
















 Heim
Heim
Chancen und Hindernisse tauchen auf, wenn Red Team AI versucht, sicherere und intelligentere Modelle für morgen zu entwickeln.
Anmerkung des Herausgebers: Louis wird Ende des Monats bei VB Transform einen redaktionellen Rundtisch zu diesem Thema moderieren. Jetzt anmelden.
KI-Modelle sind unerbittlichen Angriffen ausgesetzt. 77 % der Unternehmen sind bereits Ziel von Angriffen - 41 % davon mit Prompt Injections und Data Poisoning - und die Methoden der Angreifer entwickeln sich schneller als die aktuelle Cyberabwehr.
Um das Blatt zu wenden, müssen wir grundlegend überdenken, wie die Sicherheit in die heutigen KI-Modelle integriert wird. DevOps-Teams müssen sich von einer reaktionären Haltung verabschieden und kontinuierliche Tests gegen Angreifer in den gesamten Entwicklungszyklus einbetten.
Red Teaming als zentrales Element der KI-Verteidigung
Die Absicherung großer Sprachmodelle (LLMs) während des gesamten DevOps-Zyklus erfordert die Integration von Red Teaming als zentrale Praxis. Anstatt die Sicherheit als letzten Kontrollpunkt zu behandeln - wie es bei Webanwendungs-Pipelines üblich ist - müssen kontinuierliche Gegentests in jede Phase des Softwareentwicklungs-Lebenszyklus (SDLC) eingebettet werden.
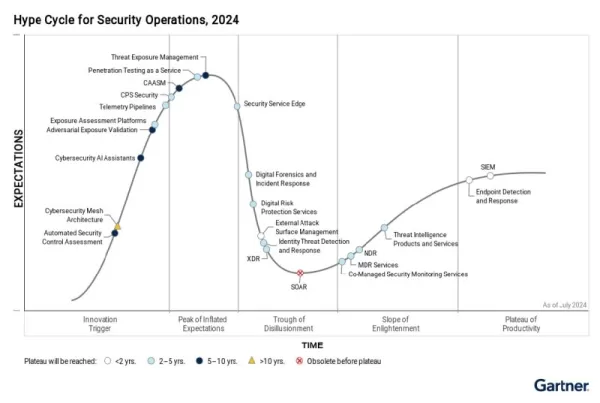
Der Hype Cycle von Gartner unterstreicht die wachsende Bedeutung des Continuous Threat Exposure Management (CTEM) und zeigt, warum Red Teaming ein integraler Bestandteil des DevSecOps-Lebenszyklus werden muss. Quelle: Gartner, Hype Cycle für Sicherheitsoperationen, 2024 Ein stärker integrierter DevSecOps-Ansatz ist unabdingbar, um zunehmenden Bedrohungen wie Prompt Injection, Data Poisoning und der Preisgabe sensibler Informationen zu begegnen. Solche gefährlichen Angriffe treten immer häufiger auf, vom Modelldesign bis zur Bereitstellung, was die Dringlichkeit einer ständigen Überwachung unterstreicht.
Die jüngsten Richtlinien von Microsoft zur Planung von Red-Team-Übungen für LLMs und ihre Anwendungen bieten einen soliden Ausgangspunkt für einen integrierten Sicherheitsprozess. In ähnlicher Weise fordert das NIST AI Risk Management Framework einen proaktiven, lebenszyklusorientierten Ansatz für gegnerische Tests und Risikominderung. Microsofts Test von mehr als 100 generativen KI-Produkten unterstreicht die Notwendigkeit, die automatische Erkennung von Bedrohungen während der gesamten Modellentwicklung mit Expertenanalysen zu kombinieren.
Da Vorschriften wie das KI-Gesetz der EU strenge Anforderungen an das Testen von Angreifern stellen, gewährleistet ein fortlaufendes Red Teaming nicht nur die Einhaltung der Vorschriften, sondern verbessert auch die allgemeine Sicherheitswiderstandsfähigkeit.
OpenAI integriert externes Red Teaming vom ersten Entwurf bis zur Bereitstellung und bestätigt damit, dass konsistente, präventive Sicherheitstests für eine erfolgreiche LLM-Entwicklung unerlässlich sind.
