されるVentureBeatのTransform 2025で、サイバーセキュリティに焦点を当てた2つのラウンドテーブル・ディスカッションをリードします。参加登録は今すぐ。
1つは、「AI Red Teaming and Adversarial Testing」と題したセッションで、AIを活用したサイバーセキュリティ・ソリューションを高度な敵対的脅威に対してテストし、強化するための戦略を探る。
関連記事
 リライト用の記事タイトルを教えていただけますか?
かつてプロ仕様のポートレート写真を撮るには、カメラマンを雇い、スタジオを借り、少なくとも1時間は時間を確保する必要がありました。今日では、AIを活用したプラットフォームが増え、そうした手間を省きながらも、洗練された、そのまま公開できるような画像を手に入れられると謳うサービスが数多く登場しています。その約束を果たすサービスもあれば、そうでないサービスも数多く存在します。価値のあるAIヘッドショットと
ElevenLabs、ブラックロック、ジェイミー・フォックス、エヴァ・ロンゴリアを新たな投資家として発表
音声AI企業であるElevenLabsは、2月に発表された5億ドルのシリーズDラウンドにおいて、追加の投資家名を明らかにした。 これには、ブラックロック、ウェリントン、D.E.ショー、シュローダーズといった機関投資家、NVIDIA、セールスフォース、サンタンデール、KPN、ドイツテレコムなどの企業、そしてジェイミー・フォックス、エヴァ・ロンゴリア、『Squid Game』のクリエイターであるファン
OpenAIのCEOアルトマン氏、パニックに駆られたマーケティング戦略を展開するAnthropicを痛烈に批判
AI業界のリーダーであるOpenAIとAnthropicの間で続いている公開の論争が激化している。OpenAIのCEOであるサム・アルトマン氏は先日、ポッドキャストの中で、競合他社の最新の安全モデルに異議を唱えた。アルトマン氏は、Anthropicがテクノロジーに対する世間の不安を利用し、自社製品の実際の能力を過大評価していると主張している。彼はこのアプローチを、真の安全対策というよりはマーケティ
関連特集おすすめ
仕事
リライト用の記事タイトルを教えていただけますか?
かつてプロ仕様のポートレート写真を撮るには、カメラマンを雇い、スタジオを借り、少なくとも1時間は時間を確保する必要がありました。今日では、AIを活用したプラットフォームが増え、そうした手間を省きながらも、洗練された、そのまま公開できるような画像を手に入れられると謳うサービスが数多く登場しています。その約束を果たすサービスもあれば、そうでないサービスも数多く存在します。価値のあるAIヘッドショットと
ElevenLabs、ブラックロック、ジェイミー・フォックス、エヴァ・ロンゴリアを新たな投資家として発表
音声AI企業であるElevenLabsは、2月に発表された5億ドルのシリーズDラウンドにおいて、追加の投資家名を明らかにした。 これには、ブラックロック、ウェリントン、D.E.ショー、シュローダーズといった機関投資家、NVIDIA、セールスフォース、サンタンデール、KPN、ドイツテレコムなどの企業、そしてジェイミー・フォックス、エヴァ・ロンゴリア、『Squid Game』のクリエイターであるファン
OpenAIのCEOアルトマン氏、パニックに駆られたマーケティング戦略を展開するAnthropicを痛烈に批判
AI業界のリーダーであるOpenAIとAnthropicの間で続いている公開の論争が激化している。OpenAIのCEOであるサム・アルトマン氏は先日、ポッドキャストの中で、競合他社の最新の安全モデルに異議を唱えた。アルトマン氏は、Anthropicがテクノロジーに対する世間の不安を利用し、自社製品の実際の能力を過大評価していると主張している。彼はこのアプローチを、真の安全対策というよりはマーケティ
関連特集おすすめ
仕事
 最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
 10 ツール
10 ツール
 xix.ai
アニメーション制作
東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
xix.ai
アニメーション制作
東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai
漫画制作
漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
書き込み
AI小説プロファイル作成のトップクリエイター:一貫性のあるキャラクターの動機と致命的な欠点を生成する
深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai
仕事
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
編集部注:ルイスは今月末、VB Transformでこのテーマに関する編集ラウンドテーブルの司会を務める。今すぐ登録してください。
AIモデルは容赦ない攻撃に直面している。企業の77%がすでに敵対的攻撃の標的になっており、そのうちの41%がプロンプト・インジェクションやデータ・ポイズニングに関与している。
この流れを変えるには、今日のAIモデルにどのようにセキュリティを組み込むかを根本的に考え直す必要がある。DevOpsチームは、開発ライフサイクル全体を通じて継続的な敵対的テストを組み込む方向に、反応的な姿勢からシフトしなければならない。
AI防御の中心をレッドチーム化する
DevOpsサイクルを通じて大規模言語モデル(LLM)を保護するには、レッド・チーミングを中核的なプラクティスとして統合する必要がある。Webアプリケーションのパイプラインでよく見られるように、セキュリティを最終チェックポイントとして扱うのではなく、継続的な敵対的テストをソフトウェア開発ライフサイクル(SDLC)のすべてのフェーズに組み込む必要がある。
プロンプト・インジェクション、データ・ポイズニング、機密情報の漏えいといった脅威の増加に対抗するためには、より統合的なDevSecOpsアプローチが不可欠になっている。このような危険な攻撃は、モデル設計からデプロイまで、ますます一般的になっており、常時監視の緊急性が高まっている。
マイクロソフト社が最近発表した、LLMとそのアプリケーションに対するレッドチーム演習の計画に関するガイドラインは、統合されたセキュリティ・プロセスの確かな出発点を示している。同様に、NISTのAIリスクマネジメントフレームワークは、敵対的なテストとリスク削減に対する、ライフサイクル指向のプロアクティブなアプローチを求めている。マイクロソフトが100以上のジェネレーティブAI製品をテストした結果、モデル開発全体を通じて自動脅威検知と専門家による分析を組み合わせる必要性が強化された。
EUのAI法のような規制が厳しい敵対的テスト要件を課す中、継続的なレッドチームはコンプライアンスを保証するだけでなく、全体的なセキュリティ回復力を向上させます。
OpenAIは、初期設計から配備まで外部のレッド・チーミングを取り入れ、一貫した予防的セキュリティ・テストがLLM開発の成功に不可欠であることを検証しています。
AIの脅威に対して従来のサイバーセキュリティが不十分な理由
従来のサイバーセキュリティ手法は、AI主導の攻撃に対して苦戦を強いられる。敵対的な戦術が従来の防御を凌駕するにつれ、新たなレッド・チーミングのテクニックが必要となります。以下に、DevOps サイクル中およびデプロイ後の AI モデルを標的とするために特別に設計された攻撃手法をいくつか紹介する:
- データポイズニング:データポイズニング:攻撃者は悪意のあるデータや偏ったデータをトレーニングデータセットに導入し、AIモデルの不正確な学習を引き起こします。これにより、検出されないまま持続的なエラーや運用上の欠陥が発生し、AI主導の成果に対する信頼が損なわれます。
- モデル回避:敵は、静的ルールやパターンベースのセキュリティシステムの限界を悪用して、検出メカニズムを回避するために入力を微妙に変更します。
- モデルの逆転:組織的なクエリーを繰り返すことで、攻撃者はトレーニングで使用した機密データを再構築したり、暴露したりすることができ、深刻なプライバシー侵害につながります。
- プロンプト・インジェクション:攻撃者は、生成AIを操作してセーフガードを無視するような入力を設計し、有害な、意図しない、または未承認のコンテンツを生成する可能性がある。
- デュアルユース・フロンティアリスク:最近の論文「Benchmark Early and Red Team Often」で強調されている:A Framework for Assessing and Managing Dual-Use Hazards of AI Foundation Models(AI基盤モデルの二重使用の危険性を評価し管理するためのフレームワーク)」で強調されているように、カリフォルニア大学バークレー校の長期サイバーセキュリティセンターの研究者は、高度なAIモデルは、複雑なサイバー攻撃、化学的脅威、その他の危険な悪用を実行するための専門家以外の障壁を低くし、世界的なリスクを大幅に増幅させると警告している。
統合された機械学習オペレーション(MLOps)の相互接続性は、こうしたリスクをさらに増幅させる。LLMと広範なAI開発パイプラインは攻撃対象領域を拡大し、より洗練されたレッドチーム活動を要求している。
こうした進化するAIの脅威に対抗するため、サイバーセキュリティのリーダーは継続的な敵対的テストを採用している。実際のAI攻撃をシミュレートする構造化されたレッドチーム演習は、隠れた弱点を特定し、それが悪用される前にセキュリティギャップを埋めるために、今や不可欠なものとなっている。
先進的なAI組織が攻撃者を出し抜くためにレッドチームを活用する方法
攻撃者はますますAIを利用して、従来のセキュリティ制御を回避する前例のない攻撃手法を開発するようになっています。彼らの目的は、できるだけ多くの新たな脆弱性を発見し、悪用することです。
これに対し、トップクラスのAI企業は、組織的なレッド・チーミングをセキュリティ戦略の要としています。レッド・チーミングを散発的に実施するのではなく、人間の専門知識、統制された自動化、反復的な人間によるイン・ザ・ループ評価を融合させた継続的な敵対的テストを実施している。このプロアクティブなアプローチは、脅威が武器化される前に特定し、無力化するのに役立ちます。
厳格なテスト方法論を通じて、これらのリーダーは体系的に弱点を特定し、実世界の敵対シナリオに対してモデルを強化します。
主なアプローチ
- Anthropicは、継続的なレッドチームプロセスの中で、厳格な人的評価を活用しています。人間による評価を自動化された敵対的攻撃と統合することで、同社は積極的に脆弱性を発見し、モデルの信頼性と解釈可能性を継続的に強化しています。
- Metaは、自動化第一のアプローチによってセキュリティを拡張します。同社のMART(Multi-round Automatic Red-Teaming)システムは、敵対的なプロンプトを繰り返し生成することで、大規模なAI導入において隠れた欠陥を迅速に特定し、攻撃ベクトルを絞り込む。
- マイクロソフトは、レッドチーミングの効果を高めるために、学際的なコラボレーションに依存している。Python Risk Identification Toolkit (PyRIT)を使用することで、マイクロソフトはサイバーセキュリティのノウハウと高度なアナリティクスおよび人間による検証を組み合わせ、脆弱性の発見を迅速化し、モデルの回復力を強化するための実用的な洞察を提供します。
- OpenAIは、グローバルなセキュリティ専門家と連携し、AIによる防御を大規模に強化しています。OpenAIは、外部の専門家の知見を自動敵対的テストと人間による検証サイクルと融合させることで、高度な脅威、特に誤情報やプロンプトインジェクションリスクに対処し、堅牢で信頼できるモデルのパフォーマンスを維持します。
要するに、一流のAI企業は、攻撃者の先を行くには、揺るぎない積極的な努力が必要であることを認識しています。これらの企業は、レッド・チーミングの取り組みに、構造化された人的監視、規律ある自動化、反復的な改良を組み込むことで、レジリエントで信頼性の高いAIシステムを構築するためのベンチマークを確立しています。
AIセキュリティを強化するための5つの実行可能な戦略
LLMやAIモデルに対する攻撃が複雑化する中、DevOpsチームとDevSecOpsチームは緊密に連携してAIセキュリティを強化する必要がある。VentureBeatは、セキュリティリーダーがすぐに実行できる、インパクトの大きい5つの戦略を推奨する:
- 早期にセキュリティを統合する(Anthropic、OpenAI)
敵対的テストを初期設計フェーズに直接組み込み、モデルのライフサイクル全体にわたって持続させる。早期に脆弱性を検出することで、リスクを低減し、混乱を最小化し、長期的なコストを削減する。
- 適応的なリアルタイム・モニタリングの導入(マイクロソフト)
高度なAIの脅威に対しては、静的な防御では不十分です。CyberAllyのようなAIを活用した継続的な監視ツールを使用することで、微妙な異常を迅速に検出し、悪用の機会を減らすことができます。
- 自動化と人間の判断のバランス(Meta、Microsoft)
自動化だけではニュアンスに欠け、手動テストでは拡張性がない。自動化された敵対的スキャンと脆弱性評価を専門家の分析と組み合わせることで、正確で実用的な結果を得ることができます。
- 外部のレッドチームを定期的に参加させる(OpenAI)
内部チームには盲点があります。定期的な外部レッドチームの評価により、見過ごされていた弱点を発見し、独立した検証を行い、継続的なセキュリティ改善を推進する。
- 動的脅威インテリジェンスの維持(Meta、Microsoft、OpenAI)
攻撃者は常に手法を改良しています。リアルタイムの脅威インテリジェンス、自動分析、専門家の洞察を継続的に統合し、防御策をプロアクティブに更新・強化する。
これらの戦略を組み合わせることで、急速に進化する敵対的脅威に直面しても、DevOpsワークフローが弾力性と安全性を維持できるようになります。
レッドチームは今や必須であり、オプションではない
AIの脅威は、従来の消極的なサイバーセキュリティでは効果的に管理できないほど高度化し、頻発している。防御力を維持するために、組織はモデル開発のあらゆる段階に継続的な敵対的テストを組み込む必要がある。自動化と人間の洞察力のバランスを取り、防御をダイナミックに適応させることで、主要なAIプロバイダーは、強力なセキュリティと迅速なイノベーションが両立できることを実証している。
最終的に、レッドチームはAIモデルを保護する以上のものであり、AI主導の未来における信頼性、回復力、信頼性を構築するものである。
Transform 2025で議論に参加しよう
私は、6月24~25日にサンフランシスコのフォート・メイソンで開催されるVentureBeatのTransform 2025で、サイバーセキュリティに焦点を当てた2つのラウンドテーブル・ディスカッションをリードします。参加登録は今すぐ。
1つは、「AI Red Teaming and Adversarial Testing」と題したセッションで、AIを活用したサイバーセキュリティ・ソリューションを高度な敵対的脅威に対してテストし、強化するための戦略を探る。










 リライト用の記事タイトルを教えていただけますか?
かつてプロ仕様のポートレート写真を撮るには、カメラマンを雇い、スタジオを借り、少なくとも1時間は時間を確保する必要がありました。今日では、AIを活用したプラットフォームが増え、そうした手間を省きながらも、洗練された、そのまま公開できるような画像を手に入れられると謳うサービスが数多く登場しています。その約束を果たすサービスもあれば、そうでないサービスも数多く存在します。価値のあるAIヘッドショットと
リライト用の記事タイトルを教えていただけますか?
かつてプロ仕様のポートレート写真を撮るには、カメラマンを雇い、スタジオを借り、少なくとも1時間は時間を確保する必要がありました。今日では、AIを活用したプラットフォームが増え、そうした手間を省きながらも、洗練された、そのまま公開できるような画像を手に入れられると謳うサービスが数多く登場しています。その約束を果たすサービスもあれば、そうでないサービスも数多く存在します。価値のあるAIヘッドショットと
 ElevenLabs、ブラックロック、ジェイミー・フォックス、エヴァ・ロンゴリアを新たな投資家として発表
音声AI企業であるElevenLabsは、2月に発表された5億ドルのシリーズDラウンドにおいて、追加の投資家名を明らかにした。 これには、ブラックロック、ウェリントン、D.E.ショー、シュローダーズといった機関投資家、NVIDIA、セールスフォース、サンタンデール、KPN、ドイツテレコムなどの企業、そしてジェイミー・フォックス、エヴァ・ロンゴリア、『Squid Game』のクリエイターであるファン
ElevenLabs、ブラックロック、ジェイミー・フォックス、エヴァ・ロンゴリアを新たな投資家として発表
音声AI企業であるElevenLabsは、2月に発表された5億ドルのシリーズDラウンドにおいて、追加の投資家名を明らかにした。 これには、ブラックロック、ウェリントン、D.E.ショー、シュローダーズといった機関投資家、NVIDIA、セールスフォース、サンタンデール、KPN、ドイツテレコムなどの企業、そしてジェイミー・フォックス、エヴァ・ロンゴリア、『Squid Game』のクリエイターであるファン
 OpenAIのCEOアルトマン氏、パニックに駆られたマーケティング戦略を展開するAnthropicを痛烈に批判
AI業界のリーダーであるOpenAIとAnthropicの間で続いている公開の論争が激化している。OpenAIのCEOであるサム・アルトマン氏は先日、ポッドキャストの中で、競合他社の最新の安全モデルに異議を唱えた。アルトマン氏は、Anthropicがテクノロジーに対する世間の不安を利用し、自社製品の実際の能力を過大評価していると主張している。彼はこのアプローチを、真の安全対策というよりはマーケティ
OpenAIのCEOアルトマン氏、パニックに駆られたマーケティング戦略を展開するAnthropicを痛烈に批判
AI業界のリーダーであるOpenAIとAnthropicの間で続いている公開の論争が激化している。OpenAIのCEOであるサム・アルトマン氏は先日、ポッドキャストの中で、競合他社の最新の安全モデルに異議を唱えた。アルトマン氏は、Anthropicがテクノロジーに対する世間の不安を利用し、自社製品の実際の能力を過大評価していると主張している。彼はこのアプローチを、真の安全対策というよりはマーケティ

XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai

2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai

XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai