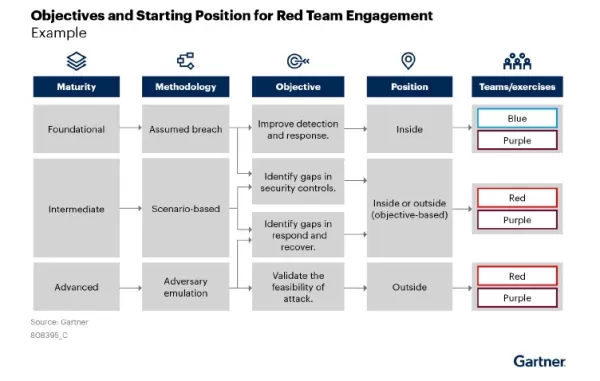
Gartners Rahmenwerk veranschaulicht die progressiven Reifestufen für Red Teaming, von grundlegenden Übungen bis hin zu fortgeschrittenen Simulationen - der Schlüssel zur systematischen Verstärkung des KI-Modellschutzes. Quelle: Gartner, Improve Cyber Resilience by Conducting Red Team Exercises Warum konventionelle Cybersicherheit gegen KI-Bedrohungen versagt
Herkömmliche Cybersecurity-Methoden haben es schwer gegen KI-gesteuerte Angriffe, da diese Bedrohungen auf völlig anderen Prinzipien beruhen. Da die Taktiken der Angreifer konventionelle Verteidigungsmaßnahmen übertreffen, sind neue Red Teaming-Techniken erforderlich. Im Folgenden werden mehrere Angriffsmethoden vorgestellt, die speziell für KI-Modelle während der DevOps-Zyklen und nach der Bereitstellung entwickelt wurden:
- Datenverfälschung: Angreifer schleusen bösartige oder verzerrte Daten in Trainingsdatensätze ein, wodurch KI-Modelle ungenau lernen. Dies führt zu dauerhaften Fehlern und betrieblichen Mängeln, die unentdeckt bleiben können und das Vertrauen in KI-gesteuerte Ergebnisse untergraben.
- Modellumgehung: Angreifer verändern auf subtile Weise die Eingaben, um Erkennungsmechanismen zu umgehen und die Grenzen statischer Regeln und musterbasierter Sicherheitssysteme auszunutzen.
- Modellumkehrung: Durch wiederholte, systematische Abfragen können Angreifer vertrauliche Daten, die beim Training verwendet wurden, rekonstruieren oder offenlegen, was zu schwerwiegenden Datenschutzverletzungen führt.
- Prompt-Injektion: Angreifer entwerfen Eingaben, die die generative KI so manipulieren, dass sie Sicherheitsvorkehrungen ignorieren und potenziell schädliche, unbeabsichtigte oder nicht autorisierte Inhalte produzieren.
- Dual-Use-Grenzrisiken: Wie in dem kürzlich erschienenen Papier " Benchmark Early and Red Team Often: A Framework for Assessing and Managing Dual-Use Hazards of AI Foundation Models, warnen Forscher des Center for Long-Term Cybersecurity der UC Berkeley davor, dass fortschrittliche KI-Modelle die Hürde für Laien senken, komplexe Cyberangriffe, chemische Bedrohungen oder andere gefährliche Exploits auszuführen - was die globalen Risiken erheblich erhöht.
Die Verflechtung von integrierten Machine Learning Operations (MLOps) verstärkt diese Risiken noch. LLM und breitere KI-Entwicklungspipelines erweitern die Angriffsfläche und erfordern ausgefeiltere Red-Teaming-Verfahren.
Um diesen sich weiterentwickelnden KI-Bedrohungen entgegenzuwirken, führen Cybersecurity-Führungskräfte kontinuierliche Tests mit Gegenspielern durch. Strukturierte Red-Team-Übungen, die reale KI-Angriffe simulieren, sind jetzt entscheidend, um versteckte Schwachstellen zu identifizieren und Sicherheitslücken zu schließen, bevor sie ausgenutzt werden.
Wie führende KI-Organisationen Red Teaming nutzen, um Angreifern zuvorzukommen
Angreifer setzen zunehmend KI ein, um noch nie dagewesene Angriffsmethoden zu entwickeln, die sich herkömmlichen Sicherheitskontrollen entziehen. Ihr Ziel ist es, so viele neue Schwachstellen wie möglich aufzudecken und auszunutzen.
Als Reaktion darauf haben führende KI-Unternehmen systematisches Red Teaming zu einem Eckpfeiler ihrer Sicherheitsstrategie gemacht. Anstatt Red Teaming nur sporadisch durchzuführen, implementieren sie kontinuierliche Gegentests, die menschliches Fachwissen, disziplinierte Automatisierung und iterative Bewertungen durch den Menschen in der Schleife kombinieren. Dieser proaktive Ansatz hilft dabei, Bedrohungen zu erkennen und zu neutralisieren, bevor sie zur Waffe werden können.
Durch rigorose Testmethoden identifizieren diese Führungskräfte systematisch Schwachstellen und stärken ihre Modelle gegenüber realen Angriffsszenarien.
Die wichtigsten Ansätze sind:
- Anthropic nutzt rigorose menschliche Bewertungen im Rahmen seines laufenden Red-Teaming-Prozesses. Durch die Integration von Human-in-the-Loop-Bewertungen mit automatisierten gegnerischen Angriffen deckt das Unternehmen proaktiv Schwachstellen auf und verbessert kontinuierlich die Zuverlässigkeit und Interpretierbarkeit seiner Modelle.
- Meta skaliert die Sicherheit durch einen Ansatz, bei dem die Automatisierung im Vordergrund steht. Sein MART-System (Multi-round Automatic Red-Teaming) generiert iterativ gegnerische Aufforderungen, um versteckte Schwachstellen schnell zu identifizieren und Angriffsvektoren in groß angelegten KI-Implementierungen einzugrenzen.
- Microsoft setzt auf interdisziplinäre Zusammenarbeit, um die Effektivität des Red-Teaming zu gewährleisten. Mit seinem Python Risk Identification Toolkit (PyRIT) kombiniert Microsoft Cybersecurity-Know-how mit fortschrittlicher Analytik und menschlicher Validierung, um die Entdeckung von Schwachstellen zu beschleunigen und umsetzbare Erkenntnisse zur Stärkung der Modellresilienz zu liefern.
- OpenAI setzt globale Sicherheitsexperten ein, um die KI-Abwehr in großem Umfang zu verbessern. Durch die Kombination von Erkenntnissen externer Experten mit automatisierten gegnerischen Tests und menschlichen Validierungszyklen begegnet OpenAI anspruchsvollen Bedrohungen - insbesondere Fehlinformationen und Prompt-Injection-Risiken -, um eine robuste und vertrauenswürdige Modellleistung zu gewährleisten.
Führende KI-Organisationen haben erkannt, dass es unermüdlicher, proaktiver Anstrengungen bedarf, um Angreifern einen Schritt voraus zu sein. Durch die Einbindung strukturierter menschlicher Aufsicht, disziplinierter Automatisierung und iterativer Verfeinerung in ihre Red-Teaming-Bemühungen setzen diese Unternehmen einen Maßstab für den Aufbau widerstandsfähiger und vertrauenswürdiger KI-Systeme.
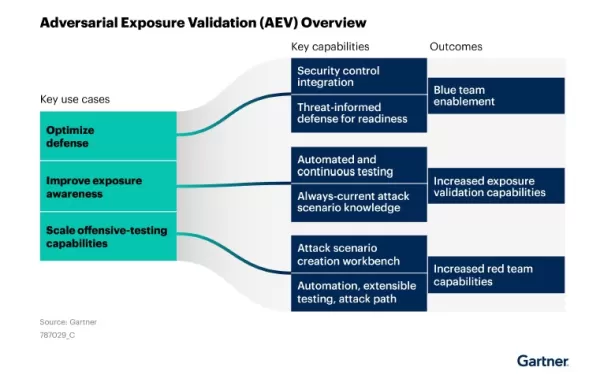
Gartner veranschaulicht, wie die Adversarial Exposure Validation (AEV) optimierte Verteidigungsstrategien, ein verbessertes Bedrohungsbewusstsein und skalierbare Offensivtests unterstützt, die für die Sicherung von KI-Modellen unerlässlich sind. Quelle: Gartner, Marktleitfaden für Adversarial Exposure Validation Fünf umsetzbare Strategien, um die KI-Sicherheit jetzt zu verbessern
Da die Angriffe auf LLMs und KI-Modelle immer komplexer werden, müssen DevOps- und DevSecOps-Teams eng zusammenarbeiten, um die KI-Sicherheit zu verbessern. VentureBeat empfiehlt diese fünf hochwirksamen Strategien, die Sicherheitsverantwortliche sofort umsetzen können:
- Sicherheit frühzeitig einbinden (Anthropic, OpenAI)
Integrieren Sie negative Tests direkt in die anfängliche Designphase und führen Sie diese über den gesamten Lebenszyklus des Modells durch. Die frühzeitige Erkennung von Schwachstellen verringert das Risiko, minimiert Unterbrechungen und senkt die langfristigen Kosten.
- Einsatz einer adaptiven Echtzeit-Überwachung (Microsoft)
Statische Schutzmaßnahmen reichen nicht aus, um fortschrittliche KI-Bedrohungen abzuwehren. Verwenden Sie kontinuierliche KI-gestützte Überwachungstools wie CyberAlly, um subtile Anomalien schnell zu erkennen und das Zeitfenster für einen Angriff zu verringern.
- Gleichgewicht zwischen Automatisierung und menschlichem Urteilsvermögen (Meta, Microsoft)
Der Automatisierung allein fehlt es an Nuancen, und manuelle Tests lassen sich nicht skalieren. Kombinieren Sie automatisierte gegnerische Scans und Schwachstellenbewertungen mit der Analyse von Experten, um genaue und umsetzbare Ergebnisse zu erhalten.
- Ziehen Sie regelmäßig externe Red Teams hinzu (OpenAI)
Interne Teams können blinde Flecken entwickeln. Regelmäßige Bewertungen durch externe Red Teams decken übersehene Schwachstellen auf, bieten eine unabhängige Validierung und treiben laufende Sicherheitsverbesserungen voran.
- Pflegen Sie dynamische Bedrohungsdaten (Meta, Microsoft, OpenAI)
Angreifer verfeinern ihre Methoden ständig. Integrieren Sie kontinuierlich Echtzeit-Bedrohungsdaten, automatisierte Analysen und Erkenntnisse von Experten, um Ihre Verteidigungsmaßnahmen proaktiv zu aktualisieren und zu verstärken.
Gemeinsam helfen diese Strategien DevOps-Workflows, angesichts der sich schnell entwickelnden Bedrohungen widerstandsfähig und sicher zu bleiben.
Red Teaming ist jetzt unerlässlich, nicht optional
KI-Bedrohungen sind mittlerweile zu ausgeklügelt und häufig, als dass sie mit herkömmlicher, reaktiver Cybersicherheit effektiv bewältigt werden könnten. Um einen Verteidigungsvorteil zu erhalten, müssen Unternehmen kontinuierliche Tests mit Angreifern in jede Phase der Modellentwicklung einbeziehen. Führende KI-Anbieter zeigen, dass starke Sicherheit und schnelle Innovation Hand in Hand gehen können, indem sie ein Gleichgewicht zwischen Automatisierung und menschlicher Einsicht herstellen und die Verteidigungsmaßnahmen dynamisch anpassen.
Letztlich geht es bei Red Teaming um mehr als nur den Schutz von KI-Modellen - es geht um den Aufbau von Vertrauen, Widerstandsfähigkeit und Zuversicht in eine KI-gesteuerte Zukunft.
Beteiligen Sie sich an der Diskussion bei Transform 2025
Ich werde zwei Diskussionsrunden zum Thema Cybersicherheit auf der Transform 2025 von VentureBeat leiten, die am 24. und 25. Juni im Fort Mason in San Francisco stattfindet. Melden Sie sich jetzt zur Teilnahme an.
Eine Sitzung mit dem Titel AI Red Teaming and Adversarial Testing (KI-Red-Teaming und Tests gegen Angreifer) befasst sich mit Strategien für das Testen und die Stärkung von KI-gestützten Cybersicherheitslösungen gegen fortgeschrittene Angreifer-Bedrohungen.
Verwandter Artikel
 Zhiyuan WITA beendet „nackte“ Roboterinteraktion mit erster Einreichung eines Konformitätsantrags
Der Sektor der verkörperten Intelligenz hat einen bedeutenden Meilenstein erreicht. Laut der jüngsten Mitteilung der Cyberspace-Verwaltungsbehörde von Shanghai hat das von Zhiyuan entwickelte WITA-Gro
Eine anthropologische Studie bringt ausgefeilte KI-Inhalte mit einem Rückgang des menschlichen Denkvermögens in Verbindung
Wenn Sie sehen, wie eine KI im Handumdrehen einen gut strukturierten, logisch klaren Code oder ein Dokument erstellt, sind Sie dann versucht, ihr ohne zu zögern zu vertrauen? Laut AIbase hat das führe
Britische Ministerien streiten über den Energiebedarf von KI-Rechenzentren
Die britische Regierung steht vor einer großen Herausforderung: Sie will die Nutzung sauberer Energien vorantreiben und gleichzeitig eine weltweit führende Rolle im Bereich der künstlichen Intelligenz
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
Zhiyuan WITA beendet „nackte“ Roboterinteraktion mit erster Einreichung eines Konformitätsantrags
Der Sektor der verkörperten Intelligenz hat einen bedeutenden Meilenstein erreicht. Laut der jüngsten Mitteilung der Cyberspace-Verwaltungsbehörde von Shanghai hat das von Zhiyuan entwickelte WITA-Gro
Eine anthropologische Studie bringt ausgefeilte KI-Inhalte mit einem Rückgang des menschlichen Denkvermögens in Verbindung
Wenn Sie sehen, wie eine KI im Handumdrehen einen gut strukturierten, logisch klaren Code oder ein Dokument erstellt, sind Sie dann versucht, ihr ohne zu zögern zu vertrauen? Laut AIbase hat das führe
Britische Ministerien streiten über den Energiebedarf von KI-Rechenzentren
Die britische Regierung steht vor einer großen Herausforderung: Sie will die Nutzung sauberer Energien vorantreiben und gleichzeitig eine weltweit führende Rolle im Bereich der künstlichen Intelligenz
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
 Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
 10 Tools
10 Tools
 xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai
Geschäft
Die beste Software zur Preisoptimierung mittels KI: Beobachten Sie die Konkurrenz und passen Sie Ihre Shop-Preise automatisch an
Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai
Code
Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai
Text-zu-Sprache
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Anmerkung des Herausgebers: Louis wird Ende des Monats bei VB Transform einen redaktionellen Rundtisch zu diesem Thema moderieren. Jetzt anmelden.
KI-Modelle sind unerbittlichen Angriffen ausgesetzt. 77 % der Unternehmen sind bereits Ziel von Angriffen - 41 % davon mit Prompt Injections und Data Poisoning - und die Methoden der Angreifer entwickeln sich schneller als die aktuelle Cyberabwehr.
Um das Blatt zu wenden, müssen wir grundlegend überdenken, wie die Sicherheit in die heutigen KI-Modelle integriert wird. DevOps-Teams müssen sich von einer reaktionären Haltung verabschieden und kontinuierliche Tests gegen Angreifer in den gesamten Entwicklungszyklus einbetten.
Red Teaming als zentrales Element der KI-Verteidigung
Die Absicherung großer Sprachmodelle (LLMs) während des gesamten DevOps-Zyklus erfordert die Integration von Red Teaming als zentrale Praxis. Anstatt die Sicherheit als letzten Kontrollpunkt zu behandeln - wie es bei Webanwendungs-Pipelines üblich ist - müssen kontinuierliche Gegentests in jede Phase des Softwareentwicklungs-Lebenszyklus (SDLC) eingebettet werden.
Ein stärker integrierter DevSecOps-Ansatz ist unabdingbar, um zunehmenden Bedrohungen wie Prompt Injection, Data Poisoning und der Preisgabe sensibler Informationen zu begegnen. Solche gefährlichen Angriffe treten immer häufiger auf, vom Modelldesign bis zur Bereitstellung, was die Dringlichkeit einer ständigen Überwachung unterstreicht.
Die jüngsten Richtlinien von Microsoft zur Planung von Red-Team-Übungen für LLMs und ihre Anwendungen bieten einen soliden Ausgangspunkt für einen integrierten Sicherheitsprozess. In ähnlicher Weise fordert das NIST AI Risk Management Framework einen proaktiven, lebenszyklusorientierten Ansatz für gegnerische Tests und Risikominderung. Microsofts Test von mehr als 100 generativen KI-Produkten unterstreicht die Notwendigkeit, die automatische Erkennung von Bedrohungen während der gesamten Modellentwicklung mit Expertenanalysen zu kombinieren.
Da Vorschriften wie das KI-Gesetz der EU strenge Anforderungen an das Testen von Angreifern stellen, gewährleistet ein fortlaufendes Red Teaming nicht nur die Einhaltung der Vorschriften, sondern verbessert auch die allgemeine Sicherheitswiderstandsfähigkeit.
OpenAI integriert externes Red Teaming vom ersten Entwurf bis zur Bereitstellung und bestätigt damit, dass konsistente, präventive Sicherheitstests für eine erfolgreiche LLM-Entwicklung unerlässlich sind.
Warum konventionelle Cybersicherheit gegen KI-Bedrohungen versagt
Herkömmliche Cybersecurity-Methoden haben es schwer gegen KI-gesteuerte Angriffe, da diese Bedrohungen auf völlig anderen Prinzipien beruhen. Da die Taktiken der Angreifer konventionelle Verteidigungsmaßnahmen übertreffen, sind neue Red Teaming-Techniken erforderlich. Im Folgenden werden mehrere Angriffsmethoden vorgestellt, die speziell für KI-Modelle während der DevOps-Zyklen und nach der Bereitstellung entwickelt wurden:
- Datenverfälschung: Angreifer schleusen bösartige oder verzerrte Daten in Trainingsdatensätze ein, wodurch KI-Modelle ungenau lernen. Dies führt zu dauerhaften Fehlern und betrieblichen Mängeln, die unentdeckt bleiben können und das Vertrauen in KI-gesteuerte Ergebnisse untergraben.
- Modellumgehung: Angreifer verändern auf subtile Weise die Eingaben, um Erkennungsmechanismen zu umgehen und die Grenzen statischer Regeln und musterbasierter Sicherheitssysteme auszunutzen.
- Modellumkehrung: Durch wiederholte, systematische Abfragen können Angreifer vertrauliche Daten, die beim Training verwendet wurden, rekonstruieren oder offenlegen, was zu schwerwiegenden Datenschutzverletzungen führt.
- Prompt-Injektion: Angreifer entwerfen Eingaben, die die generative KI so manipulieren, dass sie Sicherheitsvorkehrungen ignorieren und potenziell schädliche, unbeabsichtigte oder nicht autorisierte Inhalte produzieren.
- Dual-Use-Grenzrisiken: Wie in dem kürzlich erschienenen Papier " Benchmark Early and Red Team Often: A Framework for Assessing and Managing Dual-Use Hazards of AI Foundation Models, warnen Forscher des Center for Long-Term Cybersecurity der UC Berkeley davor, dass fortschrittliche KI-Modelle die Hürde für Laien senken, komplexe Cyberangriffe, chemische Bedrohungen oder andere gefährliche Exploits auszuführen - was die globalen Risiken erheblich erhöht.
Die Verflechtung von integrierten Machine Learning Operations (MLOps) verstärkt diese Risiken noch. LLM und breitere KI-Entwicklungspipelines erweitern die Angriffsfläche und erfordern ausgefeiltere Red-Teaming-Verfahren.
Um diesen sich weiterentwickelnden KI-Bedrohungen entgegenzuwirken, führen Cybersecurity-Führungskräfte kontinuierliche Tests mit Gegenspielern durch. Strukturierte Red-Team-Übungen, die reale KI-Angriffe simulieren, sind jetzt entscheidend, um versteckte Schwachstellen zu identifizieren und Sicherheitslücken zu schließen, bevor sie ausgenutzt werden.
Wie führende KI-Organisationen Red Teaming nutzen, um Angreifern zuvorzukommen
Angreifer setzen zunehmend KI ein, um noch nie dagewesene Angriffsmethoden zu entwickeln, die sich herkömmlichen Sicherheitskontrollen entziehen. Ihr Ziel ist es, so viele neue Schwachstellen wie möglich aufzudecken und auszunutzen.
Als Reaktion darauf haben führende KI-Unternehmen systematisches Red Teaming zu einem Eckpfeiler ihrer Sicherheitsstrategie gemacht. Anstatt Red Teaming nur sporadisch durchzuführen, implementieren sie kontinuierliche Gegentests, die menschliches Fachwissen, disziplinierte Automatisierung und iterative Bewertungen durch den Menschen in der Schleife kombinieren. Dieser proaktive Ansatz hilft dabei, Bedrohungen zu erkennen und zu neutralisieren, bevor sie zur Waffe werden können.
Durch rigorose Testmethoden identifizieren diese Führungskräfte systematisch Schwachstellen und stärken ihre Modelle gegenüber realen Angriffsszenarien.
Die wichtigsten Ansätze sind:
- Anthropic nutzt rigorose menschliche Bewertungen im Rahmen seines laufenden Red-Teaming-Prozesses. Durch die Integration von Human-in-the-Loop-Bewertungen mit automatisierten gegnerischen Angriffen deckt das Unternehmen proaktiv Schwachstellen auf und verbessert kontinuierlich die Zuverlässigkeit und Interpretierbarkeit seiner Modelle.
- Meta skaliert die Sicherheit durch einen Ansatz, bei dem die Automatisierung im Vordergrund steht. Sein MART-System (Multi-round Automatic Red-Teaming) generiert iterativ gegnerische Aufforderungen, um versteckte Schwachstellen schnell zu identifizieren und Angriffsvektoren in groß angelegten KI-Implementierungen einzugrenzen.
- Microsoft setzt auf interdisziplinäre Zusammenarbeit, um die Effektivität des Red-Teaming zu gewährleisten. Mit seinem Python Risk Identification Toolkit (PyRIT) kombiniert Microsoft Cybersecurity-Know-how mit fortschrittlicher Analytik und menschlicher Validierung, um die Entdeckung von Schwachstellen zu beschleunigen und umsetzbare Erkenntnisse zur Stärkung der Modellresilienz zu liefern.
- OpenAI setzt globale Sicherheitsexperten ein, um die KI-Abwehr in großem Umfang zu verbessern. Durch die Kombination von Erkenntnissen externer Experten mit automatisierten gegnerischen Tests und menschlichen Validierungszyklen begegnet OpenAI anspruchsvollen Bedrohungen - insbesondere Fehlinformationen und Prompt-Injection-Risiken -, um eine robuste und vertrauenswürdige Modellleistung zu gewährleisten.
Führende KI-Organisationen haben erkannt, dass es unermüdlicher, proaktiver Anstrengungen bedarf, um Angreifern einen Schritt voraus zu sein. Durch die Einbindung strukturierter menschlicher Aufsicht, disziplinierter Automatisierung und iterativer Verfeinerung in ihre Red-Teaming-Bemühungen setzen diese Unternehmen einen Maßstab für den Aufbau widerstandsfähiger und vertrauenswürdiger KI-Systeme.
Fünf umsetzbare Strategien, um die KI-Sicherheit jetzt zu verbessern
Da die Angriffe auf LLMs und KI-Modelle immer komplexer werden, müssen DevOps- und DevSecOps-Teams eng zusammenarbeiten, um die KI-Sicherheit zu verbessern. VentureBeat empfiehlt diese fünf hochwirksamen Strategien, die Sicherheitsverantwortliche sofort umsetzen können:
- Sicherheit frühzeitig einbinden (Anthropic, OpenAI)
Integrieren Sie negative Tests direkt in die anfängliche Designphase und führen Sie diese über den gesamten Lebenszyklus des Modells durch. Die frühzeitige Erkennung von Schwachstellen verringert das Risiko, minimiert Unterbrechungen und senkt die langfristigen Kosten.
- Einsatz einer adaptiven Echtzeit-Überwachung (Microsoft)
Statische Schutzmaßnahmen reichen nicht aus, um fortschrittliche KI-Bedrohungen abzuwehren. Verwenden Sie kontinuierliche KI-gestützte Überwachungstools wie CyberAlly, um subtile Anomalien schnell zu erkennen und das Zeitfenster für einen Angriff zu verringern.
- Gleichgewicht zwischen Automatisierung und menschlichem Urteilsvermögen (Meta, Microsoft)
Der Automatisierung allein fehlt es an Nuancen, und manuelle Tests lassen sich nicht skalieren. Kombinieren Sie automatisierte gegnerische Scans und Schwachstellenbewertungen mit der Analyse von Experten, um genaue und umsetzbare Ergebnisse zu erhalten.
- Ziehen Sie regelmäßig externe Red Teams hinzu (OpenAI)
Interne Teams können blinde Flecken entwickeln. Regelmäßige Bewertungen durch externe Red Teams decken übersehene Schwachstellen auf, bieten eine unabhängige Validierung und treiben laufende Sicherheitsverbesserungen voran.
- Pflegen Sie dynamische Bedrohungsdaten (Meta, Microsoft, OpenAI)
Angreifer verfeinern ihre Methoden ständig. Integrieren Sie kontinuierlich Echtzeit-Bedrohungsdaten, automatisierte Analysen und Erkenntnisse von Experten, um Ihre Verteidigungsmaßnahmen proaktiv zu aktualisieren und zu verstärken.
Gemeinsam helfen diese Strategien DevOps-Workflows, angesichts der sich schnell entwickelnden Bedrohungen widerstandsfähig und sicher zu bleiben.
Red Teaming ist jetzt unerlässlich, nicht optional
KI-Bedrohungen sind mittlerweile zu ausgeklügelt und häufig, als dass sie mit herkömmlicher, reaktiver Cybersicherheit effektiv bewältigt werden könnten. Um einen Verteidigungsvorteil zu erhalten, müssen Unternehmen kontinuierliche Tests mit Angreifern in jede Phase der Modellentwicklung einbeziehen. Führende KI-Anbieter zeigen, dass starke Sicherheit und schnelle Innovation Hand in Hand gehen können, indem sie ein Gleichgewicht zwischen Automatisierung und menschlicher Einsicht herstellen und die Verteidigungsmaßnahmen dynamisch anpassen.
Letztlich geht es bei Red Teaming um mehr als nur den Schutz von KI-Modellen - es geht um den Aufbau von Vertrauen, Widerstandsfähigkeit und Zuversicht in eine KI-gesteuerte Zukunft.
Beteiligen Sie sich an der Diskussion bei Transform 2025
Ich werde zwei Diskussionsrunden zum Thema Cybersicherheit auf der Transform 2025 von VentureBeat leiten, die am 24. und 25. Juni im Fort Mason in San Francisco stattfindet. Melden Sie sich jetzt zur Teilnahme an.
Eine Sitzung mit dem Titel AI Red Teaming and Adversarial Testing (KI-Red-Teaming und Tests gegen Angreifer) befasst sich mit Strategien für das Testen und die Stärkung von KI-gestützten Cybersicherheitslösungen gegen fortgeschrittene Angreifer-Bedrohungen.










 Zhiyuan WITA beendet „nackte“ Roboterinteraktion mit erster Einreichung eines Konformitätsantrags
Der Sektor der verkörperten Intelligenz hat einen bedeutenden Meilenstein erreicht. Laut der jüngsten Mitteilung der Cyberspace-Verwaltungsbehörde von Shanghai hat das von Zhiyuan entwickelte WITA-Gro
Zhiyuan WITA beendet „nackte“ Roboterinteraktion mit erster Einreichung eines Konformitätsantrags
Der Sektor der verkörperten Intelligenz hat einen bedeutenden Meilenstein erreicht. Laut der jüngsten Mitteilung der Cyberspace-Verwaltungsbehörde von Shanghai hat das von Zhiyuan entwickelte WITA-Gro
 Eine anthropologische Studie bringt ausgefeilte KI-Inhalte mit einem Rückgang des menschlichen Denkvermögens in Verbindung
Wenn Sie sehen, wie eine KI im Handumdrehen einen gut strukturierten, logisch klaren Code oder ein Dokument erstellt, sind Sie dann versucht, ihr ohne zu zögern zu vertrauen? Laut AIbase hat das führe
Eine anthropologische Studie bringt ausgefeilte KI-Inhalte mit einem Rückgang des menschlichen Denkvermögens in Verbindung
Wenn Sie sehen, wie eine KI im Handumdrehen einen gut strukturierten, logisch klaren Code oder ein Dokument erstellt, sind Sie dann versucht, ihr ohne zu zögern zu vertrauen? Laut AIbase hat das führe
 Britische Ministerien streiten über den Energiebedarf von KI-Rechenzentren
Die britische Regierung steht vor einer großen Herausforderung: Sie will die Nutzung sauberer Energien vorantreiben und gleichzeitig eine weltweit führende Rolle im Bereich der künstlichen Intelligenz
Britische Ministerien streiten über den Energiebedarf von KI-Rechenzentren
Die britische Regierung steht vor einer großen Herausforderung: Sie will die Nutzung sauberer Energien vorantreiben und gleichzeitig eine weltweit führende Rolle im Bereich der künstlichen Intelligenz

Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai













